






1. 背景
“AI小万”是阿里妈妈基于先进AI能力给广告商家打造的AI数字员工,作为个性化的推广管家帮助商家在淘宝平台更好地进行营销推广。它通过对话方式对客户的精准意图进行识别,辅助多轮会话及总结能力,在投放的各个环节给广告主带来个性化建议,比如依托全局营销知识库的知识问答功能,基于自然语言表达的数据快查功能,面向推广提效的诊断调优、AI巡检、早晚报、图表速成功能,面向投放过程辅助的AI选词及悉语文案功能等,目前小万支持的功能如下图所示:
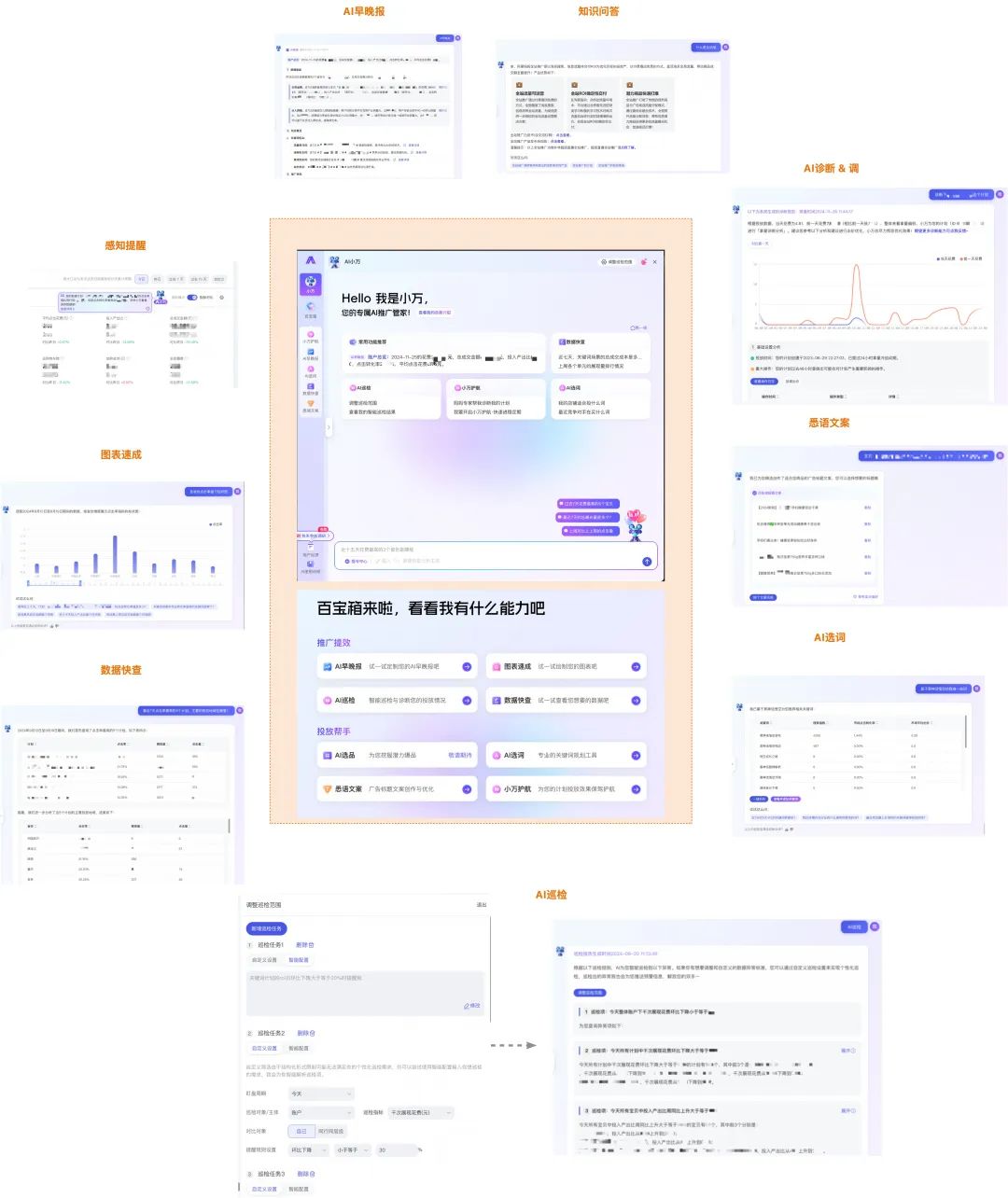
延展阅读>>:详细产品信息请参考阿里妈妈「AI小万」正式上岗,你的专业推广诊断师来了!
小万是阿里妈妈充分利用大模型价值的典型AI应用,其背后包括针对大模型规划、生成能力的原生化实践,Multi-Agent架构体系的沉淀,以及配套的原生化AI工程能力建设。本文会针对小万背后的工程能力进行一轮揭秘。
2. 整体思路
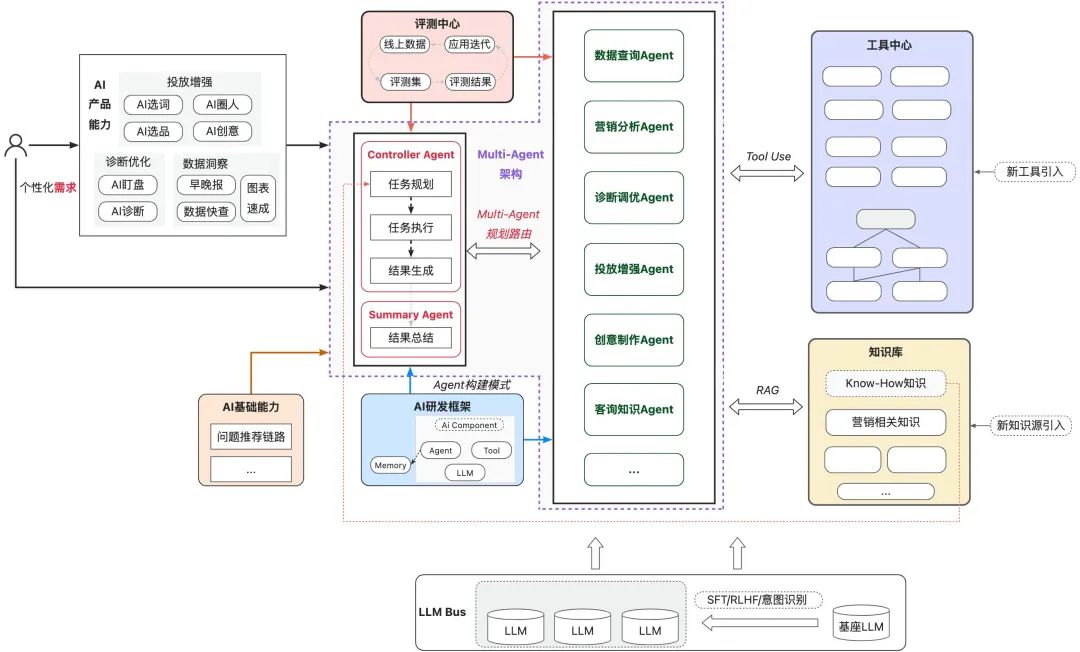
小万作为AI商业应用,与传统商业化应用最大的区别在于允许用户做个性化诉求表达,工程框架侧核心是构建Native AI Agent模式来进行支持。具体思路包括:
-
依托Multi-Agent架构体系,联动工程体系和算法能力,充分利用大模型价值(规划能力、生成能力),对商业化能力进行支撑;
-
依托工具中心,标准化外部能力的构建和调用模式,高质量的为大模型提供外部工具调用能力;
-
依托知识库,实现知识标准化迭代,持续提升知识质量,通过端到端的RAG能力,助推应用效果的持续提升;
-
依托评测中心,初步形成AI应用迭代的数据飞轮,提升AI应用迭代的质量。具体如下图所示:
3. 技术细节
3.1 Multi-Agent架构体系
小万基于Vertical Multi-Agent架构进行了Native AI Agent能力的建设,具体如下图所示。
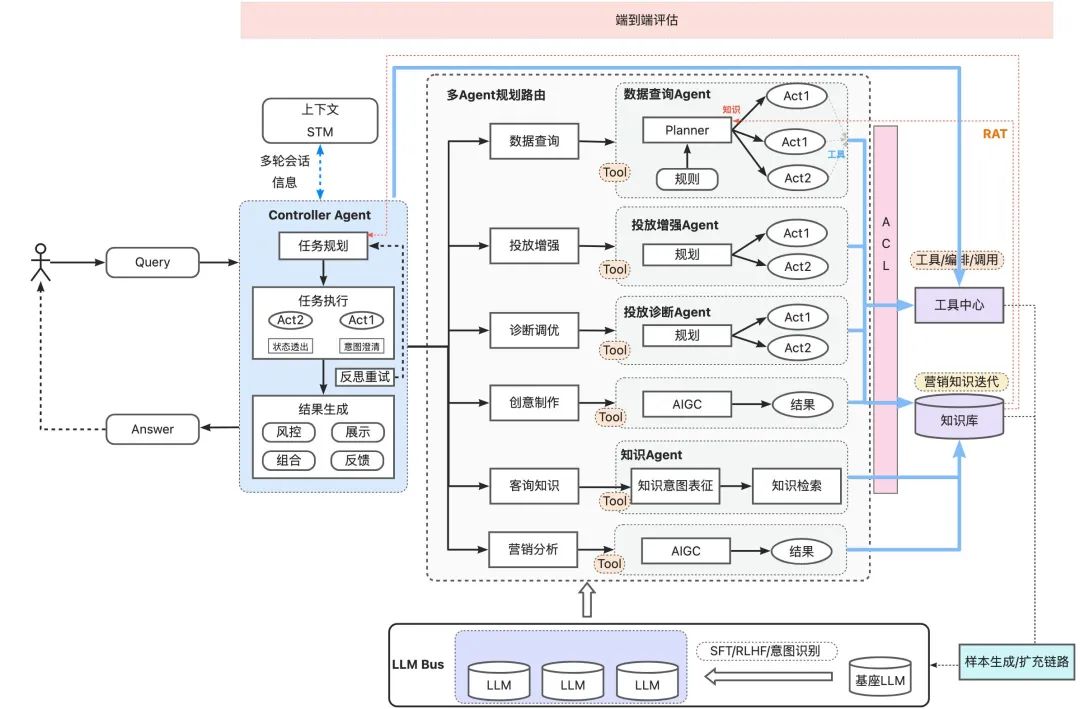
其中Controller Agent为入口层Agent,其核心定位为拆解及分发任务,汇总总结,和客户直接交互。类似于老板角色。它通过任务规划形成任务执行指令,交由执行Agent来执行,并针对执行结果对用户进行展示。Controller Agent之下为Executable Agent,其核心定位为专业工作的执行,类似于员工角色。
Controller Agent与Executable Agent基于标准化的Agent通信协议来进行交互,通信协议中包括原始的自然语言指令及改写后的更精准 & 具体的指令。交互过程中的多轮对话历史信息及执行中的过程信息,两者通过Memory进行共享。
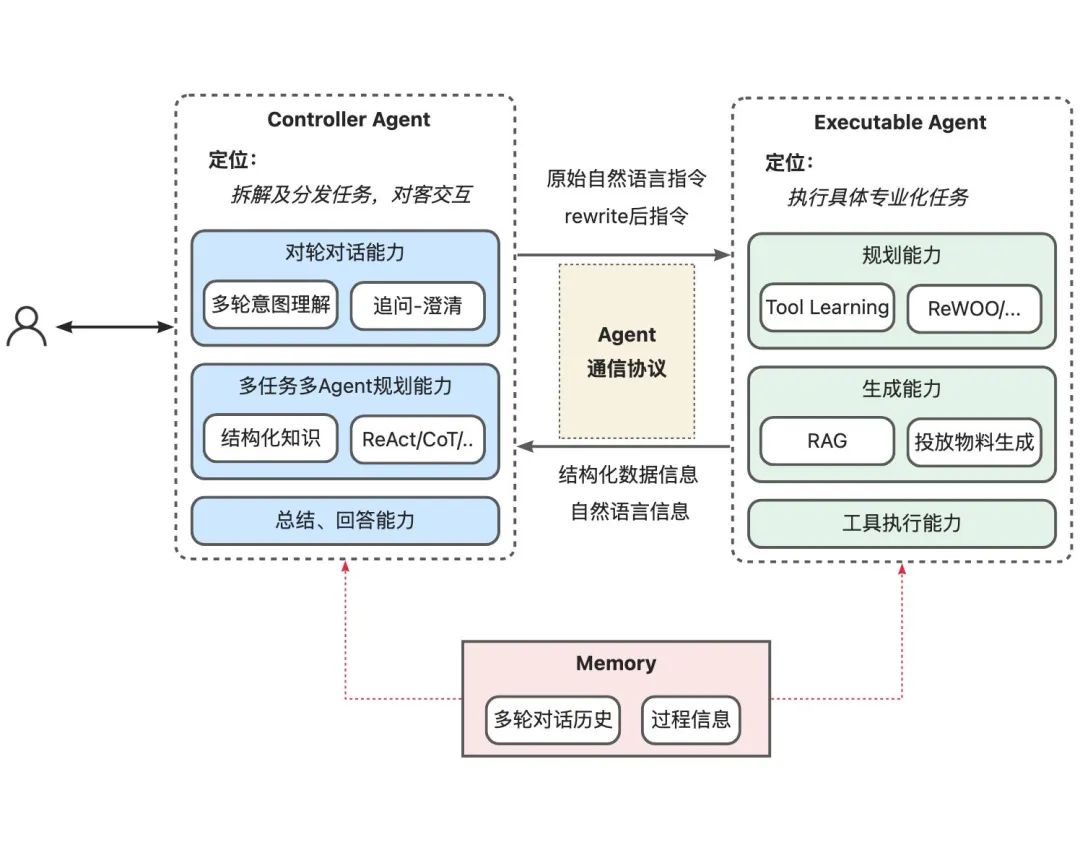
3.1.1 Controller Agent
Controller Agent是客户交互的入口,结合用户的意图进行拆解及分发,我们基于自研的研发框架联动算法侧进行了多轮对话、总结回答能力、多任务Agent规划建设。
多轮会话能力:通过Memory升级,并联动算法Planner模块及工具中心,完成了多轮会话能力的升级。
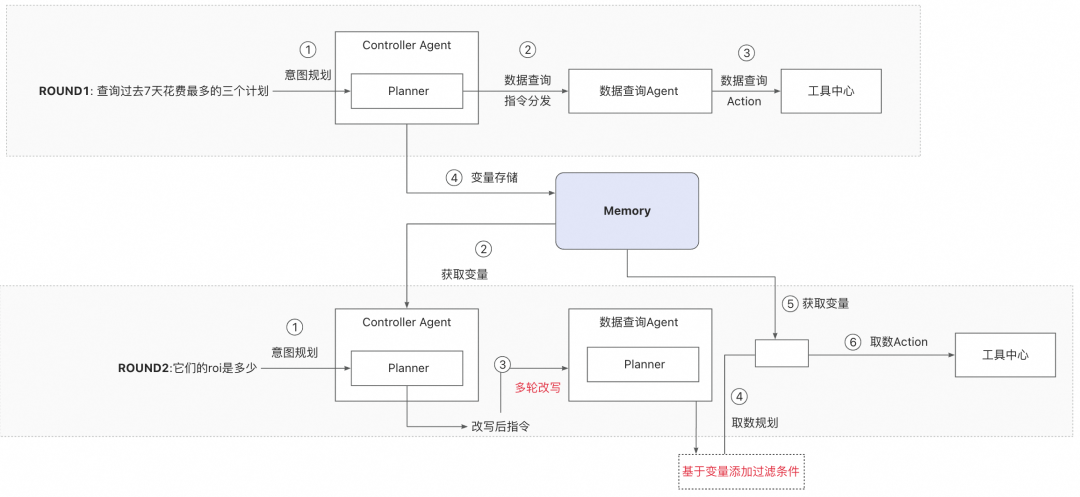
如上图所示,针对图示的多轮对话,系统处理过程如下:
🏷 ROUND 1: 查询过去7天花费最多的三个计划
-
Controller Agent的Planner模块识别用户的意图,生成数据查询指令,分发给数据查询Executable Agent。
-
数据查询Agent执行查询操作,借助工具中心中的计划数据查询工具获取对应指令关联的数据。
-
查询结果(包含计划ID、计划花费数据信息),以变量的形式存储在Working Memory中,比如:使用
tb1f88f642f5标识,同时在Episodic Memory中存储用户的对话历史。
🏷 ROUND 2: 它们的ROI是多少
-
Controller Agent的Planner结合Episodic Memory中的对话历史,基于当轮次请求,对用户进行意图识别。
-
结合对话历史及当轮次请求进行多轮对话改写,将查询范围限定于上一轮次的查询结果,对应
tb1f88f642f5变量中的数据。 -
将多轮对话改写后的指令分发给数据查询Executable Agent,数据查询Agent的Planner生成具体的取数Plan,Plan中包括基于
tb1f88f642f5变量的过滤条件。 -
数据查询Agent执行查询操作,将Plan及Plan中包含的变量value封装成action,调用工具中心中的计划数据查询工具,获取对应指令关联的数据。
Summary能力:基于研发框架进行了Graph编排,联动算法侧完成Summary能力建设,针对复杂的取数类场景完成过程润色及结果总结能力。
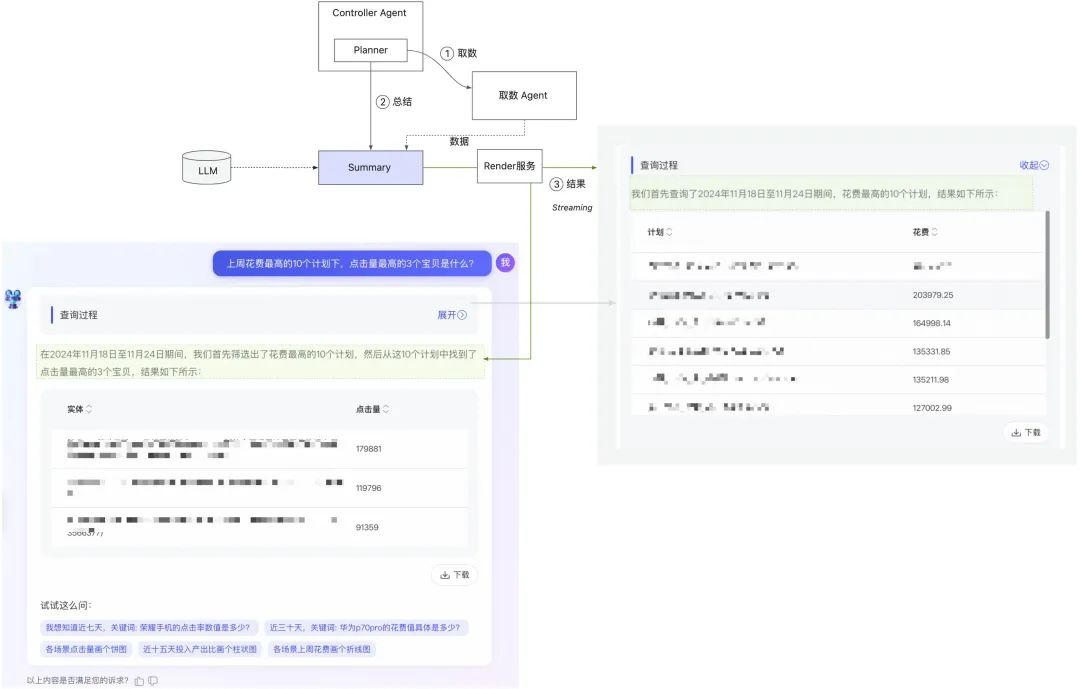
-
Agent执行的结果,通过Summary组件完成从原始数据到对客展示数据的润色和总结,可视化结果通过Streaming方式展示给用户。
-
营销场景涉及到结构化数据,Summary组件组合模型能力和工具能力,实现准确回答定性的数据问题,同时生成对数据的总结性文案。
复杂问题的CoT规划:部分复杂问题需要进行多次反思规划才能得出最终的一个结论,在Controller Agent引入了ReAct模式来进行复杂问题的CoT规划。ReAct过程中的Context数据,交由LLM进行反思,决定下一步规划的结果。
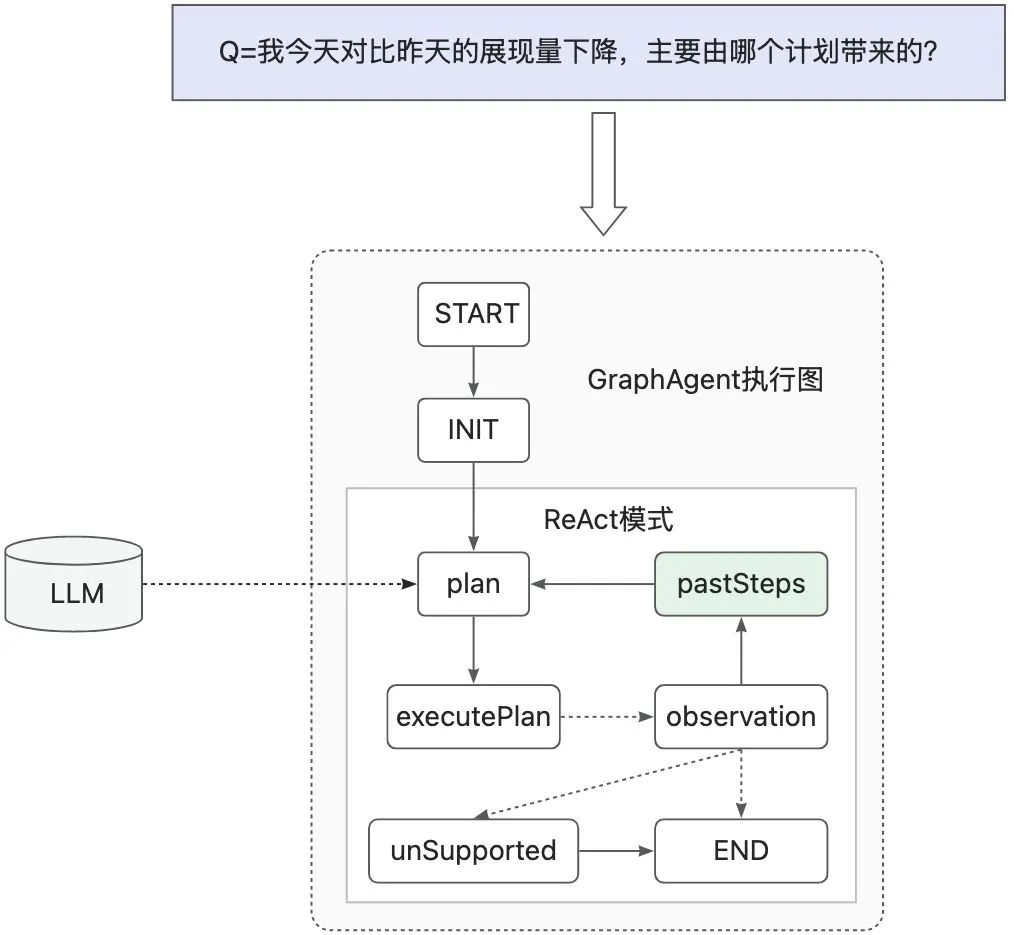
借助研发框架的组图能力,基于ReAct模式的step进行了组图,在observation之后引入了pastSteps环节,将observation的结果与之前的步骤进行汇总,供LLM在下一轮迭代中使用。
3.1.2 Executable Agent
Executable Agent,其核心定位为专业工作的执行,目前Multi-Agent下挂了几个特定领域的Agent:

数据查询Agent任务规划能力:在执行框架侧,通过Plan & Execute规划模式,与内置LLM的Planner模块之间进行交互,规划出的工具动态编排的协议,同时通过预定义了callback函数inject上下文及环境信息,完成复杂取数指令的执行。
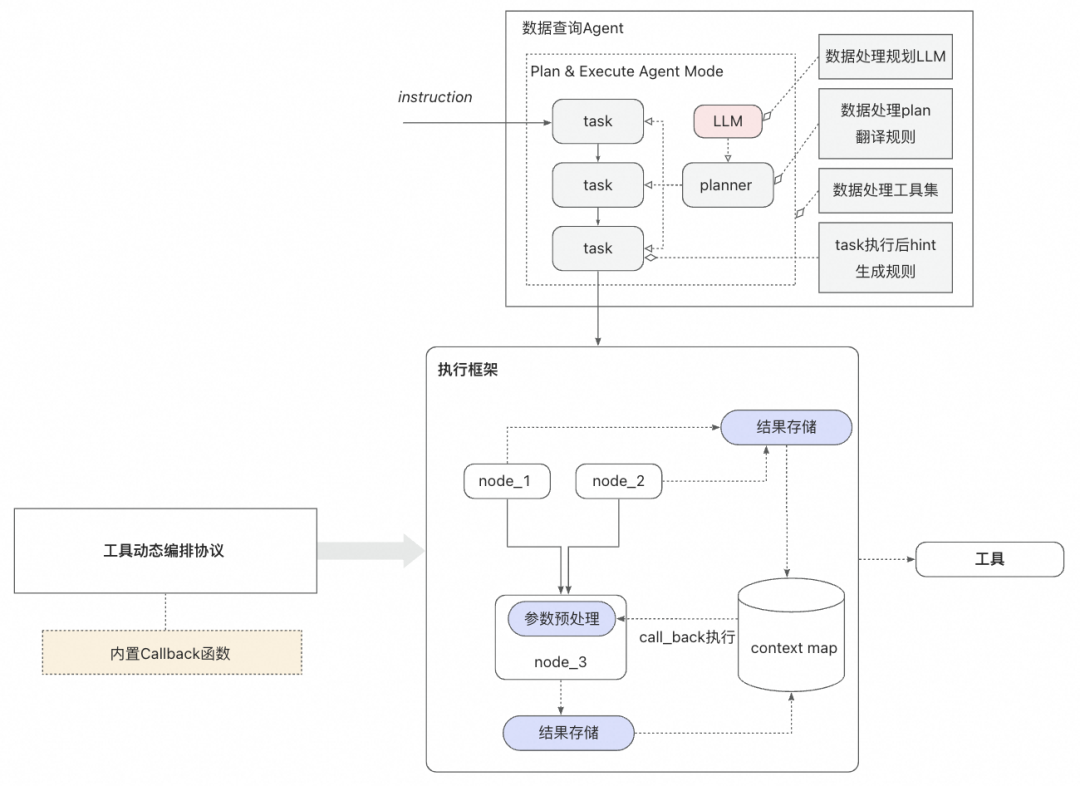
-
任务规划的主要工作在算法侧提供的Planner模块中完成,执行框架侧定义了和Planner模块之间的Plan & Execute模式交互协议。
-
数据查询Agent同时构建了对Planner模块返回的处理层,翻译为框架可以理解的执行Plan,进行必要的参数填充后,对工具中心进行调用。
-
工具中定义了工具动态编排的协议,同时预定义了callback函数,比如
__call_back_dump_list($_node_1.计划),可以获取上一个节点的计划执行结果。 -
通过执行动态编排的子任务,完成复杂取数指令的执行。
3.1.3 Agent通信协议
在Multi-Agent体系下定义了标准化的Agent协议,方便各Agent间的通信,在协议上借鉴了Google Langfun的自然语言表达,及结构化变量携带,并在出参上携带schema信息;协议定义上也参考了开源的AgentProtocol。
-
Agent入参:包括了实例化后的指令、原始请求、相关上下文变量。
{
"input": xxx, // 实例化后真实调用自然语言
"additionalInput": {
"rawInput": xxx, // 原始请求
"rewriteInput": xxx, // 改写后请求
"variable1": xxx, // 相关变量
...
},
....
}
-
Agent出参:包括了执行结果,执行后的输出类型、schema信息、过程task信息。
{
"status": "success|failed|unsupported", // 执行成功|执行失败|能力暂不具备
"outputType": "标准化输出类型"
"output": "xxx | [] | {} ",
"outputSchema": {}, // 对应的结果schema
"additionalOutput":{}
"tasks": [
{
"task_id": "xxx",
"name": "xx"
"type": "agent, tool, function, xx",
"output": "xxx | [] | {} ",
"additionalOutput":{}
"input": {}
}
]
....
}
-
Agent原始支持暴露远程调用endpoint,协议上兼容AgentProtocol(https://agentprotocol.ai/)。
3.2 基于工具中心的标准化Tool-Use能力的建设
依托小万场景,我们沉淀了具备标准化Tool-Use能力的工具中心,其面向妈妈全域工具进行管理,通过工具规范,支持高效工具接入、高效模型训练、高效agent调用,并建立工具可观测性及评估机制,建立了Tool-Use及Tool Learning的标准。
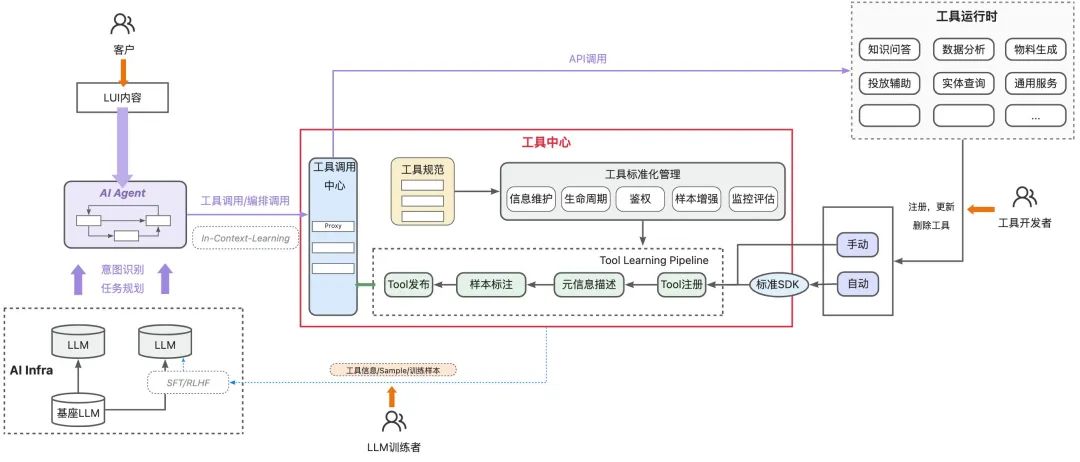
其中的关键能力包括:
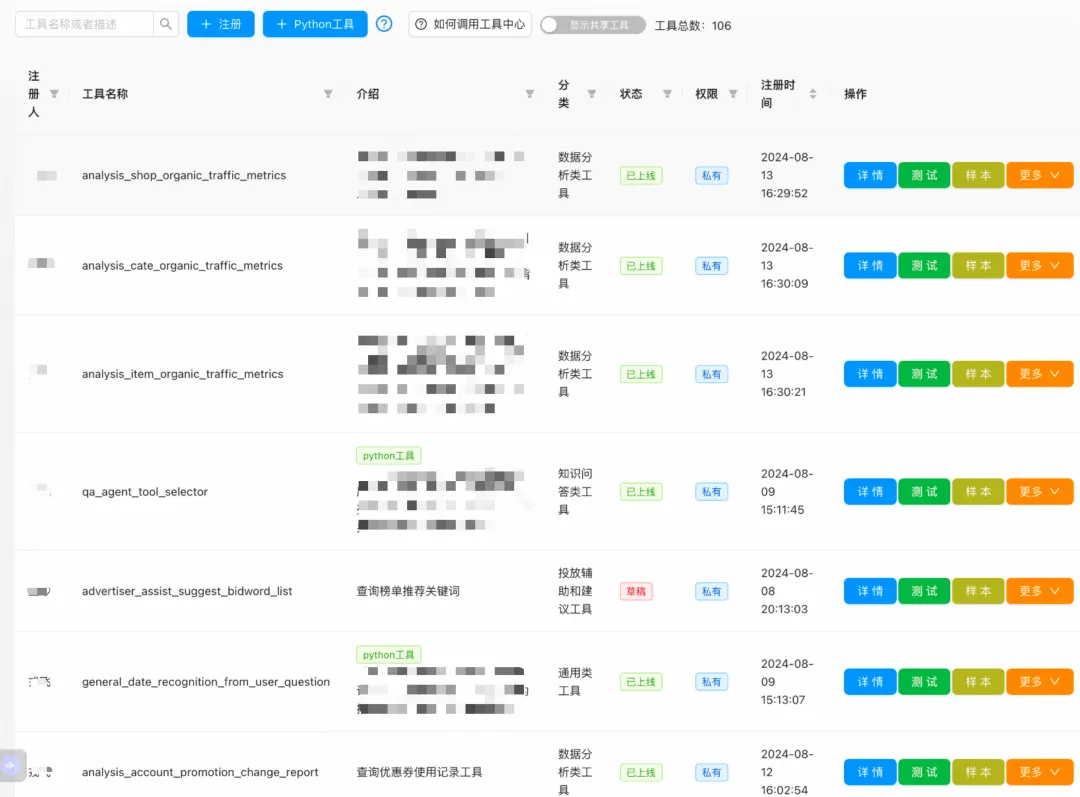
工具接入 & 样本增强标准化:对全域工具进行管理,包括工具的注册、发布、修改、删除、打标等;同时进行工具调用权限的管控;针对工具识别的样本,我们实现了样本管理能力,包括样本的添加、修改及删除;同时提供了基于种子样本进行的AI样本泛化增强能力。
-
开发者只需要设置工具出入参描述及context变量,即可完成HTTP/RPC API的快捷注册;针对需要定制开发的工具,平台提供了Python的Playground,开发者基于工具规范实现Python代码即可完成工具注册。
-
开发者可以对工具进行管理,包括授权、打标等;通过标签快速搜索和对工具进行自定义分类,可以进行工具快速查找,并关联到相应的Agent上。
-
针对工具调用样本进行了管理,样本主要应用于模型SFT和ICL(In Context Learning的few shot样本),目前样本包括正样本(应该使用这个工具的问题集合);负样本(不能应用这个工具的问题集合);评测样本(测试集,用于评估ICL效果)三种;样本增强场景,充分利用了大模型能力,基于种子样本进行泛化生成。
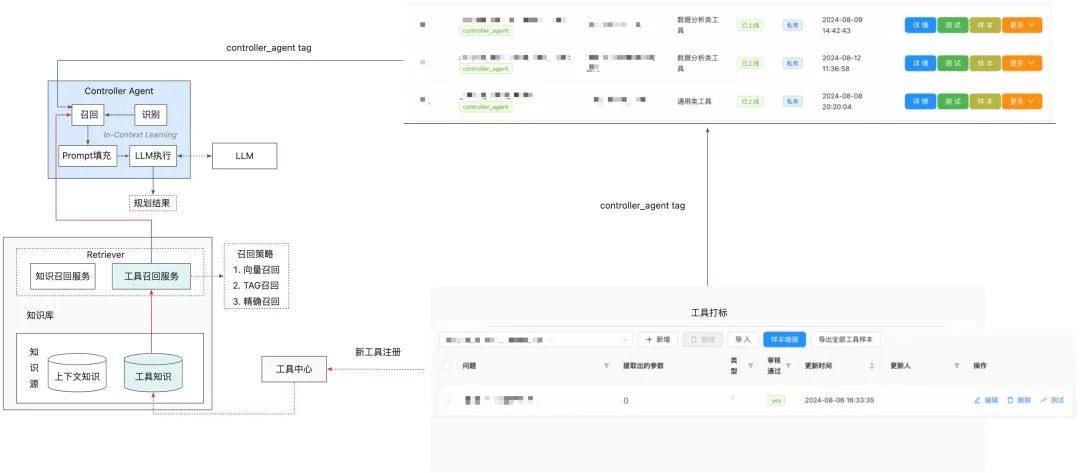
工具动态感知:联动Controller Agent侧构建了In-Context-Learning链路,新工具可以通过打标进行动态感知,badcase可以通过升级工具样本进行快速解决。
-
在工具中心上进行工具打标,小万的Controller Agent的ICL组件会打
controller_agenttag。 -
打标后的工具的工具信息(工具定义、描述、关联的正负样本)以知识的方式进入知识库,知识库提供统一的工具召回服务,包含多种召回策略(向量、TAG、精确)。
-
Controller Agent在执行时会基于向量 + TAG进行工具知识召回,召回的工具信息进行Prompt填充,并完成ICL识别及后置的工具执行。
3.3 基于Advanced RAG的知识库建设
依托小万场景进行了知识库建设,为妈妈营销大模型提供优质数据语料,并提供端到端的RAG能力,助推小万知识场景效果的持续提升。
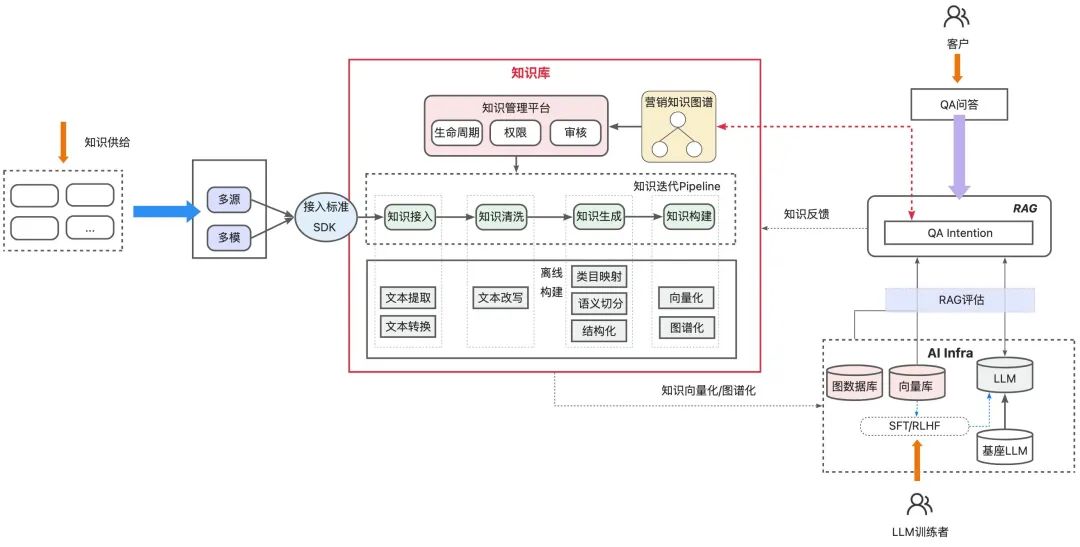
其中的关键能力包括:
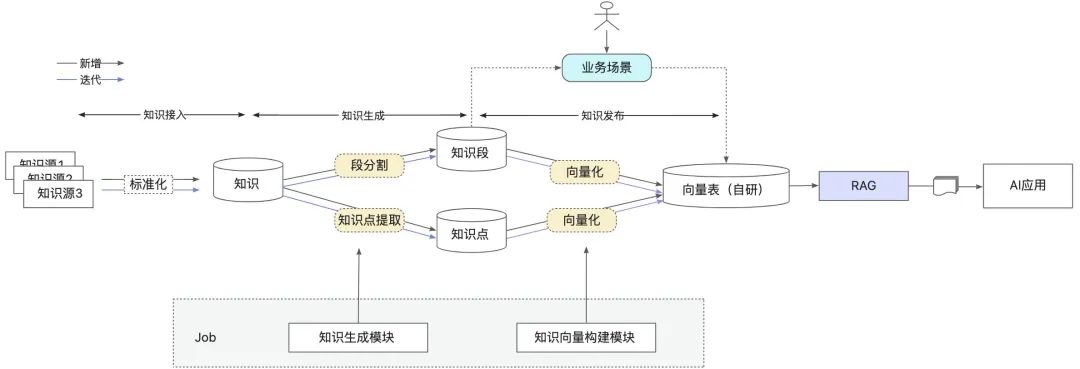
知识接入标准化:实现了从知识接入到知识索引构建的链路标准化,具体如下图所示:
-
链路覆盖了从知识接入到索引构建完成的完整链路,目前链路的各个环节支持配置化。
-
支持多种维度的索引构建,比如(业务)场景维度、知识源维度,不同维度均实现了底层数据表隔离,确保构建的稳定性;知识源维度的构建模式避免索引的冗余构建,提升索引信息的复用性。
-
知识生成环节包括了知识分段和知识点提取两种模式,其中知识点抽取模式基于大模型来进行增强;知识分段模式支持了常见的预处理策略,如去除特殊符号、去除网页链接及邮件地址等,架构上预留了扩展策略。
-
原始支持了离线、实时索引构建,目前100篇以下的知识源5分钟内可以完成索引构建。
知识管理标准化:依托内部的AI研发平台构建了营销场景的知识管理平台,实现了面向小万的知识管理标准化。
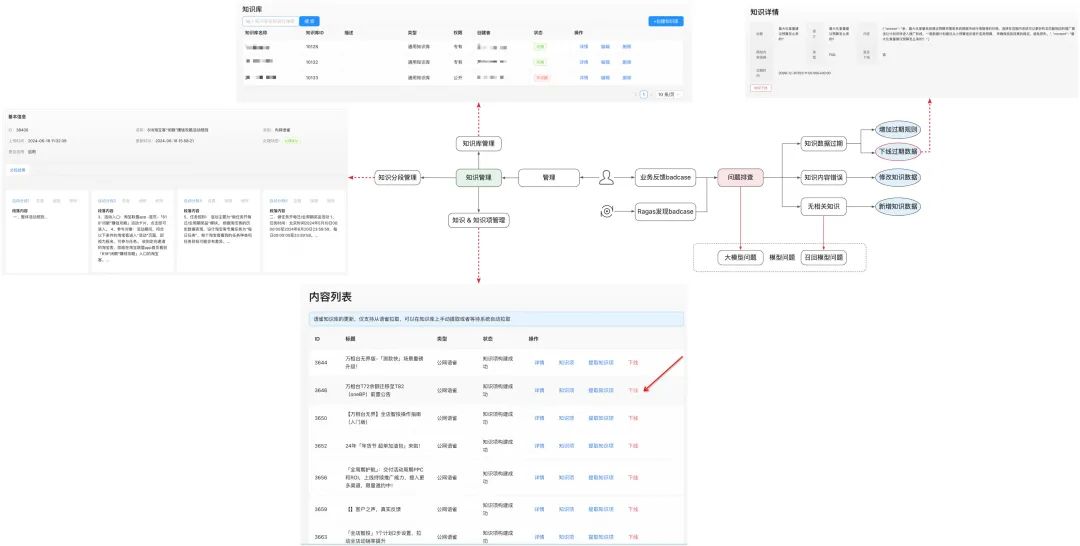
-
便捷的数据源接入能力,目前支持内网语雀、外网语雀、富文本、外网钉钉文档、消息队列、数据库等多种知识源的接入,知识源接入后,支持自动更新最新知识内容。
-
通用的知识、知识项管理能力,可以对知识源、知识分段结果、知识、知识项进行快速查看及管理。
-
知识干预能力,可以根据线上反馈/系统发现的问题,通过traceId追踪知识召回流程,并按需补充/下线特定的知识,快速应对线上可能出现的之类问题。
-
知识构建流程管控能力,知识构建全生命周期可在控制台处查看及干预(如可手动发起场景构建、手动重新向量化知识点等;同时提供页面随时查看及操作后台任务,方便系统运维人员追踪并及时发现异常运行的任务。
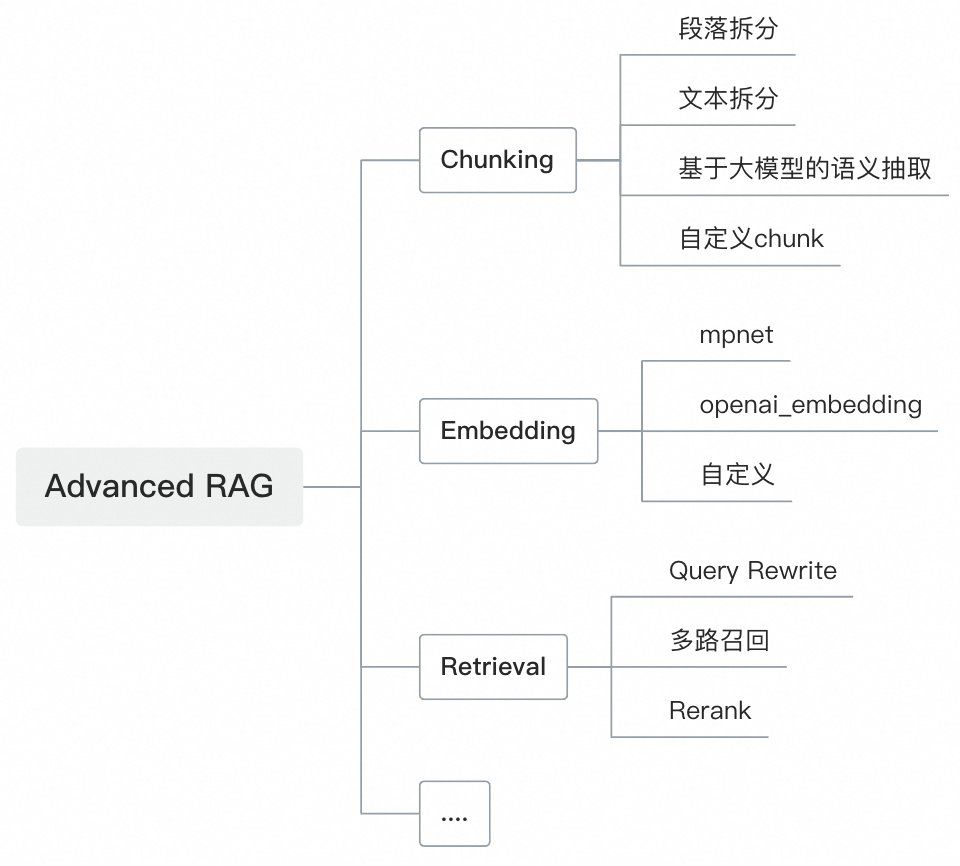
Advanced RAG系统建设:持续进行RAG高级能力的升级,支持多种类型的Chunk、Retrieval、Generation等配置化;围绕着Chunking、Retrieval、Generation等高级RAG特性进行了各种优化,比如基于大模型的语义抽取、基于大模型的Query Rewrite、Q-Q & Q-A & FAQ & 关键词的四路召回模式等。
3.4 面向应用迭代的数据飞轮建设
AI应用的效果,最终依托数据飞轮来提升,我们面向小万,完成了标准化数据链路的构建,依托评测中心收拢应用侧的回流、反馈、清洗、标注、评测数据,持续提升小万的迭代质量。
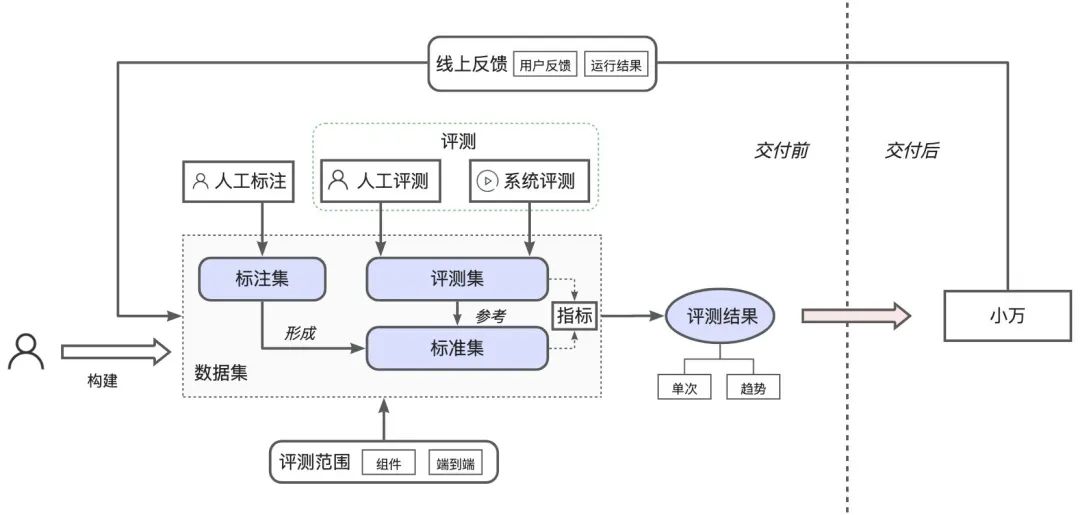
依托人工/自动化评测的数据飞轮迭代机制:评测中心打通线上回流截图,基于人工/自动化评测发现线上潜在的问题,并通过工单系统来追踪和反馈,解决后通过Popup机制通知到潜在用户,从而驱动业务迭代。
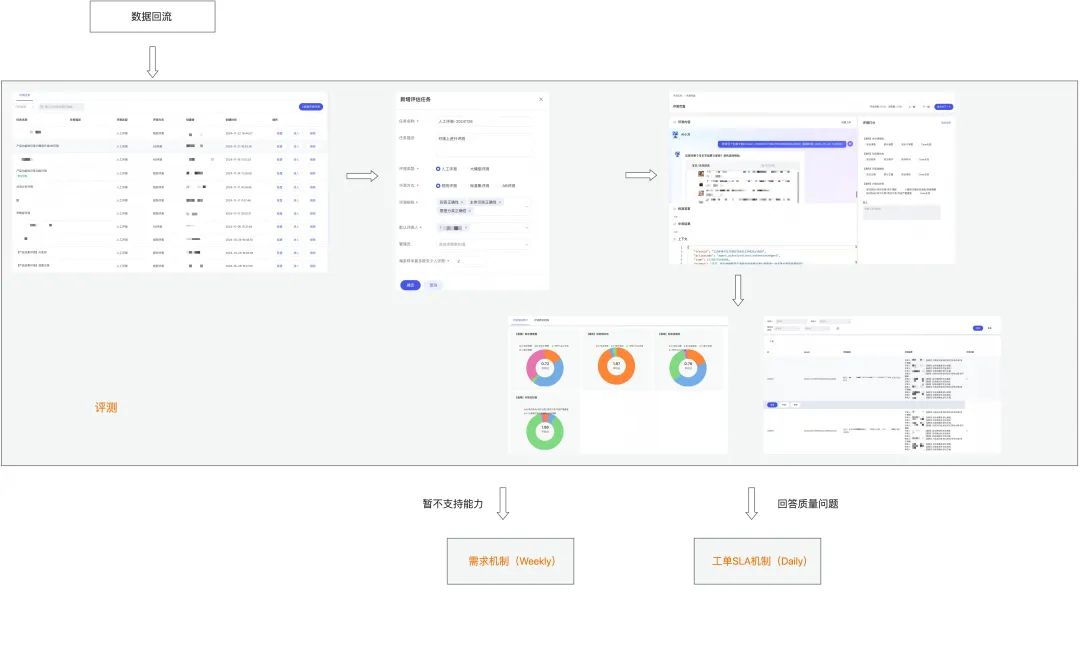
-
基于标准化的埋点日志,完成数据采集、数据回流及渲染,回流结果中包括多轮信息及运行截图信息。针对小万场景,基于数据回流面板进行回流数据打标,发现有问题的case。
-
基于评测中心,创建评测任务,评测类型包括人工评测和大模型评测,评测方式包括规则评测、标准集评测及AB评测。
-
基于评测中心完成评测,并生成评测报告,评测报告包括了分指标的综合评分、变化趋势及评测明细。
-
针对数据回流打标及评测结果,基于系统机制完成后续的action串联,针对暂不支持能力, 基于需求机制(Weekly)来进行优化审计,针对回答质量问题,基于工单SLA机制(Daily)进行改进优化。
4. 未来规划
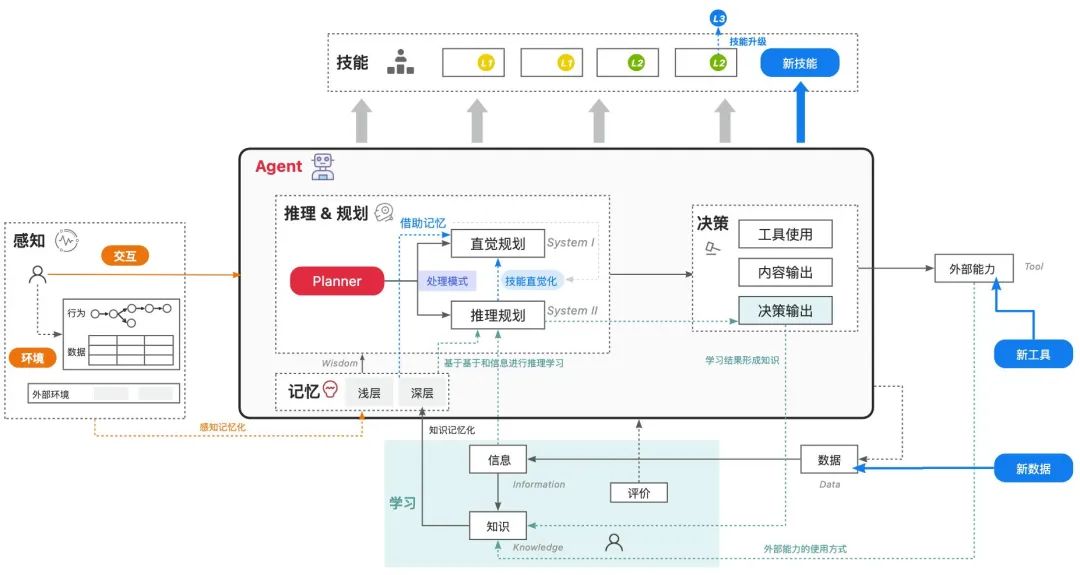
AI数字员工的一个核心特质是可以在真实场景中基于正负反馈不断提升自身能力,实现“自我进化”,这也是搜推广等传统算法模型驱动业务的技术精髓。
目前,小万已经初步完成了交互感知、直觉规划、外部能力标准化接入以及基础知识生产和迭代链路的构建。为了进一步提高其智能水平,我们需要以智能体Agent为中心,进行拟人化建设,标准化感知、规划及认知学习模式,推动Agent技能进化。下个阶段,我们将持续建设基于Memory的感知能力、System2级别的推理和规划能力,并构建完整的DIKW学习链路,确保小万能够持续学习并不断涌现新技能。
▐ 关于我们
我们是阿里妈妈AI数据与应用平台团队,专注于推进AI商业应用、AI工程体系构建,及AI应用架构的升级,目前相关的工程能力,覆盖阿里妈妈内外多条业务线,欢迎各业务方关注与业务合作。同时,欢迎具备AI背景的同学加入我们!
📮简历投递邮箱:alimama_tech@service.alibaba.com
也许你还想看


















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









