







泛化能力指的是由某学习方法得到的模型对新数据的预测能力。泛化误差是度量这一能力的指标。实际上,泛化误差就是所学到的模型的期望风险,跟上一篇讲到的选择模型时衡量的期望风险一样:
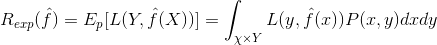
那么泛化误差的概率上界是什么呢?
假设f是选定的模型函数,R(f)是在训练集上的训练误差期望,R^(f)是在整个概率分布上的样本均值,即在可能的所有数据上产生的误差,所以理想状态下我们希望选择的模型的训练误差等于R^(f),但是实际情况下是不可能的,那么我们就需要让R(f)特别接近R^(f),根据Hoeffding不等式:
设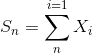
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 864
864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









