






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达

Evolving Attention with Residual Convolutions
作者单位:北京大学, 微软, 中科院, ETH Zurich, 清华大学
论文:https://arxiv.org/abs/2102.12895
本文提出了一种新型通用的注意力机制Evolving Attention来提高Transformer的性能。针对多种任务,其中包括图像分类、自然语言理解和机器翻译,本文所提出的Evolving Attention机制在各种最先进的模型中都取得了显著的性能提升。
转载自:AI人工智能初学者
1 摘要
Transformer是一种普遍存在于自然语言处理的模型,近期在计算机视觉领域引起了广泛关注。而Attention map主要用来编码input tokens之间的依赖关系,其对于一个Transformer模型来说是必不可少的。然而,它们在每一层都是独立学习的,有时无法捕获精确的模式。
因此在本文中,作者提出了一种新型通用的注意力机制Evolving Attention来提高Transformer的性能。一方面,不同层次的Attention map可以共享共同的知识,即前一层的Attention map可以通过残差连接指导后续层的Attention map;另一方面,Low-Level和High-Level Attention在不同的抽象层次上存在差异,因此作者采用卷积层来模拟Attention map的演化过程。
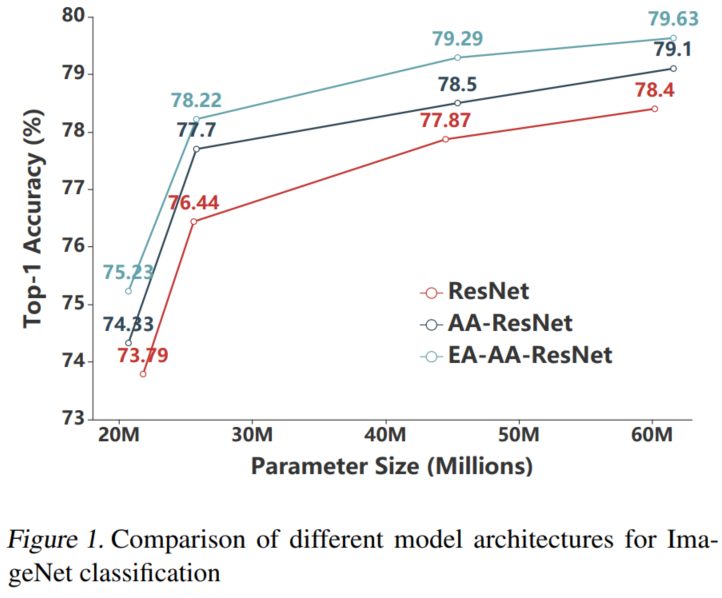
针对多种任务,其中包括图像分类、自然语言理解和机器翻译,本文所提出的Evolving Attention机制在各种最先进的模型中取得了显著的性能提升。
本文的贡献如下:
1、提出了一种新的Attention机制,该机制由一系列Residual CNN增强。这是第1个Attention Map作为多通道图像进行pattern extraction和evolution的研究,为Attention机制提供了新的思路;
2、通过大量的实验表明,在各种自然语言和计算机视觉任务中本文所提方法都有持续的改善。并广泛的分析表明,残差连接和卷积感应偏差都有助于产生更好的Attention Map;
3、本文所提出的Evolving Attention机制对基于Attention的结构具有普遍的适用性,并具有更广泛的应用前景。
2 相关工作
Transformer最开始是由Vaswani等人引入机器翻译,然后被广泛应用于NLP、CV和TS领域的许多任务中。Transformer完全由Self-Attention和feed-forward layers组成。由于其比递归神经网络(RNNs)更具有并行性,所以在大规模训练场景中能够表现出优越性。
值得注意的是,BERT是基于深度双向Transformer的架构。在大规模语言语料库上进行预先训练后,只需添加一个输出层就可以对BERT进行微调,从而可以得到最先进的性能。
Transformer背后的假设是,序列内关系可以通过Self-Attention自动捕获。然而,在实践中,Self-Attention层是否能够学习到输入Tokens之间的合理依赖关系是值得怀疑的。
许多研究者试图分析Attention机制所产生的Attention Map,Raganato等人分析了机器翻译的Transformer模型,并表明一些Attention Heads能够隐式地捕捉某些关系:较低的层倾向于学习更多的语法,而较高的层倾向于编码更多的语义。
Tang等人提出,Transformer模型引导句法关系的能力比递归神经网络模型弱。Tay等人认为,显式的Toeken-Token交互并不重要,提出用合成的Attention Map取代点积的Attention。
此外,关于Attention机制提供的中间表征是否有助于解释模型预测的原因也存在争论。
总之,现有Attention注意机制引导的Attention Map不够好。此外,有尝试结合卷积和Self-Attention层来丰富图像和文本表示。然而,本文的工作是第一批将Attention Map作为多通道图像,并利用专门的深度神经网络进行pattern extraction和evolution。
Transformer的另一个局限性在于它禁止对长序列进行建模,因为内存和计算复杂度都是序列长度的二次函数。为了解决这一问题,Reformer采用了2种技术来提高Transformer的效率:
利用位置敏感哈希来修正点积Attention;
用Reversible Layer代替Residual Layers。
此外,Gehring等人利用一种完全基于卷积神经网络的结构进行序列到序列学习,其中非线性的数量是固定的,与输入长度无关。Parmar等人将独立的Self-Attention层应用于图像分类,将Attention操作限制在像素的局部区域内。Vision Transformer(ViT)将图像分割成一系列的小块,并利用一种尽可能接近Text-Based Transformer的架构。
此外,还有其他的研究方向,包括相对位置表示、远距离信息的自适应掩码、基于树的Transformer和基于自动进化的Transformer。而这些工作与本文正交,他们中的大多数都可以受益于本文所提出的Evolving Attention Mechanism。
3 Evolving Attention Transformer
3.1 Overview
这里文本序列的表示可以写成 ,其中 为序列长度, 为维数大小。
对于图像表示,传统的形状为 ,其中 、 和 分别表示图像的高度、宽度和通道大小。
为了将一个标准的Transformer应用到图像表示中,将其形状Reshape为 ,其中 ,每个像素作为Transformer模型中的单个Token。
一个标准的Transformer由一个Self-Attention层和2个位置上的前馈层组成。Attention Map是由每个Self-Attention层单独生成的,彼此之间没有明显的交互作用。然而,独立的Self-Attention层并没有很好的泛化能力来捕获Token之间的底层依赖关系。
因此,本文采用了一个残差卷积模块,在继承前一层知识的基础上,对当前层的Attention Map进行泛化。该机制被命名为Evolving Attention(EA)。
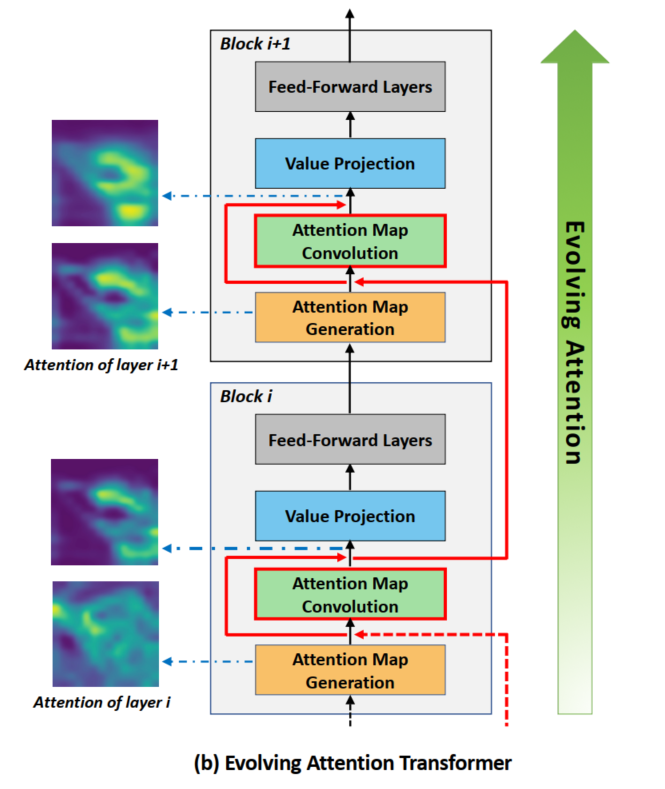
图2(b)说明了通过不断Evolving Attention而增强的Transformer架构。每一个发展Evolving注意(EA-) Transformer块由四个模块组成,包括Attention Map生成、Attention Map卷积、Value投影和前馈层。Attention Map之间的残差连接(红线突出显示)是通过一些正则化效果来促进Attention信息流的设计。
注意,为了简洁起见,在图中省略了Norm层。
3.2 Attention Map生成
给定输入表征 ,可以计算出如下Attention Maps:首先,通过linear projections计算每个Attention Head的query和key矩阵,即 ,其中 和 分别表示query矩阵和key矩阵, 和 为linear projections参数。然后,通过缩放dot-product运算得到Attention Maps:

这里
表示Attention Map,
是隐藏维度大小。为了将顺序信息注入到模型中,在输入表示中加入了位置编码。位置编码可以是绝对的,也可以是相对的,本文遵循每个baseline模型的原始实现,把绝对位置嵌入直接添加到嵌入
的Token中;对于相对位置表示,Attention公式可以改写为:
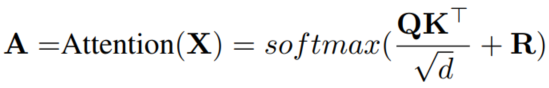
其中
为相对位置编码矩阵。对于文本数据,有
,其中
是2个Token的相对索引的可训练嵌入向量。对于图像数据,采用了高度和宽度2个独立的嵌入向量:

其中
为第
个像素的query表征,
和
分别为高度和宽度的可训练嵌入向量,
和
为第
个和第
个像素的高度indices,
为宽度indices。
3.3 Attention Map卷积
在vanilla Transformer中,每一层的Attention Map都是独立计算的,彼此之间没有显式的互动。
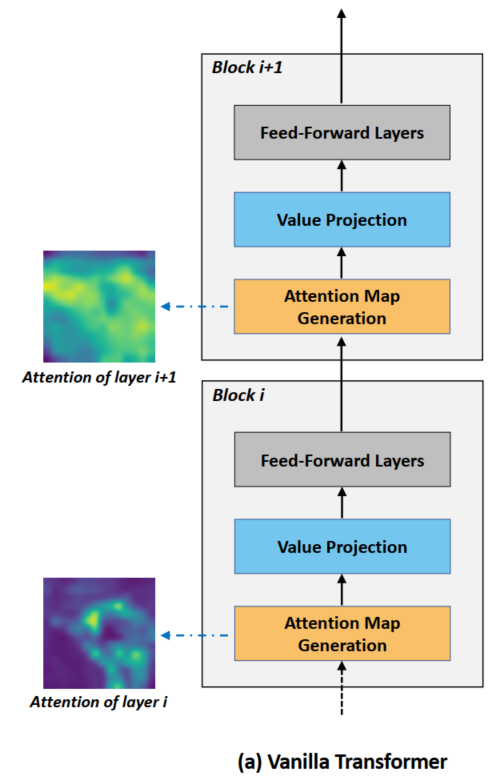
相反,在EA-Transformer中在相邻的Attention Map之间建立了显式的skip connections。假设每一层有K个正面。然后有K个从Attention Map Generation模块输出的Attention Map,它们构造一个张量
(
是序列长度),它可以被视为一个有
个通道的
图像。以此作为输入,并采用一个具有
核的卷积层来泛化Attention Map。输出通道也设为
,因此可以共同生成所有Attention Map的head。在每个卷积层之后应用ReLU激活来提供非线性和稀疏性。最后,将结果Attention Map与输入相结合并输入到softmax激活层:

其中
为前一block的Attention
矩阵;
是由当前Self-Attention块计算的
矩阵,遵循不含softmax的方程(2);
输入是残差连接后的组合矩阵,作为卷积模块的输入。
CNN为带有ReLU激活的卷积层。 是线性组合的超参数。在实验中,作者根据经验在每个任务的验证集上选择 和 值。
3.4 Value映射和前馈层
给定Attention Map A,EA-Transformer block的其余部分value projection和position-wise Feedforward Layers。value projection层可表示为:

其中
为第k个head的Attention Map,
为value projection参数,
为value projection生成的对应表征。然后将所有head的表征串接起来(表示为
)送入参数为
的线性projection层。最后,采用2层位置前馈的方法实现:

通常Bottleneck结构,
的维数是
和
两者的4倍。
3.5 Decoders卷积
在sequence to sequence的Transformer网络中,有3种Attention,即Encoder Self-Attention、Decoder Self-Attention和Encoder-Decoder Attention。对于Encoder网络采用了标准卷积,其中考虑了滑动窗口中周围的像素。对于Decoder部分,需要一个不同的卷积策略来防止预测后续的位置。
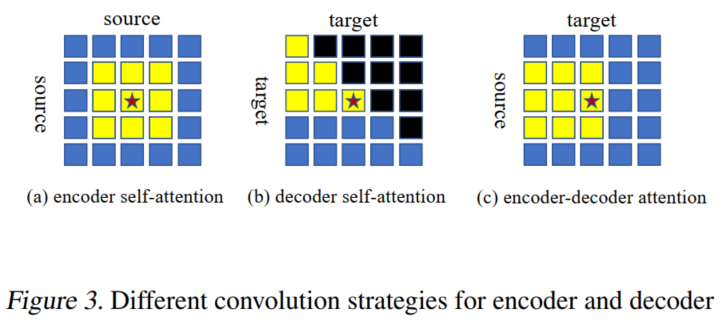
在图3中,可视化了3种Attention Map的卷积策略,其中当前Token是由一个星形标识的。黄色像素被卷积考虑,而其他像素不包括在内。
如图3(b)所示,Decoder Self-Attention在卷积中只取左上角的像素。右上角的像素(黑色)被永久屏蔽,而其他像素(蓝色)不为当前Token计算。这就产生了一个6×6的卷积核,其实现方式如下:
在右上角为Mask的Map中使用标准的3×3卷积;
卷积后,将整个Attention矩阵向下移动1个像素,向右移动1个像素。
如图3(c)所示,为了防止信息泄露,Encoder-Decoder Attention只取卷积核中左边的像素。这可以通过一个标准的3×3卷积向右移动1个像素来实现。
4. 实验
4.1 图像分类

如表1所示,AA-ResNet的表现始终明显优于相应的ResNet。在AAResNet-34、-50、-101和-152的基础上,EA-AA-ResNets的Top-1准确率分别提高了1.21%、0.67%、0.80%和0.67%。
4.2 自然语言理解
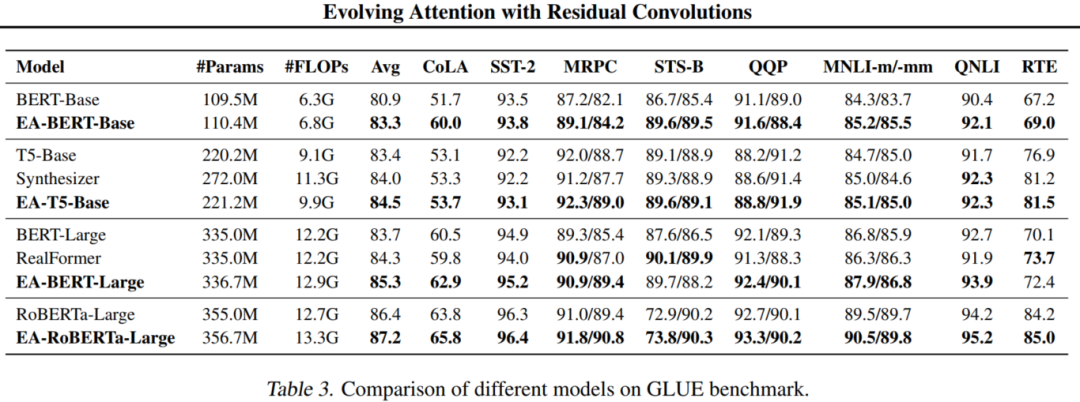
BERT-style模型的比较如表3所示。T5-Base和BERT-Large型模型在development set上进行评估,以便与现有Baseline进行比较。其他模型在测试集上进行评估。在不同的下游任务中,EA-BERT比vanilla BERT表现更好。其中,EA-BERT-Base、EA-T5-Base、EA-BERT-Large和EARoBERTa-Large在GLUE基准上的平均得分分别为83.3、84.5、85.0和87.2,比相应Baseline分别增加了2.4、1.1、1.6和0.8个百分点。这种改进可以通过加载现有的检查点并在有限的训练时间内微调额外的参数来实现。
4.3 机器翻译

Transformer-Lite是一个轻量级架构,所有维度都设置为160,以取代bottleneck结构。Transformer-Base编码器为6层,解码器网络为6层。它有8个head,512维的normal层,2048维的第1层FFN以形成bottleneck结构。如表5所示,EA-based模型在只需要少量额外参数和计算的情况下,对多个数据集和网络架构实现了一致的改进。
4.4 可视化分析

图4显示了ImageNet分类的3个范例案例,其中显示了来自16、17和18层代表性head的Attention Maps。这些层位于网络的中间,对应于一个适当的可视化抽象层。
值得注意的是,AA-ResNet更倾向于提取广泛和模糊的注意力模式。而EA-AA-ResNet则产生了更清晰的Attention Map,并且在3个连续的层次上存在明显的演化趋势。
对于滑雪者的案例,Attention Map成功地捕获了第16层的主要目标。然后,在evolving attention的帮助下,轮廓在第17层变得更加清晰。最后,对第18层进行了进一步的改进,它识别出了一个完整的滑板。其他案例也显示了类似的现象。
5 论文PDF下载
[1].Evolving Attention with Residual Convolutions
后台回复:0301,即可下载上述论文PDF
后台回复:Transformer综述,即可下载两个最新的视觉Transformer综述PDF,肝起来!
点击下方卡片并关注,了解CV最新动态
重磅!CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer方向 微信交流群,也可申请加入CVer大群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,才能通过且邀请进群

▲长按加微信群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看!![]()















 8065
8065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









