






摘要: 当把Transformer中的LSA替换为DwConv/动态滤波器时仍可取得相近,甚至更优的性能,本文对此进行了深入挖掘并得到了影响LSA性能的两个关键因素,提出了增强版ELSA。挖掘发现:空域注意力的生成与应用是其根因,即相对位置嵌入与近邻滤波器应用是关键因素 。基于上述发现,我们采用Hadamard注意力与Ghost头提出了增强版局部自注意力ELSA:
- Hadamard注意力通过引入Hadamrd乘积以更高效的生成注意力 同时保持高阶映射关系;
- Ghost头则对注意力与静态矩阵进行组合以提升通道容量。
实验结果表明:采用ELSA直接替换SwinTransformer中的LSA即可取得1.4%的性能提升。ELSA同样有助于VOLO性能提升,其中ELSA-VOLO-D5取得了87.2%的top1精度且无需额外训练数据。ELSA可以提升基线模型在COCO数据集的性能1.9boxAP/1.3maskAP,在ADE20K数据集的性能1.9mIoU。
ELSA译文
Abstract
自我注意在建模长期依赖关系方面具有强大的能力,但在局部精细级特征学习方面却存在不足。局部自注意LSA (local self-attention, LSA)的性能与卷积(convolution)相当,但不如动态过滤器(dynamic filter),这给研究者们带来了一个难题,即使用LSA还是使用它的对等物,哪一种更好,以及是什么原因使LSA表现不佳。为此,我们从信道设置和空间处理两个方面对LSA进行了全面的研究。我们发现问题在于空间注意的产生和应用,其中相对位置嵌入和邻近滤波器的应用是关键因素。基于这些发现,我们提出了具有hadmard注意和鬼头的增强局部自我注意(ELSA)。Hadamard注意在保持高阶映射的前提下,引入了Hadamard乘积来有效地引起邻域注意。Ghost head鬼头结合注意地图和静态矩阵来增加通道容量。实验证明了该方法的有效性。在不修改体系结构/超参数的情况下,drop-in用ELSA替换LSA将Swin Transformer[48]的top-1精度提升至+1.4。在D1到D5期间,ELSA也始终使VOLO[83]受益,ELSA-VOLO-D5在ImageNet-1K上无需额外的训练图像即可达到87.2。此外,我们评估了ELSA在下游任务中的作用。ELSA显著提高了基线,在COCO上提高了+1.9框Ap / +1.3掩码Ap,在ADE20K上提高了+1.9 mIoU。
1. Introduction
从上游到下游的视觉任务,视觉transformers [3,22,35,59,62,89]通过实现有希望的结果,掀起了一场革命。在这一成功的背后,多头自我注意(MHSA)发挥了关键作用,它生成的注意力映射动态聚合空间信息,具有更大的灵活性和更大的容量。最近的研究[55,82]表明多头自我注意multihead self-attention(MHSA)倾向于关注视觉变压器前几层的局部信息。几种方法[11,17,83,87]引入感应偏差,迫使前几层嵌入局部细节,提高了视觉transformers的泛化能力。作为其中的代表,SwinTransformer[48]为MHSA带来了局域性,并在广泛的视觉任务上取得了很大的进展。

图1所示。Swin-T[48]体系结构的不同层比较。在Swin-T中,局部自注意(LSA)的效率低于深度卷积(DwConv)。其top-1精度也不如DDF等动态滤波器[92]。在使用相同数量的参数和FLOPs作为LSA的情况下,我们的ELSA有很大的优势超过这些同行。
然而,在Swin Transformer中出现了一个奇怪的现象。当用深度卷积(DwConv)[13,37]或动态滤波器替换SwinTransformer中的局部自注意(LSA)时,可以获得类似的性能。如图1所示,我们将swin- t[48]中的LSA替换为DwConv和解耦动态过滤器DDF[92]。LSA的top-1精度与DwConv相似,低于DDF,但需要更多的FLOPs(浮点运算)。这一现象也在最近的论文中被观察到[17,25,32,83],但他们缺乏对这种现象背后原因的详细分析,这促使我们提出一个问题:是什么让局部的自我关注平庸?
为了回答这个问题,我们彻底回顾了LSA,从信道设置和空间处理两个关键方面介绍了动态滤波器。
- 通道设置。DwConv和LSA之间的一个直接区别是通道设置。DwConv对不同的通道应用不同的过滤器。LSA采用多头策略,在每组信道中共享过滤器(即注意图)。在本文中,我们将DwConv的信道设置作为多头策略的一种特殊情况,其中头数设置为信道数。一种猜测是,DwConv中更多的头可能是其性能与LSA相比较的关键因素。但是,我们的实验表明,即使我们将DwConv的头数设置为与LSA的头数相同,DwConv仍然可以达到与LSA相似甚至更好的准确性。我们还发现,直接增加LSA的头数并不能提高LSA的性能。
- 空间处理。如何获取和应用过滤器(或注意映射)来收集空间信息是DwConv、动态过滤器DDF和LSA之间的另一个区别。DwConv以滑动窗口的方式在所有特征像素之间共享静态过滤器。动态滤波器DDF[39,42,66,83,92]采用旁路网络,通常是1x1卷积,生成特定于空间的滤波器,并将这些滤波器应用到每个像素的邻近区域。LSA通过查询矩阵和密钥矩阵的点积生成注意图,这也是一种特定空间的过滤器。LSA将这些注意映射应用到本地窗口。
本文将上述三种空间处理方法统一为一种范式,并从参数化、规范化 和 过滤器的应用三个方面对它们进行了比较深入的研究。结果表明,相对位置嵌入和邻近滤波器的应用是影响性能的两个关键因素。然而,在相邻情况下计算查询和键的点积在计算上并不友好。在相邻情况下,需要一种有效的滤波器生成方法来替代点积,同时保持性能。
基于这些发现,我们提出了增强的局部自注意模块(ELSA)来更好地嵌入局部信息。ELSA由Hadamard注意力和ghost head鬼头模块组成。
- 在Hadamard注意力中,我们用更多的Hadamard乘积代替点积。在保持高阶映射的同时,在相邻情况下更易于计算。
- 该ghost head将注意力和静态鬼头矩阵相结合,有效地提高了信道容量和性能。我们在SwinTransformer [48]/VOLO[83]中通过drop-replace LSA/Outlooker[83]来验证ELSA的性能。在不改变其他部分的体系结构/超参数的情况下,ELSA大大提高了Swin Transformer和VOLO的性能,同时引入了很少的开销。此外,我们还证明了ELSA在下游对象检测方面的优越性能。
简而言之,我们在这方面做出了以下贡献工作:
- 广泛调查LSA及其对等物,以实证揭示是什么因素导致LSA表现平庸。
- 提出增强的局部自我注意(ELSA),通过引入Hadamard注意力和ghost head鬼头,更好地嵌入局部细节。
- 在上游和下游任务中验证ELSA。在drop-in replacement中使用ELSA始终如一地提高了基线方法。
2. Related Work
Vision Transformers
Transformer[65]首先在NLP任务中提出,并取得了主导性能[1,20]。最近,开创性的工作ViT[22]成功地将纯基于变压器的架构应用于计算机视觉,揭示了Transformer在处理视觉任务方面的潜力。提出了大量的后续研究[4、5、9、12、18、21、23、24、27-29、31、38、41、43、45、50、52、56、76、77、80、81、84]。许多学者对ViT进行分析[15,17,26,32,44,55,69,73,75,82],并通过引入局部性对早期地层进行改进[11,17,48,64,79,83,87]。特别是,Raghu等人[55]观察到vit的前几层主要关注局部信息。Li等人[82]也证明了前几层嵌入了局部细节。Xiao等[75]和Wang等[68]发现引入诱导偏置,如引入卷积干,可以稳定训练,提高vit的峰值性能。同样,Dai等人[17]将卷积与vit结合起来,提高了模型的泛化能力。作为一个里程碑,Swin Transformer[48]还利用本地自关注(LSA)将详细信息嵌入到高分辨率精细级特性中。尽管取得了这些成功,但一些研究[17,25,32,83]观察到LSA的性能在上下游任务[32]中都与卷积相当。这一现象背后的原因尚不清楚,同样条件下的深入比较是有价值的。
Dynamicfilters
卷积和深度卷积DwConv[13]在cnn中得到了广泛的应用[34,36,37,57,60],但它们的内容不确定性限制了模型的灵活性和容量。为了解决这一问题,动态滤波器相继被提出。一种动态过滤器[10,51,78,88]预测了组合几个专家过滤器的系数,然后在所有空间像素之间共享这些过滤器。另一种动态过滤器[7,39,42,58,66,67,83,92]生成特定空间的过滤器。具体来说,动态过滤网络[39]使用独立的网络分支来预测每个像素处的完整过滤器。PAC[58]在自适应特征上使用一个固定的高斯核来修改每个像素处的标准卷积滤波器。DRConv[7]将CondConv[78]扩展到每个像素。CARAFE[66]和CARAFE++[67]是上采样和下采样的动态层,在每个像素上预测一个通道共享2D滤波器。类似地,Involution[42]将类似carafe的结构应用于特征提取。VOLO[83]引入了outlook来嵌入本地细节。DDF[92]将动态滤波器与空间滤波器和信道滤波器解耦,在实现有希望的结果的同时减少了计算开销。在本工作中,我们观察到动态过滤器,如DDF[92],其性能优于LSA。在比较和讨论的基础上,我们实证地揭示了导致这种现象的因素,并提出了增强局部自注意(ELSA)来更好地嵌入局部细节。
3. Channel Setting
为了弄清楚是什么让LSA变得平庸,我们首先关注DwConv和LSA最明显的区别之一,即通道设置。深度卷积DwConv对每个通道应用不同的过滤器。不同的是,一些动态过滤器[42,66,83]和LSA采用多头策略,将信道分成多个组,在每个组内共享同一个过滤器。在本文中,我们将DwConv的设置作为多头策略的一种特殊情况,其中头数等于信道数。因此,比较LSA和DwConv的信道设置,实质上是考察不同头数的性能。
图2显示了ImageNet-1K数据集上的调查结果。我们在相同的超参数下比较了两个版本的Swin-T[48],每次只修改头部设置。设置1意味着所有图层的头部数量都设置为1。
- 设置1×表示swin-T的初始设置,即设置四个阶段的头数为{3、6、12、24}。
- 设置2×表示将原设置加倍,即{6、12、24、48}。
- 设置C表示头数设置为所有层的通道数。
 图2。调查不同的通道设置。为了进行公平比较,每次只改变head的数量。
图2。调查不同的通道设置。为了进行公平比较,每次只改变head的数量。
在C选项下,LSA版本内存不足。
有人猜测,在DwConv版本中,更多的头可以增加信道容量,因此可能会导致相当的性能。但是,我们发现在相同的信道设置下,如1x和2x,DwConv版本仍然达到了与LSA版本相似的性能。DwConv的版本甚至超过了设置为1时的LSA 1版本,说明通道设置并不是导致这种奇怪现象的根本因素。
此外,我们观察到,设置超过1x的头对LSA版本没有好处。一个可能的原因是,对于每一代的头,更多的头导致更少的通道。因此,直接增加磁头的数量并不能提高信道容量或性能。需要一种新的策略来进一步提高信道容量和准确度。
4. Spatial Processing
由于通道设置不是关键因素,我们从空间加工的角度寻求答案。DwConv、动态滤波器和LSA采用不同的策略来收集空间信息。我们首先回顾这些策略,并将其统一为一个范例。然后,从三个方面对这些策略进行比较。
4.1. Formulation
Conv / DwConv。Conv和DwConv不生成过滤器。它们通过滑动窗口共享静态卷积滤波器。它们的空间处理可以写成
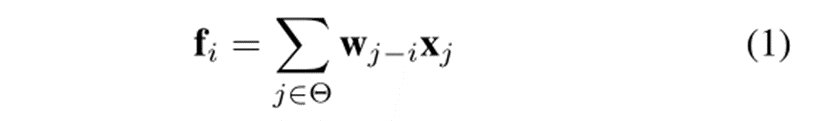
其中,fi表示像素i处的输出,xj表示像素j处的输入,wj−i为滤波器权值,j−i为像素j与i之间的相对偏移量。以尺寸为3的滤波器为例,j−i对应{(−1,−1),(−1,0),(−1,1),…,(1,1)}。Θ表示像素i周围的相邻区域。
Dynamicfilters。动态过滤器[42,66,83,92]通过旁路网络在每个像素上生成特定空间的过滤器。以Involution[42]为代表,它使用一个1x1的卷积来在每个像素上生成过滤器,并将其应用到该像素的邻近区域。它可以写成
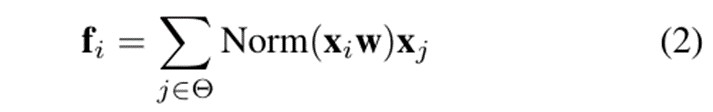
LSA。与动态过滤器不同,LSA使用本地窗口的注意映射作为特定空间的过滤器。就公式而言,LSA可以写成
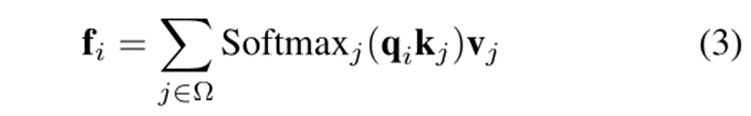
其中qi、kj、vj分别是像素I和像素j处的查询/键/值向量。它们是通过线性映射从输入特征生成的。Ω表示本地窗口区域。这里,为了简单起见,我们省略了多头策略。
Unified paradigm. 为了统一上述策略,我们首先将式2中的w视为一种相对位置嵌入,将式1中的wj−i视为一种相对位置偏差。然后,这些空间加工策略可以统一为一个范式,可以写成
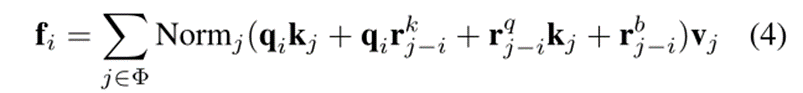
其中Φ可以是本地窗口Ω或邻近区域Θ; Normj可以是标识映射,滤波器归一化,或softmax; rkj−i和rqj−i是相对位置嵌入,rbj−i表示相对位置偏差。
DwConv、动态过滤器和LSA都是这种统一范式的特殊情况。例如,当仅使用rbj−i作为参数化时,利用标识映射作为Normj,并采用邻近区域Θ作为Φ,方程4将退化为DwConv。同理,如果参数化设为qirkj−i, Normj设为恒等式映射,Φ设为邻近区域Θ,则式4为内卷Involution的一个变体,其中rkj−i等于式2中的w。我们还可以通过改变参数化、Normj和Φ,从这个范例中得到LSA。因此,LSA的空间处理在参数化、归一化和过滤应用三个方面存在本质的不同。然后我们通过广泛的比较来研究每个因素。
4.2. Investigation
Parameterization. 我们首先通过将Φ设置为本地窗口,将Normj设置为softmax来比较不同参数化的效果。结果如表1所示。可以看出,在本地窗口应用过滤器时,动态过滤器DDF(Net2)的参数化策略优于标准LSA (Net1)。此外,动态过滤器的一个变种(Net6)与Swin-T中的LSA是相同的。Net7表明,在本地窗口应用过滤器时,将LSA参数化与动态过滤器相结合可以进一步提高性能。

表1. 不同参数化策略的比较。选择Swin-T[48]作为基线。
Acc@1表示准确度最高。†表示报告的结果
Normalization. 规范化是影响空间处理的另一个因素。DwConv和内卷Involution [42]采用恒等映射作为归一化。DDF[92]引入了滤波器归一化。LSA和outlook[83]使用softmax函数进行归一化。
我们在相同的条件下公平地比较这些选项。我们选择表1中的Net7作为基线,每次只更改归一化部分。从表2中可以看出,恒等映射导致训练崩溃,softmax优于滤波器归一化。说明LSA性能不佳不应归咎于归一化部分。更多的比较,请参考附录。

表2. 不同标准化策略的比较。我们只是为了公平比较而切换Net7的标准化。
Filter application. 空间处理的最后一个因素是如何应用滤波器。SwinTransformer中的LSA将注意力映射应用到不重叠的本地窗口。相比之下,DwConv和动态滤波器DDF将滤波器应用于滑动的相邻区域。这种差异可以用公式4中Φ的不同设置来描述。我们选择SwinT、Net6和Net7作为基线。根据控制变量原则,我们在这些模型的前三个阶段只切换Φ。我们用两种方式实现相邻情况Net7(称为Net7- n)。为了节省GPU内存,我们使用SDC[87]来实现它,这样我们就可以像其他节点一样,使用一个节点(8个GPU, 32G GPU内存) 来训练Net7-N。我们也执行了展开版本,但这将消耗大量GPU内存,并需要多个节点进行训练。对比结果如表3所示。当将滤波器应用到邻近区域时,Net6和Net7都得到了明显的改进,说明邻近应用对于空间处理是至关重要的。
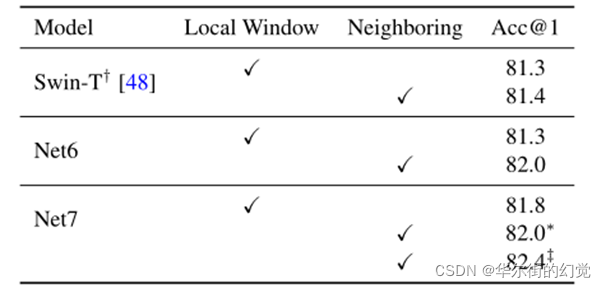
表3.不同过滤器应用的比较。
为了进行公平比较,我们只切换公式4中Φ的设置。
†为[48]中报告的结果。*表示模型采用SDC[87]实现,训练在一个节点上。
‡表示该模型使用展开操作来实现,并在两个节点上进行训练。
4.3. Discussion
Key factors. 基于上述研究,可以将导致LSA性能不佳的因素归纳为两个方面:影响性能的一个关键因素是相对位置嵌入。即使在局部窗口应用过滤器时,具有相对位置嵌入rkj−i和rq j−i的变体(Net5和Net6)也能获得与Swin-T类似的性能。Net7的准确度进一步超过swin-T 0.5%。另一个关键因素是过滤器应用程序。在以查询为中心的相邻区域上应用过滤器可以大大提高Net6和Net7的性能。到目前为止,我们可以根据经验回答我们一开始提出的问题。DwConv能够匹配LSA性能的原因是由于使用了neighborfilter。否则,DwConv退化为Net4的变种,其性能不如LSA。同样,动态过滤器优于LSA的原因是相对位置嵌入和邻接过滤器的应用。将这些因素集成到LSA (Net7-N)中,可以获得所有LSA中性能最好的一种。
Local window v.s. Neighboring. 本地窗口版本的峰值性能低于相邻窗口版本。本地窗口的另一个缺点是,它需要像窗口切换这样的策略来在窗口之间交换信息,这就限制了模型设计在每个阶段都有成对的层。
天下没有免费的午餐。相邻版本的缺点是吞吐量低。在滑动的相邻区域中计算查询和键之间的点积是不容易的。它需要滑动块[?],展开操作,或者专门的CUDA实现,这些要么消耗内存,要么耗费时间。如何在保持良好性能的同时避免点积是一个具有挑战性的问题。
5. Enhanced Local Self-Attention
除了回答我们提出的问题,更重要的是,我们设计了一个新的本地自注意模块,它超越了Swin Transformer中的LSA和动态过滤器。这是通过我们的增强局部自我注意(ELSA)来实现的,其中的关键技术是Hadamard注意和鬼头模块。根据公式,ELSA可以写成:
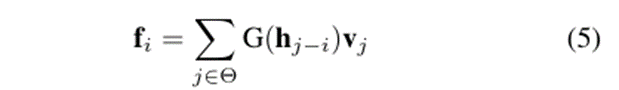
式中,hj−i为Hadamard注意值,G(·)标注鬼头映射,fi为像素i处的输出特征,vj为像素j处的值向量。图3展示了ELSA的整体结构。
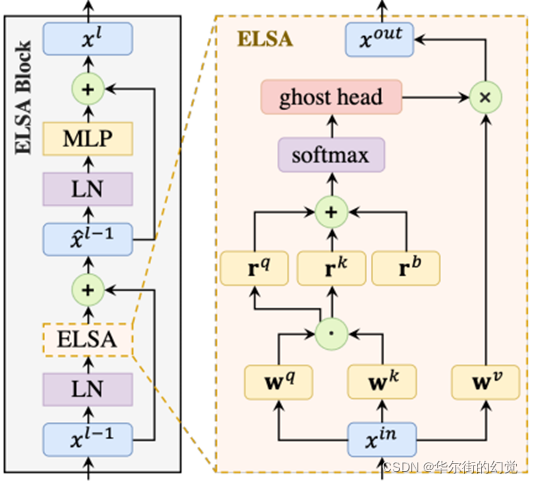
图3. ELSA块示意图。ELSA可以无缝地替代模型中的LSA或动态过滤器。
Hadamard attention. 首先,我们回顾了Net7-N和Net6N,它们在我们的调查中获得了最高和第二高的准确性。如上所述,Net7-N带来了实现和推理方面的困难。在邻近的情况下,Net7-N中的qikj需要使用展开、滑动块[87]或CUDA操作来实现,这些操作要么消耗内存,要么耗费时间。如公式6所示,Net6-N删除了点积项qikj,从而消除了卷积/注意力生成中的困难。
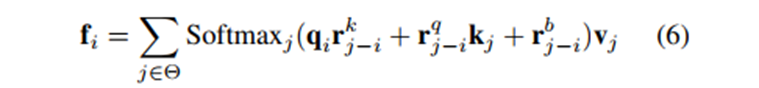
但Net6-N的性能略低于Net7-N。我们发现,Net6-N的较低精度可能是由于较低的映射顺序。具体来说,Net7可以被认为是输入x的三阶映射,因为Net-7包含了二阶项qikj,并将其与值v结合起来。但是,由于Net6-N删除了qikj的点积,它就变成了输入x的二阶映射。
深度学习中一个常见的假设是,高阶映射具有较强的拟合能力[46]。因此,我们希望设计一个模块来维护三阶映射,就像Net7-N一样,但不使用查询和关键矩阵的点积。为了实现这一点,我们提出了Hadamard注意,它在查询和键之间引入了Hadamard乘积作为二阶项。就提法而言,Hadamard注意可以写成:
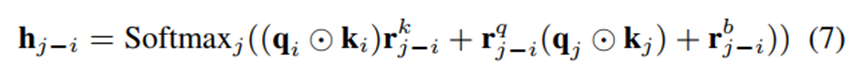
除了三阶表示外,Hadamard注意力很容易实现。不像Net7-N需要内存/耗时操作来计算qikj, qi ?ki和qj ?kj可以通过查询和关键特征映射的简单元素乘法来实现。同样,rkj−i和rq j−i等价于1 × 1个卷积滤波器。因此,方程7可以通过特征相乘和卷积层来实现。更多的实现细节请参考附录和我们的代码。
Ghost Head. 在第3节中,我们揭示了头的数量和模型性能之间的关系。虽然信道设置并不是影响性能的最关键因素,但是图2中更多信道容量更好的磁头仍然会略微提高dwconvw-swin-t的性能。由于直接增加LSA的头数不会带来任何收益,我们提供了另一种廉价而有效的增加信道容量的方法。在GhostNet[30]的驱动下,我们提出了鬼头模块,它将原始的鬼头与两个静态矩阵相结合进行扩展,表示为:
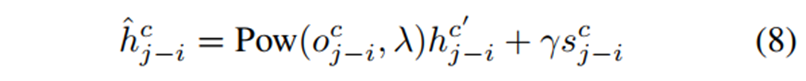
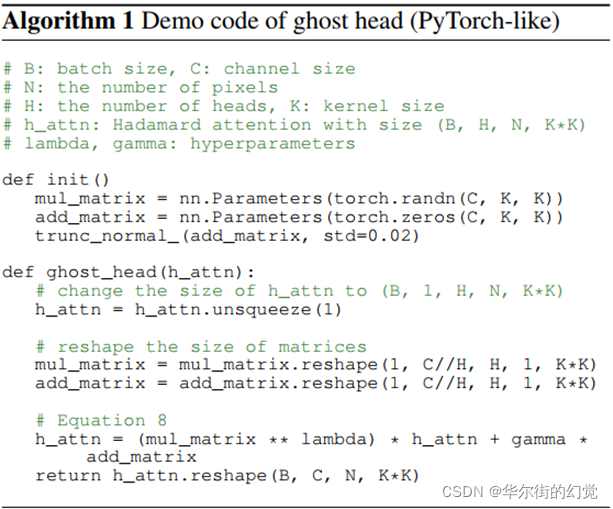
hcj−i / ˆhcj−i∈R为鬼头模块前后的Hadamard注意值,位于c0 / c-th通道,对应于相对偏移量j−i;c与c’的关系为c’ = c%nh,其中nh为正面次数,%为mod运算; O, S∈Rnc×ks×ks是两个静态矩阵,Ocj−i、Scj−i为相对偏移量j−i在第c个通道上对应的O、S中的值; Pow(·)是幂运算,λ、γ是两个超参数。鬼头的演示代码总结在算法1中。在实际实现中,我们编写CUDA操作,以避免GPU内存消耗过大。

鬼头是一个便宜的模块。其开销仅为O(nc×ks×ks×np),其中nc为通道数,ks为滤波器大小(即相邻区域的大小),np为像素数。最近,Refiner[91]也提出在softmax之后调整注意事项。与它们不同的是,幽灵头不利用复杂的卷积和线性映射,而是只使用两个简单的静态矩阵。还有,鬼头的主要目的不是提炼注意力,而是丰富渠道容量。
6. Experiments
我们在Swin-Transformer和VOLO架构中评估了ELSA,包括ImageNet-1K图像分类[19]、COCO对象检测[47]和ADE20K语义分割[90]。对于Swin Transformer[48],我们在不改变任何架构/超参数的情况下,用ELSA替换LSA。对于VOLO[83],我们调整了ELSA块的几个超参数,而其他部分保持不变。
6.1. Image Classification on ImageNet-1K
Settings 我们的主要评估是在ImageNet-1K[19]数据集上进行的。在训练过程中,不使用额外的训练图像。我们的代码基于Pytorch[53]、timm[72]、DDF[92]、Swin Transformer[48]和VOLO[83]。详细的设置如下。
Swin-Transformer. 我们将前三个阶段的LSA块替换为我们的ELSA块,并在[48]之后训练ELSA-swin。特别是,选择了AdamW[49]作为优化器。基础学习率设置为1e-3,按照线性策略缩放,即lr = lrbase×(batch_size/1024)个批量,按照余弦策略衰减。我们为310个epoch训练模型,其中前20个epoch用于热身,最后10个epoch用于冷却。使用了5e-2的重量衰减。我们还利用了与Swin-Transformer [48]相同的增强和正则化策略。ELSASwin-B训练采用指数移动平均(EMA)[54,61]。所有模型都是在224x224分辨率上训练/评估,除非另有说明。
VOLO. 我们用ELSA替换VOLO中的所有outlook模块。我们按照VOLO的培训协议对ELSA-VOLOs进行培训。VOLO的大多数设置与Swin Transformer的设置相似,除了以下不同之处。VOLO-D1的基础学习率为1.6e-3, VOLO-D5的基础学习率为8e4。训练时使用Token标记[40],因此MixToken[40]代替了MixUp[86]和CutMix[85]。EMA用于ELSA-VOLO-D5训练。详见[83]。
Ablation study. 我们分别分析了Hadamard注意和鬼头模块在ELSA中的作用。我们选择Swin-T[48]作为我们的基础架构,并对ELSA进行了不同的修改。消融实验结果如表4所示。在Hadamard的关注下,swin-t的性能提高了1.1%。通过插入鬼头,我们观察到另一个0.3%的改善。
表5进一步比较了Swin Transformer和VOLO上不同类型层的性能。可以看出,Swin-T和VOLO-D1结合ELSA的top-1准确率分别达到82.7%和84.7%,优于其他同类。
Compare with the state-of-the-art models.
ELSA-Swin和ELSA-VOLO与其他最先进的模型见表6。#Res表示在验证/微调中使用的分辨率。为了进行公平的比较,根据参数的数量将结果分成若干组。
可以看到,对于不同的模型尺寸,我们提出的ELSA一致地提高了Swin Transformer和VOLO,同时引入了很少的开销。特别是,ELSA提高了Swin-T、Swin-S和Swin-B的1.4%、0.5%和0.5%,其中ELSA-Swin-S与原始的Swin-B相比,参数和FLOPs都增加了三分之二。在224分辨率上,ELSA-VOLO-D1和ELSAVOLO-D3的top-1准确率分别为84.7%和85.7%。ELSA-VOLO-D3的性能与原VOLO-D4的性能相匹配。但是,对于ELSA-VOLOD3, VOLOD4的开销超过2×参数。在没有附加图像的情况下,由于过度拟合,在监督训练下提高大型模型的准确性是非常困难的。即便如此,ELSA仍能略微改善VOLO-D5。
值得注意的是,所有这些ELSA-Swin的记录都是在没有修改Swin transformer中的任何超参数的情况下获得的,这可能不是我们ELSA的最佳设置。
对于VOLO,我们也保持其他部分的结构和超参数不变。在这种控制变量的原则下,ELSA区块的使用仍然达到了最先进的水平。手动或通过NAS重新设计宏架构/超参数可能会产生更好的Pareto性能。
6.2. Object Detection on COCO
Settings. 在COCO数据集上进行了目标检测和实例分割实验。我们报告验证子集上的性能,并使用平均精度(AP)作为度量。我们在Mask RCNN / Cascade Mask RCNN中评估ELSASwin[2,33],这是在[6,70,71,79,87]中常见的做法。按照通用的训练协议,我们采用多尺度训练,将输入的短边从480缩放到800,而长边不超过1333。采用AdamW[49]作为优化器,初始学习率为1e-4,权值衰减为5e-2,批量大小为16。为了进行公平的比较,所有主干都只使用ImageNet1K进行预训练,并在COCO上用1×时间表(12 epoch)进行微调。我们的实现是基于Swin Transformer[48]和mmdetection[8]。
Results. 表7列出了实验结果。可以看出,ELSA-Swin-T和ELSA-Swin-S(标记为ELSAT / ELSA-S)在检测上分别提高了相应基线1.9 AP和1.8 AP,均优于组内其他方法。请注意,与ViL[87]和RegionViT[6]不同,ELSA-Swin不修改Swin Transformer的宏架构/超参数。带有ELSA-Swin-T和ELSA-Swin-S的级联掩码RCNNs的检测结果分别为49.8 AP和51.6 AP,分别比基线高1.7 AP和1.3 AP。附录显示了更多与3×调度的COCO数据集的比较。
6.3. Semantic Segmentation on ADE20K
Settings. 我们评估了ELSA-Swin在ADE20K[90]上的语义分割性能,ADE20K包含20K训练、2K验证和3K测试图像,涵盖150个语义类别。在[32,48,83]之后,选择UperNet[74]作为基线框架。在培训过程中,采用了AdamW作为优化器。初始学习速率设置为6e-5,权值衰减设置为1e-2。所有模型都经过160K次线性学习速率衰减的迭代训练,并经过1500次线性预热。我们在mmsegmentation[16]中使用默认的增强设置,其中输入的分辨率设置为512 × 512。在推理过程中,我们采用插值率为[0.75,1.0,1.25,1.5,1.75]的多尺度检验。详情请参考[16,48]和我们的代码。
Results. 表8显示了采用多尺度测试的平均IoU (MS mIoU)、模型大小(Param)和不同方法的FLOPs。根据模型参数的数量将结果分成三组。为了进行公平的比较,所有被比较的骨干都只使用ImageNet1K进行了预训练。带有ELSA-Swin-T的UperNet在MS mIoU上比Swin-T版本高1.9倍。采用ELSA-Swin-S作为骨干达到50.3 MS mIoU, MS mIoU比Swin-S高0.8,甚至优于第三组的Swin-B和twin-svt-l。
7. Conclusions
在本研究中,我们从信道设置和空间处理两个方面详细研究了LSA及其对等物,以从经验上理解LSA性能不佳的原因。结果表明,相对位置嵌入和邻居过滤器的应用是DwConv和动态过滤器性能与LSA相似或优于LSA的关键原因。基于这些观察结果,我们进一步提出了具有Hadamard注意和鬼头的增强局部自我注意(ELSA),它可以无缝地替代LSA及其在各种网络中的对等体。实验表明,在不修改其他体系结构/超参数的情况下,ELSA可以不断地改进基线,而不受模型大小和任务的影响,且开销很小。
Acknowledgements
本研究得到阿里巴巴集团研究实习生计划和国家自然科学基金项目(No.61976094)的资助。
A. Additional Investigation
除了峰值性能外,我们还比较了Filter归一化[92]和softmax的收敛速度。我们选择Net7作为基线,并在表9中显示了不同时期的精度。可以看出,Filter归一化在早期就可以加快模型的收敛速度。但是,由于Filter Normalization中均值为0,方差为1的约束,限制了滤波器的灵活性。因此,在过去的100个时代,带有Filter Normalization的Net7落后于softmax版本。
B. COCO Detection with 3× Schedule
表10列出了3×时间表(36 epoch)的COCO检测结果。可以看出,ELSA-Swin-T(又称ELSA-T)提高基线1.5 box AP / 1.1 mask AP;ELSA-Swin-S(称为ELSA-S)将基线提高0.7 box AP / 0.3 mask AP。它们的box AP都超过了组内的其他对手。带有ELSA-Swin-T和ELSA-Swin-S的级联掩码RCNNs的检测结果分别为51.1 AP和52.3 AP,分别比基线高0.6 AP和0.5 AP。值得注意的是,ELSA-Swin-S版本甚至超过了Swin-B版本。
C. Ghost Head on Global Self-Attention
除了ELSA外,我们还对鬼头应用于全局自我注意时的性能进行了评估。我们选择DeiT-Ti[62]作为基线。我们首先去除DeiT-Ti中的类/蒸馏令牌,并使用全局平均池生成用于分类的特征。然后,我们将鬼头模块应用于softmax后的全局自注意映射。在全局自注意的情况下,鬼头模块只将头的数量增加一倍,而不是将头的数量增加到通道的数量。从表11中可以看出,鬼头模块在top-1精度上也显著提高了3.7%的基线。
我们并没有严格按照式7执行阿达玛注意。阿达玛注意被实现为方程??它更快更好。这里,我们将展示如何以伪代码的形式一步一步地从等式7实现我们的实现。方程7的严格实现如算法2所示,其中使用展开运算来计算qj ?kj。展开操作消耗内存,其主要功能是平移feature map,对齐像素i和j,这样我们就可以直接加qi ?Ki和qj ?kj。我们可以使用深度卷积来移动feature map,而不是展开运算,如算法3所示。
D. Implementation of Hadamard Attention
算法3可以进一步简化,将两个1×1卷积层合并为一层,如算法4所示。注意,算法2、算法3和算法4是完全相同的。通过设置相同的模型参数,可以得到相同的输出。
从算法4中可以看出,式7可以通过特征相乘,然后1×1卷积和群卷积来实现。对于我们的最终实现(方程7的一个变体),我们稍微修改了这些卷积层的序列,并在它们之间添加了一个激活函数(GELU),如所附的代码所示。














 3115
3115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









