






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:新智元 | 编辑:LRS
【导读】注意力机制这么好用,怎么不把它塞到卷积网络里?最近Meta AI的研究人员提出了一个基于注意力的池化层,仅仅把平均池化层替换掉,就能获得+0.3%的性能提升!
Visual Transformer(ViT)作为计算机视觉领域的新兴霸主,已经在各个研究任务中逐渐替换掉了卷积神经网络CNN。
ViT与CNN之间存在着许多不同点,例如ViT的输入是image patch,而非像素;分类任务中,ViT是通过对类标记(class token)进行决策等等。
class token实际上是ViT论文原作者提出,用于整合模型输入信息的token。class token与每个patch进行信息交互后,模型就能了解到具体的分类信息。
并且在自注意力机制中,最后一层中的softmax可以作为注意力图,根据class token和不同patch之间的交互程度,就能够了解哪些patch对最终分类结果有影响及具体程度,也增加了模型可解释性。
但这种可解释性目前仍然是很弱的,因为patch和最后一层的softmax之间还隔着很多层和很多个header,信息之间的不断融合后,很难搞清楚最后一层softmax是否真的可以解释分类。
所以如果ViT和CNN一样有视觉属性就好了!
最近Meta AI就提出了一个新模型,用attention map来增强卷积神经网络,说简单点,其实就是用了一个基于注意力的层来取代常用的平均池化层。

Augmenting Convolutional networks with attention-based aggregation
论文:https://arxiv.org/abs/2112.13692
仔细一想,池化层和attention好像确实很配啊,都是对输入信息的加权平均进行整合。加入了注意力机制以后的池化层,可以明确地显示出不同patch所占的权重。
并且与经典ViT相比,每个patch都会获得一个单一的权重,无需考虑多层和多头的影响,这样就可以用一个简单的方法达到对注意力可视化的目的了。

在分类任务中更神奇,如果对每个类别使用不同颜色进行单独标记的话,就会发现分类任务也能识别出图片中的不同物体。

基于Attention的池化层
文章中新提出的模型叫做PatchConvNet,核心组件就是可学习的、基于attention的池化层。

模型架构的主干是一个卷积网络,相当于是一个轻量级的预处理操作,它的作用就是把图像像素进行分割,并映射为一组向量,和ViT中patch extraction操作对应。
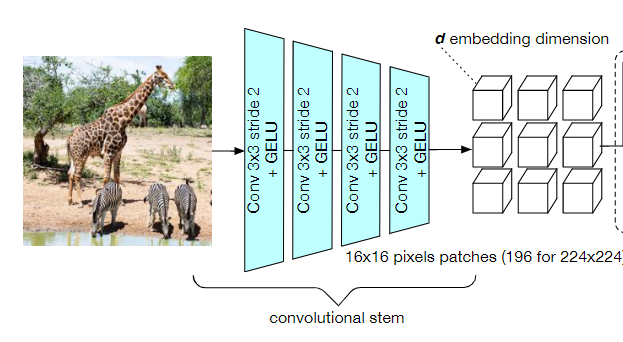
最近也有研究表明,采用卷积的预处理能让模型的性能更加稳定。
模型的第二部分column(主干trunk),包含了整个模型中的大部分层、参数和计算量,它由N个堆叠的残差卷积块组成。每个块由一个归一化、1*1卷积,3*3卷积用来做空间处理,一个squeeze-and-excitation层用于混合通道特征,最后在残差连接前加入一个1*1的卷积。
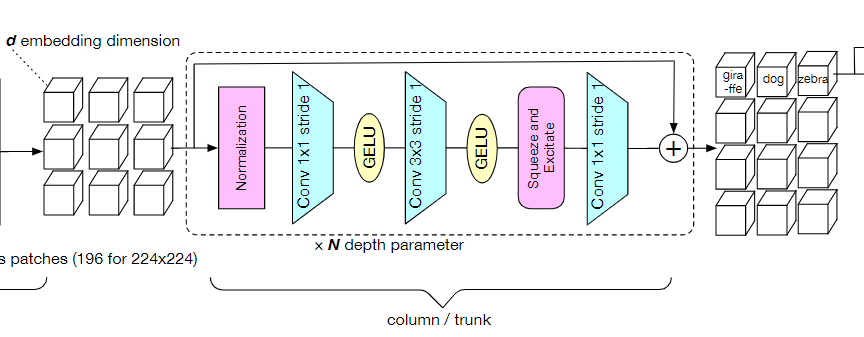
研究人员对模型块的选择也提出了一些建议,例如在batch size够大的情况下,BatchNorm往往效果比LayerNorm更好。但训练大模型或者高分辨率的图像输入时,由于batch size更小,所以BatchNorm在这种情况下就不太实用了。
下一个模块就是基于注意力的池化层了。
在主干模型的输出端,预处理后的向量通过类似Transformer的交叉注意力层(cross attention layer)的方式进行融合。

注意力层中的每个权重值取决于预测patch与可训练向量(CLS)之间的相似度,结果和经典ViT中的class token类似。
然后将产生的d维向量添加到CLS向量中,并经过一个前馈网络处理。
与之前提出的class-attention decoder不同之处在于,研究人员仅仅只用一个block和一个head,大幅度简化了计算量,也能够避免多个block和head之间互相影响,从而导致注意力权重失真。
因此,class token和预处理patch之间的通信只发生在一个softmax中,直接反映了池化操作者如何对每个patch进行加权。
也可以通过将CLS向量替换为k×d矩阵来对每个类别的attention map进行归一化处理,这样就可以看出每个块和每个类别之间的关联程度。
但这种设计也会增加内存的峰值使用量,并且会使网络的优化更加复杂。通常只在微调优化的阶段以一个小的学习率和小batch size来规避这类问题。
实验结果
在图像分类任务上,研究人员首先将模型与ImageNet1k和ImageNet-v2上的其他模型从参数量,FLOPS,峰值内存用量和256张图像batch size下的模型推理吞吐量上进行对比。
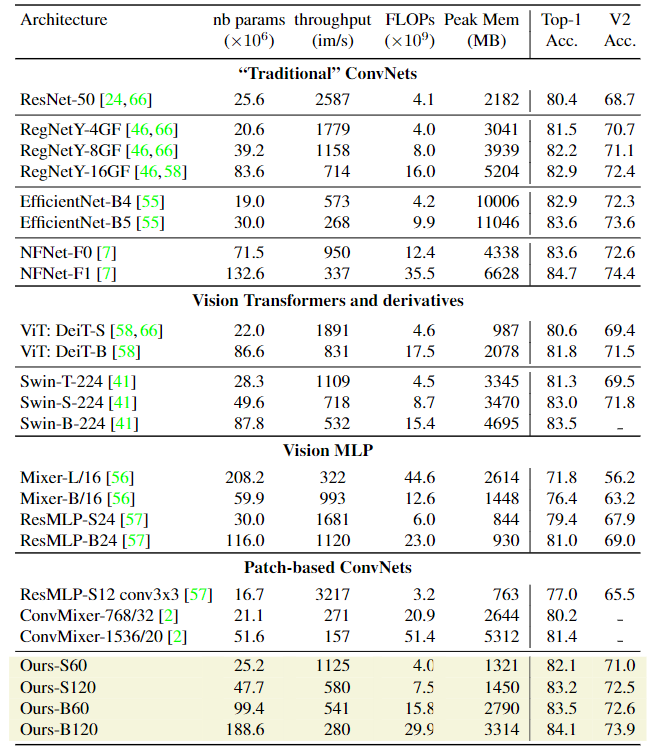
实验结果肯定是好的,可以看到PatchConvNet的简单柱状结构(column architecture)相比其他模型更加简便和易于扩展。对于高分辨率图像来说,不同模型可能会针对FLOPs和准确率进行不同的平衡,更大的模型肯定会取得更高的准确率,相应的吞吐量就会低一些。
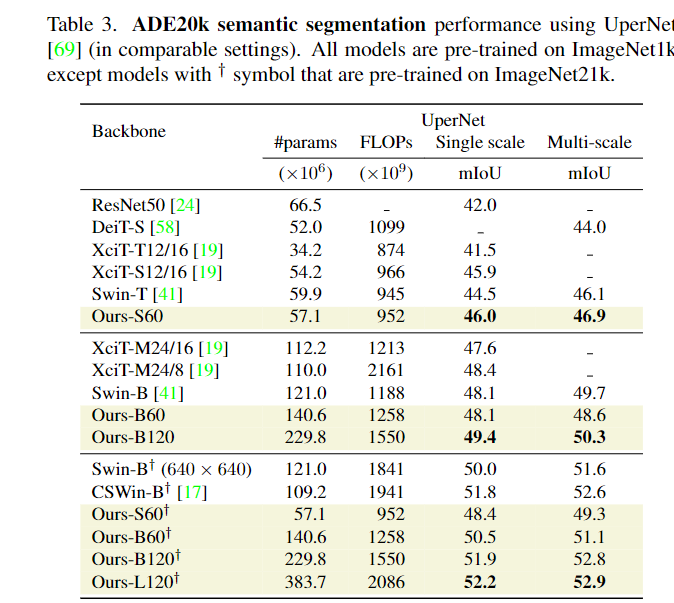
在语义分割任务上,研究人员通过ADE20k数据集上的语义分割实验来评估模型,数据集中包括2万张训练图像和5千张验证图像,标签超过150个类别。由于PatchConvNet模型不是金字塔式的,所以模型只是用模型的最后一层输出和UpperNet的多层次网络输出,能够简化模型参数。研究结果显示,虽然PatchConvNet的结构更简单,但与最先进的Swin架构性能仍处于同一水平,并且在FLOPs-MIoU权衡方面优于XCiT。
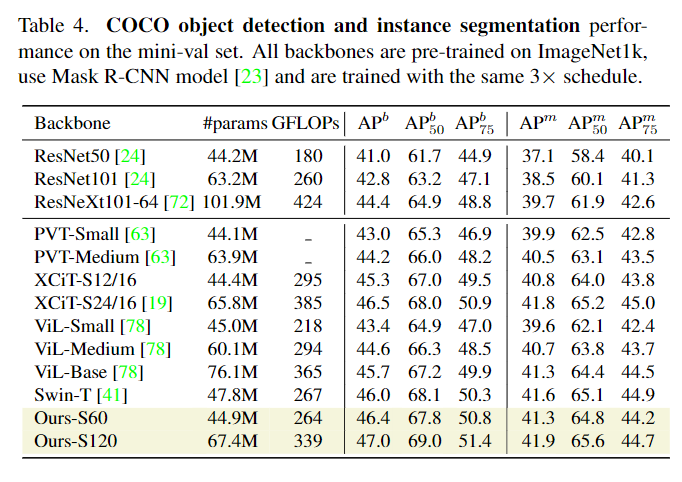
在检测和实例分割上,研究人员在COCO数据集上对模型进行评估,实验结果显示PatchConvNet相比其他sota架构来说,能够在FLOPs和AP之间进行很好的权衡。
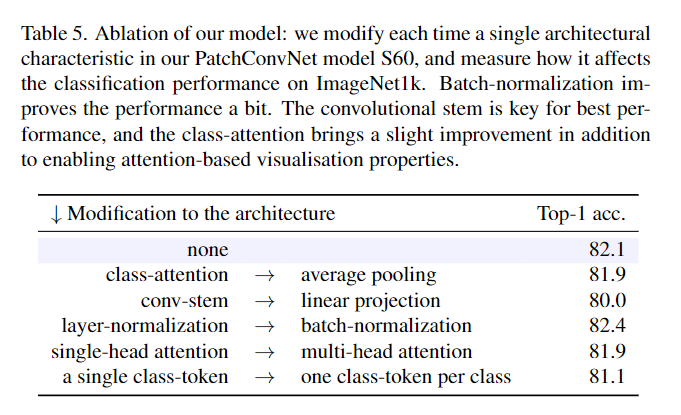
在消融实验中,为了验证架构问题,研究人员使用不同的架构对比了Transformer中的class attention和卷积神经网络的平均池化操作,还对比了卷积主干和线性投影之间的性能差别等等。实验结果可以看到卷积主干是模型取得最佳性能的关键,class-attention几乎没有带来额外的性能提升。
另一个重要的消融实验时attention-based pooling和ConvNets之间的对比,研究人员惊奇地发现可学习的聚合函数甚至可以提高一个ResNet魔改后模型的性能。
通过把attention添加到ResNet50中,直接在Imagenet1k上获得了80.1%的最高准确率,比使用平均池化层的baseline模型提高了+0.3%的性能,并且attention-based只稍微增加了模型的FLOPs数量,从4.1B提升到4.6B。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()















 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









