









 文章提出了一种融合注意力网络DFAN,利用扩张卷积捕获低分辨率图像的多尺度上下文信息,特别是高频分量。DFAN包括扩张卷积注意模块(DCAM)和多特征注意块(MFAB),以增强高频特征的提取,提高超分辨率性能。此方法解决了传统方法中忽略高频信息的问题,且在实验中表现出性能提升。
文章提出了一种融合注意力网络DFAN,利用扩张卷积捕获低分辨率图像的多尺度上下文信息,特别是高频分量。DFAN包括扩张卷积注意模块(DCAM)和多特征注意块(MFAB),以增强高频特征的提取,提高超分辨率性能。此方法解决了传统方法中忽略高频信息的问题,且在实验中表现出性能提升。
Fusing Attention Network Based on Dilated Convolution for Superresolution
(基于扩张卷积的超分辨融合注意力网络)
近年来,具有不同滤波器或多个分支的深度神经网络在单超分辨率(SR)方面取得了良好的性能。然而,它们忽略了低分辨率图像的多尺度上下文信息的高频分量。为了解决这个问题,我们提出了一个融合的注意力网络的基础上扩张卷积(DFAN)SR。具体来说,我们首先提出了一个扩张的卷积注意模块(DCAM),它通过锁定具有不同大小感受野的多个区域,从LR图像的不同区域捕获多尺度上下文信息。然后,我们提出了一个多特征注意块(MFAB),进一步关注多尺度上下文信息的高频成分,并提取更多的高频特征。实验结果表明,所提出的DFAN实现视觉质量评价和定量评价方面的性能改善。
INTRODUCTION
单图像超分辨率(single image superresolution,SISR)旨在从单个低分辨率(LR)图像中恢复出高分辨率(high resolution,HR)图像,广泛应用于医学图像、卫星图像和遥感图像。然而,SISR有一个众所周知的不适定问题,LR图像的细节信息丢失。许多传统的方法来解决这个问题,如双三次插值,最大后验,邻域嵌入、稀疏表示等。
最近,许多基于深度学习的方法已经取得了显着的性能。Dong等人提出了一种具有三层的卷积神经网络(CNN)超分辨率(SRCNN),它实现了从LR图像到HR图像的端到端学习。然而,SRCNN算法难以提取图像的深层信息。然后,Dong等人提出了一种加速超分辨率CNN(FSRCNN),它用反卷积层取代双三次插值以进行上采样。与此同时,Shi等人提出了一种高效的子像素CNN(ESPCN),它使用子像素卷积层来代替反卷积层,进一步降低了计算复杂度。为了进一步提高性能,通过深化神经网络,Ying等人提出了一种深度递归残差网络(DRRN),它使用了残差网络(Resnet)架构。Lai等人提出了一种深拉普拉斯金字塔超分辨率网络(LapSRN),其渐进地预测残差图像并重建HR图像。受密集连接网络(DenseNet)的成功激励,Tong等人提出了一种用于超分辨率的密集跳跃连接网络(SRDenseNet),该网络避免了消失梯度问题,并通过密集跳跃连接加快了训练速度。为了实现更深的卷积网络,Kim等人提出了一种具有20层的非常深的卷积网络超分辨率(VDSR),它使用残差学习来解决深度卷积网络训练过程中的梯度爆炸问题。此外,Kim等人提出了一种用于图像超分辨率(SR)的深度递归卷积网络(DRCN),它还通过多次循环同一层来增加网络的深度。由于Resnet使深度卷积网络的训练变得容易,Lim等人修改了Resnet架构,并提出了一种具有16个残差块和跳过连接的增强型深度残差网络SR(EDSR),通过去除批量归一化和ReLU激活来实现性能改进。
然而,由于上述方法的网络是单流的,当它们通过增加网络的深度来提高性能时,这些方法不能在LR图像的多个上下文尺度上获得各种特征。为了解决这个问题,Ren等人提出了一种用于图像SR(CNF)的融合多CNN,其在各个分支处采用SRCNN。Hu等人提出了通过级联多尺度交叉网络(CMSC)的SR,该网络由具有两个并行分支的子网组成,它集成了不同分支的信息。此外,Li 等人提出了一种用于SR的多尺度残差网络(MSRN),其使用不同的卷积滤波器来提取特征,并通过分层特征融合技术将所有残差块的输出级联。虽然这些方法通过使用不同的滤波器或多个分支来扩展感受野的大小,但它们忽略了LR图像的多尺度上下文信息的高频分量,如边缘和纹理。
为了解决这个问题,我们提出了一种基于扩张卷积的融合注意力网络(DFAN)的SR,它实现了性能的提高,通过捕获多尺度上下文信息的LR图像的许多不同区域,以获得丰富的高频特征。一方面,与通过不同滤波器或多分支获取多尺度上下文信息的网络相比,DFAN通过使用不同膨胀率的3×3滤波器来获取多个不同区域的特征,从而获得更多的多尺度上下文信息。另一方面,与用不同滤波器或多个分支同等对待提取特征的低频分量和高频分量相比,DFAN从LR图像的多尺度背景信息中提取高频分量,得到更多的高频特征。
本文的主要贡献如下:
1)我们提出了一个DFAN用于SR,它捕获多尺度的上下文信息从LR图像的不同区域,并提取高频功能,以实现更好的重建性能。
2)我们提出了一个扩张卷积注意模块(DCAM),它锁定多个区域与不同大小的感受野通过不同的扩张率。DCAM从LR图像的不同区域捕获多尺度上下文信息。
3)我们提出了一个**多特征注意块(MFAB)**的基础上DCAM进一步专注于多尺度上下文信息的高频成分,并提取更多的高频特征。
RELATED WORKS
Dilated Convolution
Yu和Koltun提出了扩张卷积,其通过不同的扩张率来扩大感受野大小。卷积运算 * 定义如下:
扩张卷积操作可以通过不同的扩张速率在不同范围处应用相同的卷积核。因此,扩张卷积扩大了感受野大小而不增加额外的计算复杂度。近年来,扩张卷积引起了越来越多的研究者的关注。Li等人提出了一种用于理解高度拥塞场景的扩张CNN(CSRNet),其使用扩张卷积来代替池化操作。Liu等人提出了一种用于图像去噪的扩张残差卷积网络,该网络在传统3 × 3卷积的基础上使用扩张卷积来捕获文本信息。
虽然扩张卷积网络可以在不增加额外计算复杂度和内存消耗的情况下扩大感受野大小,但它会导致感受野内的盲点。为了解决这个问题,Zhang等人提出了一种用于图像SR的扩张卷积(DCSR),它将标准卷积和扩张卷积相结合以形成混合卷积。混合卷积消除了感受野中的盲点。DCSR使用残差学习来预测HR-LR对的残差,而不是直接的HR预测。DCSR在训练过程中训练单个模型处理不同尺度(×2、×3、×4),并通过扩大感受野大小来捕捉LR图像和HR图像之间的相关性,获得了性能的改善。
Attention Mechanism
注意机制的想法来自人类视觉注意系统,它自动聚焦于最重要的信息。注意机制的本质是关注感兴趣的信息,抑制无用的信息,其结果通常以概率图或概率特征向量的形式表现出来。
近年来,注意机制在图像超分辨率重建中得到了成功的应用。Choi和Kim提出了一种具有SR选择单元的深度CNN,它可以比ReLU更好地处理非线性功能。Kim等人提出了SR的剩余注意力模块,其使用具有全局感受野的通用视差注意力机制来处理不同的立体图像。Zhang等人提出了一种用于SR的非常深的残余通道注意力网络,该网络通过考虑特征通道之间的相互依赖性,使用通道注意力机制来自适应地重新缩放特征。
FUSING ATTENTION NETWORK BASED ON DILATED CONVOLUTION
Network Framework
在这篇文章中,提出了一种DFAN的图像SR。DFAN的框架如图1所示。
DFAN主要由三部分组成:1)特征提取; 2)上采样模块; 3)重建部分。假设ILR和IHR分别表示为输入LR图像和输出HR图像,在开始时,使用一个卷积层(Conv)从输入LR图像提取初始特征图F0

其中f0(·)表示第一卷积层(Conv)的卷积操作,并且F0表示提取的初始特征图。同时,F0用于特征提取。具体地,F0由G个MFAG和一个卷积层(Conv)更新,然后通过全局跳过连接将更新的特征图添加到F0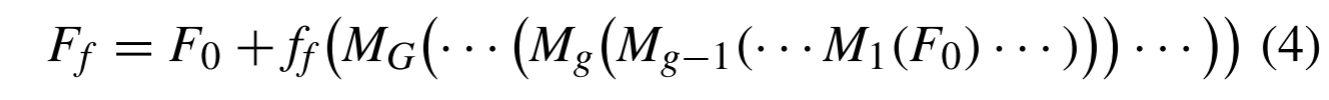
其中Mg(·)表示第g个MFAG的特征提取操作,ff(·)表示中间卷积层(Conv)的卷积操作,并且Ff表示提取的特征图。Ff用于由上采样模块上采样
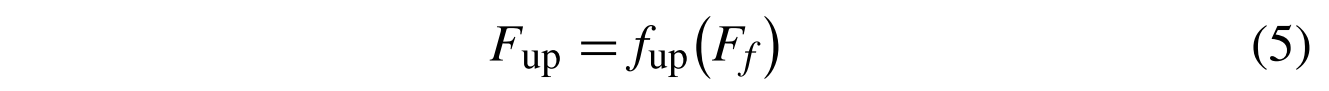
其中fup(·)表示上采样操作,并且Fup表示上采样特征。在本文中,我们使用子像素卷积层作为上采样模块。最后,Fup用于最后一个卷积层的重构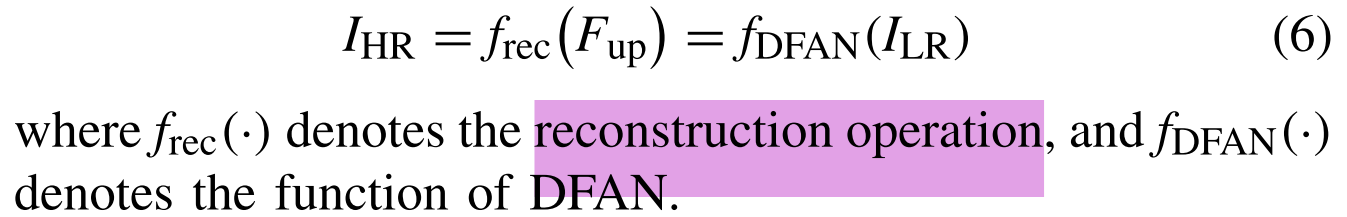

Dilated Convolutional Attention Module
虽然具有不同滤波器和多分支的网络可以获得多尺度上下文信息,但不同滤波器和多分支扩展的感受野的大小是有限的。如果我们想要得到一个大的感受野,我们必须使用尺寸大、网络分支多的滤波器,但这使得网络训练变得困难。相反,如果我们使用较小的尺寸和较少的网络分支的过滤器,这是很难获得多尺度的上下文信息。因此,在本文中,我们提出了一个DCAM。DCAM使用具有不同膨胀率的3 × 3滤波器,其具有不同大小的感受野,以捕获多个不同区域的多尺度上下文信息。
DCAM的结构见图2。其由不同的扩展卷积注意块(DAB)组成。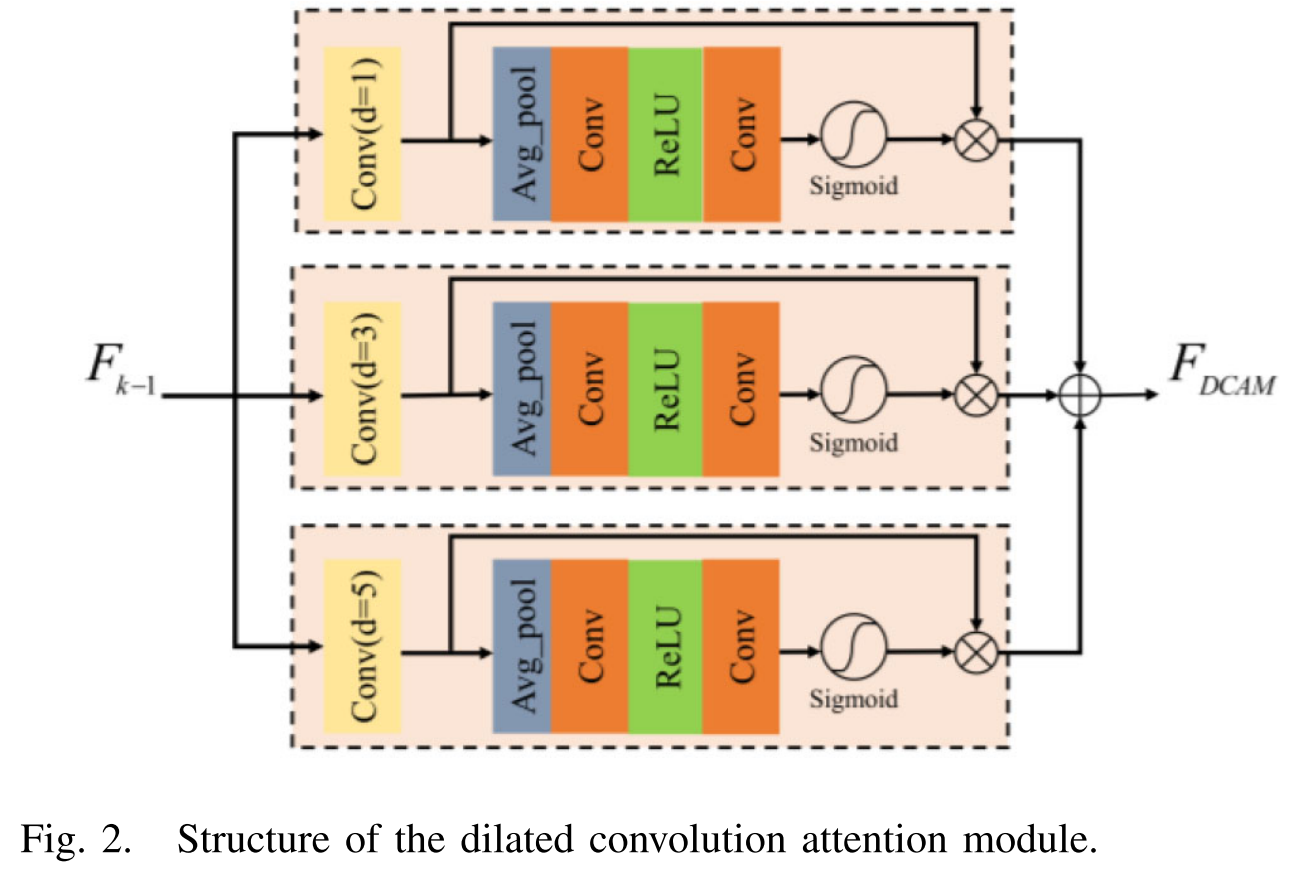
DCAM通过具有不同感受野大小的DAB捕获多个不同区域的多尺度上下文信息。每个DAB由扩张卷积层和信道注意块组成。DAB首先通过扩展卷积层提取多个特征,其中包含低频特征和高频特征;然后通过平均池化层从提取的多个特征中提取统计量,并通过两个卷积层和ReLU函数捕获上下文信息的相互关系;最后通过Sigmoid函数和通道乘法对提取的多个特征进行重新校准,以关注更多的高频特征。设X表示DAB的输入特征,DAB的操作可以公式化如下:
在DCAM中,我们设置了三个具有不同膨胀率的DAB。当扩张率为1、3和5时,DAB的感受野大小分别为3、11和19。当多个卷积层具有不同的感受野时,它可以获得更多的LR图像信息和多个不同区域的细节。因此,DCAM可以捕获LR图像多个不同区域的多尺度上下文信息。
将Fk−1和FDCAM分别设置为DCAM的输入和输出,DCAM的操作可以公式化如下: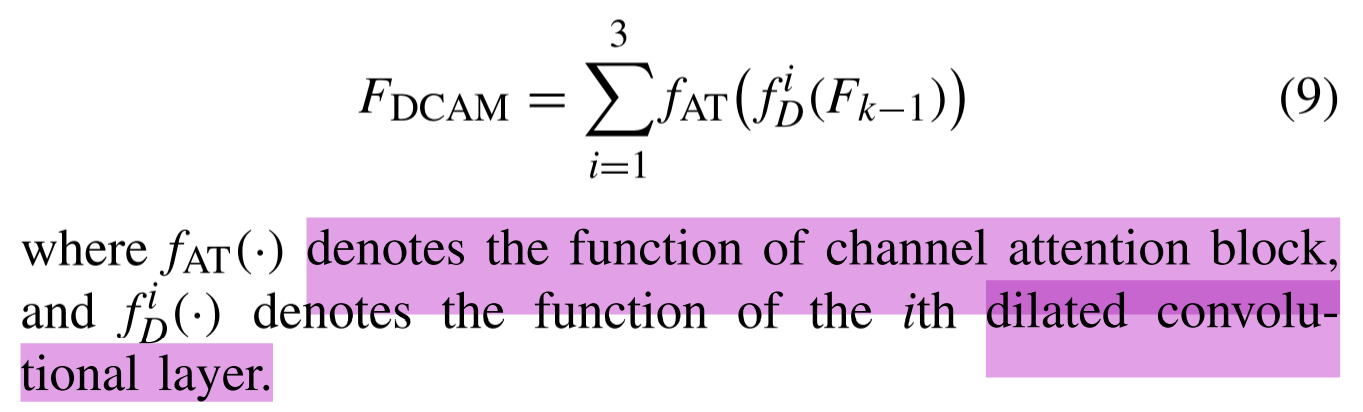
Multifeature Attention Block
捕获的许多不同区域的多尺度上下文信息包含大量重复且容易提取的低频分量,这在提取过程中浪费了大量的计算。同时,高频信息难以提取。因此,我们提出了一种基于DCAM的MFAB,进一步关注多尺度上下文信息的高频分量,并提取更多的高频特征。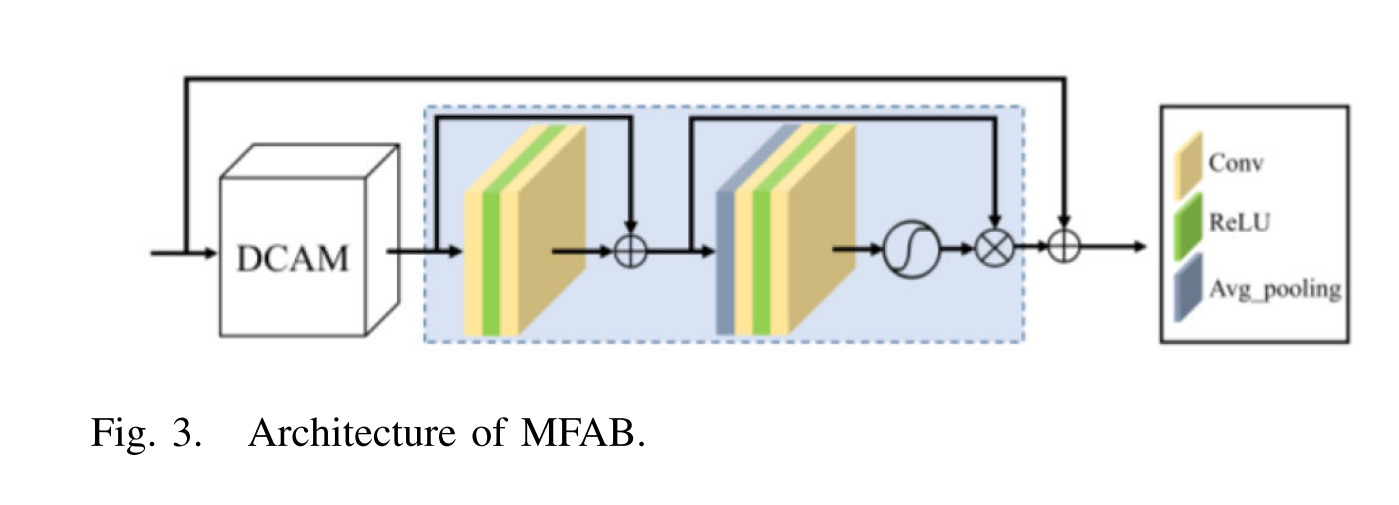
MFAB的结构示于图3中,由DCAM模块和残差通道模块组成。DCAM旨在通过具有不同感受野大小的不同DAB捕获多尺度上下文信息。残差注意力模块旨在进一步提取LR图像的更多高频特征。

其中fDCAM(·)表示DCAM的函数,并且FDCAM表示提取的多个特征。然后,通过残差注意模块更新FDCAM,提取高频成分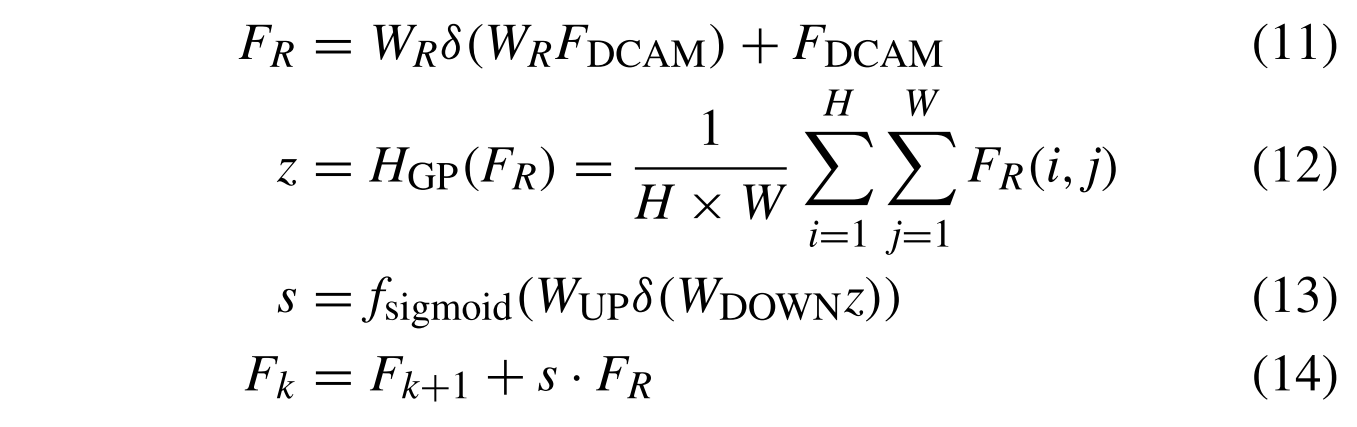
其中fsigmoid(·)表示Sigmoid门控,δ(·)表示ReLU函数,WR表示残余块的卷积层权重,并且WUP和WDOWN分别表示信道上采样层权重和信道下采样层权重。

















 1384
1384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









