






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:CSIG文档图像分析与识别专委会

本文简要介绍今年CVPR 2023的录用论文“Document Image Shadow Removal Guided by Color-Aware Background”的主要工作。现有的文档图像阴影去除方法 [1,2]依赖于固定值背景而忽略文档的其他印刷颜色,可能会对具有复杂背景的图像造成颜色失真或阴影残留问题。为了解决上述问题,作者提出了颜色感知背景提取网络(CBENet)提取彩色背景用于指导阴影去除网络(BGShadowNet)进行阴影去除。BGShadowNet分为两个阶段,在阶段一采用背景约束解码器生成一个粗略的结果,在阶段二通过在编码-解码模型中嵌入基于背景的注意力模块(BAModule)维持文档外观的一致性,用细节增强模块(DEModule)提高纹理细节来改进初步去阴影的结果。在两个基准数据集RDD和Kligler上定性和定量的实验证实了本文所提出方法的优越性。
一、研究背景
目前的文档阴影去除算法 [1,2]通常假设文档的背景颜色是一个固定值。用聚类 [1]或是深度学习 [2]的方法得到背景颜色指导文档图像阴影的去除。但是这样的做法会忽略文档中存在的其它印刷颜色,对文档背景复杂的图像可能会造成颜色失真或阴影残留的问题。如图1(d)存在颜色失真和阴影残留,(f) 存在阴影残留。而本文提出的基于颜色感知背景的文档图像阴影去除方法能很好地避免这两个问题。

图1 本文基于颜色感知背景的方法可以更好地去除文档图像阴影,避免颜色失真和阴影残留。
二、方法原理简述
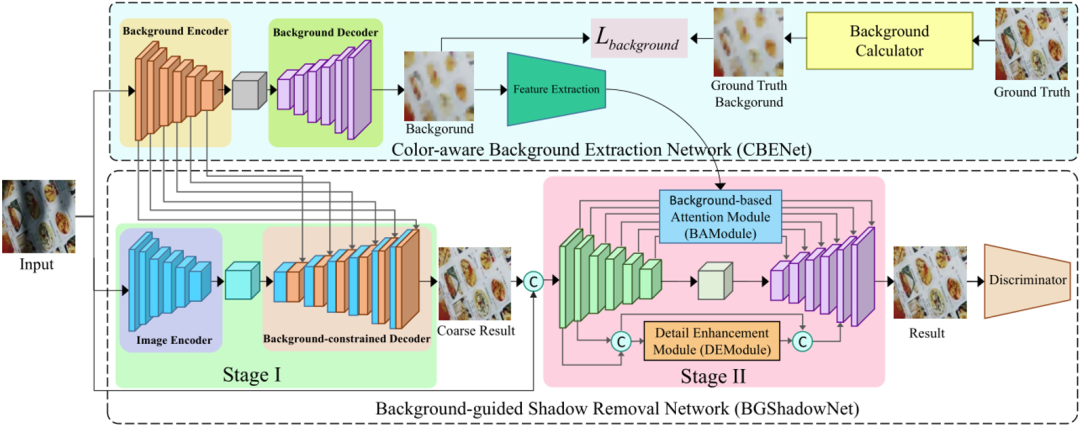
图2 模型结构图
图2是模型的整体结构图,它包含颜色感知背景提取网络(Color-aware Background Extraction Network, CBENet)和阴影去除网络(Background-guided Shadow Removal Network , BGShadowNet)。CBENet采用U-Net [3]结构用于提取颜色随空间变化的彩色背景,提供一些有用的颜色信息帮助BGShadowNet进行阴影去除。彩色背景的GT计算过程如下,首先将无阴影的图像分为16×16的Patch,然后对于每个区域,根据像素强度聚类成两个簇,分别是背景和文字。一般来说背景比文字亮一些,用更亮的簇的均值作为这个Patch的背景颜色。最后对这个区域做平滑,避免边界颜色过度不平滑。图3展示了彩色背景的可视化。

图3 彩色背景可视化:(a) 阴影图像,(b) 局部背景图像,(c) 最终背景图像。
BGShadowNet包含两个阶段,阶段1的目的是生成一个粗略的阴影去除图像,采用U-Net [3]结构。为了利用背景图像的编码特征,在解码的时候将CBENet的编码特征集成到对应的层级,最后生成一个粗略的去阴影结果。在阶段2对阶段1的结果进行改进和提升。输入粗略的去阴影结果和原图的堆叠,进入一个编码-解码网络(DenseUnet [4]),在基于背景的注意力模块(Background-based Attention Module, BAModule)结合彩色背景信息保持文档外观的一致性。在细节增强模块(Detail Enhancement Module, DEModule)利用底层特征来恢复粗糙结果的纹理细节。最后的结果经过判别器判断文档的真实性。
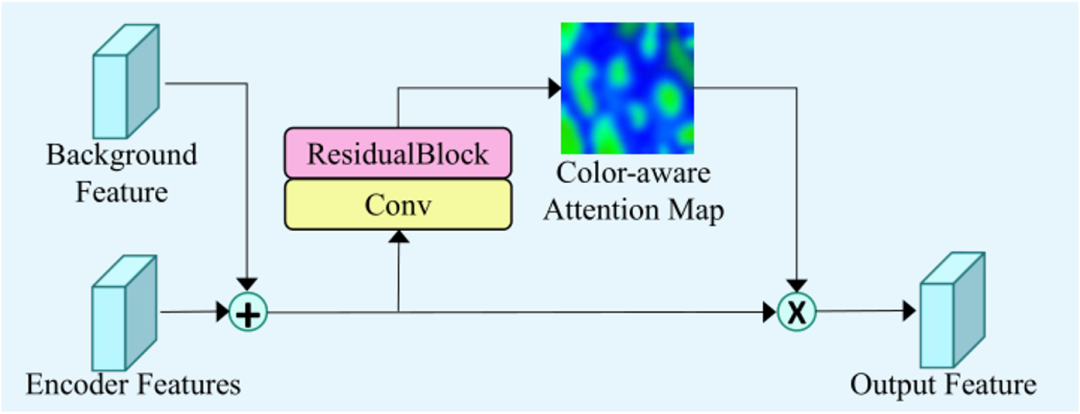
图4 BAModule结构图
有相似背景的区域应该具有类似的外观(颜色和光照)。然而,粗略的去除阴影结果中可能存在光照或颜色伪影。为了保持图像的整体一致性,本文引入了一种基于背景的注意力模块(BAModule),其结构如图4所示。编码特征和背景特征堆叠后经过卷积生成颜色感知注意力图与堆叠后的输入特征相乘得到输出特征。
由于网络中存在多个卷积和下采样操作,高层次的特征可能会丢失部分细节信息,导致细节模糊的结果。与高层次特征相比,CNN层的低层特征通常包含更多的纹理细节。因此,本文引入了一个细节增强模块(DEModule) 来利用网络中的低层特征,恢复粗略结果的纹理细节,其结构如图5所示。取编码器前两层的编码特征堆叠后经过两次卷积得到特征图M,全局平均池化后得到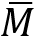 ,计算两者之间的余弦相似度得到S。通过以下公式对S进行量化得到量化编码图E,和量化级别L一起得到反映低层信息的相对统计信息的量化计数图C。C通过卷积后与上采样后的结果堆叠得到绝对统计信息H。H通过图5右侧的分支生成新的量化级别与量化编码图E相乘后得到输出特征。
,计算两者之间的余弦相似度得到S。通过以下公式对S进行量化得到量化编码图E,和量化级别L一起得到反映低层信息的相对统计信息的量化计数图C。C通过卷积后与上采样后的结果堆叠得到绝对统计信息H。H通过图5右侧的分支生成新的量化级别与量化编码图E相乘后得到输出特征。
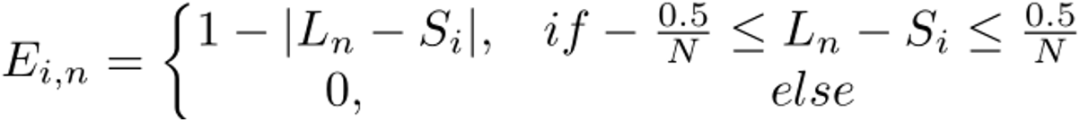
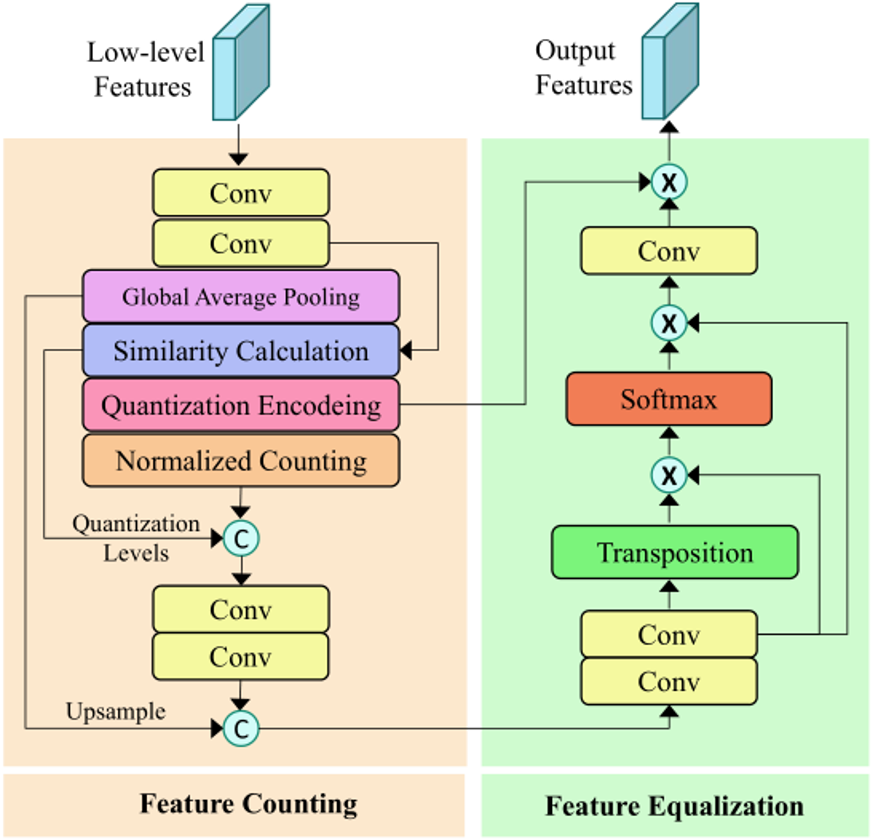
图5 DEModule结构图
网络的Loss包括CBENet的背景重建Loss,第二个是阶段1和阶段2输出结果的Loss,第三个是结构一致性损失,最后一个是对抗损失。
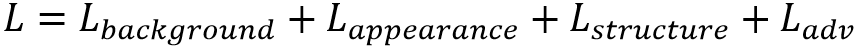
三、主要实验结果及可视化效果
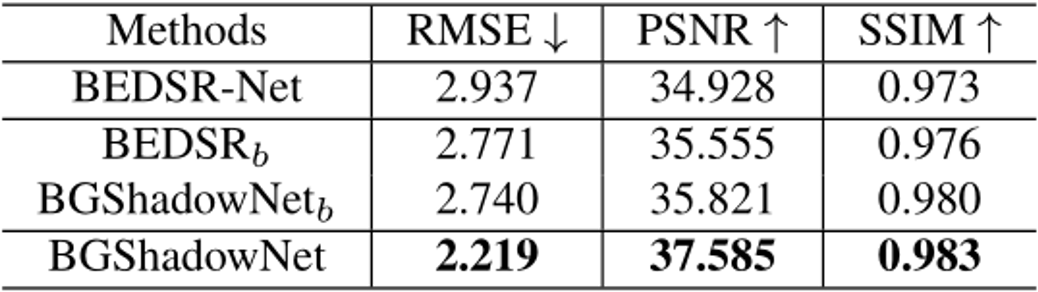
本文构建了一个真实的文档阴影去除数据集RDD,4371份用于训练,545用于测试。测试的数据集还包括Kligler [5]。表1实验结果证明本文方法的有效性。两个数据集上的RMSE、PSNR和SSIM都优于现有的文档阴影去除方法。
表1 RDD和Kligler测试集的实验结果
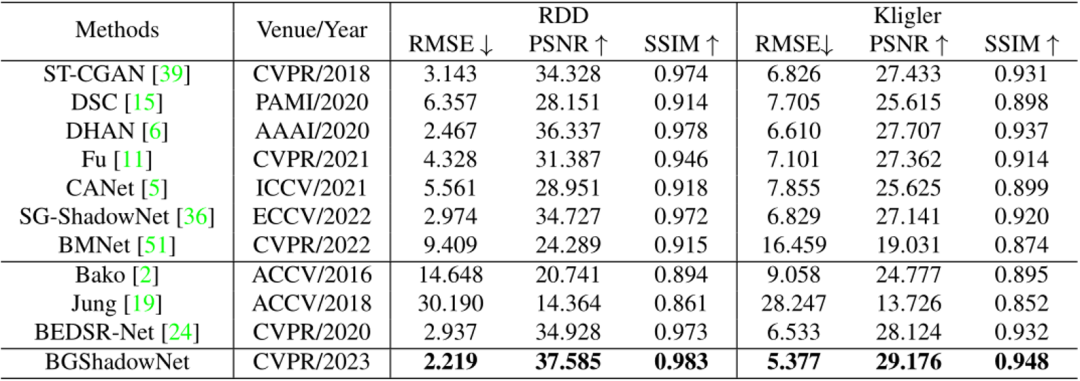

 图6 各种阴影去除方法的可视化比较:(a) 输入图像,(b) Jung,(c) DSC,(d) Fu,(e) DHAN,(f) CANet,(g) BEDSR-Net,(h) 本文的BGShadowNet,以及 (i) 真实标注图像。
图6 各种阴影去除方法的可视化比较:(a) 输入图像,(b) Jung,(c) DSC,(d) Fu,(e) DHAN,(f) CANet,(g) BEDSR-Net,(h) 本文的BGShadowNet,以及 (i) 真实标注图像。
用户测试的实验结果也表明本文的方法去阴影的效果排名最高。有20.32%的志愿者认为本文的方法去阴影的效果最好。
表2展示了本文提出的BAModule和DEModule的消融实验,图7是对应的可视化结果。表3展示了彩色背景的消融实验。
表2 在RDD和Kligler上的消融实验,BASE1:一个DenseUnet;BASE2:两个堆叠的DenseUnet;BGShadowNet1:没有Stage2;BGShadowNet2:没有DEModule和BAModule;BGShadowNet3:没有BAModule;BGShadowNet4:没有DEModule。
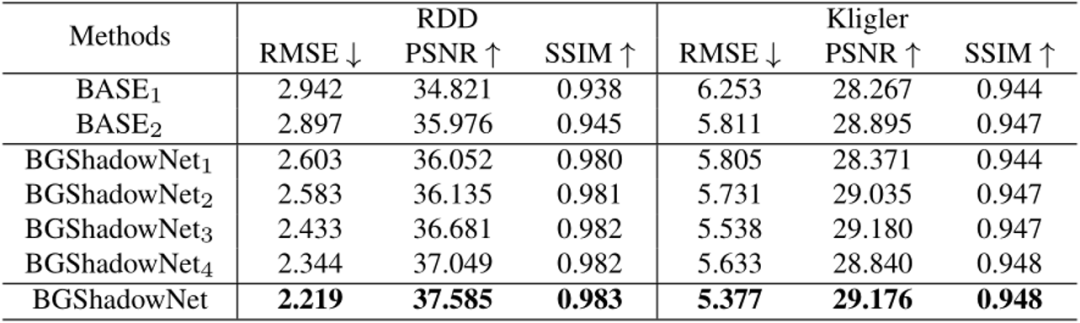
 图7 消融实验的可视化比较:(a) 输入图像,(b) BASE1,(c) BASE2,(d) BGShadowNet1,(e) BGShadowNet2,(f) BGShadowNet3,(g) BGShadowNet4,以及 (h) 本文的BGShadowNet。
图7 消融实验的可视化比较:(a) 输入图像,(b) BASE1,(c) BASE2,(d) BGShadowNet1,(e) BGShadowNet2,(f) BGShadowNet3,(g) BGShadowNet4,以及 (h) 本文的BGShadowNet。
表3 在RDD数据集上彩色背景的消融实验
四、总结及讨论
1. 为了解决现有方法对具有复杂背景的图像造成颜色失真或阴影残留问题,本文提出了颜色感知背景提取网络(CBENet)提取彩色背景用于指导阴影去除网络(BGShadowNet)进行阴影去除。
2. 本文提出基于背景的注意力模块(BAModule)维持文档外观的一致性,以及细节增强模块(DEModule)提高纹理细节。
3. 当图像受到严重的噪声干扰时,本文方法的阴影去除结果可能会包含一些残留噪声,导致与周围环境的亮度不均匀。
五、相关资源
论文地址:https://openaccess.thecvf.com/content/CVPR2023/papers/Zhang_Document_Image_Shadow_Removal_Guided_by_Color-Aware_Background_CVPR_2023_paper.pdf
参考文献
[1] Bako S, Darabi S, Shechtman E, et al. Removing shadows from images of documents[C]. ACCV, 2016.
[2] Y. H. Lin, W. C. Chen, and Y. Y. Chuang. Bedsr-net: A deep shadow removal network from a single document image [C]. CVPR, 2020.
[3] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]. MICCAI, 2015.
[4] N Bharath Raj and N Venkateswaran. Single image haze removal using a generative adversarial network [C]. CVPR, 2018.
[5] N. Kligler, S. Katz, and A. Tal. Document enhancement using visibility detection [C]. CVPR, 2018.
原文作者:Ling Zhang, Yinghao He, Qing Zhang, Zheng Liu, Xiaolong Zhang, Chunxia Xiao*
撰稿:李海洋 编排:高 学
审校:连宙辉 发布:金连文
最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者ransformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()

















 1360
1360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









