






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer444,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球,可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文搞科研,强烈推荐!

衡宇 发自 凹非寺
转载自:量子位(QbitAI)
谷歌110亿参数Genie,用来打造交互虚拟世界,它来了!
划重点:不受视频监督训练;只用给它单张图像,就能提示生成可玩的2D虚拟世界;这个交互式的虚拟世界还自主可控。
但令人撇嘴的点,就是Genie最后出的效果,画质太糊了。
像这样:

或者这样:

团队也站出来承认,Genie目前确实还有限制,现在只能以1FPS制作游戏。
看得网友忍不住吐槽,不说和Sora的效果比了,就算和别的文生视频或者文生图相比,都是“2K”和“480p”的差距。
看起来挺令人兴奋的,但emmm怎么说呢,画质和风格都像个上世纪80年代的游戏。
但也有人站出来为Genie说话。
比如英伟达科学家Jim Fan,就明确表达:
与Sora不同,Genie实际上是个能推断动作、用正确动作驱动世界模型。

Genie团队负责人Tim Rocktäschel激情开麦,称认为这(Genie)是迈向AGI通用世界模型的充满希望的一步。
他援引了世界模型第一推崇者Yann LeCun的推特,称:
“诚然, OpenAI的Sora惊艳世界,但正如杨立昆所说,世界模型一定需要动作。”

画质就一个字,糊
书归正传。
咱们从视觉上来感受一下Genie的神奇魔法,直接上效果图。
这是官方给出的例子——
现实世界的照片,喂给Genie,就能动起来,变成无限的虚拟世界。
Like this,小黄狗逛公园:

还有古堡武士向前冲:

Genie团队用Imagen2生成图像,然后把图像喂给Genie。Genie把图像作为起始帧,生成以下效果。

团队表示,Genie不仅仅能用AI绘画来作为驱动的起始帧,随便拿张人类大作,也可以达到同样的效果。
比如这是个小朋友的画作:

丢给Genie后,能得到老鹰起飞的效果:

这也是一张小朋友涂鸦,经由Genie处理后得到的:

可以明显看到,上面给出的这些官方效果,明显画质参差不齐。
难怪有的网友称,这些demo看上去有一种700度近视眼摘掉眼镜看世界的美
不少人提问为什么不用超高清分辨率输出,目前还没得到回应。

除了画质太糊,Genie的另一个点,就是网友们觉得demo都太短太短了。
平均每个时长不到2s。
好多人都急了:
能不能放出来1分钟时长的demo啊???或者至少让咱看看,超过3秒钟,会是啥样子吧。

然而,虽然肉眼可见的画质糊、时长短,Genie仍然是令人惊呼的新研究。
毕竟,任何人,包括幼儿园阶段的小朋友,都可以绘出一个世界,然后加入其中,开始探索。
有小伙伴已经在畅想,日后能用Genie制造“一个让每个人都感到满足和满足、永无止境的生成世界”。
眨眼间,AI就从生成下一个word发展到了生成下一个world。

Genie,一种通用方法
令人欣慰,谷歌DeepMind放出了关于Genie的论文,《Genie: Generative Interactive Environments》。
论文显示,Genie是一个11B参数的交互式环境生成模型,能够从互联网视频中无监督地学习并生成可交互的虚拟世界。
并且,Genie可以通过文本、图像、照片甚至手绘草图生成最终的交互式虚拟世界。

整个Genie包含三个关键组件:
潜在动作模型(Latent Action Model ,LAM);
视频分词器(Tokenizer);
潜在动态模型(Dynamics Model)。
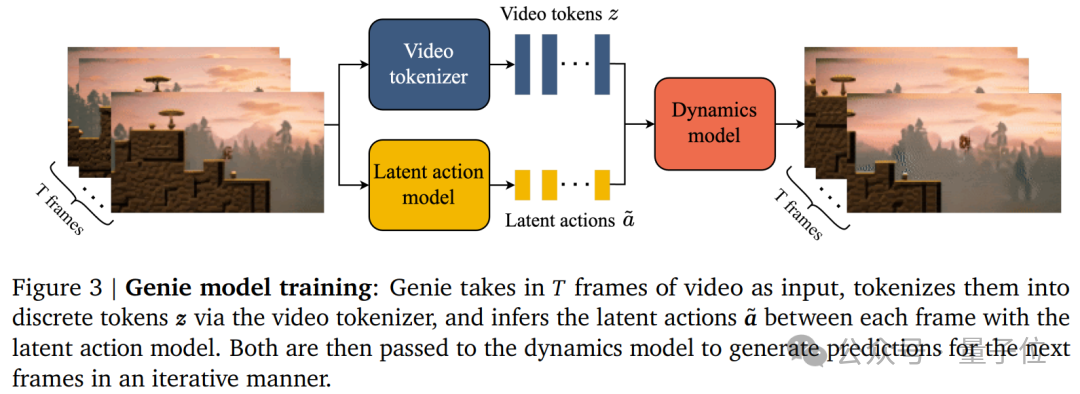
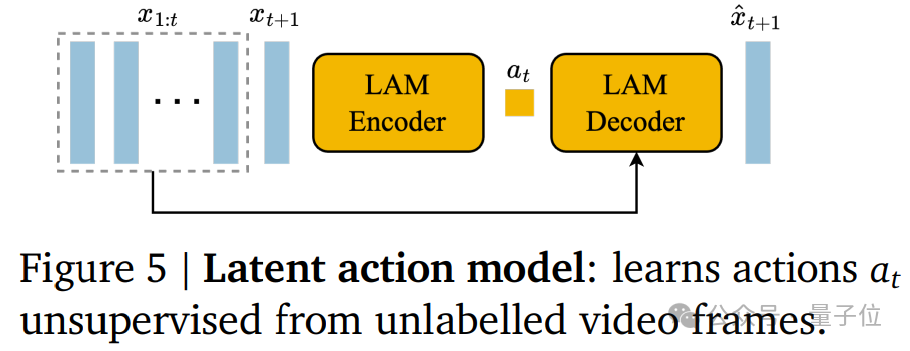
其中,潜在动作模型用于推理每对帧之间的潜在动作。
为了让视频生成可控,谷歌DeepMind用前一帧所采取的动作来预测未来帧。
由于此类动作标签在互联网视频中可用的很少,同时获取动作注释的成本超级高,因此,团队以完全无监督的方式学习潜在动作。
也就是说,Genie的训练使用了大量公开的互联网视频数据集,而没有使用任何动作标签数据。
视频分词器的作用则是把原始视频帧转换为离散token。
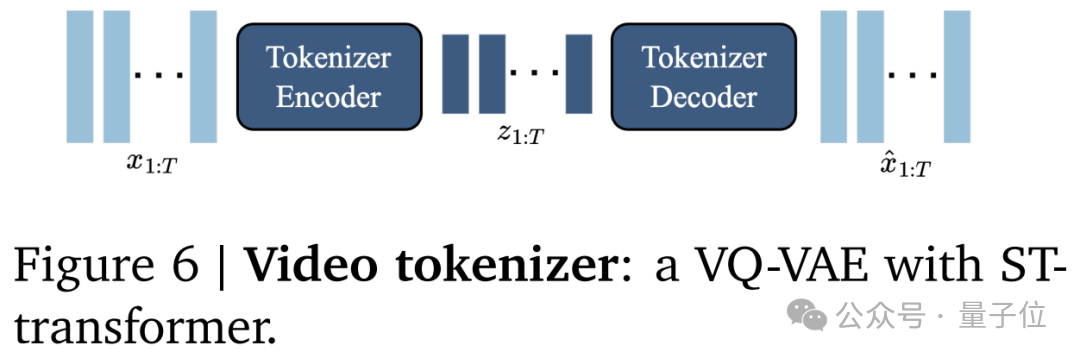
三组件之中的第三样,潜在动态模型,作用是给定潜在动作和过去帧的token,用来预测视频的下一帧。
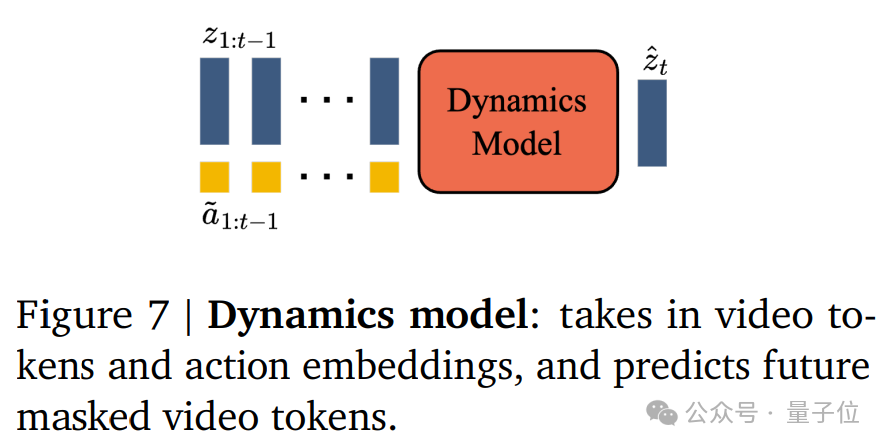
论文介绍,在训练过程中,使用超200000小时的互联网游戏视频,作为其训练数据。
这些数据集经过筛选,且包含了2D平台游戏的视频片段。
最终,其推理过程如下:
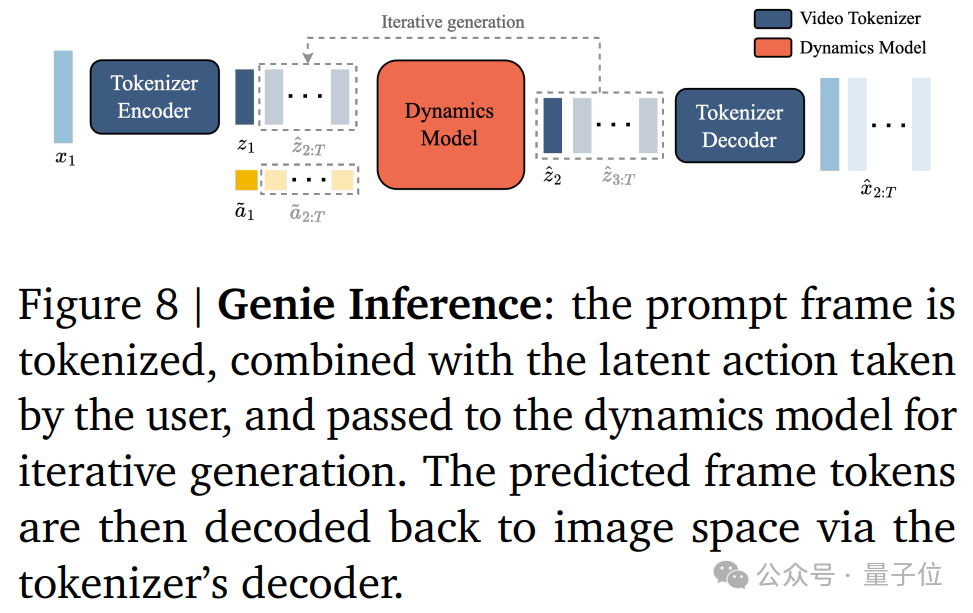
值得引起注意的是,Genie允许用户通过潜在动作在生成的环境中进行交互。
这些动作是通过一个因果动作模型学习得到的,这个模型允许用户通过指定潜在动作来控制视频的生成过程。
用户通过潜在动作与生成的环境进行交互,从而创造出新的、动态的视频内容。

这也是谷歌认为Genie是实现通用Agent的基石之作的原因之一。
此前研究表明,游戏环境可以成为开发AI Agent的有效测试平台,但实际情况中常常受到可用游戏数量的限制。
借助 Genie,未来的AI Agent可以在新生成的世界中,进行永无休止的训练。
多说一句,论文中进行了一个概念证明,即“Genie学到的潜在动作可以转移到真实的人类环境中”,不过,这都是未来可能发生的事情了。
谷歌还明确表达了自己的态度:Genie是一种通用方法。
也就是说,虽然Genie的训练数据多是2D的游戏视频or机器人视频,但不需要任何额外的领域知识,Genie就可以在多个领域中应用。
为了验证这个观点,谷歌在RT1的无动作视频上训练了一个较小的模型,只有2.5B。
结果发现,具有相同潜在动作序列的轨迹通常会表现出相似的行为,也就是说,Genie能够学习一致的动作空间。
这对训练机器人甚至具身智能来说,都是大大的利好消息。

最后来看一眼Genie的研究团队~
团队人员不老少,共同一作就有六位,分别是Jake Bruce,Michael Dennis,Ashley Edwards,Jack Parker-Holder,Yuge( Jimmy) Shi,以及Tim Rocktäschel。
Yuge(Jimmy)Shi是华人,本科毕业于澳大利亚国立大学,2023年在牛津大学拿下机器学习博士学位。
她在2023年3月加入谷歌DeepMind,此前还在Meta AI实习过。
此外,研究团队不少人都是谷歌DeepMind的开放性团队(Open-Endedness Team)成员。
研究团队中,有位不列颠哥伦比亚大学的计算机科学副教授,他同时是谷歌DeeoMind的高级研究顾问。
他在推特上敲了敲小黑板,称:
咳咳,注意了,现在看到的Genie是最糟糕的情况!
相信用不了多久它就会变完美。
参考链接:
[1]https://sites.google.com/view/genie-2024/home
[2]https://arxiv.org/pdf/2402.15391.pdf
CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-多模态和扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如多模态或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看














 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









