 HiMo-CLIP:长文本图像检索新SOTA
HiMo-CLIP:长文本图像检索新SOTA




点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer2233,小助手拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料及应用!发论文/搞科研/涨薪,强烈推荐!

描述得越详细,图文匹配的分数就应该越高——这听起来是常识,但现有的CLIP模型却做不到。
近日,中国联通数据科学与人工智能研究院团队在AAAI 2026 (Oral)上发表最新成果HiMo-CLIP。该工作通过巧妙的建模“语义层级”与“语义单调性”,在不改变编码器结构的前提下,让模型自动捕捉当前语境下的“语义差异点”,大幅刷新了长文本检索任务的SOTA记录。


痛点:当描述变长,CLIP却“懵”了
在多模态检索任务中,我们通常期望:文字描述越详细、越完整,其与对应图像的匹配度(对齐分数)应该越高。这被称为“语义单调性”。
然而,现实很骨感。现有的模型(包括专门针对长文本优化的Long-CLIP等)往往将文本视为扁平的序列,忽略了语言内在的层级结构。
如下图所示,对于同一张“白色福特F250皮卡”的图片,当文本从简短的“正面视图...”扩展到包含“超大轮胎”、“车轴可见”、“有色车窗”等详细描述的长文本时,许多SOTA模型的对齐分数反而下降了!
这种现象表明,模型未能有效处理长文本中的“语义层级”,导致细节信息淹没了核心语义,或者无法在复杂的上下文中捕捉到最具区分度的特征。

图1. 随着描述变长,现有模型分数下降,而HiMo-CLIP(绿勾)稳步提升。
方法:HiMo-CLIP框架
为了解决上述问题,研究团队提出了一种即插即用的表征级框架HiMo-CLIP。它包含两个核心组件:层级分解模块(Hierarchical Decomposition,HiDe)和单调性感知对比损失(Monotonicity-aware Contrastive Loss,MoLo)。
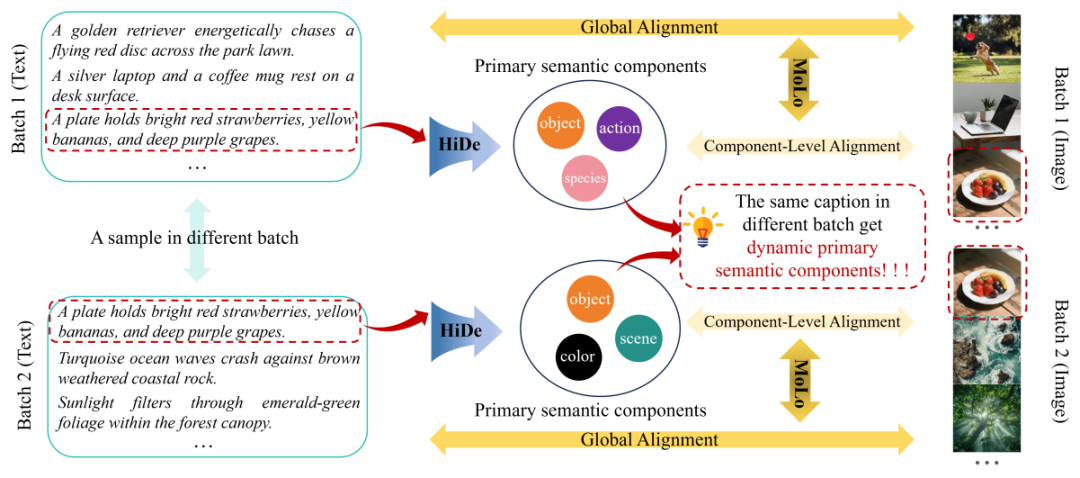
图2. HiMo-CLIP框架概览。(1)HiDe模块利用Batch内的PCA动态提取语义成分;(2)MoLo损失函数强制模型同时对齐“全量文本”和“语义成分”,实现单调性约束。
1. HiDe:谁是重点?由“邻居”决定
在真实场景中,数据样本往往是高度复杂的。如图2所示,我们面对的不是简单的“红苹果”和“绿苹果”,而是像“一只金毛猎犬在公园草坪上追赶红盘”、“盘子里放着鲜红的草莓、黄香蕉和深紫色的葡萄”这样高度复杂的场景。传统的固定分词法在这种复杂度下根本抓不住重点。HiMo-CLIP换了个思路,它像一个玩“大家来找茬”的高手:通过观察Batch内的“邻居”,动态提取最具区分度的特征。
长文本特征f1:代表“整句话”的意思。
动态子语义f2:代表“这句话里最独特的记忆点”。
举个栗子:假设长文本是:“一只戴着墨镜的柯基在沙滩上奔跑”。
场景A(混在风景照里):如果这一批次(Batch)的其他图片都是“沙滩排球”、“海边游艇”。PCA一分析,发现“沙滩”大家都有,不稀奇。唯独“柯基”是独一份。
此时,f2自动代表“柯基(物体)”。
场景B(混在狗群里):如果这一批次的其他图片都是“草地上的柯基”、“沙发上的柯基”。PCA一分析,发现“柯基”遍地都是,也没法区分。唯独“戴墨镜”和“在沙滩”是特例。
此时,f2自动代表“戴墨镜/沙滩(属性/环境)”。
这就是HiDe最聪明的地方:它不需要人教它什么是重点,而是利用统计学原理,自适应地提取出那个最具辨识度的“特征指纹”,自动构建语义层级。
2. MoLo:既要顾全大局,又要抓住细节
找到了重点f2,怎么用呢?作者设计了MoLo,强制模型“两手抓”:
MoLo=InfoNCE(f1, feat)+λ*InfoNCE(f2, feat)
第一手:InfoNCE(f1, feat)是传统的图文匹配,保证图片和“整句话”(f1)对齐。
第二手:InfoNCE(f2, feat)强制图片特征还要特别像那个提取出来的“独特记忆点”(f2)。
这个操作看似简单,实则一石三鸟:
自动摘要:f2就是特征空间里的“高维短文本”,省去了人工构造短文本的偏差。
更懂机器的逻辑:人类定义的关键词(如名词)未必是模型分类的最佳依据(可能是纹理或形状)。PCA完全在特征空间操作,提取的是机器认为的差异点,消除了人类语言和机器理解之间的隔阂(Gap)。
数据效率高:你只需要喂给模型长文本,它在训练中顺便学会了如何拆解长句、提取关键词。训练的是长文本,却白捡了短文本的匹配能力。
实验:长短通吃,全面SOTA
研究团队在多个经典的长文本、短文本检索基准,以及自行构造的深度层级数据集HiMo-Docci上进行了广泛实验。
表1. 长文本检索结果。
| 表2. 短文本检索结果。
|
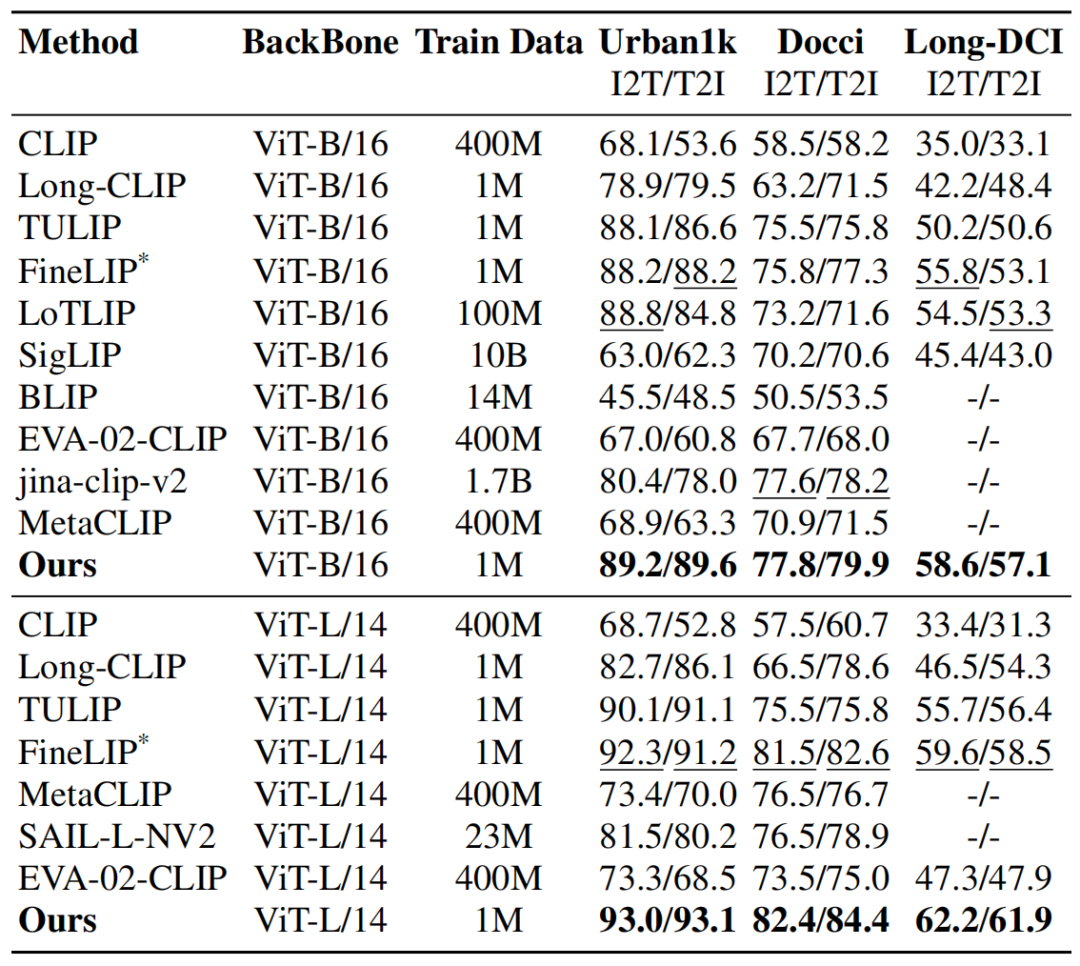
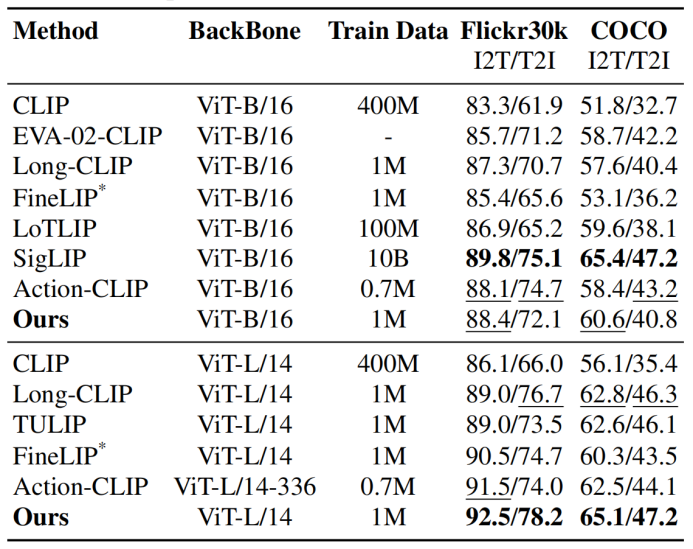
在长文本(表1)和短文本(表2)检索任务上,HiMo-CLIP展现出了显著的优势。值得注意的是,HiMo-CLIP仅使用了1M(一百万)的训练数据,就击败了使用100M甚至10B数据的方法(如LoTLIP,SigLIP等)。
为了充分评估长文本的对齐效果,研究团队构建了HiMo-Docci数据集,同时还提出了HiMo@K指标,以量化模型是否真的“读懂”了层级。结果显示,HiMo-CLIP保持了极高的单调性相关系数(0.88),远超对比方法。

图3. HiMo-Docci上的单调性可视化。随着文本描述逐渐完整(1→5),HiMo-CLIP的分数(红线)呈现出完美的上升趋势,而其他模型的分数则波动剧烈,甚至下降。
进一步的,为了探究各个组件对性能的具体贡献,研究团队进行了详尽的消融实验,揭示了HiDe与MoLo协同工作的内在机理。感兴趣的朋友可到原文了解更多细节~
总结
HiMo-CLIP通过显式建模语义层级和单调性,成功解决了视觉-语言对齐中长期被忽视的结构化问题。
创新点:首次提出利用In-batch PCA进行动态语义分解(HiDe)和单调性损失(MoLo)。
效果:在长文本、组合性文本检索上取得SOTA,同时兼顾短文本性能。
意义:这一工作不仅提升了检索精度,更让多模态模型的对齐机制更加符合人类的认知逻辑,为未来更复杂的多模态理解任务指明了方向。
论文题目:HiMo-CLIP: Modeling Semantic Hierarchy and Monotonicity in Vision-Language Alignment. AAAI 2026 Oral.
文章:https://arxiv.org/abs/2511.06653
开源地址:github.com/UnicomAI/HiMo-CLIP
本文系学术转载,如有侵权,请联系CVer小助手删文
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ICCV 2025 论文和代码下载
在CVer公众号后台回复:ICCV2025,即可下载ICCV 2025论文和代码开源的论文合CVPR 2025 论文和代码下载
在CVer公众号后台回复:CVPR2025,即可下载CVPR 2025论文和代码开源的论文合集
CV垂直方向和论文投稿交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-垂直方向和论文投稿微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。 一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者论文投稿+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)人数破万!如果你想要了解最新最快最好的CV/DL/AI论文、实战项目、行业前沿、从入门到精通学习教程等资料,一定要扫描下方二维码,加入CVer知识星球!最强助力你的科研和工作!
▲扫码加入星球学习
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)人数破万!如果你想要了解最新最快最好的CV/DL/AI论文、实战项目、行业前沿、从入门到精通学习教程等资料,一定要扫描下方二维码,加入CVer知识星球!最强助力你的科研和工作!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号 整理不易,请点赞和在看

















 6525
6525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









