









《Adversarial Transfer Learning for Chinese Named Entity Recognition with Self-Attention Mechanism》
- paper publisher: ACL 2018
- 方向:NER
- source code: https://github.com/CPF-NLPR/AT4ChineseNER
摘要
中文NER缺少大量的标注数据。。中文NER和中文分词中间含有大量的相似实体边界,两个任务之间也各有自己的特点。而现有的中文NER模型既没有从CWS中获取到有用的边界信息, 也没有过滤出分词任务的特殊信息。
本文创新点: 提出一种新的对抗迁移学习框架,充分利用共享任务之间的 边界信息同时过滤掉分词任务的特有信息以免干扰NER任务。此外,因为每个字符在进行实体预测时都可以提供非常重要的信息,所以本文还引入了self-attention机制,在预测实体类别时,利用自注意力机制捕捉两个实体之间的长期依赖关系。
引言
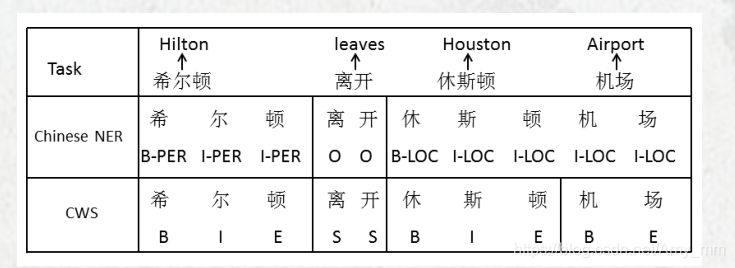
- task-shared information: CWS和NER之间含有很多共同的信息, 比如希尔顿和离开都是一样的边界信息。
- task-specific information:特有的信息。比如休斯顿机场,二者的边界并不一样,NER的边界更为粗粒度。
挑战:
(1)怎样只运用二者共享的信息而防止特有的信息干扰彼此。如果不区分特有的信息,当遇到“休斯顿机场”时,CWS分词为“休斯顿“和”机场“,而NER是”休斯顿机场“,造成识别错误。
(2)如何更好的捕捉到整个序列间的全局依赖关系。LSTM可以较好的获得长期依赖的信息,但是它并不能获得任意两个字符之间的依赖信息。比如“希尔顿”可以是人名也可以是机构名;当“希尔顿离开”时区分为人名,当为“住在希尔顿”时区分为机构名。
解决方法:
问题一方案:提出对抗迁移学习架构,任务共享的词边界信息整合到NER任务中。对抗迁移学习是将对抗学习合并到迁移学习中。引入对抗学习保证CWS只利用task-shared词边界信息。
问题二方案:利用自注意力机制对LSTM的隐藏层表示进行同步。
本文贡献:
- 第一个在NER任务中应用对抗迁移学习。将CWS中的task-shared词边界信息应用到NER任务中。
- 引入srlf-attention机制,能够捕捉到整个序列中的全局依赖信息学习到序列中的潜在特征。
3.在两个不同的数据集上进行实验,并且取得了state-of-the-art的成绩。
2 Related Work
-
NER
早期方法:HMM CRF
近期:神经网络
BILSTM+CRF
GCNN 中文NER -
对抗训练
GoodFellow在CV中取得很大成果
NLP中,对抗学习 被应用到领域自适应,跨语言迁移学习,多任务学习以及众包学习
在本文中,不同于之前的对抗学习应用,利用对抗学习对NER和CWS进行联合训练,目的是提取出两个任务中共享的词边界信息。这是对抗学习首次应用在中文NER中。
*自注意力机制
self-attention在2017年被Vaswani引入到机器翻译中,捕捉句子中的全局依赖,取得最好的结果。
NLU和语义角色标注中都有用到自注意力机制。本文是第一个将self-attention应用到中文NER中的。
3方法
本文提出一种对抗迁移学习框架,学习CWS和NER中task-shared词边界信息,同时利用对抗学习过滤掉CWS独有的信息,利用self-attention学习全局依赖信息,也就是任意两个字符之间的依赖关系。
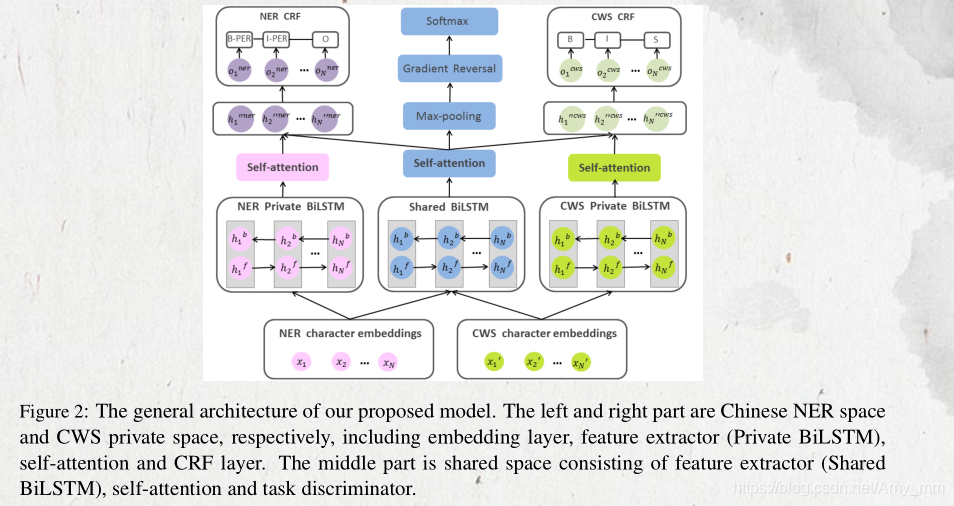
本文模型主要包括五个部分:embedding layer,shared-private 特征提取器,也就是BIlstm,self-attention, task-specific CRFtask discriminator
3.1 Embedding Layer
加载预训练embedding 词典,将离散的NER和CWS字符映射为分布式的embedding 向量。
3.2 Shared-Private Feature Extractor
LSTM是RNN 的一种变种,主要是通过门控机制和记忆细胞解决梯度消失和梯度爆炸问题。
双向LSTM能够捕捉到当前时刻的过去和将来的上下文信息。
其隐藏层单元可以表示为:
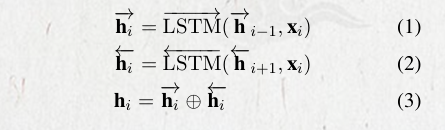
- shared-private feature extraction
如上图所示:
共享特征提取器:输入为NER和CWS, 提取任务共享的边界信息
private 提取各个任务的特征。
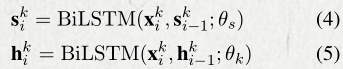
3.3 self-attention
本文应用multi-head self-attention机制。
H = {h1, h2, …hn}表示private特征提取器的输出。S = {s1, s2, …sn}表示共享特征提取器的输出。
以private为例讲述self-attention的工作机制。
Q,K,V分别是query, key, value的矩阵,维度为N*2d, N代表N个序列,d代表隐藏层维度。
multi-head self-attenyion是先用不同的线性映射将QKV映射h次,然后h个映射结果并行进行scaled dot-product 计算,最后将h个计算后的结果拼接起来得到新的表示。
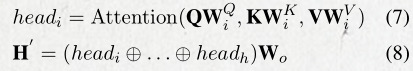
3.4 task-specific CRF
对于任务k的每句话,最后的表示是将private空间以及shared空间经过self-attention后的表示拼接起来。
对于句子x={c1, c2…cn},预测tag序列为y={y1, y2…y3},CRF的计算如下:
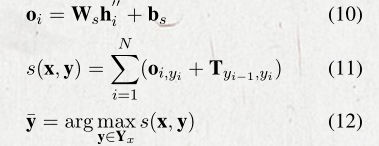
其中oi 代表 ci 字符的tag为 yi 的tag概率值。T是转移概率矩阵,也就是两个连续label s 之间的转移概率。
最后利用viterbi算法得到最后的tag sequence。
训练过程中loss函数: 负对数似然函数。
ground-truth label的概率计算如下:
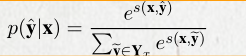
给定T个训练样本,得到的损失函数计算如下:
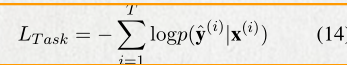
然后运用反向传播算法优化损失函数。
3.5 Task Discriminator
对抗学习:防止CWS的特有信息会出现在共享的信息中,对NER任务造成负面影响。
利用task discriminator 判断每个输入的句子来自哪个任务法人数据集。
任务区分器的计算如下:
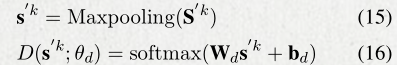
引入对抗学习的loss, 防止CWS的specific特征混入shared信息,
Es代表shared 特征提取器,D代表任务区分器
对抗学习loss训练共享模型提取出共享特征,导致任务区分器不能很好的对任务进行区分,产生loss。所以最小化这个loss函数,也就是 当共享的LSTM生成一个共享特征的表示会误导任务区分器,任务区分器必须尽最大可能的做出正确的判断。
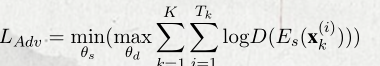
在softmax之前增加梯度逆转层,解决优化函数的极大极小问题。在训练阶段,最小化任务区分器的loss函数,然后通过梯度反转层,梯度变为相反的符号进而对抗的鼓励共享层学习共享词边界信息特征。
在训后,任务区分器和共享特征提取器会达到一个点:任务区分器不能通过共享特征提取器的输出判断该句子来自哪一个任务。
3.6 Training
最后的损失函数为:
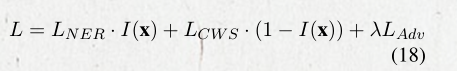
在训练过程中,每一轮都随机选择一个任务,然后从该任务的训练集中选取 一个batch的数据。通过Adam优化函数进行优化loss。因为二者的收敛率不同,所以根据NER的性能进行early stopping。
4. 实验
4.1 Datasets
NER: 微博数据集和sighan数据集
CWS: MSR 数据集
4.2 Setting
embedding size:100
LSTM size: 120
learning rate: 0.001
lambda: 0.06
droupout:0.3
multi-head: 8
batch size:64 / 20
pretrain embedding : 百度百科数据的word2vec
4.3 实验结果
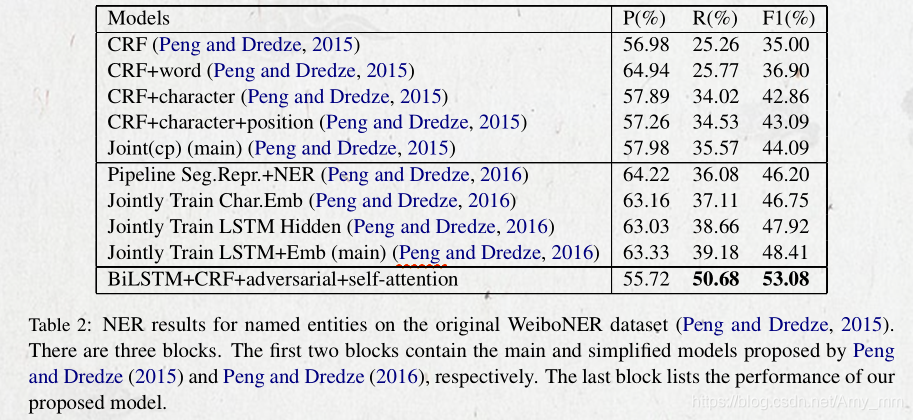
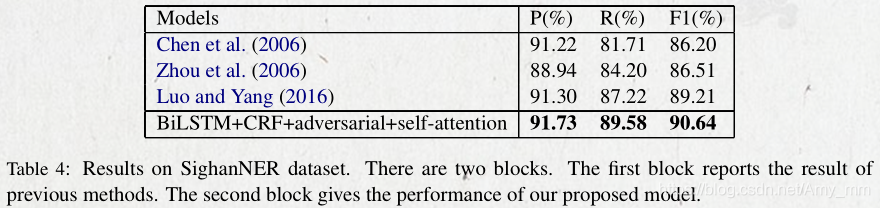
本文中加的小技巧的比较。
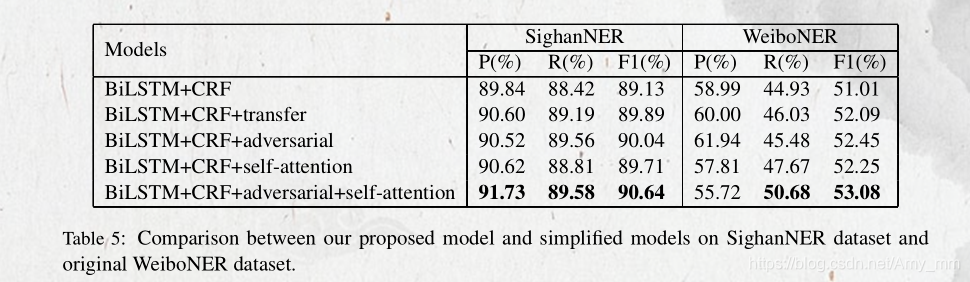
transfer learning:证明CWS中的词边界信息对于NER任务是有正向作用的
adversarial:证明对抗学习能够减少CWS中的独有信息混入共享信息中
self-attention: 正向作用
微博的性能较差的原因:
(1)数据集很少,训练集只有1300条。
(2)微博数据表达不正式。














 105
105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









