




 数据倾斜是指在并行处理大数据时,由于key分布不均导致的性能瓶颈。它在MapReduce的shuffle阶段尤为明显,表现为某些task处理的数据远超其他task,从而引发计算效率低下、负载不均和内存溢出等问题。数据倾斜的判断依据包括任务执行时间不一致、OOM错误和特定key的数据量异常。解决数据倾斜需要从业务逻辑和优化技术方案两方面着手。
数据倾斜是指在并行处理大数据时,由于key分布不均导致的性能瓶颈。它在MapReduce的shuffle阶段尤为明显,表现为某些task处理的数据远超其他task,从而引发计算效率低下、负载不均和内存溢出等问题。数据倾斜的判断依据包括任务执行时间不一致、OOM错误和特定key的数据量异常。解决数据倾斜需要从业务逻辑和优化技术方案两方面着手。
数据倾斜是什么
从本质上来看,数据倾斜指的是说在并行处理海量数据的时候,某个或者某些分区的数据分布不均匀导致引起性能瓶颈的情况。那么为什么会出现数据分布不均匀的情况?原理其实很简单,主要是因为key分布不均匀,重复的key很多,个别节点出现过载和拥塞。
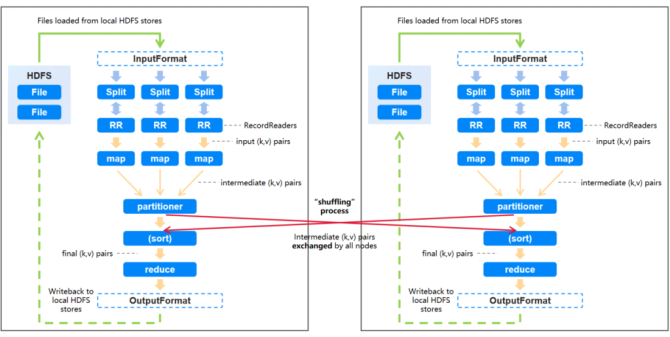
我们先来简单回顾上上一篇长提到的MapReduce的流程图,可以看到,输入的数据集被拆分成多个独立的部分(InputSplit)后会被分散到不同的节点上进行处理,生成多个Map tasks。
RecordReader会将数据转换为适合mapper读取的键值对后会发送到mapper进行进一步处理。Mapper针对每条输入记录(来自RecordReader)进行处理并生成新的键值对,对这些数据通过hash等方式散列到不同的reducer,然后开始spill(溢写)写入磁盘。
如果不同key的数据量分布不均,个别key对应的数据量特别大的话,就会发生数据倾斜。比如大部分key对应10条数据,但是个别key却对应了100万条数据,那么大部分task可能就只会分配到10条数据,然后1秒钟就运行完了,个别task可能分配到了100万数据,要运行一两个小时,最终等待时间可能会超出可接受范围,也可能会导致负载不均衡超出节点的计算能力,个别节点成为性能瓶颈。
下面我们举个例子来进一步理解,假设有这么两组数据:
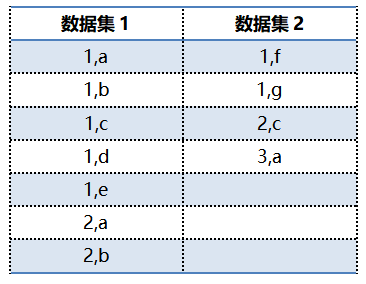
在MR程序启动后,Mappers从两个数据集中读取输入数据,partitioner获取中间输出后,基于key进行分区。
在进行shuffle的时候,通常会将同样的key对应的数据拉取到同一个task中进行处理,这个时候我们可以看到下方对应的task1就存在着数据倾斜的问题。
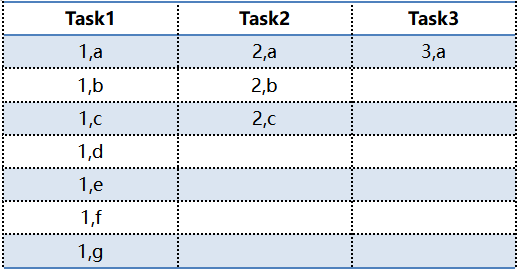
在这种情况下,Task2/Task3将比Task1更快的完成任务,因为Task1需要处理的数据更多。那可想而知,如果业务上存在大量key=1的倾斜数据,那么Task1对应的节点就会出现过载和拥塞,导致计算系统效率低下,最终由于读取过多数据引起task不稳定甚至故障。
如何判断是否出现数据倾斜
出现数据倾斜会存在以下现象:
- 在并行处理海量数据的时候,某个或者某些分区的数据更多,导致引起性能瓶颈。比如有1000个task,有999个1ms搞定了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









