






AI 绘画工具的选择与运用
1.工作场景下 AI绘画工具的选择
目前文生图的主流 Al 绘画平台主要有三种: Midjourney、Stable Diffusion、DALL·E-2。
如果要在实际工作场景中应用,我更推荐 Stable Diffusion。
通过对比,Stable Diffusion在数据安全性(可本地部署)、可扩展性(成熟插件多) 、风格丰富度(众多模型可供下载,也可以训练自有风格模型) 、费用版权 (开源免费、可商用) 等方面更适合我们的工作场景。

那么如何在实际工作中应用 Stable Diffusion 进行 AI 绘画?
要在实际工作中应用 AI 绘画,需要解决两个关键问题,分别是: 图像的精准控制和图像的风格控制。

1.图像精准控制
图像精准控制推荐使用 Stable Diffusion 的 ControlNet 插件。在 ControlNet出现之前,AI绘画更像开盲盒,在图像生成前,你永远都不知道它会是一张怎样的图。ControlNet的出现,真正意义上让 AI 绘画上升到生产力级别。简单来说 ControlNet 它可以精准控制 AI 图像的生成。

ControlNet 主要有 8 个应用模型: OpenPose、 Canny、HED、Scribble、MIsd、SegNormal
Map、Depth。以下做简要介绍:
OpenPose 姿势识别
它还可以生成多人的姿势,此通过姿势识别,达到精准控制人体动作。除了生成单人的姿势,外还有手部骨骼模型,解决手部绘图不精准问题。以下图为例:
左侧为参考图像,经OpenPose精准识别后,得出中间的骨骼姿势,再用文生图功能,描述主体内容、场景细节和画风后,就能得到一张同样姿势,但风格完全不同的图。

Canny 边缘检测
Canny 模型可以根据边缘检测,,从原始图片中提取线稿,再根据提示词,来生成同样构图的画面,也可以用来给线稿上色,

HED 边缘检测
跟 Canny 类似,但自由发挥程度更高。HED边界保留了输入图像中的细节,绘制的人物明暗对比明显,轮廓感更强,适合在保持原来构图的基础上对画面风格进行改变时使用。

Scribble 黑白稿提取
涂鸦成图,比 HED 和 Canny 的自由发挥程度更高,也可以用于对手绘线稿进行着色处理

Mlsd 直线检测
通过分析图片的线条结构和几何形状来构建出建筑外框,适合建筑设计的使用

Seg 区块标注
通过对原图内容进行语义分割,可以区分画面色块,适用于大场景的画风更改

Normal Map 法线贴图
适用于三维立体图,通过提取用户输入图片中的 3D 物体的法线向量,以法线为参考绘制出副新图,此图与原图的光影效果完全相同。

Depth 深度检测
通过提取原始图片中的深度信息,可以生成具有同样深度结构的图。还可以通过 3D 建模软件直接搭建出一个简单的场景,再用 Depth 模型染出图

ControlNet 还有项关键技术是可以开启多个 ControlNet 的组合使用,对图像进行多条件控制。例如:
你想对一张图像的背景和人物姿态分别进行控制,那我们可以配置 2 个ControlNet,第1个 ControlNet 使用 Depth模型对背景进行结构提取并重新风格化,第 2个ControlNet 使用 OpenPose 模型对人物进行姿态控制。此外在保持 Seed种子数相同的情况下,固定出画面结构和风格,然后定义人物不同姿态,渲染后进行多帧图像拼接,就能生成一段动画。
以上通过 ControlNet 的 8 个主要模型,我们解决了图像结构的控制问题。接下来就是对图像风格进行控制。
2.图像风格控制
Stable Difusion 实现图像风格化的途径主要有以下几种: Artist 艺术家风格、Checkpoint预训练大模型、LORA微调模型、Textual Inversion 文本反转模型。

Artist 艺术家风格
主要通过画作种类 Tag (如: oil painting、ink painting、comic、illustration) ,画家/画风 Tag (如:
Hayao Miyazaki、 Cyberpunk) 等控制图像风格。网上也有比较多的这类风格介绍,如:
/top-sd-artists
但需要注意的是,使用艺术家未经允许的风格进行商用,会存在侵权问题。

2
AI 绘画工具的部署安装
以下主要介绍三种部署安装方式:云端部署、本地部署、本机安装,各有优缺点。当本机硬件条件支持的情况下,推荐本地部署,其它情况推荐云端方式。
1.云端部署 Stable Diffusion
通过 Google Colab 进行云端部署,推荐将成熟的 Stable Diffusion Colab 项目复制到自己的 Google
云端硬盘运行,省去配置环境麻烦。这种部署方式的优点是: 不吃本机硬件,在有限时间段内,可以免费使用 Google Colab 强大的硬件资源,通常能给到
15G 的 GPU 算力,出图速度非常快。缺点是: 免费 GPU 使用时长不固定,通常情况下一天有几个小时的使用时长,如果需要更长时间使用,可以订阅Colab 服务

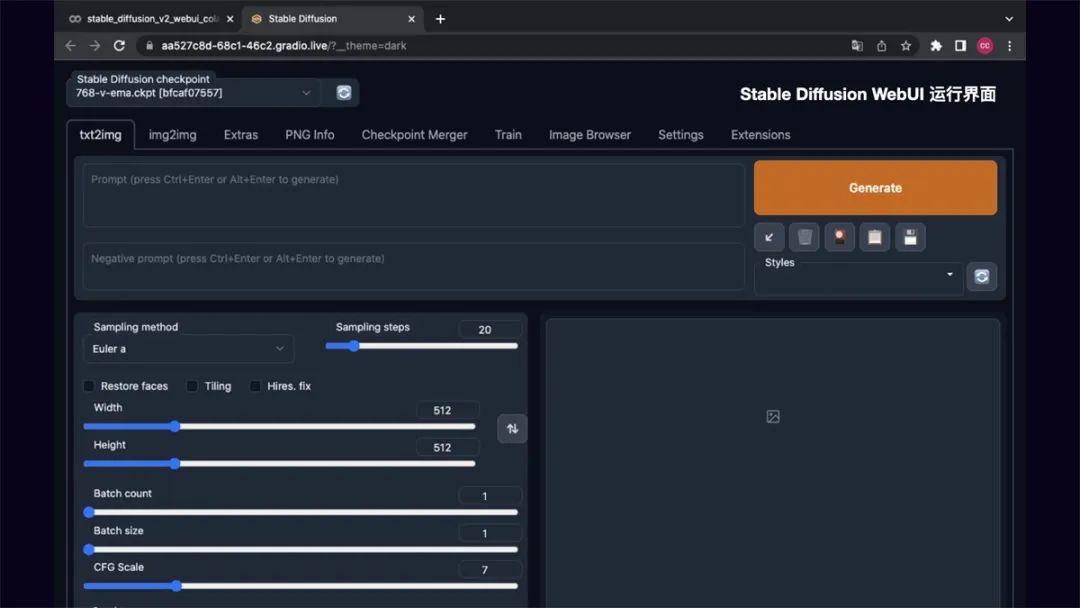
Stable Diffusion WebUl 运行界面如下,在后面的操作方法里我会介绍下 Stable Diffusion的基础操作。
2.本地部署 Stable Diffusion
相较于 Google Colab 云端部署,本地部署 Stable Diffusion的可扩展性更强,可自定义安装需要的模型和插件,隐私性和安全性更高,自由度也更高,而且完全免费。当然缺点是对本机硬件要求高,Windows 需要 NVIDIA显卡,8G 以上显存,16G 以上内存。Mac 需要M1/M2 芯片才可运行。

3.本机安装 DiffusionBee
如果觉得云端部署和本地部署比较繁琐,或对使用要求没有那么高,那就试下最简单的一键安装方式。
下载 Diffusionbee 应用: diffusionbee.com/download。
优点是方便快捷,缺点是扩展能力差(可以安装大模型,无法进行插件扩展,如 ControlNet) 。


3
AI 绘画工具的操作技巧
1.Stable Diffusion 基础操作
文生图
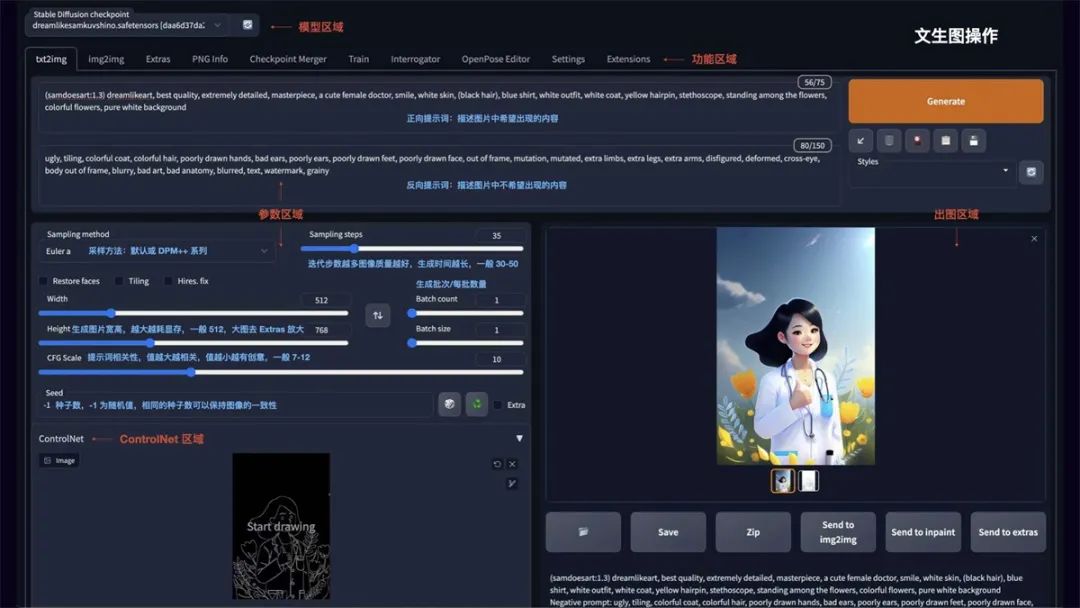
如图所示 Stable Diffusion WebUl 的操作界面主要分为: 模型区域、功能区域、参数区域出图区域
txt2img 为文生图功能,重点参数介绍:
正向提示词: 描述图片中希望出现的内容
反向提示词: 描述图片中不希望出现的内容
Sampling method: 采样方法,推荐选择 Euler a 或 DPM++ 系列,采样速度快
Sampling steps: 迭代步数,数值越大图像质量越好,生成时间也越长,一般控制在 30-50就能出效果
Restore faces: 可以优化脸部生成
Width/Height: 生成图片的宽高,越大越消耗显存,生成时间也越长,一般方图 512x512竖图 512x768,需要更大尺寸,可以到 Extras
功能里进行等比高清放大
CFG: 提示词相关性,数值越大越相关,数值越小越不相关,一般建议 7-12 区间
Batch count/Batch size: 生成批次和每批数量,如果需要多图,可以调整下每批数量
Seed: 种子数,-1 表示随机,相同的种子数可以保持图像的一致性,如果觉得一张图的结构不错,但对风格不满意,可以将种子数固定,再调整 prompt 生成
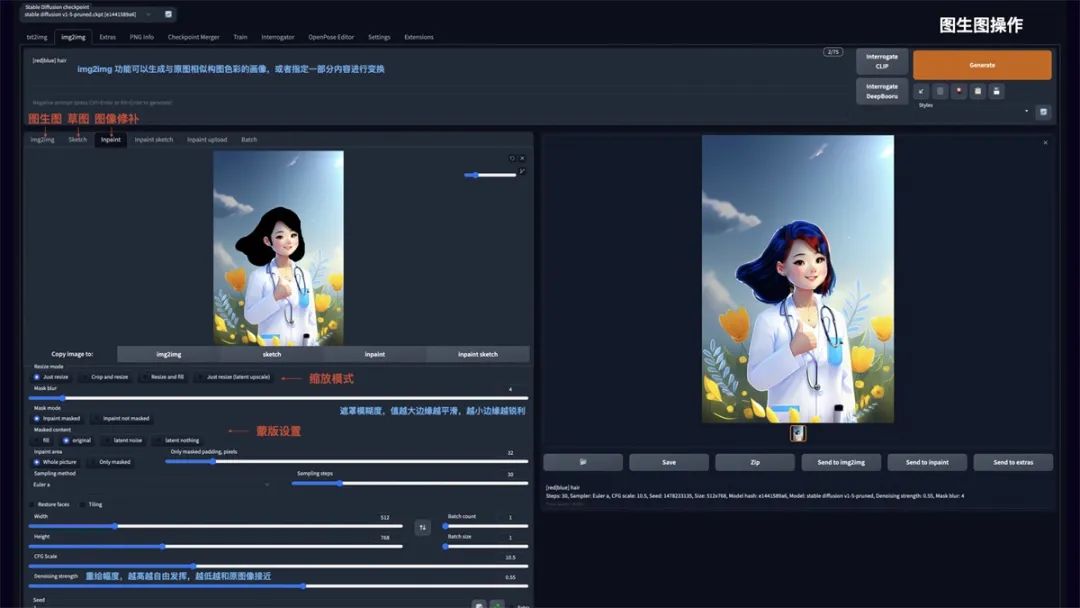
图生图
img2img 功能可以生成与原图相似构图色彩的画像,或者指定一部分内容进行变换。可以重点使用 Inpaint 图像修补这个功能:
Resize mode: 缩放模式,Just resize 只调整图片大小,如果输入与输出长宽比例不同,图片会被拉伸。Crop and resize
裁剪与调整大小,如果输入与输出长宽比例不同,会以图片中心向四周,将比例外的部分进行裁剪。Resize and fill
调整大小与填充,如果输入与输出分辨率不同,会以图片中心向四周,将比例内多余的部分进行填充
Mask blur: 蒙版模糊度,值越大与原图边缘的过度越平滑,越小则边缘越锐利
Mask mode: 蒙版模式,Inpaint masked 只重绘涂色部分,Inpaint not masked 重绘除了涂色的部分
Masked Content: 蒙版内容,fill 用其他内容填充,original 在原来的基础上重绘
Inpaint area: 重绘区域,Whole picture 整个图像区域,Only masked 只在蒙版区域
Denoising strength: 重绘幅度,值越大越自由发挥,越小越和原图接近
ControlNet
安装完 ControlNet 后,在 txt2img 和 img2img 参数面板中均可以调用 ControlNet。操作说明:
Enable: 启用 ControlNet
Low VRAM: 低显存模式优化,建议 8G 显存以下开启
Guess mode: 猜测模式,可以不设置提示词,自动生成图片
Preprocessor: 选择预处理器主要有 OpenPose、Canny、HED、Scribble、MIsd.Seg、Normal Map、Depth
Model: ControlNet 模型,模型选择要与预处理器对应
Weight: 权重影响,使用 ControlNet 生成图片的权重占比影响
Guidance strength(T): 引导强度,值为 1时,代表每选代 1 步就会被 ControlNet引导1次
Annotator resolution: 数值越高,预处理图像越精细Canny low/high threshold: 控制最低和最高采样深度Resize
mode: 图像大小模式,默认选择缩放至合适
Canvas width/height: 画布宽高
Create blank canvas: 创建空白画布
Preview annotator result: 预览注释器结果,得到一张 ControlNet 模型提取的特征图片
Hide annotator result: 隐藏预览图像窗

LORA 模型训练说明
前面提到 LORA 模型具有训练速度快,模型大小适中 (100MB 左右),配置要求低 (8G 显存),能用少量图片训练出风格效果的优势。
以下简要介绍该模型的训练方法:
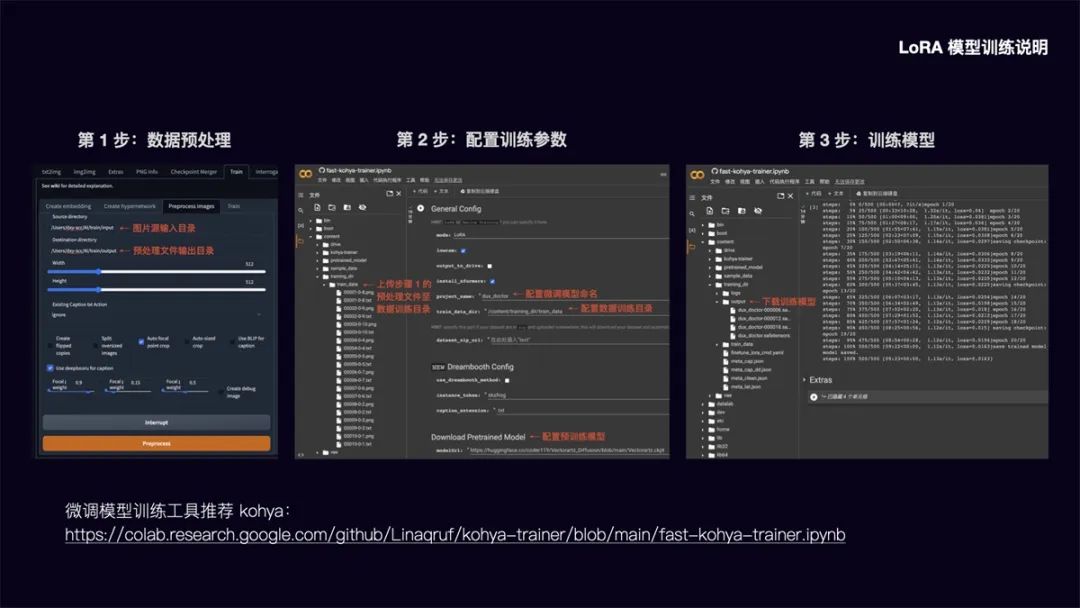
第 1步:数据预处理
在Stable Diffusion WebUl 功能面板中,选择 Train 训练功能,点选 Preprocess images 预处理图像功能。在
Source directory 栏填入你要训练的图片存放目录,在 Destinationdirectory 栏填入预处理文件输出目录。width 和
height 为预处理图片的宽高,默认为512x512,建议把要训练的图片大小统一改成这个尺寸,提升处理速度。勾选 Auto focalpoint crop
自动焦点裁剪,勾选 Use deepbooru for caption 自动识别图中的元素并打上标签。点击 Preprocess 进行图片预处理。
第 2 步: 配置模型训练参数
在这里可以将模型训练放到 Google Colab 上进行,调用 Colab 的免费 15G GPU 将大大提升模型训练速度。LoRA
微调模型训练工具我推荐使用 Kohya,运行
KohyaColab:
https://colab.research.google.com/github/Linaqruf/kohyatrainer/blob/main/fast-
kohya-traineripynb
配置训练参数
先在 content 目录建立 training_dir/training_data 目录,将步骤 1
中的预处理文件上传至该数据训练目录。然后配置微调模型命名和数据训练目录,在 Download Pretrained Model
栏配置需要参考的预训练模型文件。其余的参数可以根据需要调整设置。
第 3 步: 训练模型
参数配置完成后,运行程序即可进行模型训练。训练完的模型将被放到 training dir/output目录,我们下载 safetensors
文件格式的模型,存放到 stable-diffusion-webui/models/Lora 日录中即可调用该模型。由于直接从 Colab
下载速度较慢,另外断开Colab 连接后也将清空模型文件,这里建议在 Extras 中配置 huggingface 的 Write
Token.将模型文件上传到 huggingface 中,再从 huggingface File 中下载,下载速度大大提升,文件也可进行备份。
2.Prompt 语法技巧
文生图模型的精髓在于 Prompt 提示词,如何写好 Prompt 将直接影响图像的生成质量
提示词结构化
Prompt 提示词可以分为 4 段式结构: 质风 + 面主体 + 面细节 + 风格参考画面画风: 主要是大模型或 LORA 模型的
Tag、正向画质词、画作类型等画面主体: 画面核心内容、主体人/事/物/景、主体特征/动作等
画面细节: 场景细节、人物细节、环境灯光、画面构图等
风格参考: 艺术风格、渲染器、Embedding Tag 等

提示词语法
提示词排序:越前面的词汇越受 AI 重视,重要事物的提示词放前面
增强/减弱: (提示词:权重数值),默认 1,大于 1 加强,低于 1 减弱。如(doctor:1.3)混合: 提示词|提示词,实现多个要素混合,如[red
blue] hair 红蓝色头发混合
+ 和 AND: 用于连接短提示词,AND 两端要加空格
分步染:[提示词 A:提示词 B:数值],先按提示词 A 生成,在设定的数值后朝提示词 B 变化。如[dog🐱30] 前 30
步画狗后面的画猫,[dog🐱0.9] 前面 90%画狗后面 10%画猫
正向提示词: masterpiece,best quality 等画质词,用于提升画面质量
反向提示词: nsfw, bad hands, missing fingers…, 用于不想在画面中出现的内容
Emoji: 支持 emoji,如 形容表情,当 修饰手

常用提示词举例:

3.ChatGPT 辅助生成提示词
我们也可以借助 ChatGPT 帮我们生成提示词参考
给 ChatGPT 一段示例参考: /guides/using-openai-chat-gpt-to-write-stable-
diffusion.prompts
根据参考生成 Prompts,再添加细节润色

4.Stable Diffusion 全中文环境配置
在实际使用中,我们还可以把 Stable Diffusion 配置成全中文环境,这将大大增加操作友好度。全中文环境包括了 Stable Diffusion
WebUl 的汉化和 Prompt 支持中文输入。
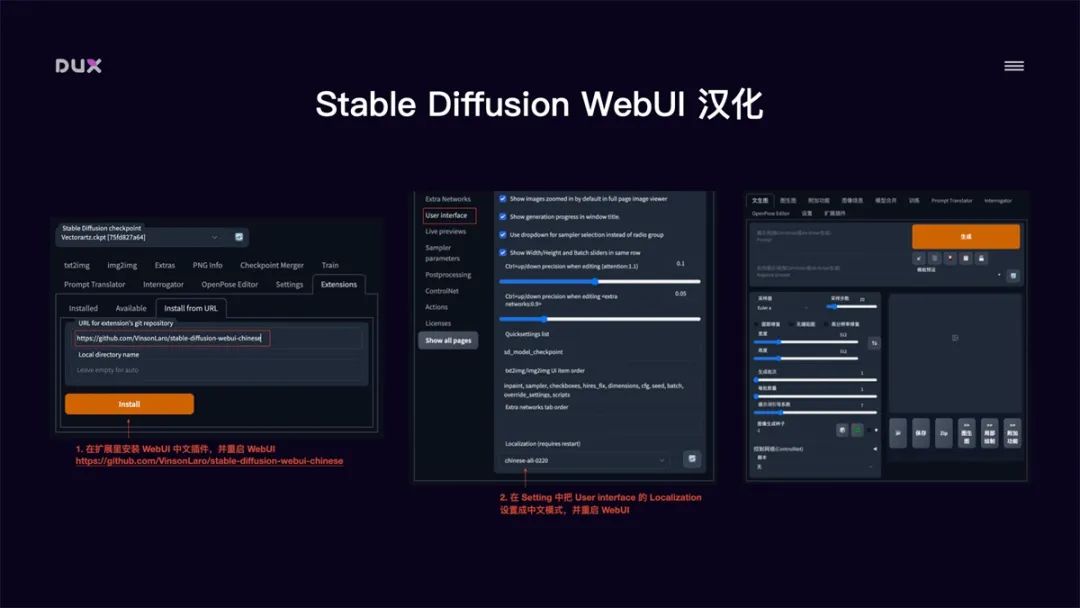
Stable Diffusion WebUl 汉化
安装中文扩展插件: 点击 Extensions 选择Install from URL,输入
https://github.com/VinsonLaro/stable-diffusion-webui-chinese,点击 Install,并重启
WebUI
切换到中文模式: 在 Settings 面板中,将 User interface 中的 Localization 设置成 Chinese中文模式,重启
WebUl 即可切换到中文界面
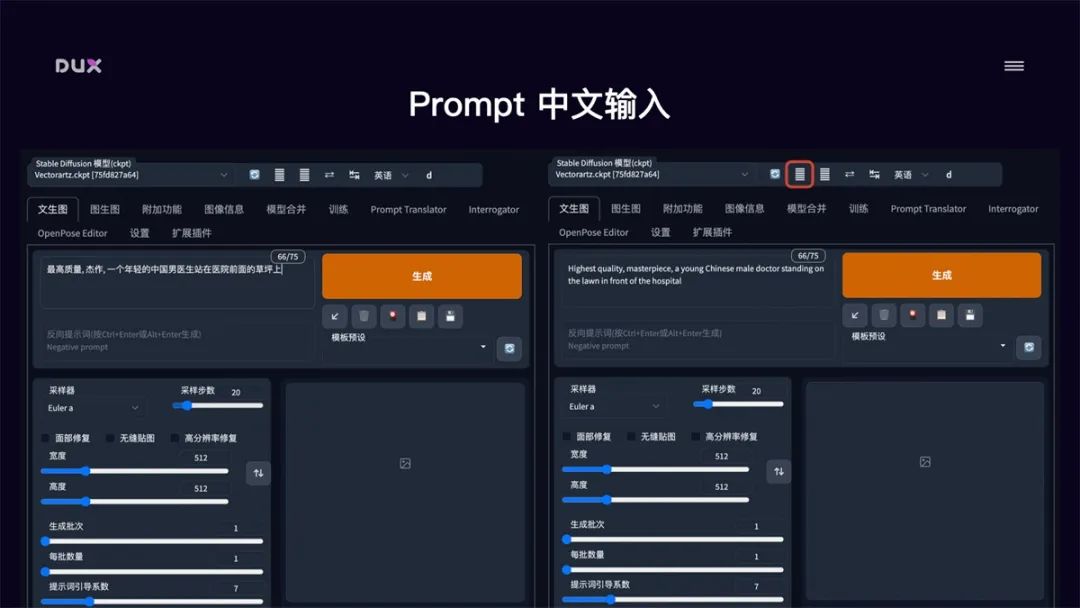
Prompt 中文输入
下载提示词中文扩展插件: https://github.com/butaixianran/Stable-Difusion-Webui-Prompt-
Translator,将项目作为 zip 文件下载,解压后放到 stable-diffusion-webui/extensions 目录中,重启 WebUl
调用百度翻译 API: 去 api.fanyi.baidu.com 申请一个免费 API Key,并将翻译服务开通。在管理控制台的开发者信息页中确认 APP
ID 和密
在 Stable Diffusion WebUl 的 Prompt Translator 面板中,选择百度翻译引擎,并将申请的APPID 和
密钥填写进去,点击保存
使用: 在 Stable Diffusion WebUl
页面顶部会出现一个翻译工具栏,我们在提示词输入框中输入中文,点击工具栏中的翻译就能自动把提示词替换成英文
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









