







由于自己最近在准备面试,所以也找了些面试题,以下内容是自己的总结,通过从多次的面试经验中提取出了一些高频的可能会问到的问题,这些面试问题的答案仅供参考。
1. 什么是ANR,如何避免它?
应用程序有一段时间反应不灵敏,系统会向用户显示一个对话框,提示应用程序无响应。默认情况下,在android中Activity的最长执行时间是5秒,BroadcastReceiver的最长执行时间则是10秒。
Android应用程序通常是运行在一个单独的线程(例如,main)里。这意味着你的应用程序所做的事情如果在主线程里占用了太长的时间的话,就会引发ANR对话框,因为你的应用程序并没有给自己机会来处理输入事件或者Intent广播。
因此,运行在主线程里的任何方法都尽可能少做事情。特别是,Activity应该在它的关键生命周期方法(如onCreate()和onResume())里尽可能少的去做创建操作。潜在的耗时操作,例如网络或数据库操作,或者高耗时的计算如改变位图尺寸,应该在子线程里(或者以数据库操作为例,通过异步请求的方式)来完成。替代的方法是,主线程应该为子线程提供一个Handler,以便完成时能够提交给主线程。以这种方式设计你的应用程序,将能保证你的主线程保持对输入的响应性并能避免由于5秒输入事件的超时引发的ANR对话框。这种做法应该在其它显示UI的线程里效仿,因为它们都受相同的超时影响。
2. 四大组件
Activity、Broadcast Receiver、Content provide、Service
3. OOM
可能出现的情况:
1.数据库的cursor没有关闭
2.构造adapter时,没有使用缓存convertView
衍生listview的优化问题—–减少创建view的对象,充分使用convertView,可以使用静态类来优化处理getview的过程
3.Bitmap对象不使用时采用recycle()释放内存
4.activity中的对象的生命周期大于activity
参考:
1. 使用更加轻量的数据结构例如,我们可以考虑使用ArrayMap/SparseArray而不是HashMap等传统数据结构。通常的HashMap的实现方式更加消耗内存,因为它需要一个额外的实例对象来记录Mapping 操作。另外,SparseArray更加高效,在于他们避免了对key与value的自动装箱(autoboxing),并且避免了装箱后的解箱。
2. 避免在Android里面使用Enum,Android官方培训课程提到过“Enums often require more than twice as much memory as staticconstants. You should strictly avoid using enums on Android.”, 具体原理请参考《Android性能优化典范(三)》,所以请避免在Android里面使用到枚举。
3. 减小Bitmap对象的内存占用 Bitmap是一个极容易消耗内存的大胖子,减小创建出来的Bitmap的内存占用可谓是重中之重,通常来说有以下2个措施:inSampleSize:缩放比例,在把图片载入内存之前,我们需要先计算出一个合适的缩放比例,避免不必要的大图载入。decode format:ARGB_6666/RBG_545/ARGB_4444/ALPHA_6,解码格式,选择的不同存在很大差异。
4.Bitmap对象的复用缩小Bitmap的同时,也需要提高BitMap对象的复用率,避免频繁创建BitMap对象,复用的方法有以下2个措施LRUCache :“最近最少使用算法”在Android中有极其普遍的应用。 ListView与GridView等显示大量图片的控件里,就是使用LRU的机制来缓存处理好的Bitmap,把近期最少使用的数据从缓存中移除,保留使用最频繁的数据,inBitMap高级特性:利用inBitmap的高级特性提高Android系统在Bitmap分配与释放执行效率。使用inBitmap属性可以告知Bitmap解码器去尝试使用已经存在的内存区域,新解码的Bitmap会尝试去使用之前那张Bitmap在Heap中所占据的pixel data内存区域,而不是去问内存重新申请一块区域来存放Bitmap。利用这种特性,即使是上千张的图片,也只会仅仅只需要占用屏幕所能够显示的图片数量的内存大小。
5 使用更小的图片 在涉及给到资源图片时,我们需要特别留意这张图片是否存在可以压缩的空间,是否可 以使用更小的图片。尽量使用更小的图片不仅可以减少内存的使用,还能避免出现大量的 InflationException。假设有一张很大的图片被XML文件直接引用,很有可能在初始化视图时会因为内存 不足而发生InflationException,这个问题的根本原因其实是发生了OOM。
6.StringBuilder 在有些时候,代码中会需要使用到大量的字符串拼接的操作,这种时候有必要考虑使用 StringBuilder来替代频繁的“+”。
7.避免在onDraw方法里面执行对象的创建 类似onDraw等频繁调用的方法,一定需要注意避免在这里做 创建对象的操作,因为他会迅速增加内存的使用,而且很容易引起频繁的gc,甚至是内存抖动。4. Activity生命周期
了解Activity的生命周期的根本目的就是为了设计用户体验更加良好的应用。因为Activity就相当于MVC中的View层,是为了更好的向用户展现数据,并与之交互。了解Activity的生命周期和各回调方法的触发时机,我们可以更好的在合适的地方向用户展现数据(因为每个应用每个Activity的作用不同,所以具体每个回调方法的最佳时间不好把握,但是只要遵循最基本的原则即可),保证数据的完整性和程序的良好运行。
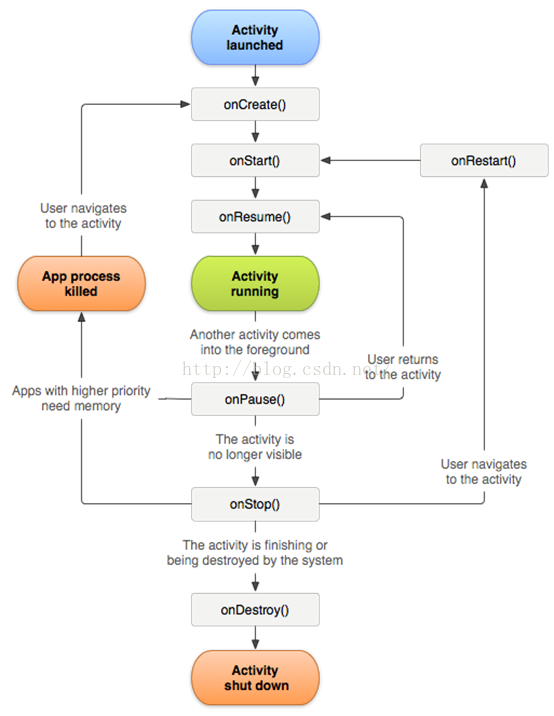
简要说明:
onCreate(BundlesavedInstanceState):创建activity时调用。设置在该方法中,还以Bundle中可以提出用于创建该 Activity 所需的信息。
onStart():activity变为在屏幕上对用户可见时,即获得焦点时,会调用。
onResume():activity开始与用户交互时调用(无论是启动还是重新启动一个活动,该方法总是被调用的)。
onPause():activity被暂停或收回cpu和其他资源时调用,该方法用于保存活动状态的。。
onStop():activity被停止并转为不可见阶段及后续的生命周期事件时,即失去焦点时调 用。
onRestart():重新启动activity时调用。该活动仍在栈中,而不是启动新的活动。
onDestroy():activity被完全从系统内存中移除时调用,该方法被调用可能是因为有人直接调用 finish()方法 或者系统决定停止该活动以释放资源。
1、不设置Activity的android:configChanges时,切屏会重新调用各个生命周期,切横屏时会执行一次,切竖屏时也是一次
2、设置Activity的android:configChanges="orientation"时,切屏还是会重新调用各个生命周期,切横、竖屏时只会执行一次,但是低版本的系统,不会重新调用。
3、设置Activity的android:configChanges="orientation|keyboardHidden|screenSize"时,切屏不会重新调用各个生命周期,只会执行onConfigurationChanged方法.
详情可参考:亲测Android横竖屏切换小结,带测试结果
锁定屏与解锁屏幕只会调用onPause(),而不会调用onStop方法,开屏后则调用onResume().
点击MainActivity按钮跳转到AnotherAcitivty,再回到MainActivity.写出两者相应生命周期调用顺序
AnotherActivity通过Back键返回Main
Main(onPause)-->Anoth(onCreate,onStart,onResume)-->Main(onStop)-->Anoth(onPause)--->Main(onRestart,onStart,onResume)--->Anoth(onStop,onDestroy)
AnotherActivity通过Intent跳转返回Main
Main(onPause)-->Anoth(onCreate,onStart,onResume)-->Main(onStop)-->Anoth(onPause)--->Main(onCreate,onStart,onResume)--->Anoth(onStop)
5. MVC
mvc是model,view,controller的缩写,mvc包含三个部分:
模型(model)对象:是应用程序的主体部分,所有的业务逻辑都应该写在该层。
视图(view)对象:是应用程序中负责生成用户界面的部分。也是在整个mvc架构中用户唯一可以看到的一层,接收用户的输入,显示处理结果。
控制器(control)对象:是根据用户的输入,控制用户界面数据显示及更新model对象状态的部分,控制器更重要的是一种导航功能,响应用户触发的相关事件,交给m处理。
1)视图层(view):一般采用xml文件进行界面的描述,使用的时候可以非常方便的引入,当然,如何你对android了解的比较的多了话,就一定可以想到在android中也可以使用javascript+html等的方式作为view层,当然这里需要进行java和javascript之间的通信,幸运的是,android提供了它们之间非常方便的通信实现。
2)控制层(controller):android的控制层的重任通常落在了众多的acitvity的肩上,这句话也就暗含了不要在acitivity中写代码,要通过activity交割model业务逻辑层处理,这样做的另外一个原因是android中的acitivity的响应时间是5s,如果耗时的操作放在这里,程序就很容易被回收掉。
3)模型层(model):对数据库的操作、对网络等的操作都应该在model里面处理,当然对业务计算等操作也是必须放在的该层的。
6. Handler
andriod提供了Handler和Looper来满足线程间的通信。Handler先进先出原则。Looper类用来管理特定线程内对象之间的消息交换(MessageExchange)。UI thread 通常就是mainthread,而Android启动程序时会替它建立一个Message Queue。
1) Message:Message是在线程之间传递消息,它可以在内部携带少量的消息,用于在不同的线程中交换数据。
2) Looper: 一个线程可以产生一个Looper对象,由它来管理此线程里的MessageQueue(消息队列)。调用Looper的loop()方法后,就会进入到一个无限循环当中,然后每当发现Message Queue中有消息时,都会将其传递到Handle的handleMessage()方法中。每个线程中也只会有一个Looper对象。
3) Message Queue(消息队列):用来存放通过handle发送的消息,等待被处理。每个线程中只会有一个Message Queue.
4) Handler: 你可以构造Handler对象来与Looper沟通,以便push新消息到Message Queue里;或者接收Looper从Message Queue所送来的消息。
7. Android 动画有哪几种?描述一下
在Android3.0(即API Level11)以前,Android仅支持2种动画:分别是Frame Animation(逐帧动画)和Tween Animation(补间动画),在3.0之后Android支持了一种新的动画系统,称为:Property Animation(属性动画)
(1)Frame Animation(帧动画)主要用于播放一帧帧准备好的图片,类似GIF图片,优点是使用简单方便、缺点是需要事先准备好每一帧图片;
(2)Tween Animation(补间动画)仅需定义开始与结束的关键帧,而变化的中间帧由系统补上,优点是不用准备每一帧,缺点是只改变了对象绘制,而没有改变View本身属性。因此如果改变了按钮的位置,还是需要点击原来按钮所在位置才有效。有平移、缩放、旋转、透明等四种实现方式。
(3)Property Animation(属性动画)是3.0后推出的动画,优点是使用简单、降低实现的复杂度、直接更改对象的属性、几乎可适用于任何对象而仅非View类,3.0之前的版本可使用github第三方开源库nineoldandroids.jar进行支持!
8. 返回键与Home键区别?
back键默认行为是finish处于前台的Activity的即Activity的状态为Destroy状态为止,再次启动该Activity是从onCreate开始的(不会调用onSaveInstanceState方法)。Home键默认是stop前台的Activity即状态为onStop为止而不是Destroy,若再次启动它,会调用onSaveInstanceState方法,保持上次Activity的状态则是从OnRestart开始的---->onStart()--->onResume()。
9. 请介绍下ContentProvider是如何实现数据共享的。
一个程序可以通过实现一个Content provider的抽象接口将自己的数据完全暴露出去,而且Content providers是以类似数据库中表的方式将数据暴露。Content providers存储和检索数据,通过它可以让所有的应用程序访问到,这也是应用程序之间唯一共享数据的方法。要想使应用程序的数据公开化,可通过2种方法:创建一个属于你自己的Content provider或者将你的数据添加到一个已经存在的Content provider中,前提是有相同数据类型并且有写入Content provider的权限。
10. String和stringbuffer、stringbuilder
String:字符串常量 是对象不是基本数据类型.
为不可变对象,一旦被创建,就不能修改它的值.
对于已经存在的String对象的修改都是重新创建一个新的对象,然后把新的值保存进去.
String 是final类,即不能被继承.
StringBuffer:字符串变量(线程安全)
是一个可变对象,当对他进行修改的时候不会像String那样重新建立对象
它只能通过构造函数来建立,
StringBuffer sb = newStringBuffer();
对象被建立以后,在内存中就会分配内存空间,并初始保存一个null.通过它的append方法向其赋值.
sb.append("hello");
字符串连接操作中StringBuffer的效率要明显比String高,且节省空间
StringBuilder 字符串变量(非线程安全)
大多数情形下,建议采用此类。因为在大多数实现中,它比 StringBuffer要快。两者的方法基本相同。
我们的程序是在单线程下运行,或者是不必考虑到线程同步问题,我们应该优先使用StringBuilder类;当然,如果要保证线程安全,自然非StringBuffer莫属了。
String对象是不可变对象,每次操作Sting 都会重新建立新的对象来保存新的值。
为什么要把String类设计成不可变类,是它的用途决定的。不可变类有一些优点,比如因为它的对象是只读的,所以多线程并发访问也不会有任何问题。当然也有一些缺点,比如每个不同的状态都要一个对象来代表,可能会造成性能上的问题
StringBuffer对象实例化后,只对这一个对象操作。
11.抽象类和接口的区别
含有 abstract方法的类必须定义为abstractclass, abstract class类中的方法不必是抽象的。 abstract class类中定义抽象方法必须在具体(Concrete)子类中实现,所以,不能有抽象构造方法或抽象静态方法。如果的子类没有实现抽象父类中的所有抽象方法,那么子类也必须定义abstract类型。
接口(interface)可以说成是抽象类的一种特例,接口中的所有方法都必须是抽象的。接口中的方法定义默认为public abstract类型,接口中的成员变量类型默认为public static final。
下面比较一下两者的语法区别:
1.抽象类可以有构造方法,接口中不能有构造方法。
2.抽象类中可以有普通成员变量,接口中没有普通成员变量
3.抽象类中可以包含非抽象的普通方法,接口中的所有方法必须都是抽象的,不能有非抽象的普通方法。
4. 抽象类中的抽象方法的访问类型可以是public,protected 和(默认类型,虽然
eclipse 下不报错,但应该也不行),但接口中的抽象方法只能是public类型的并且默认即为publicabstract类型。
5. 抽象类中可以包含静态方法,接口中不能包含静态方法
6. 抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任意,但接口中定义的变量只能是 public static final类型,并且默认即为public static final类型。
12. 什么时候用抽象类什么时候用接口?
它用于要创建一个体现某些基本行为的类,并为该类声明方法,但不能在该类中实现该类的情况;
接口(interface)是抽象类的变体。在接口中,所有方法都是抽象的。
接口和抽象类都是多态的一种表现,接口和抽象类都能描述一般性的公有特征。
由于子类只能扩展一个父类,而能实现多个接口,所以接口比抽象类更灵活。但是接口不能包括具体的方法(即没有方法体,只有方法名),而抽象类可以(比如非抽象的方法),要将两种好处结合起来,可以创建一个接口和一个实现该接口的抽象类(便利类),然后根据情况决定使用哪个。
13.java抽象类或接口被继承后方法一定要重写吗
抽象类中的非抽象方法不用重写,其他必须重写,接口的方法必须重写;
继承自抽象类的,如果子类不是抽象的话,那所有抽象方法必须从写普通方法不用重写;如果子类是抽象的那就所有的方法都不用必须重写
14.java三大特征封装、继承、多态
封装:把对同一事物进行操作的方法和相关方法放在同一个类中,使用者不必关心类的具体实现细节,隐藏对象的内部结构,增加安全性、简化编程;
继承:子类共享父类的数据和方法,实现代码的复用性,减少代码冗余,使维护和扩展变得简单;
多态:同一个操作作用于不同对象,会有不同的结果,增加了类的灵活性、可替换性、可扩充性。
15.重载和重写的区别
1、重载:
是一个类里面,写了多了同名的方法,参数列表不同,各个方法的返回值类型可以不一样。
2、重写:
也叫覆盖,指在子类中定义一个与父类中方法同名同参数列表的方法。因为子类会继承父类的方法,而重写就是将从父类继承过来的方法重新定义一次,重新填写方法中的代码。
16.final, finally, finalize 的区别。
final 用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。
内部类要访问局部变量,局部变量必须定义成 final类型。
finally是异常处理语句结构的一部分,表示总是执行。
finalize是 Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等。JVM不保证此方法总被调用
17.error 和 exception有什么区别?
error表示系统级的错误和应用程序本身无法克服和恢复的一种严重问题。比如说内存溢出。不可能指望程序能处理这样的情况。
exception表示一种设计或实现问题。也就是说,它表示如果程序运行正常,从不会发生的情况。表示需要捕捉或者需要程序进行处理的异常,用户可以克服并解决的,是程序必须处理的,程序不应该死掉。
18.
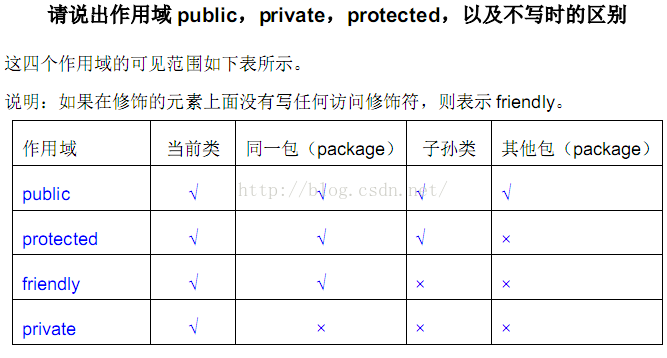
19.请写出你最常见到的 5 个 runtime exception
1,ClassCastException
Object x = new Integer(0);
System.out.println((String)x);
当试图将对象强制转换为不是实例的子类时,抛出该异常(ClassCastException)
2,ArithmeticException
int a=5/0;
一个整数“除以零”时,抛出ArithmeticException异常。
3, NullPointerException
String s=null;
int size=s.size();
当应用程序试图在需要对象的地方使用 null 时,抛出NullPointerException异常
4, IndexOutOfBoundsException
"hello".indexOf(-1);
指示索引或者为负,或者超出字符串的大小,抛出IndexOutOfBoundsException异常
5, NegativeArraySizeException
String[] ss=new String[-1];
如果应用程序试图创建大小为负的数组,则抛出NegativeArraySizeException异常。
sleep指线程被调用时,占着CPU不工作,形象地说明为“占着CPU睡觉”,此时,系统的CPU部分资源被占用,其他线程无法进入,会增加时间限制。
wait指线程处于进入等待状态,形象地说明为“等待使用CPU”,此时线程不占用任何资源,不增加时间限制
第一种解释:
功能差不多,都用来进行线程控制,他们最大本质的区别是:sleep()不释放同步锁,wait()释放同步锁.
还有用法的上的不同是:sleep(milliseconds)可以用时间指定来使他自动醒过来,如果时间不到你只能调用interreput()来强行打断;wait()可以用notify()直接唤起.
第二种解释:
sleep是Thread类的静态方法。sleep的作用是让线程休眠制定的时间,在时间到达时恢复,也就是说sleep将在接到时间到达事件时恢复线程执行,例如:
try{
System.out.println("I'm going to bed");
Thread.sleep(1000);
System.out.println("I wake up");
}
catch(IntrruptedException e) {
}
wait是Object的方法,也就是说可以对任意一个对象调用wait方法,调用wait方法将会将调用者的线程挂起,直到其他线程调用同一个对象的notify方法才会重新激活调用者,例如:
//Thread 1
try{
obj.wait();//suspend thread until obj.notify() is called
}
catch(InterrputedException e) {
}
第三种解释:
这两者的施加者是有本质区别的.
sleep()是让某个线程暂停运行一段时间,其控制范围是由当前线程决定,也就是说,在线程里面决定.好比如说,我要做的事情是 "点火->烧水->煮面",而当我点完火之后我不立即烧水,我要休息一段时间再烧.对于运行的主动权是由我的流程来控制.
而wait(),首先,这是由某个确定的对象来调用的,将这个对象理解成一个传话的人,当这个人在某个线程里面说"暂停!",也是 thisOBJ.wait(),这里的暂停是阻塞,还是"点火->烧水->煮饭",thisOBJ就好比一个监督我的人站在我旁边,本来该线程应该执行1后执行2,再执行3,而在2处被那个对象喊暂停,那么我就会一直等在这里而不执行3,但正个流程并没有结束,我一直想去煮饭,但还没被允许,直到那个对象在某个地方说"通知暂停的线程启动!",也就是thisOBJ.notify()的时候,那么我就可以煮饭了,这个被暂停的线程就会从暂停处继续执行.
其实两者都可以让线程暂停一段时间,但是本质的区别是一个线程的运行状态控制,一个是线程之间的通讯的问题
在java.lang.Thread类中,提供了sleep(),
而java.lang.Object类中提供了wait(), notify()和notifyAll()方法来操作线程
sleep()可以将一个线程睡眠,参数可以指定一个时间。
而wait()可以将一个线程挂起,直到超时或者该线程被唤醒。
wait有两种形式wait()和wait(milliseconds).
sleep和wait的区别有:
1,这两个方法来自不同的类分别是Thread和Object
2,最主要是sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。
3,wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在
任何地方使用
synchronized(x){
x.notify()
//或者wait()
}
4,sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常
21.同步和异步有何异同,在什么情况下分别使用他们?举例说明。
如果数据将在线程间共享。例如正在写的数据以后可能被另一个线程读到,或者正在读的数据可能已经被另一个线程写过了,那么这些数据就是共享数据,必须进行同步存取。当应用程序在对象上调用了一个需要花费很长时间来执行的方法,并且不希望让程序等待方法的返回时,就应该使用异步编程,在很多情况下采用异步途径往往更有效率。
22.进程和线程以及他们的区别
简而言之,一个程序至少有一个进程,一个进程至少有一个线程.
线程的划分尺度小于进程,使得多线程程序的并发性高。
另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。这就是进程和线程的重要区别。
23.线程安全和线程不安全
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则的话就可能影响线程安全。
线程安全就是多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用。不会出现数据不一致或者数据污染。
线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据
24.List和Map的区别
List是存储单列数据的集合,Map是存储键和值这样的双列数据的集合;List中存储的数据是有先后顺序,并且允许重复,Map中存储的数据是没有顺序的(除了Treemap,由于底层是二叉树实现的),其键是不能重复的,它的值是可以有重复的。
25.HashMap 和Hashtable的区别
HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,在只有一个线程访问的情况下,效率要高于Hashtable。
HashMap 允许将null作为一个 entry的key或者 value,而Hashtable不允许。
25(1)ArrayList、LinkedList、Vector的区别
ArrayList,Vector底层是由数组实现,LinkedList底层是由双线链表实现,从底层的实现可以得出它们的性能问题,ArrayList,Vector插入速度相对较慢,查询速度相对较快,而LinkedList插入速度较快,而查询速度较慢。再者由于Vevtor使用了线程安全锁,所以ArrayList的运行效率高于Vector。
26.字节流与字符流的区别
字节流在操作的时候本身是不会用到缓冲区(内存)的,是与文件本身直接操作的,而字符流在操作的时候是使用到缓冲区的
字节流在操作文件时,即使不关闭资源(close方法),文件也能输出,但是如果字符流不使用close方法的话,则不会输出任何内容,说明字符流用的是缓冲区,并且可以使用flush方法强制进行刷新缓冲区,这时才能在不close的情况下输出内容
那开发中究竟用字节流好还是用字符流好呢?
在所有的硬盘上保存文件或进行传输的时候都是以字节的方法进行的,包括图片也是按字节完成,而字符是只有在内存中才会形成的,所以使用字节的操作是最多的。
如果要java程序实现一个拷贝功能,应该选用字节流进行操作(可能拷贝的是图片),并且采用边读边写的方式(节省内存)。
27.Heap和stack有什么区别
java的内存分为两类,一类是栈内存,一类是堆内存。栈内存是指程序进入一个方法时,会为这个方法单独分配一块私属存储空间,用于存储这个方法内部的局部变量,当这个方法结束时,分配给这个方法的栈会释放,这个栈中的变量也将随之释放。
堆内存用于存放由new创建的对象和数组,在堆中分配的内存,由 Java虚拟机的自动垃圾回收器来管理,例如,使用 new创建的对象都放在堆里,所以,它不会随方法的结束而消失。方法中的局部变量使用 final修饰后,放在堆中,而不是栈中。
28.Java数据结构有哪些
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。主要是2个family collection (List,Set,Queue)和 map
list: linkedlist,arraylist,vector 存放有序、可重复的元素
set: treeset,hashset 存放不可重复的元素,除了treeSet底层由于是二叉树实现的,所以是有序的,其他的hashSet,AbstractSet等是无序的。
Queue Deque
map: treemap,hashmap,sortedmap 存放键不重复的元素,除了treemap底层是二叉树实现的,所以是有序的,其他的hashmap,AbstractMap等是无序的
29.Activity和service的通信方式
1. 在Activity不绑定Service的前提下(如果绑定了,Activity挂了Service也就挂了)进行相互传输数据,Activity向Service传输数据可以使用Intent,Service向Activity传输数据可以使用广播机制
2. Activity调用bindService(Intent service, ServiceConnection conn, int flags)方法,得到Service对象的一个引用,这样Activity可以直接调用到Service中的方法,如果要主动通知Activity,我们可以利用回调方法
3. 如果要与另外一个进程的Service进行通信,则可以用Messenger其实实现IPC的方式,还有AIDL(接口定义语言),但推荐使用Messenger
30.Java中对象序列化的作用是什么?
简单说就是为了保存在内存中的各种对象的状态,并且可以把保存的对象状态再读出来。虽然你可以用你自己的各种各样的方法来保存Object States,但是Java给你提供一种应该比你自己好的保存对象状态的机制,那就是序列化。
a)当你想把的内存中的对象保存到一个文件中或者数据库中时候;
b)当你想用套接字在网络上传送对象的时候;
31.基本数据类型
java提供了一组基本数据类型,包括boolean, byte, char, short, int, long, float, double,java也提供了这些类型的封装类,分别为Boolean, Byte, Character, Short, Integer, Long, Float, Double。
既然提供了基本类型,为什么还要使用封装类呢
某些情况下,数据必须作为对象出现,此时必须使用封装类来将简单类型封装成对象。
比如,如果想使用List来保存数值,由于List中只能添加对象,因此我们需要将数据封装到封装类中再加入List。在JDK5.0以后可以自动封包,可以简写成list.add(1)的形式,但添加的数据依然是封装后的对象。
另外,有些情况下,我们也会编写诸如func(Object o)的这种方法,它可以接受所有类型的对象数据,但对于简单数据类型,我们则必须使用封装类的对象。
某些情况下,使用封装类使我们可以更加方便的操作数据。比如封装类具有一些基本类型不具备的方法,比如valueOf(), toString(),以及方便的返回各种类型数据的方法,如Integer的shortValue(), longValue(), intValue()等。
另 java swicth 的作用对象有哪些?
int型(包括其包装类)的,String型,枚举型。
其中因为 byte,short,char是可以自动转型为int
String是JDK1.7版本以后才支持的
32 Java的四种引用,强弱软虚,用到的场景
1.强引用,这是使用最普遍的引用。如果一个对象具有强引用,那就类似于必不可少的生活用品,垃圾回收器绝不会回收它。当内存空间不足,Java虚拟机宁愿抛出
OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
2.软引用,如果一个对象只具有软引用,那就类似于可有可无的生活用品。如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。
3.弱引用,如果一个对象只具有弱引用,那就类似于可有可无的生活用品。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
4.虚引用,"虚引用"顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收,具有不确定性。
33.ThreadPool的用法和优劣
线程池是为突然大量爆发的线程设计的,通过有限的几个固定线程为大量的操作服务,减少了创建和销毁线程所需的时间,从而提高效率。 FixedThreadPool(int nThreads):创建一个可重用的固定线程数的线程池,如果池中所有的nThreads个线程都处于活动状态时提交任务(任务通常是Runnable或Callable对象),任务将在队列中等待,直到池中出现可用线程 CachedThreadPool():调用此方法创建的线程池可根据需要自动调整池中线程的数量,执行任务时将重用存在先前创建的线程(如果池中存在可用线程的话).如果池中没有可用线程,将创建一个新的线程,并将其添加到池中.池中的线程超过60秒未被使用就会被销毁,因此长时间保持空闲的 SingleThreadExecutor():创建一个单线程的Executor.这个Executor保证按照任务提交的顺序依次执行任务. ScheduledThreadPool(int corePoolSize):创建一个可重用的固定线程数的线程池. ScheduledExecutorService是ExecutorService的子接口,调用ScheduledExecutorService的相关方法,可以延迟或定期执行任务. 以上静态方法均使用默认的ThreadFactory(即Executors.defaultThreadFactory()方法的返回值)创建线程,如果想要指定ThreadFactory,可调用他们的重载方法.通过指定ThreadFactory,可以定制新建线程的名称,线程组,优先级,守护线程状态等.如果Executors提供的创建线程池的方法无法满足要求,可以使用ThreadPoolExecutor类创建线程池.
34.Java IO与NIO
Java NIO和IO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。 Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。 Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
35.反射的作用于原理
JAVA反射(放射)机制:Reflection,Java程序可以加载一个运行时才得知名称的class,获悉其完整构造(但不包括methods定义),并生成其对象实体、或对其fields设值、或唤起其methods。 用途:Java反射机制主要提供了以下功能:在运行时判断任意一个对象所属的类;在运行时构造任意一个类的对象;在运行时判断任意一个类所具有的成员变量和方法;在运行时调用任意一个对象的方法;生成动态代理。
36.解析XML的几种方式的原理与特点:DOM、SAX
Dom解析在内存中创建一个DOM树,该结构通常需要加载整个文档然后才能做工作。由于它是基于信息层次的,因而DOM被认为是基于树或基于对象的,树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改能随机访问文件内容,也可以修改原文件内容
SAX解析 SAX处理的优点非常类似于流媒体的优点。分析能够立即开始,而不是等待所有的数据被处理。SAX解析器采用了基于事件的模型,它在解析XML文档的时候可以触发一系列的事件,当发现给定的tag的时候,它可以激活一个回调方法,告诉该方法制定的标签已经找到。而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。这对于大型文档来说是个巨大的优点线性解析,不能随机访问,也无法修改原文件。
37.泛型是做什么的,为了解决什么问题,是从哪个版本开始出现的
泛型是Java SE 1.5的新特性,泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。 Java语言引入泛型的好处是安全简单。在Java SE 1.5之前,没有泛型的情况的下,通过对类型Object的引用来实现参数的“任意化”,“任意化”带来的缺点是要做显式的强制类型转换,而这种转换是要求开发者对实际参数类型可以预知的情况下进行的。对于强制类型转换错误的情况,编译器可能不提示错误,在运行的时候才出现异常,这是一个安全隐患。 泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,以提高代码的重用率。
38.常见的排序算法
冒泡排序,插入排序,快速排序,选择排序,归并排序 实现代码或思想。

39.常见的设计模式
工厂模式、模版方法模式、装饰者模式、单例模式、观察者模式......
工厂模式:http://blog.csdn.net/android_cmos/article/details/50441803
模版方法模式:http://blog.csdn.net/android_cmos/article/details/50813204
装饰者模式:http://blog.csdn.net/android_cmos/article/details/50725626
单例模式:http://blog.csdn.net/jason0539/article/details/23297037/
观察者模式:http://blog.csdn.net/android_cmos/article/details/50489055
40,Android布局不同大小的屏幕怎么做到更好的适配
个人对于多设备UI适配的理解
以下是个人的一点总结:
I. 使用简洁的风格来设计UI,让界面变得简单并且一体化,使UI有更加的自适应能力。
II. 尽量使用match_parent,wrap_content等属性来实现实现UI的自适应,减少dp的使用,尽量不要使用px。
III. 如果使用dp,那么不要在layout文件中显示的设定数值,而是通过dimens文件来引用,不同设备上就可以使用同一份layout,而通过不同的dimens来适配。
IV. 可以的情况下,尽量使用.9的png文件,通过无损的缩放来适应UI。
V. 有些在XML上很难设定的UI细节,可能可以通过java代码动态调整的方案来解决。
VI. 如果有需要的话,可以通过w720dp,h360dp,1024x768等属性来对市面上销量比较好的手机做针对性的UI适配。
VII. 没有真机的情况下,可以通过SDK内的模拟器和网上的在线模拟器检查UI效果。
VIII.对于某些app,可以使用Html5来开发UI(即以app内嵌WebView控件来展示Html5),可能可以获得更加的UI适应效果。
前些天看到过一个百分比对布局进行适配的博客,忘了收藏了 = =!
41,Android MVC模式的优缺点
1、 优点
(1) 可以为一个模型在运行时同时建立和使用多个视图。变化-传播机制可以确保所有相关的视图及时得到模型数据变化,从而使所有关联的视图和控制器做到行为同步。
(2) 视图与控制器的可接插性,允许更换视图和控制器对象,而且可以根据需求动态的打开或关闭、甚至在运行期间进行对象替换。
(3) 模型的可移植性。因为模型是独立于视图的,所以可以把一个模型独立地移植到新的平台工作。需要做的只是在新平台上对视图和控制器进行新的修改。
(4) 潜在的框架结构。可以基于此模型建立应用程序框架,不仅仅是用在设计界面的设计中。
2、 缺点
(1) 增加了系统结构和实现的复杂性。对于简单的界面,严格遵循MVC,使模型、视图与控制器分离,会增加结构的复杂性,并可能产生过多的更新操作,降低运行效率。
(2) 视图与控制器间的过于紧密的连接。视图与控制器是相互分离,但确实联系紧密的部件,视图没有控制器的存在,其应用是很有限的,反之亦然,这样就妨碍了他们的独立重用。
(3) 视图对模型数据的低效率访问。依据模型操作接口的不同,视图可能需要多次调用才能获得足够的显示数据。对未变化数据的不必要的频繁访问,也将损害操作性能。
(4) 目前,一般高级的界面工具或构造器不支持MVC模式。改造这些工具以适应MVC需要和建立分离的部件的代价是很高的,从而造成使用MVC的困难。
42.什么是TCP连接的三次握手
第一次握手:客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
如果对上面有什么疑惑,或者补充,欢迎提出!















 4715
4715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









