







 本文介绍了PrefixSpan序列模式挖掘算法,它不产生任何侯选集,能挖掘满足阈值的所有序列模式。文章阐述了算法原理,从后缀序列转换为前缀序列的过程,并给出了递归顺序的重要性。同时,分享了算法实现时遇到的难点和解决办法,以及作者对PrefixSpan算法的理解和其特点。
本文介绍了PrefixSpan序列模式挖掘算法,它不产生任何侯选集,能挖掘满足阈值的所有序列模式。文章阐述了算法原理,从后缀序列转换为前缀序列的过程,并给出了递归顺序的重要性。同时,分享了算法实现时遇到的难点和解决办法,以及作者对PrefixSpan算法的理解和其特点。
更多数据挖掘代码:https://github.com/linyiqun/DataMiningAlgorithm
介绍
与GSP一样,PrefixSpan算法也是序列模式分析算法的一种,不过与前者不同的是PrefixSpan算法不产生任何的侯选集,在这点上可以说已经比GSP好很多了。PrefixSpan算法可以挖掘出满足阈值的所有序列模式,可以说是非常经典的算法。序列的格式就是上文中提到过的类似于<a, b, (de)>这种的。
算法原理
PrefixSpan算法的原理是采用后缀序列转前缀序列的方式来构造频繁序列的。举个例子,
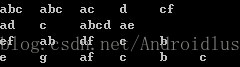
比如原始序列如上图所示,4条序列,1个序列中好几个项集,项集内有1个或多个元素,首先找出前缀为a的子序列,此时序列前缀为<a>,后缀就变为了:
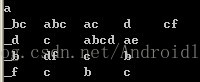
"_"下标符代表前缀为a,说明是在项集中间匹配的。这就相当于从后缀序列中提取出1项加入到前缀序列中,变化的规则就是从左往右扫描,找到第1个此元素对应的项,然后做改变。然后根据此规则继续递归直到后续序列不满足最小支持度阈值的情况。所以此算法的难点就转变为了从后缀序列变为前缀序列的过程。在这个过程要分为2种情况,第1种是单个元素项的后缀提前,比如这里的a,对单个项的提前有分为几种情况,比如:
<b a c ad>,就会变为<c ad>,如果a是嵌套在项集中的情况<b c dad r>,就会变为< _d r>,_代表的就是a.如果a在一项的最末尾,此项也会被移除<b c dda r>变为<r>。但是如果是这种情况<_da d d>a包含在下标符中,将会做处理,应该此时的a是在前缀序列所属的项集内的。
还有1个大类的分类就是对于组合项的后缀提取,可以分为2个情况,1个是从_X中寻找,一个从后面找出连续的项集,比如在这里<a>的条件下,找出前缀<(ab)>的后缀序列
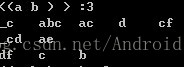
第一种在_X中寻找还有没有X=a的情况,因为_已经代表1个a了,还有一个是判断_X != _a的情况,从后面的项集中找到包含有连续的aa的那个项集,然后做变换处理,与单个项集的变换规则一致。
算法的递归顺序
想要实现整个的序列挖掘,算法的递归顺序就显得非常重要了。在探索递归顺序的路上还是犯了一些错误的,刚刚开始的递归顺序是<a>---><a a>----><a a a>,假设<a a a>找不到对应的后缀模式时,然后回溯到<a (aa)>进行递归,后来发现这样会漏掉情况,为什么呢,因为如果 <a a >没法进行到<a a a>,那么就不可能会有前缀<a (aa)>,顶多会判断到<(aa)>,从<a a>处回调的。于是我发现了这个问题,就变为了下面这个样子,经测试是对的。:
加入所有的单个元素的类似为a-f,顺序为
<a>,---><a a>.同时<(aa)>,然后<ab>同时<(ab)>,就是在a添加a-f的元素的时候,检验a所属项集添加a-f元素的情况。这样就不会漏掉情况了,用了2个递归搞定了这个问题。这个算法的整体实现可以对照代码来看会理解很多。最后提醒一点,在每次做出改变之后都会判断一下是否满足最小支持度阈值的。
PrefixSpan实例
这里举1个真实一点的例子,下面是输入的初始序列:
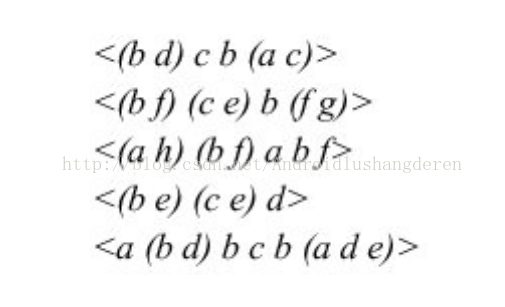
挖掘出的所有的序列模式为,下面是一个表格的形式
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1849
1849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









