






现在的数据越来越多的被存储,对于数据库来讲,访问大数据量会变得越来越慢,于是为了提高访问的速度,将小范围区域的数据存储在一个高速缓冲存储器,以至于不会每次去读取磁盘,而是在内存中直接访问数据。

![]()
内存存储的代价远远的大于磁盘存储的价值,所以缓存很小,并不能存储你所有的数据,所以你不得不保存你所认为重要的数据(使用次数较多的数据),那就要淘汰最少使用的数据,如何从缓存中淘汰最少使用的数据,一个简单而且有效的算法,最近最少使用算法LRU.
LRU原理
最久未使用算法(LRU):最久没有访问的内容作为替换对象 ----- 来自wiki
LRU翻译过来就是最久未使用,当缓存到达一定的阀值时,剔除掉最久未使用的数据,通俗来讲,比如一个缓存只能缓存10000条数据,10000条就是这个缓存的阀值,小于10000条时可以随意添加,一旦数据量到达了10000条时,这个时候就要删除最久未使用的数据了,以保持最大程度的使用缓存。
LRU实现
LRU的实现最简单的就是单链表的实现,这里引用的就是JDK中的LinkedHashMap,它有两种形式,一个是最晚读的数据放在前面,最早读的数据放在后面,另一个就是FIFO,也就是先进先出。
晚读放前,早读放后
每次新的数据从头部开始插入,当链表缓存空间满了的时候,就从尾部对数据进行删除,如果有数据命中的话,就将该数据移动到头部。
而基于LinkedHashMap的实现有两种方法,一种就是继承LinkedHashMap的方式,叫做inheritance,一种直接使用LinkedHashMap,叫做delegation,这两种都可以实现LRU算法,而大部分功能LinkedHashMap已经实现了,但是淘汰的删除方法就需要重写了。
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; } protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false; }这是LinkedHashMap的构造方法和删除元素的方法,默认情况下,LinkedHashMap是根据元素的添加顺序进行存储的,如果构造参数accessOrder为true的话,就会按照访问数据,最晚访问的放在最前,最早访问的放在最后。
(1) inheritance
public class LruInheritance<K, V> extends LinkedHashMap<K, V> { private final int MAX_SIZE=100; public LruInheritance(int cacheSize) {在构造方法中,由于将负载因子设置为0.75,所以在原有容量要除以该负载因子,因为Map中的阀值是原有容量*负载因子,以此来判断是否超标。而原本LinkedHashMap删除的机制返回的都是false,所以要重写removeEldestEntry方法,如果超过当前容量就返回true,就会删除当前元素了。
super((int) Math.ceil(cacheSize / 0.75)+1, 0.75f, true);
MAX_SIZE = cacheSize; } @Override protected boolean removeEldestEntry(Map.Entry eldest) { return size() > MAX_SIZE; } }
(2) delegation
public class LruDelegation<K, V> { private final int MAX_SIZE; LinkedHashMap<K, V> map; public LruDelegation(int cacheSize) {
MAX_CACHE_SIZE = cacheSize; int capacity = (int) Math.ceil(MAX_SIZE / 0.75) + 1; map = new LinkedHashMap(capacity, 0.75f, true) {
@Override protected boolean removeEldestEntry(Map.Entry eldest) { return size() > MAX_SIZE; } }; }}在这个构造方法中,它内部就是用已经重写removeEldestEntry方法的LinkedHashMap实现的,他与inheritance不同的是,对LinkedHashMap不同使用,一个当爹使,一个当朋友使。FIFO(先进先出)
其实与第一种方式相比,对于LinkedHashMap来讲,就是accessOrder参数的变化,上面也提到,LinkedHashMap默认的是FIFO的,构造参数accessOrder默认是false的,所以与第一种相比,只要将accessOrder置为false,或者使用一个无参构造,就可以实现了。final int MAX_SIZE= 100;这种是基于单链表实现LRU
LinkedHashMap<Integer, String> lru = new LinkedHashMap<Integer, String>() { @Override protected boolean removeEldestEntry(Map.Entry<Integer, String> eldest) { return size() > MAX_SIZE; } };缺点是:由于LinkedHashMap本身特性,所以是线程不安全的,而且命中率不高。优点是:实现起来简单,很多东西LinkedHashMap已经帮你实现了
其实多链表或者多队列的组合使用,效率和命中很更高,一个链表或队列专门用来维护命中概率(作为访问历史数据存储),另一个作为多次访问数据存储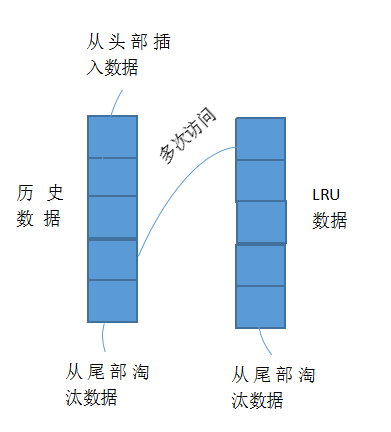
新的数据都会从历史数据的队列的头部插入,如果当前队列容量满了之后,就会从尾部淘汰,如果当前历史数据被访问多次,就会移动到正式的LRU数据队列中,然后按时间排序,当该队列满了之后,就会从尾部淘汰。多个链表或队列组合的LRU能够应该复杂的场景,能够应对不同情况,不同的淘汰机制,提高数据的命中率,同时响应的维护成本也响应的提高了。















 31
31

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









