







 本文详细介绍了音频领域中mel频谱和mfcc特征在深度学习中的重要性,以及它们在解决各类音频业务中的应用。着重探讨了预加重等信号处理技术对特征的影响,以及如何结合算法流程优化模型的准确性与鲁棒性。
本文详细介绍了音频领域中mel频谱和mfcc特征在深度学习中的重要性,以及它们在解决各类音频业务中的应用。着重探讨了预加重等信号处理技术对特征的影响,以及如何结合算法流程优化模型的准确性与鲁棒性。
前言
在音频领域,mel频谱和mfcc是非常重要的特征数据,在深度学习领域通常用此特征数据作为网络的输入训练模型,来解决音频领域的各种分类、分离等业务,如端点侦测、节奏识别、和弦识别、音高追踪、乐器分类、音源分离、回声消除等相关业务。
当然,针对深度学习音频领域的业务,不是用下这两个特征、选几个网络、打个标签,放数据训练就完事了, 仅仅基于mel频谱和mfcc这两个特征,解决好上述业务某些情况下还是远远不够的,熟悉这些特征的内在逻辑性、衍生细节和延展,才能更好的结合深度学习解决业务问题。
下面讲解mel频谱和mfcc特征的算法流程和一些细节、延展,这些细节从局部角度来看,都会影响到最终特征呈现的细节差异,这些差异放大到模型训练结果的准确性、鲁棒性上怎么样是非常值得研究的,某些情况下可能会有质的变化,质的变化无论正向还是负向都是值得关注的,最怕的是没变化;同时,一些问题的延展从广义角度来看,带来不同的特征组合、网络结构设计思考等也是解决业务问题非常重要的思想源泉。
算法流程
设 sr 为采样率,fftLength 为帧长度,slideLength 为滑动长度
下面是一张mel频谱和mfcc的大概算法流程图。
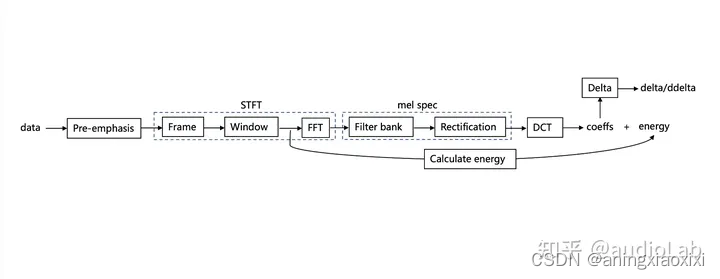
1. 预加重(Pre-emphasis)
如流程图所示的第1步,属于信号的预处理,补偿高频分量损失,提升高频分量,一般情况下可以忽略此步骤,属于信号的简单增强,对特征有一定的提升效果。公式如下
Pre-emphasis的公式为:
x[n] = x[n] - αx[n-1]
其中,x[n]表示经过预加重处理后的信号,α是一个常数,通常取值为0.95或0.97。该公式的实现过程如下:
1 对于输入信号x[n],将每一时刻的信号与前一时刻的信号相减,得到预加重处理后的信号x[n]。
2 α是一个控制预加重程度的常数,取值范围通常在0到1之间。α越大,预加重的程度越高,高频分量的增强效果越明显。
通过上述公式,Pre-emphasis算法可以有效地增强信号中的高频分量,提高信号的清晰度和可懂度。在实际应用中,Pre-emphasis算法可以用于语音处理、音频处理等领域,以改善语音和音频信号的质量。

















 384
384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









