







faiss: Billion-scale similarity search with GPUs
paper https://arxiv.org/abs/1702.08734
github https://github.com/facebookresearch/faiss
摘要:
【提出问题】
特种数据库系统中的相似度搜索应用程序处理诸如图像或视频之类的复杂数据,这些数据通常由
高维特征表示并且需要特殊的索引结构。本文解决相似度搜索更好利用GPU的问题。尽管GPU
擅长数据并行任务,但先前的方法遇到算法瓶颈:暴露出较少的并行性(例k-min selection),
或不能充分利用内存的层次结构。
【解决方案】
我们提出了一种用于k-selection的设计。其运行性能最高可达理论峰值55%,使得近似最近邻
ANN(approximate nearest neighbor)实现比现有GPU SOTA快8.5倍。通过提出brute-force
优化设计,基于乘积量化(PQ)的近似和压缩域搜索,我们尝试应用于不同的相似性搜索场景。
在所有这些设置中,我们都大大超越了现有SOTA技术。我们的实现可在35分钟内,Yfcc100M
数据集的9500万张图像上构建高精度k-NN图,利用4个Titan XGPU卡,在不到12小时的时间
内连接10亿个矢量的图。为了比较和复现,我们已经开源了方法。
1.引论
本文做出了以下贡献:
GPU k-selection,在快速寄存器存储器中运行,足够的灵活性可以融合其他内核,为此我们提供了
复杂性分析; 用于在GPU上进行精确和近似k-nearest neighbor查找的近优算法布局;实验表明,
在单或多GPU配置中,这些改进在中型到大型的最近邻居搜索任务上性能大幅超越历史最好。
本文的结构如下。第2节介绍了上下文和符号。第3节回顾了GPU体系结构,讨论了将其用于相似性
搜索时出现的问题。第4节介绍了我们的主要贡献之一,即我们针对GPU的k-selection,而第5节则
提供了有关算法计算布局的细节。最后,第6节为我们的方法提供了广泛的实验,与SOTA技术进行
了比较,并展示了图像集合的具体用例。
===================================
源代码实现/原理解释: https://github.com/facebookresearch/faiss/wiki
Faiss是一个用于高效相似性搜索和稠密向量聚类的库。 它包含的算法可搜索任意大小的向量集,
直至放不到RAM的向量。 它还包含用于评估和参数调整的支持代码。 Faiss用C ++编写用Python封装。
一些最有用的算法是在GPU上实现的。 它是由Facebook AI Research开发的。
Faiss基本构建块: 聚类 clustering, 降维PCA, 乘积量化quantization
Faiss provides an efficient k-means implementation,Clustering on the GPU.
Computing a PCA,
PQ encoding / decoding.
A Survey of Product Quantization,2018,
https://www.jstage.jst.go.jp/article/mta/6/1/6_2/_pdf
Abstract:
Product Quantization (PQ) search and derivatives are popular and successful methods for
large-scale approximated nearest neighbor(ANN) search. In this paper, we review the
fundamental algorithm of this class of algorithms and provide executable sample codes.
We then provide a comprehensive survey of the recent PQ-based methods.
-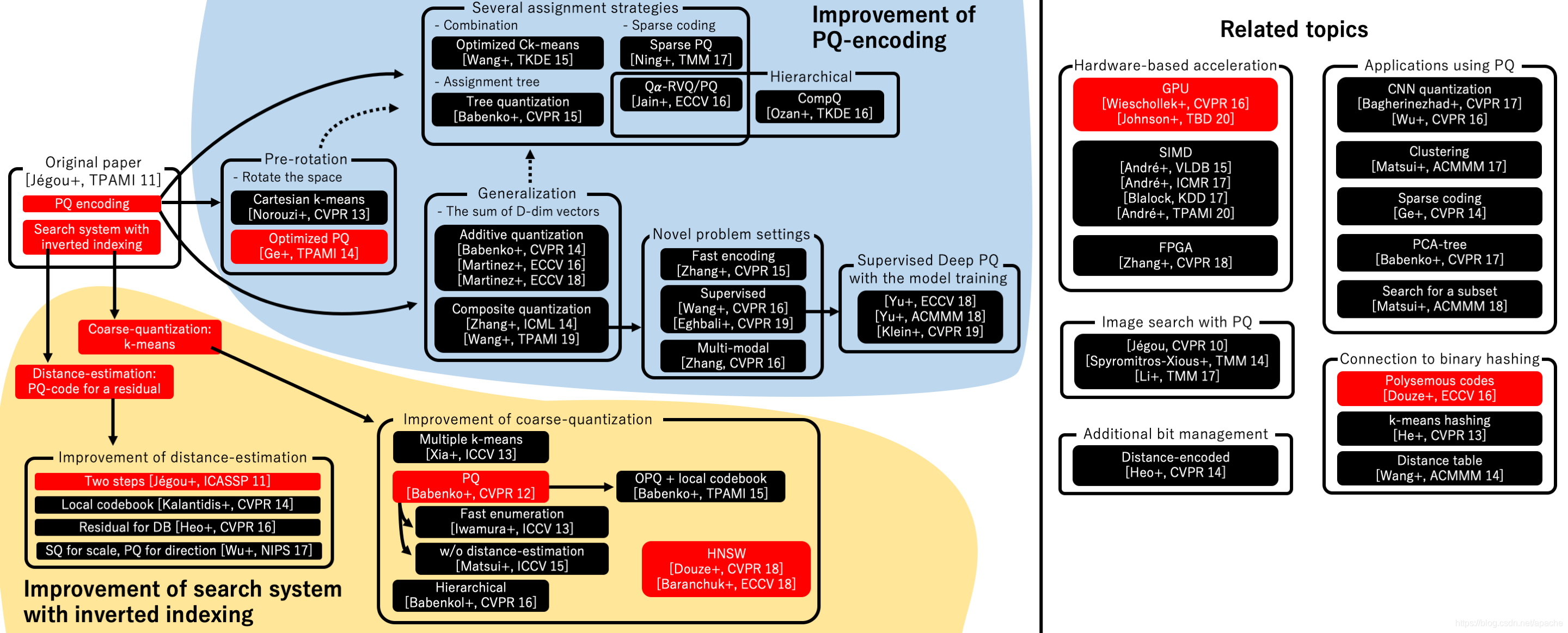
-A relation of PQ-based methods
-
faiss-web-service , https://github.com/plippe/faiss-web-service
gRPC faiss-server, https://github.com/ynqa/faiss-server
================================================================
faiss简介及示例 https://blog.csdn.net/kanbuqinghuanyizhang/article/details/80774609
Faiss 在项目中的使用 https://waltyou.github.io/Faiss-In-Project/
Facebook开源向量检索框架Faiss https://zhuanlan.zhihu.com/p/266589272
图像检索:向量索引,, https://yongyuan.name/blog/vector-ann-search.html
youtube视频推荐系统
https://daiwk.github.io/posts/dl-youtube-video-recommendation.html
Billion-scale semantic similarity search with FAISS+SBERT
【中译】https://www.yanxishe.com/TextTranslation/2987
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
https://arxiv.org/abs/1908.10084
【中译】 https://blog.csdn.net/weixin_43922901/article/details/106014964

















 1136
1136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









