







前言
很多熟悉我的朋友,都是从我春节前的一篇文章开始的:DeepSeek + Dify :零成本搭建企业级本地私有化知识库保姆级喂饭教程
很多朋友也是从这里知道了dify,并用上了个人本地知识库。但是在日常答疑过程中,我们发现,知识库回答Excel的内容,效果非常糟糕!比如:明明表里有30条数据,它只检索到了3条,问他表里总共多少条数据,他的回答都是乱七八糟的。
知识库本质上是向量相似度匹配,他本就不适合这种对精确度要求很高的统计查询场景,我们过于苛责知识库了。
那么,问题来了:我们能不能不导入数据,直接让dify访问数据库,基于数据库回答我的问题?
当然能!我们可能通过MCP来实现!
前面,我写过两篇关于MCP的极速入门的文章:
大家可能已经对MCP有一定的了解了!
今天,带大家写一个通信方式为SSE的MCP服务器,让你的Dify拥有自主查询数据库的能力!
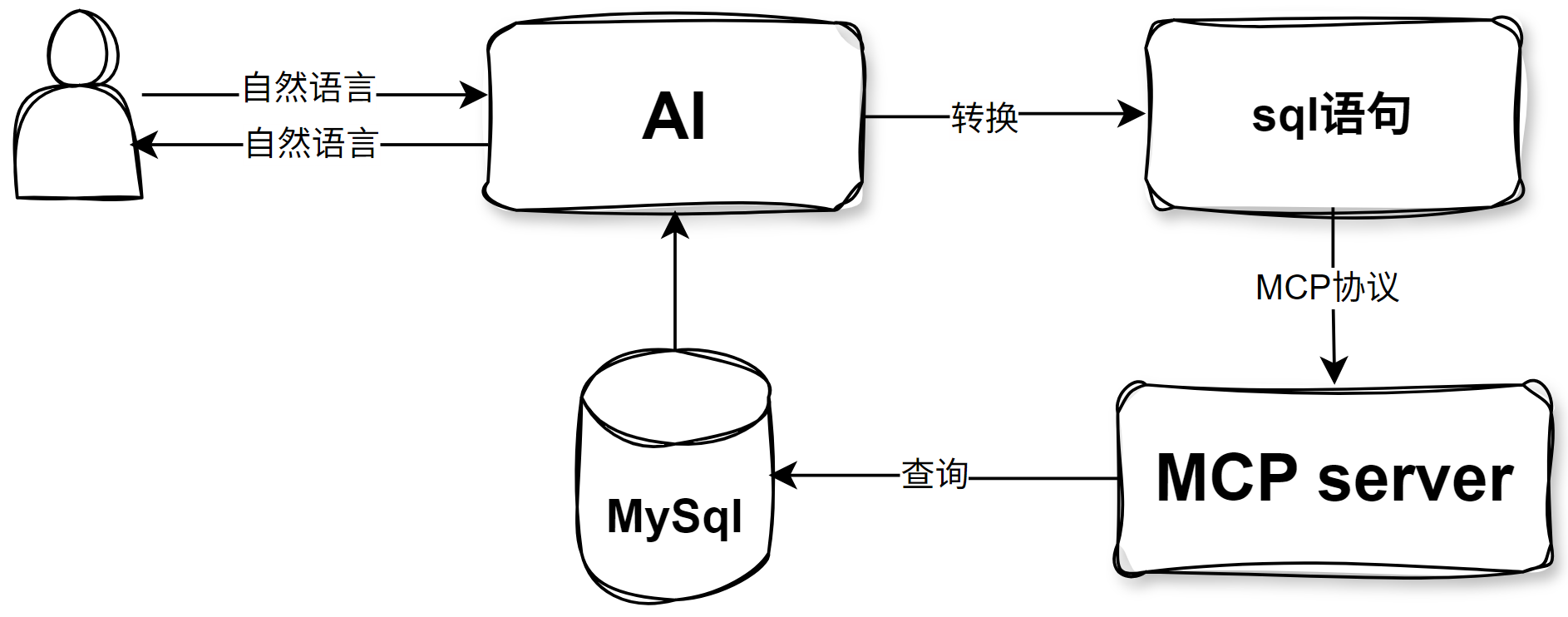
一、基本流程
我们通过在自然语言与AI交互,
一、安装MySql
本步骤安装Mysql,如果电脑已经安装有Mysql或者服务器部署有Mysql,本步骤可跳过
一)下载
由于Mysql的下载安装比较繁琐,按照我的风格,我又把他做成了一键安装包,只需点击安装即可自动安装,老规矩,我把MySql一键安装包下载链接放到了同名工众号上,维信搜索工众号:阿坡RPA,回复关键字:mysql,链接自动掉落。
二)安装
解压下载好的一键安装包后,安装步骤:
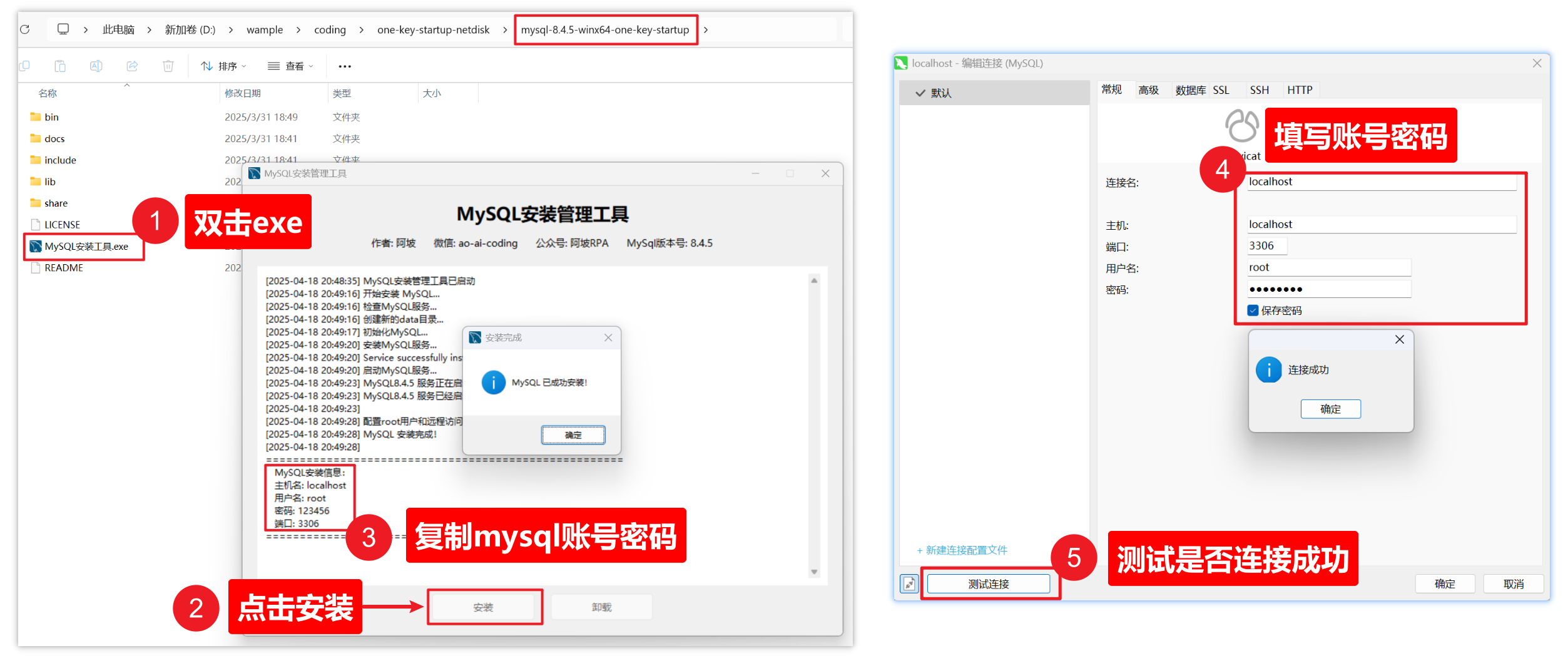
① 双击根目录内的 MySql管理工具.exe
② 点击安装 按钮即可等待安装完成
③ 复制mysql账号密码
④ 在navicat内填写好账号密码(下载连接在同一个网盘内)
⑤ 点击左侧测试连接
出现成功确认框,表示成功安装了MySql,接下来即可开始后面的操作了
二、把数据导入MySql
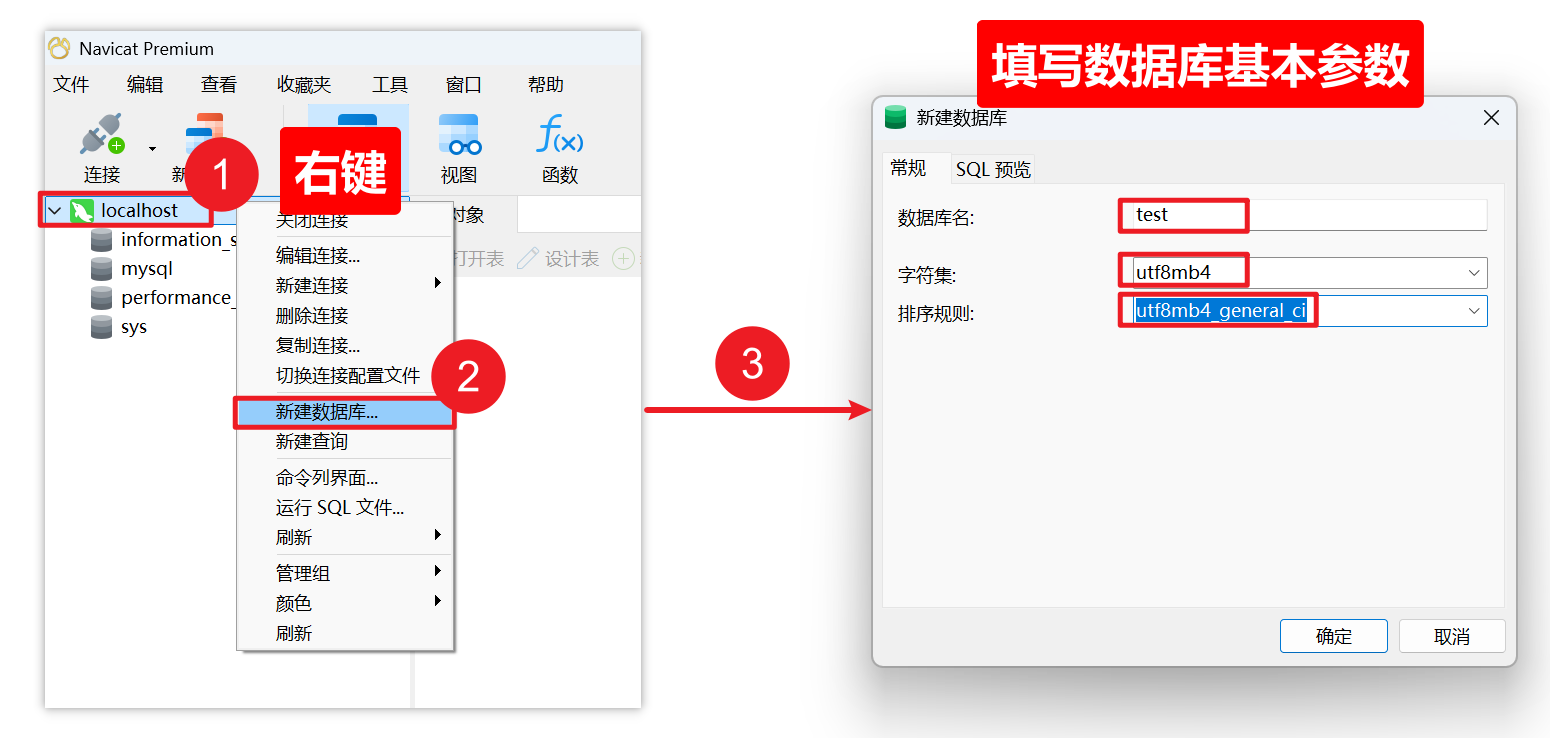
一)创建数据库
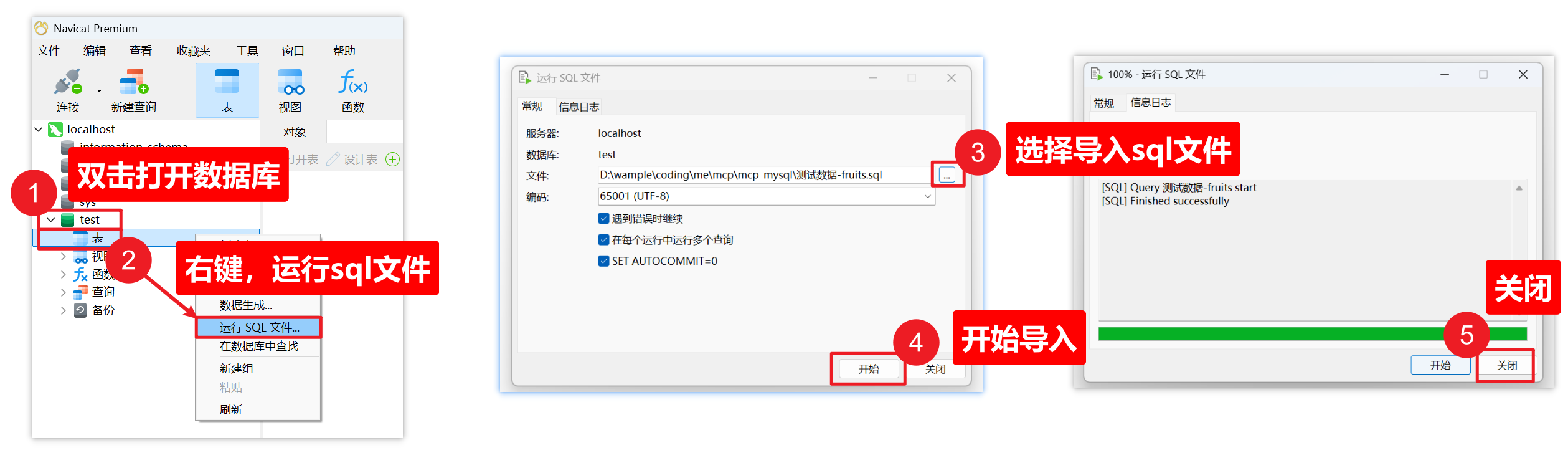
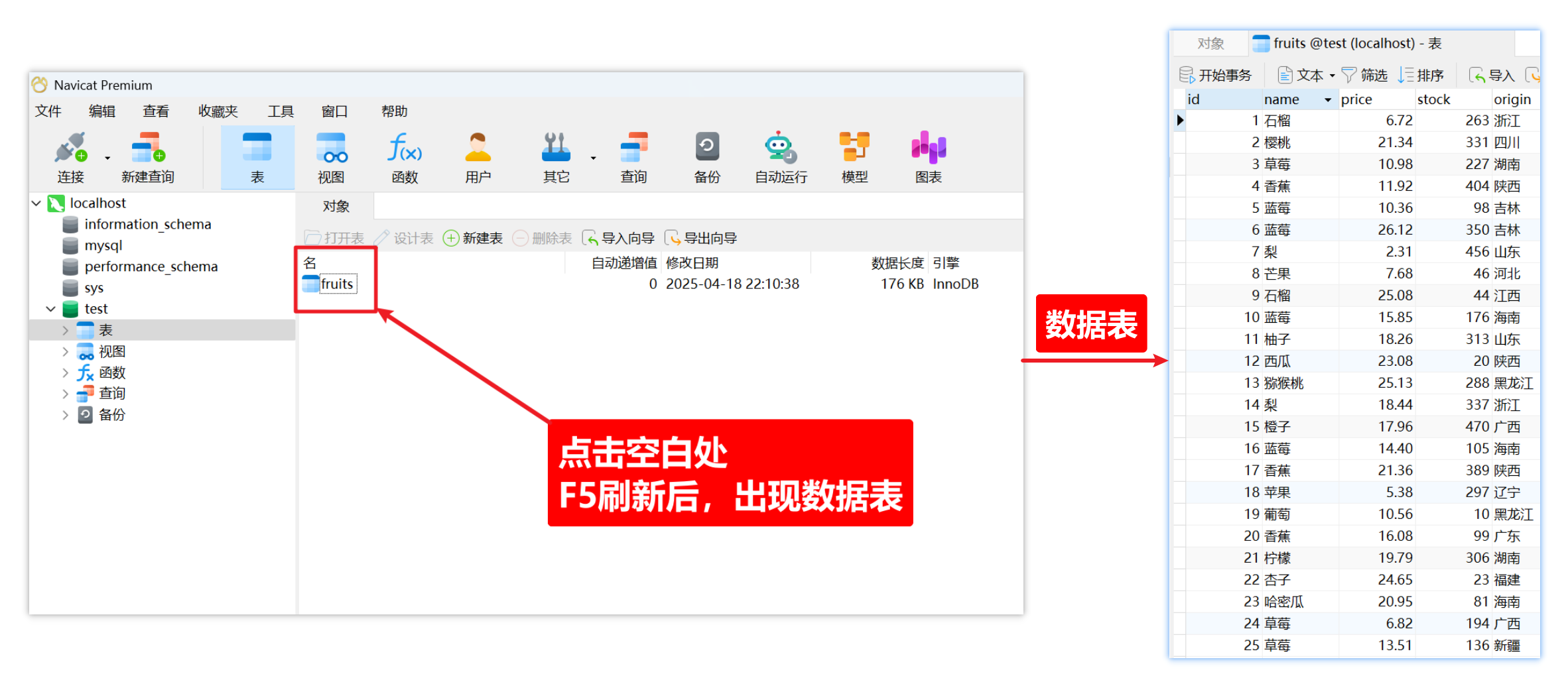
二)导入数据表
注意:导入sql文件测试数据,在下载mysql的网盘内获取
三、安装并启动MCP服务
下载mysql-mcp-server源码,这是一个github项目的源码,原github地址是:https://github.com/mangooer/mysql-mcp-server-sse
我已经下载好放在同一个网盘里,请根据文章开头获取方式获取,下打开载好的项目源码,进入源码目录:
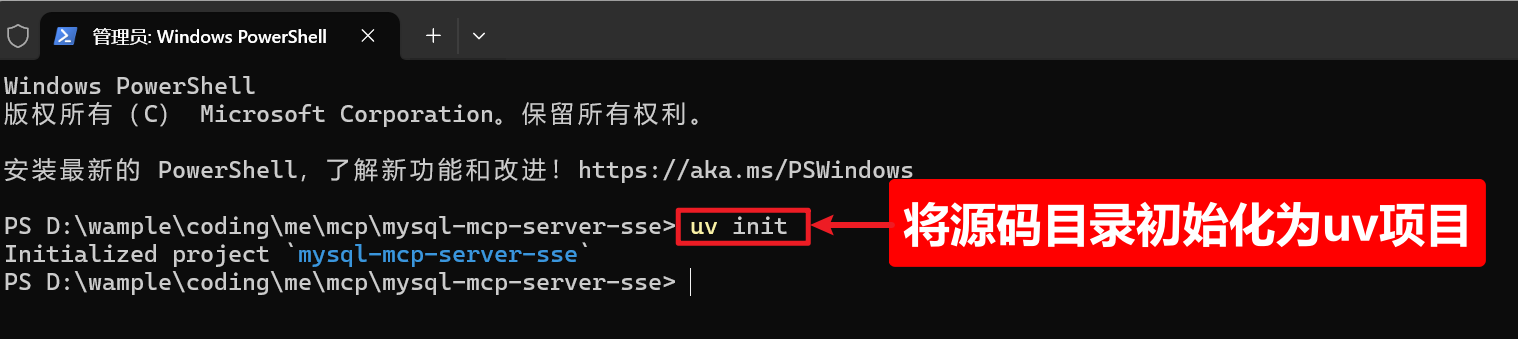
一)初始化源码项目为uv项目
输出指令:
# 初始化
uv init
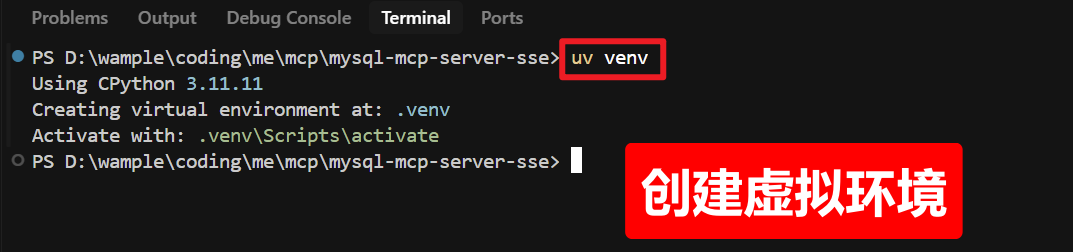
二)创建虚拟环境
# 创建虚拟环境
uv venv
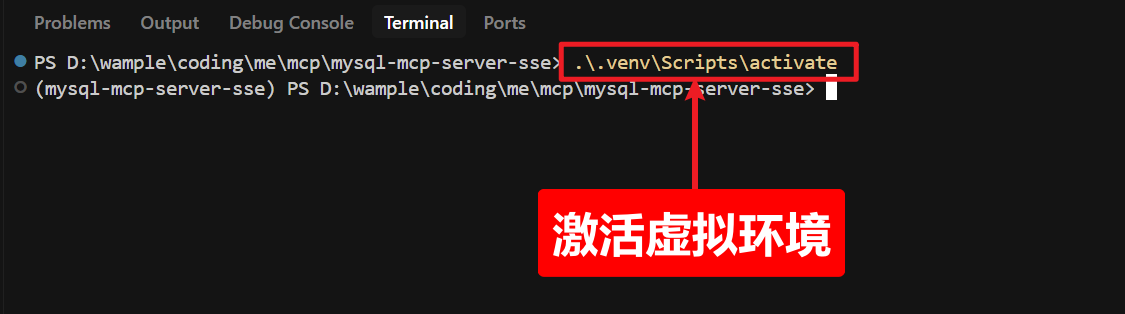
三)激活虚拟环境
.venv\Scripts\activate
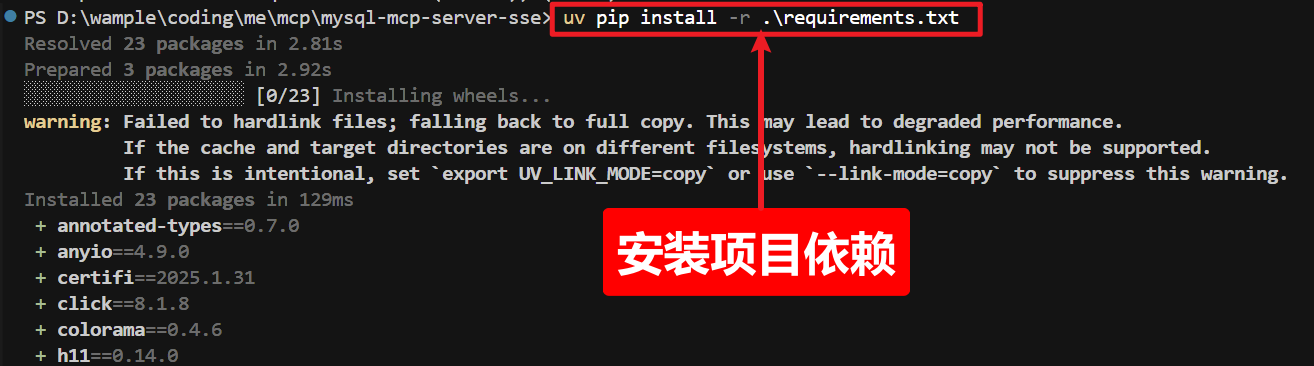
四)安装项目依赖
uv pip install -r .\requirements.txt
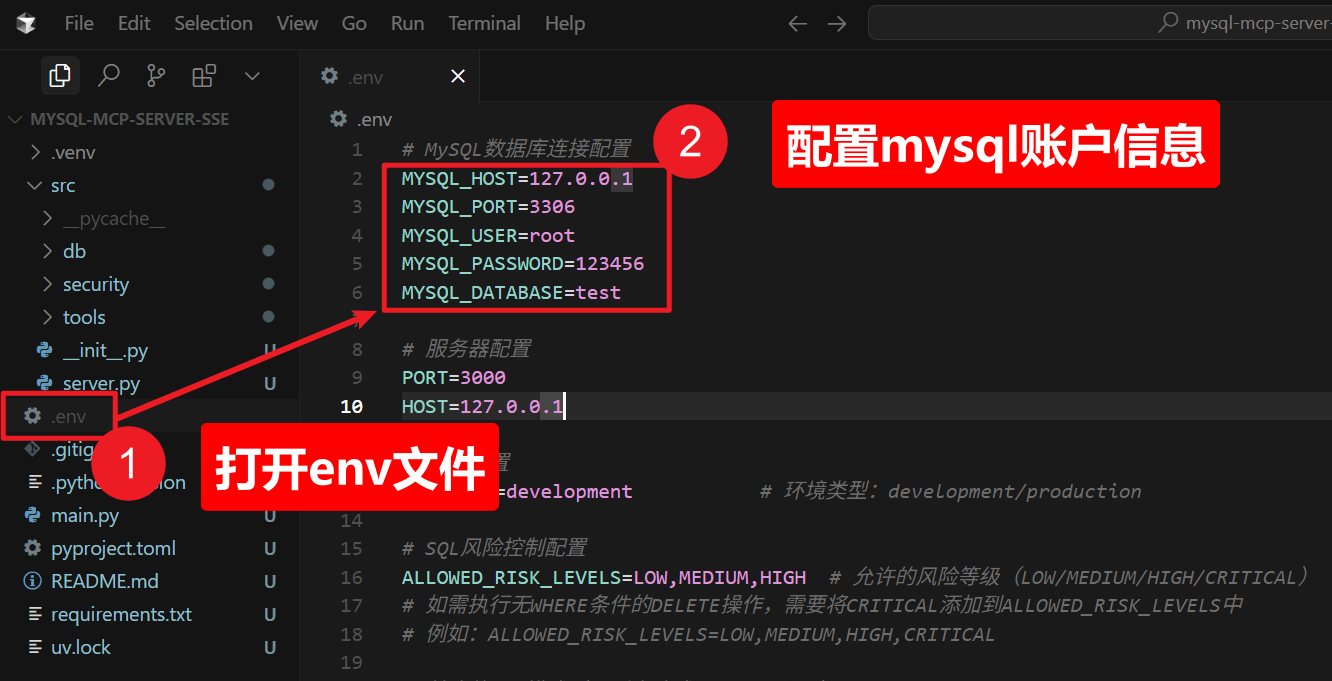
五)数据库配置
在项目的env 文件内配置前面获取到的mysql账户密码及地址
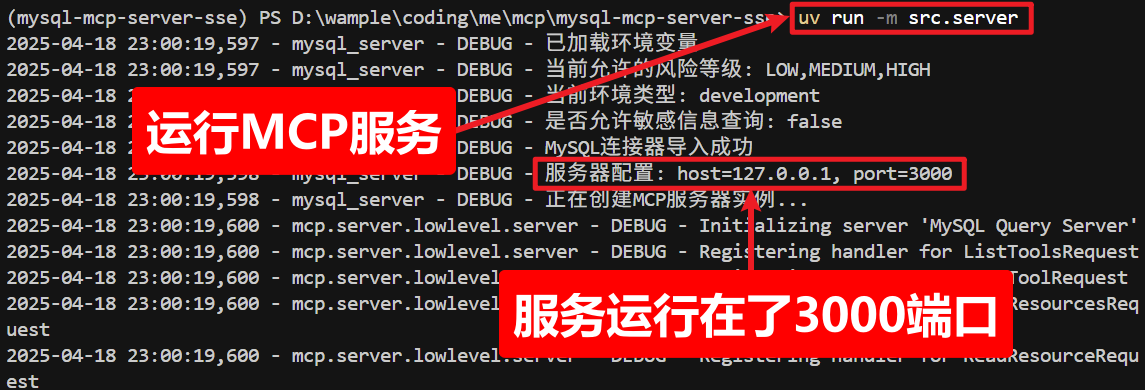
六)运行server
本项目会开启一个 SSE 通信方式的MCP服务,方便AI通过url远程调用本服务
uv run -m src.server
可以看到,MCP服务运行在了 3000 端口,请记住该端口号,后面配置Dify工作流会用到
四、Dify工作流调用MCP服务
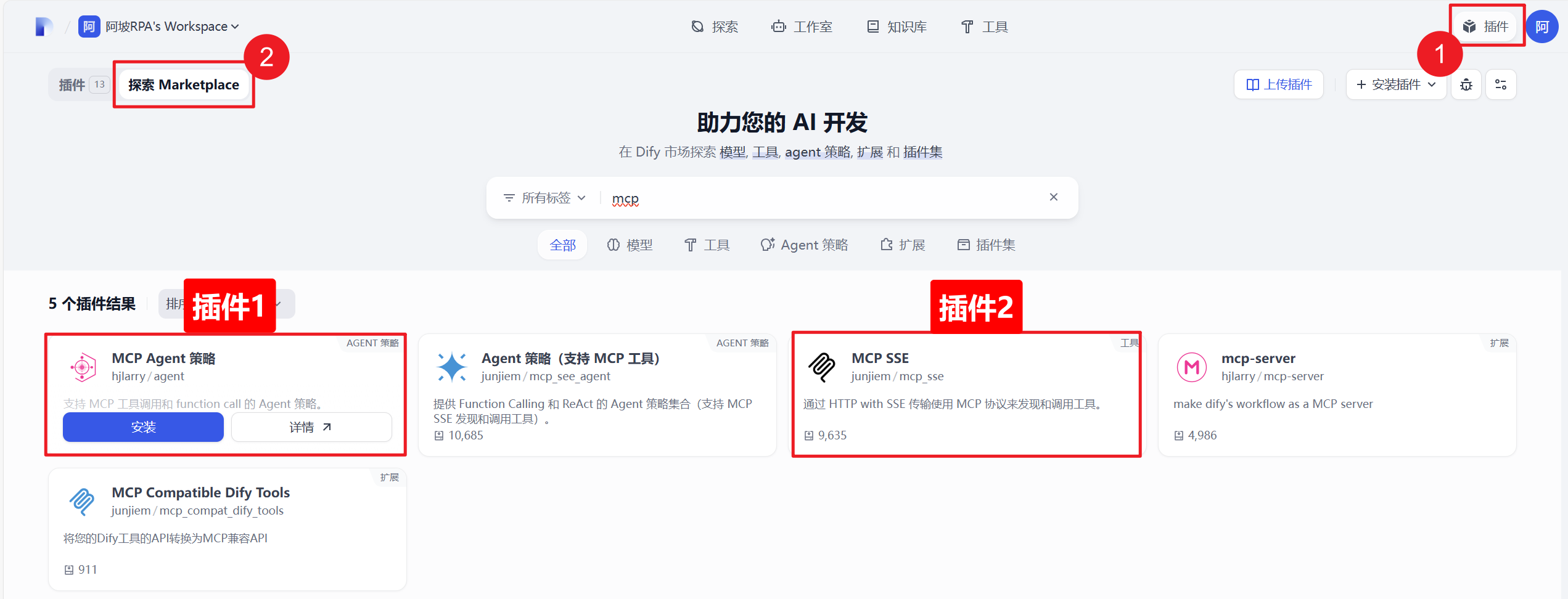
一)安装插件
安装 MCP Agent策略 MCP SSE 插件,以供后面使用
二)创建对话工作流应用
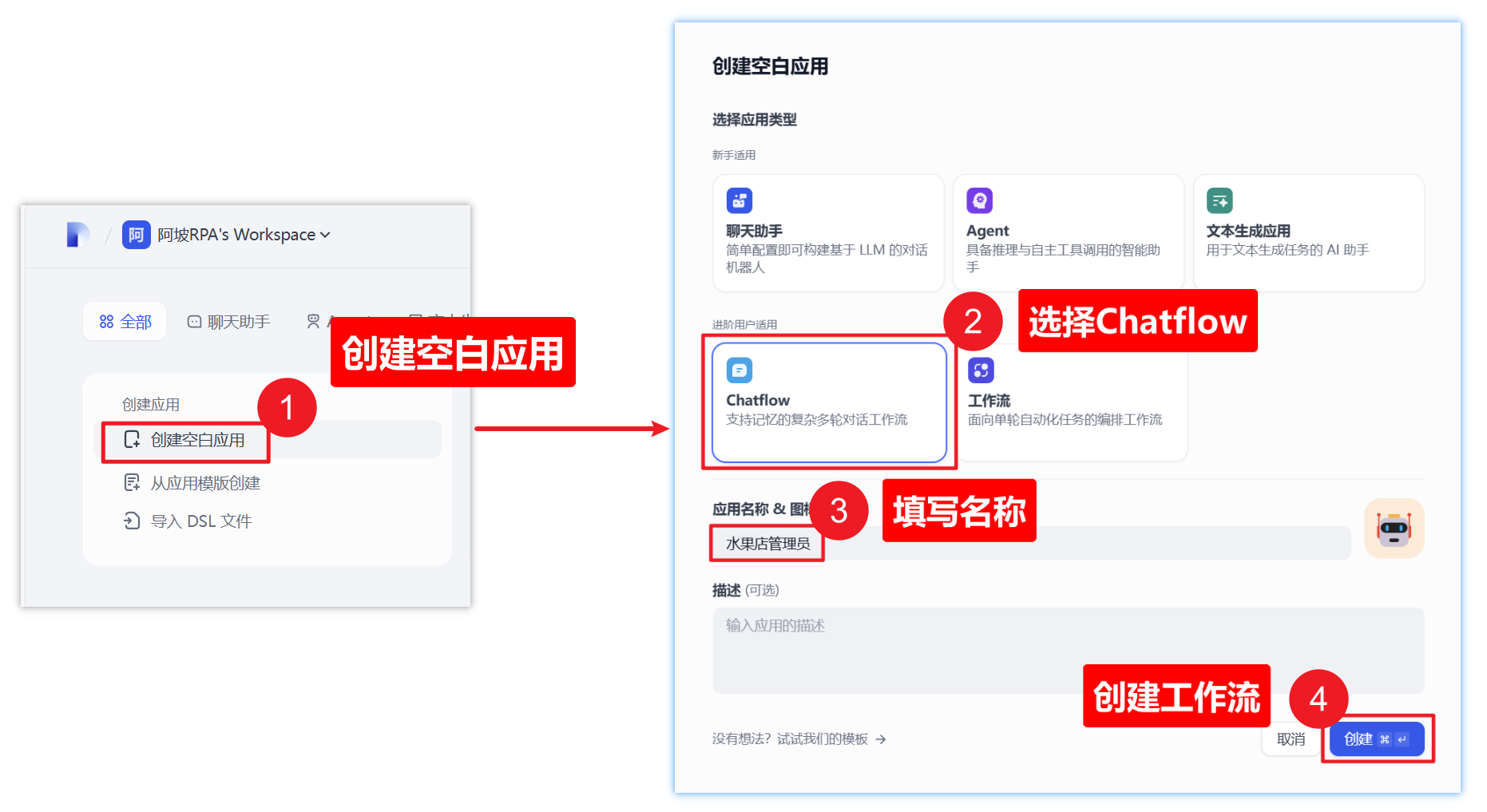
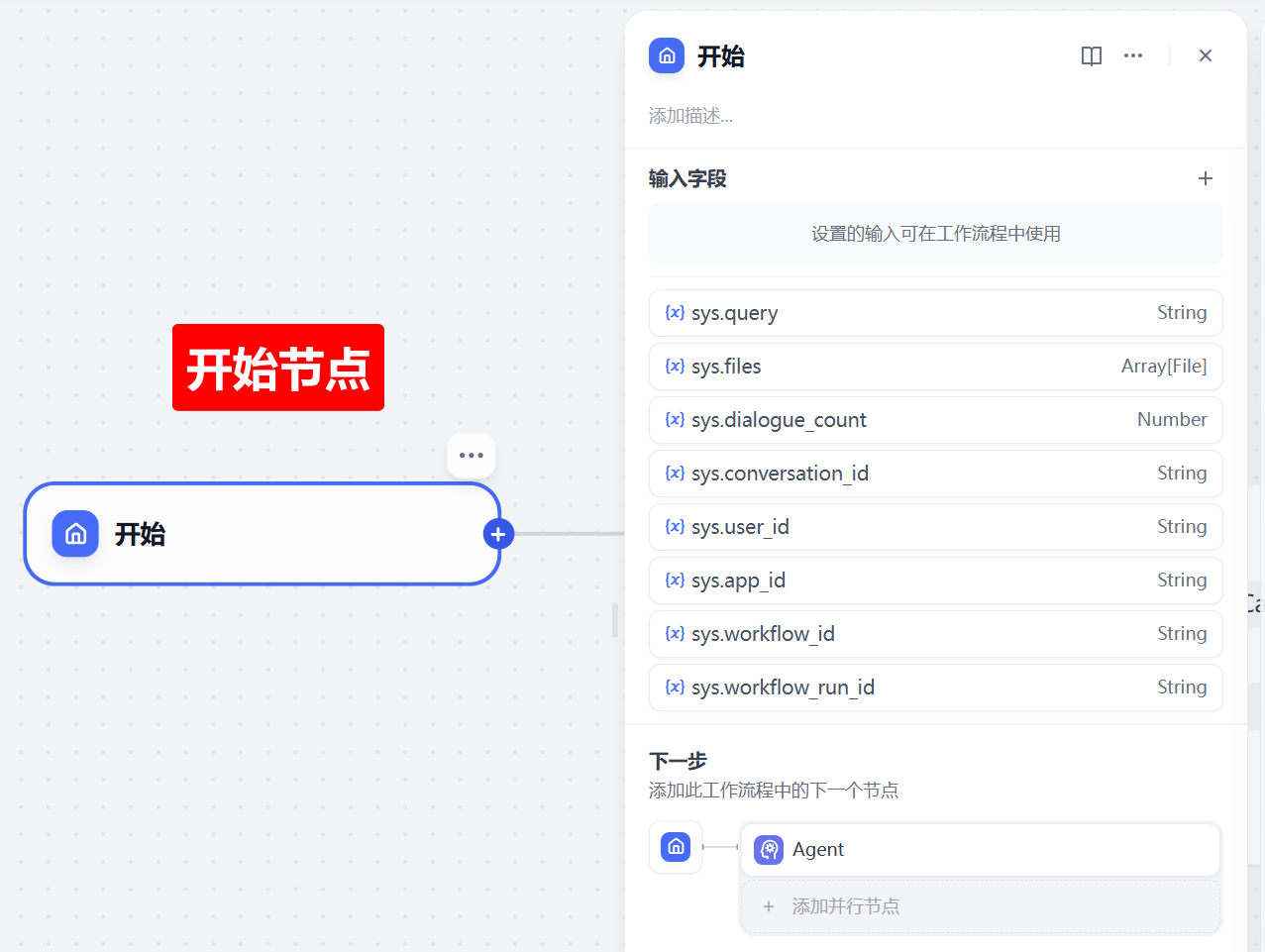
三)开始节点
开始节点什么都不用填写,默认使用输入框的内容 sys.query 作为输入参数
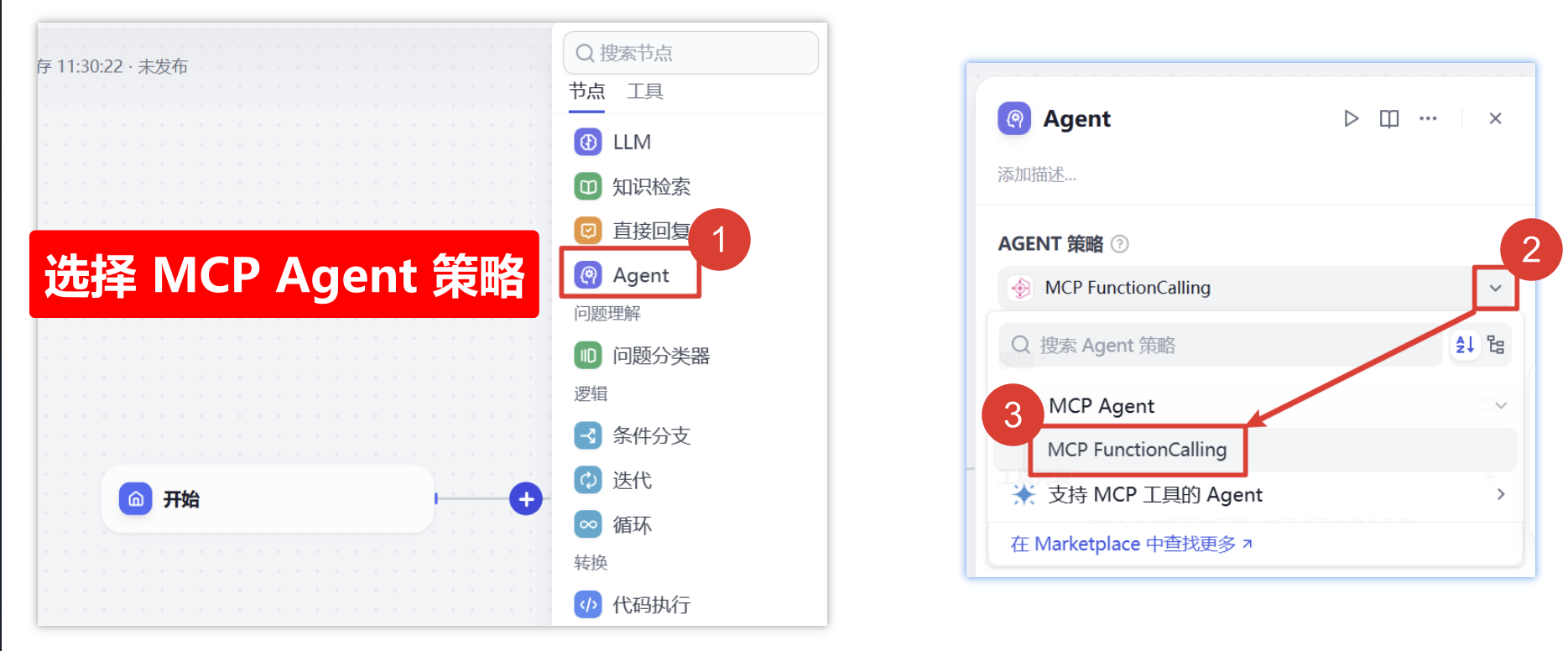
四)Agent策略节点
1、选择策略工具
选择刚才下载的 MCP Agent 策略作为意图识别的工具,他会自主来决策,该选择调用工具列表中的哪个工具执行任务
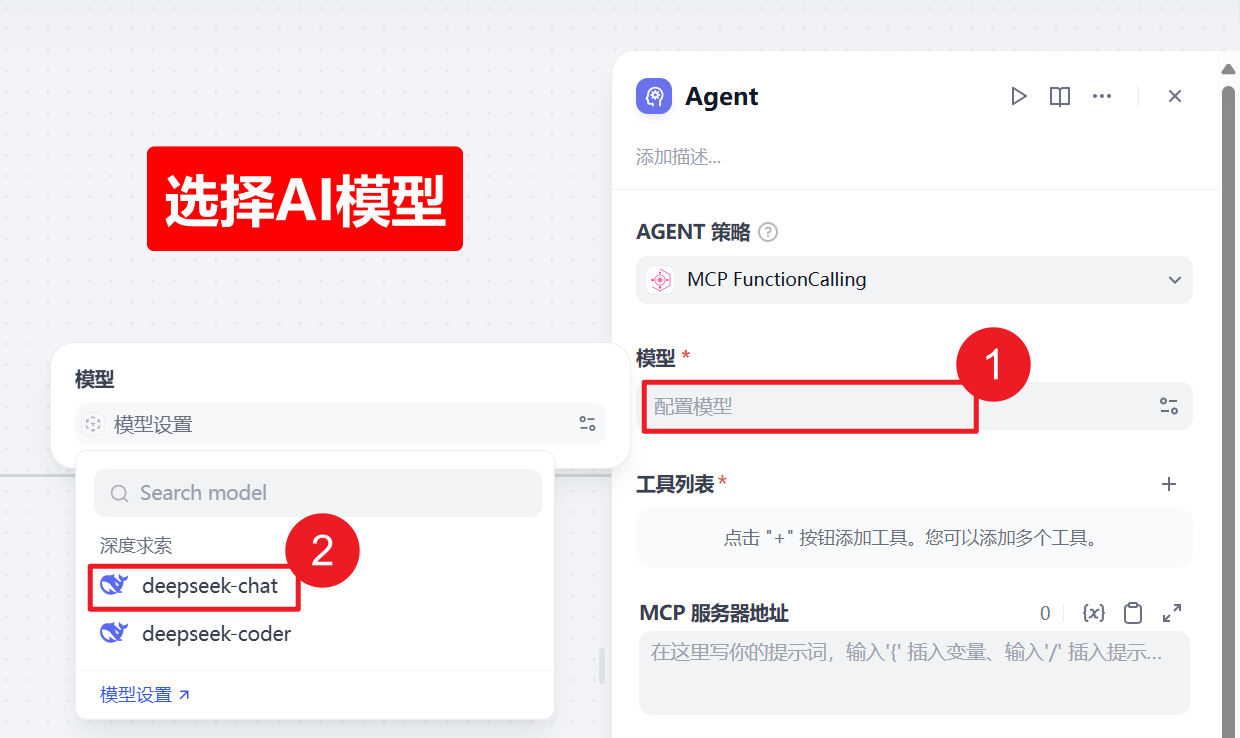
2、选择AI模型
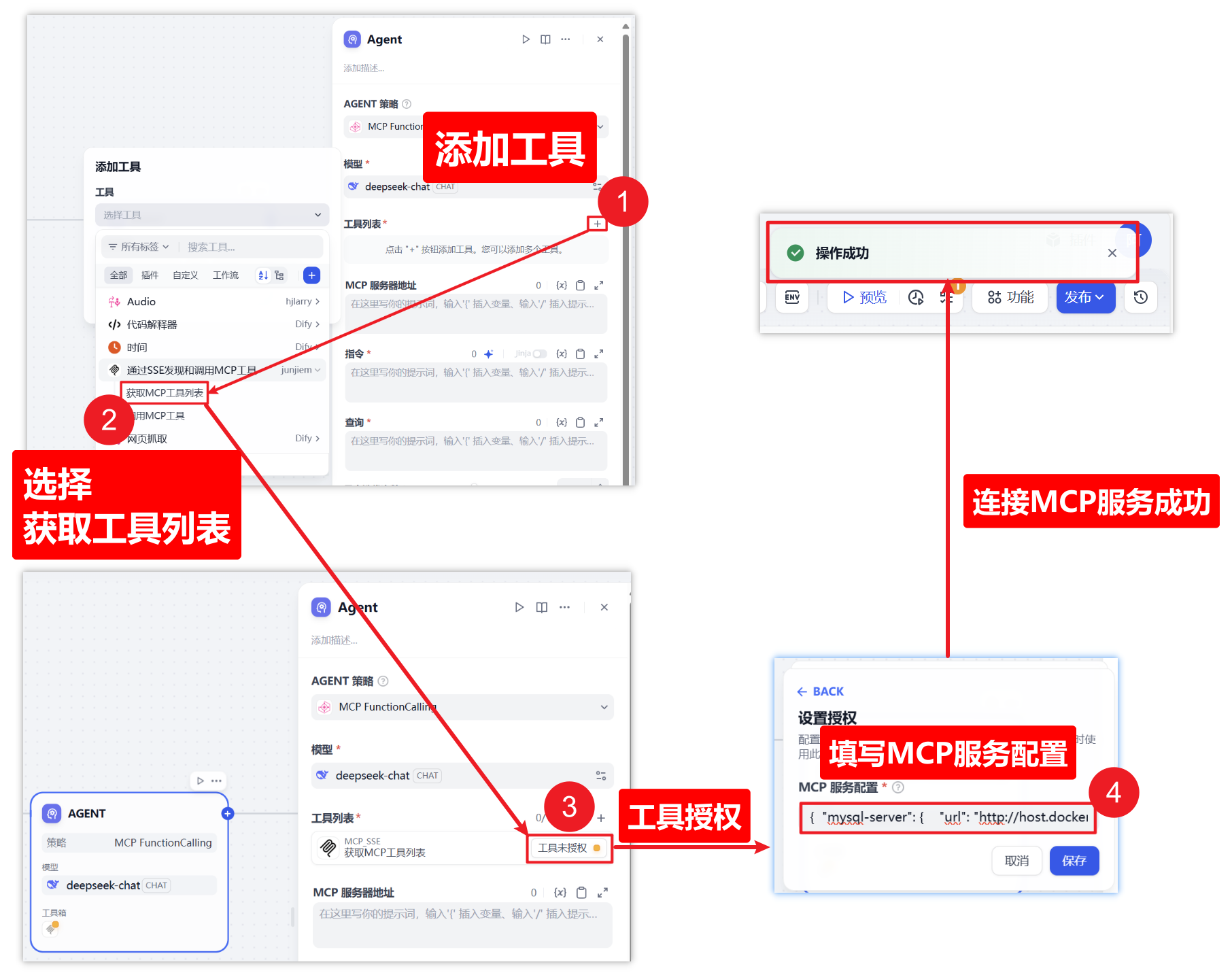
3、添加工具
① 点击添加工具
② 选择前面安装的插件工具
获取MCP工具列表,调用MCP工具,两个都要选择,此处仅以第一个为例,第二个操作步骤一样
③ 点击工具授权
④ 填写MCP的SSE服务配置
此处填写的信息就用到了前面启动MCP服务时我提到的端口号 3000 了
{ "mysql-server": { "url": "http://host.docker.internal:3000/sse", "headers": {}, "timeout": 60, "sse_read_timeout": 300 }}
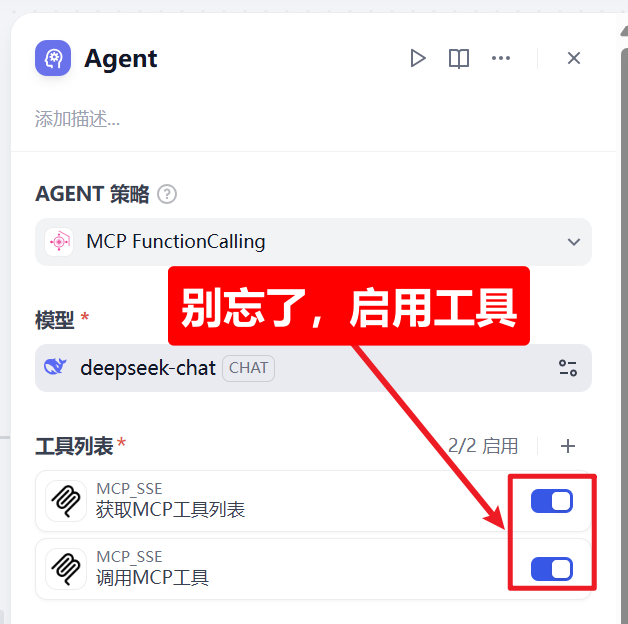
4、启用工具
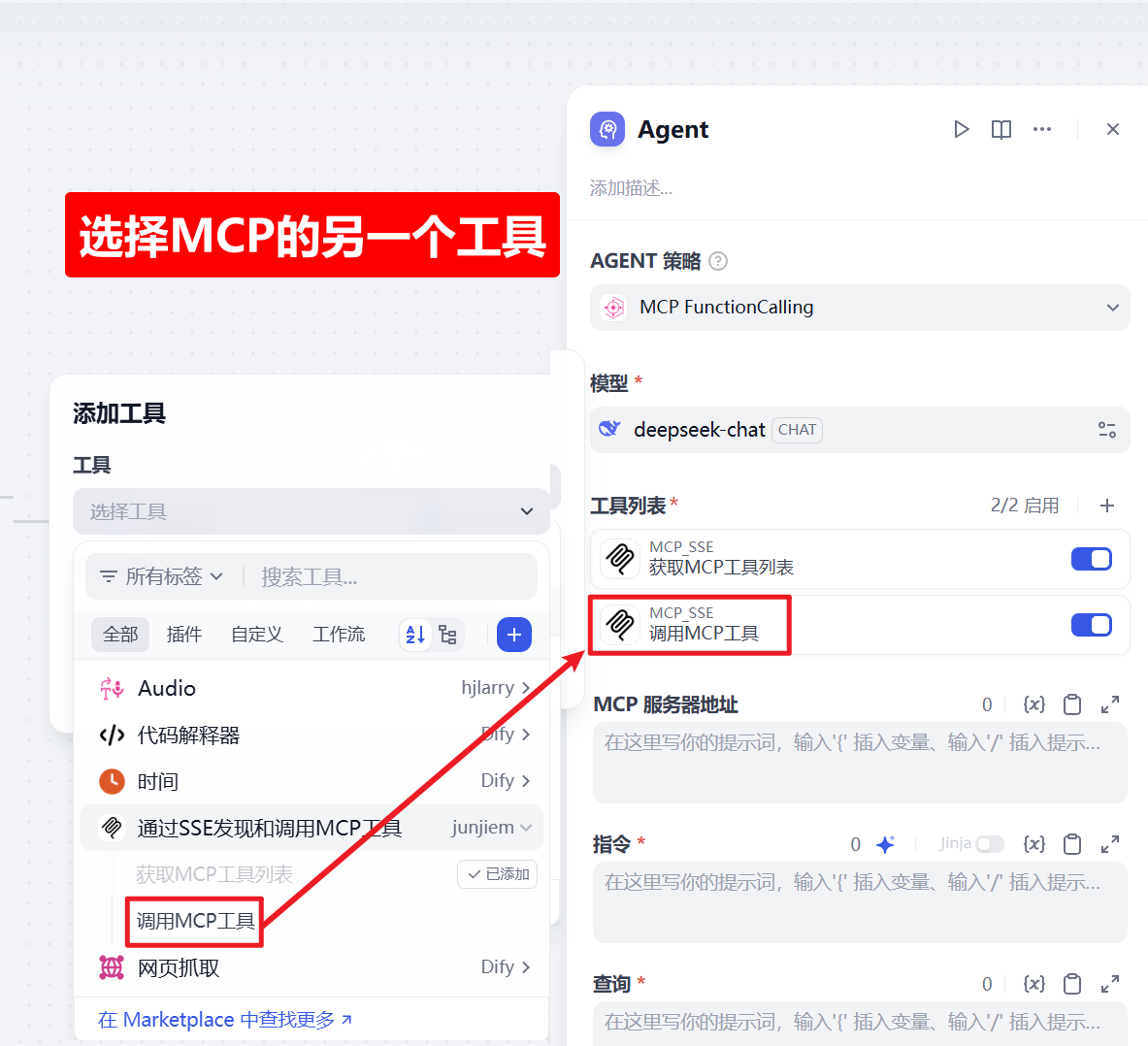
5、选择另一个工具
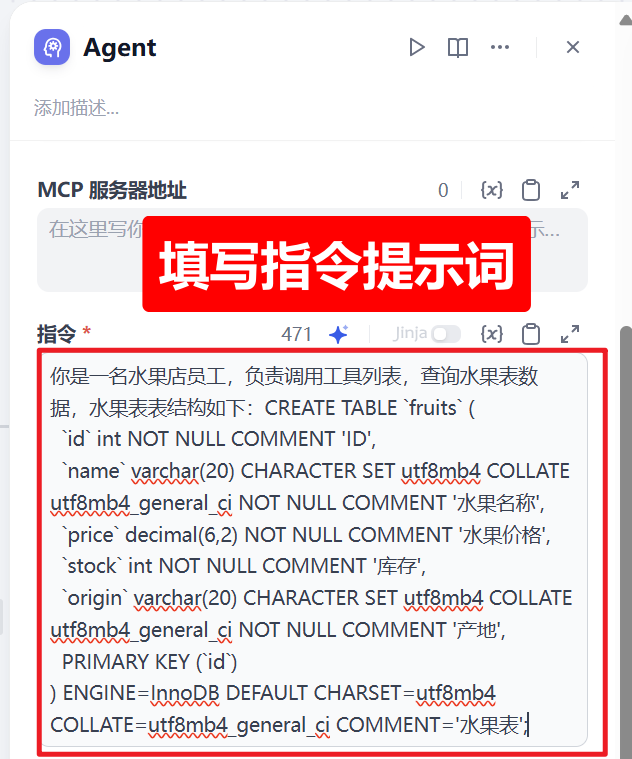
6、填写指令提示词
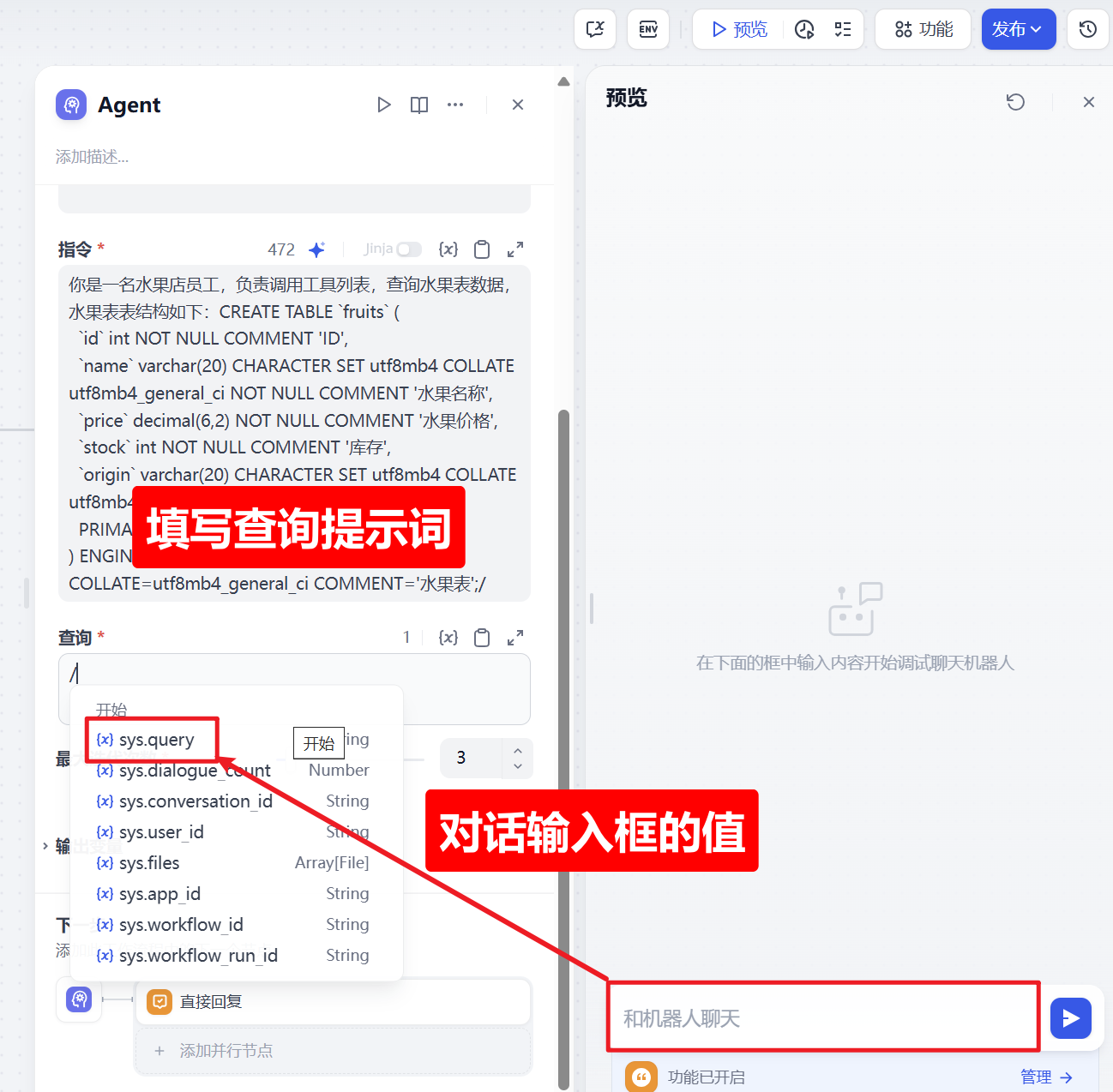
你是一名水果店员工,负责调用工具列表,查询水果表数据,水果表表结构如下:CREATE TABLE `fruits` (
`id` int NOT NULL COMMENT 'ID',
`name` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '水果名称',
`price` decimal(6,2) NOT NULL COMMENT '水果价格',
`stock` int NOT NULL COMMENT '库存',
`origin` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '产地',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='水果表';
7、设置查询提示词
聊天输入框的值就是 sys.query
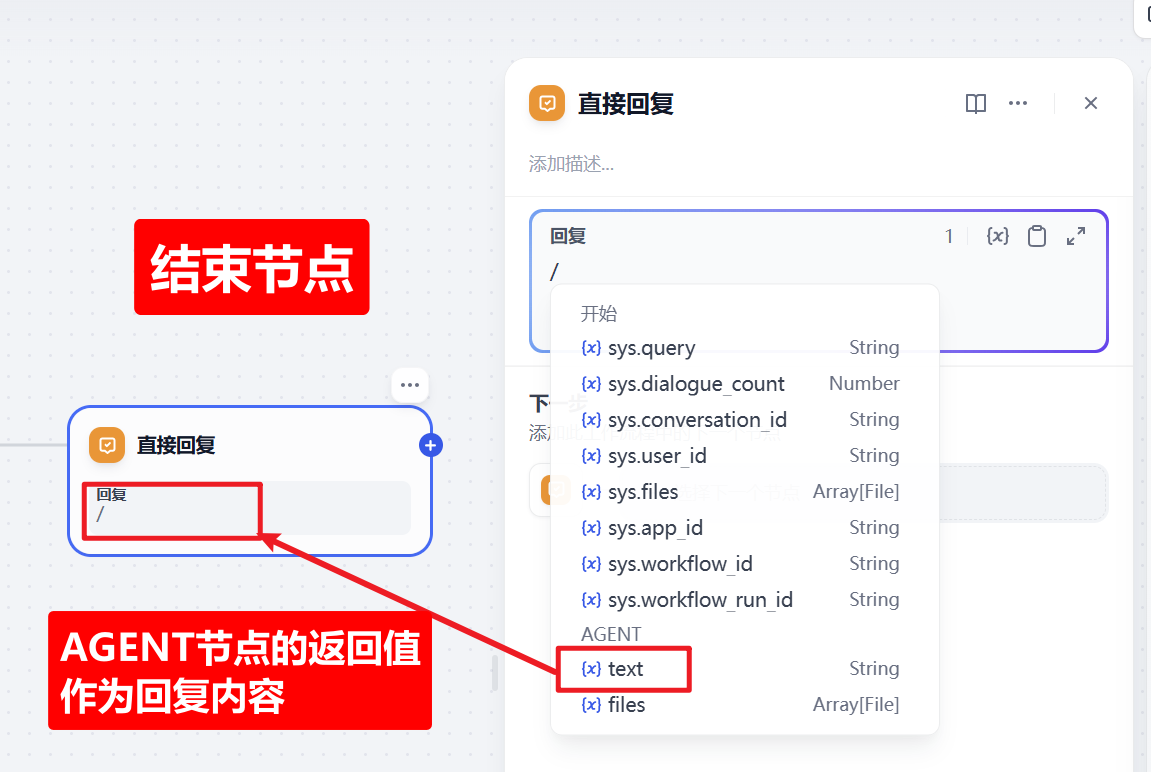
五)直接回复节点
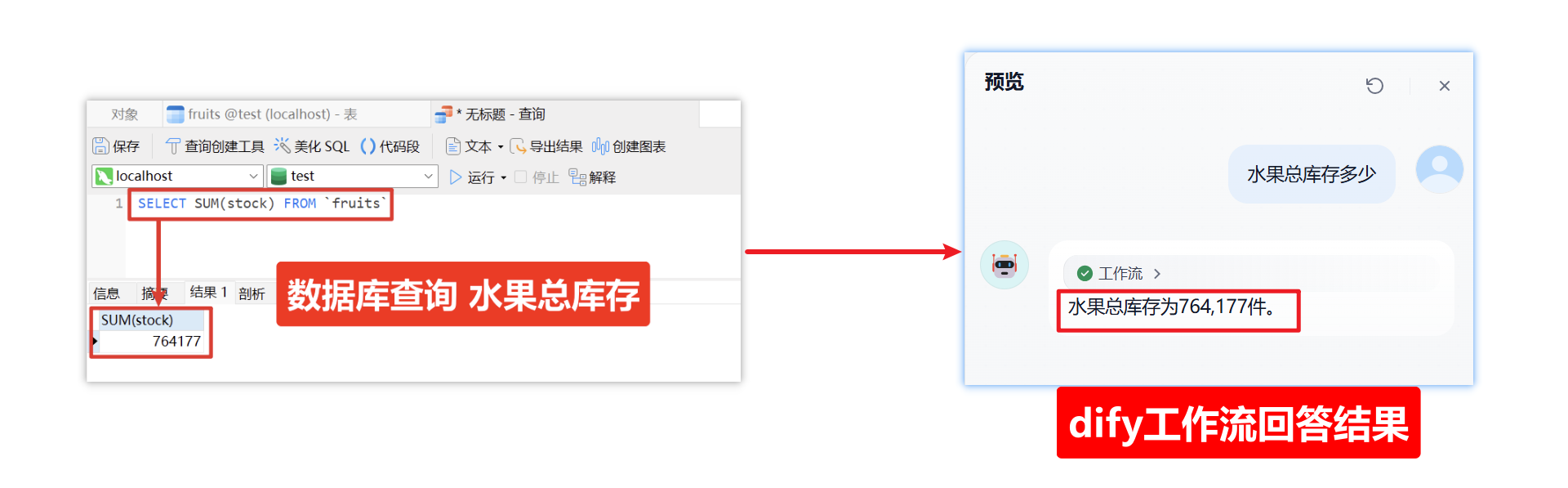
六)测试效果
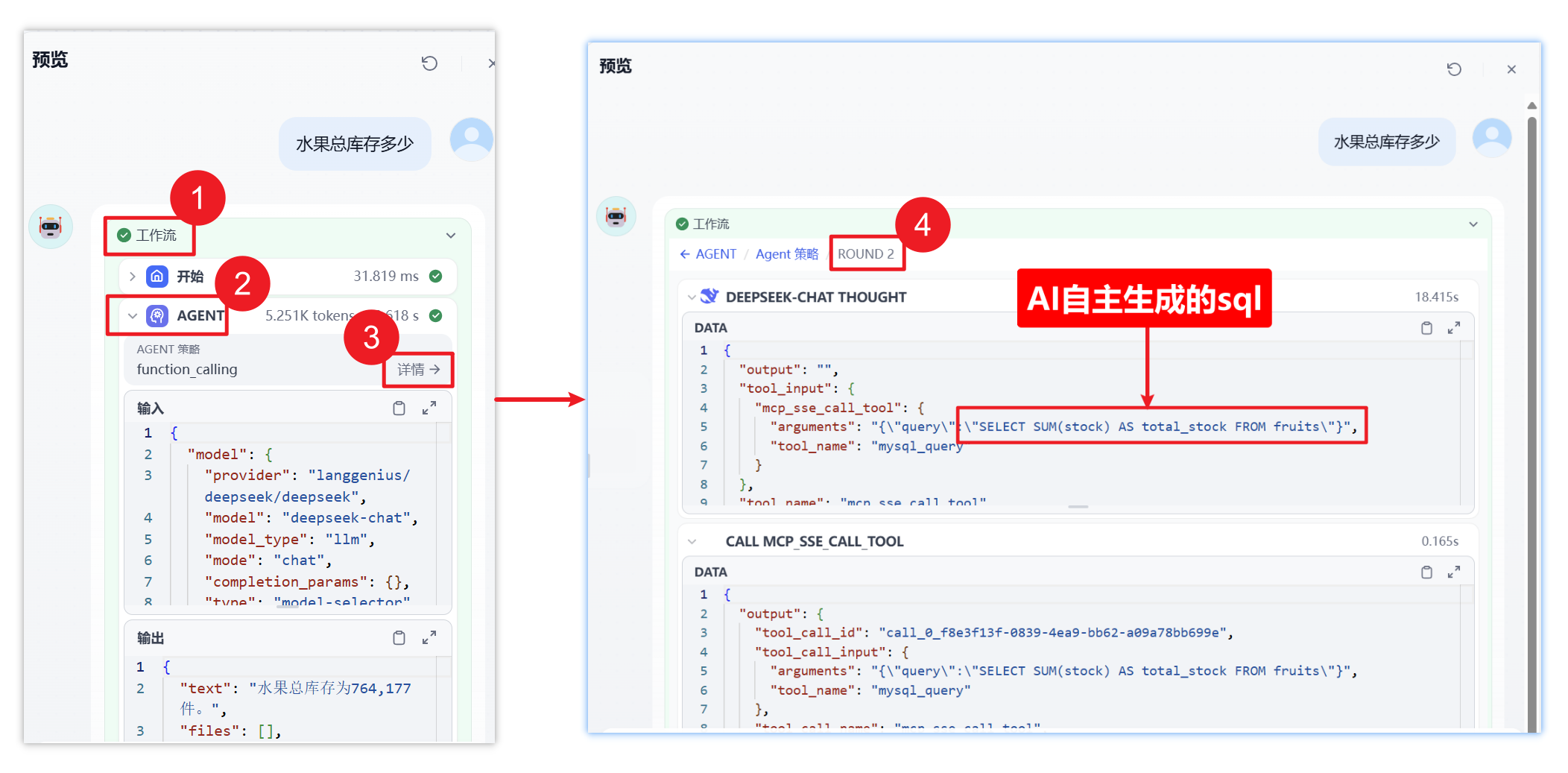
1、dify的返回结果
2、可以看到MCP服务控制台的打印信息
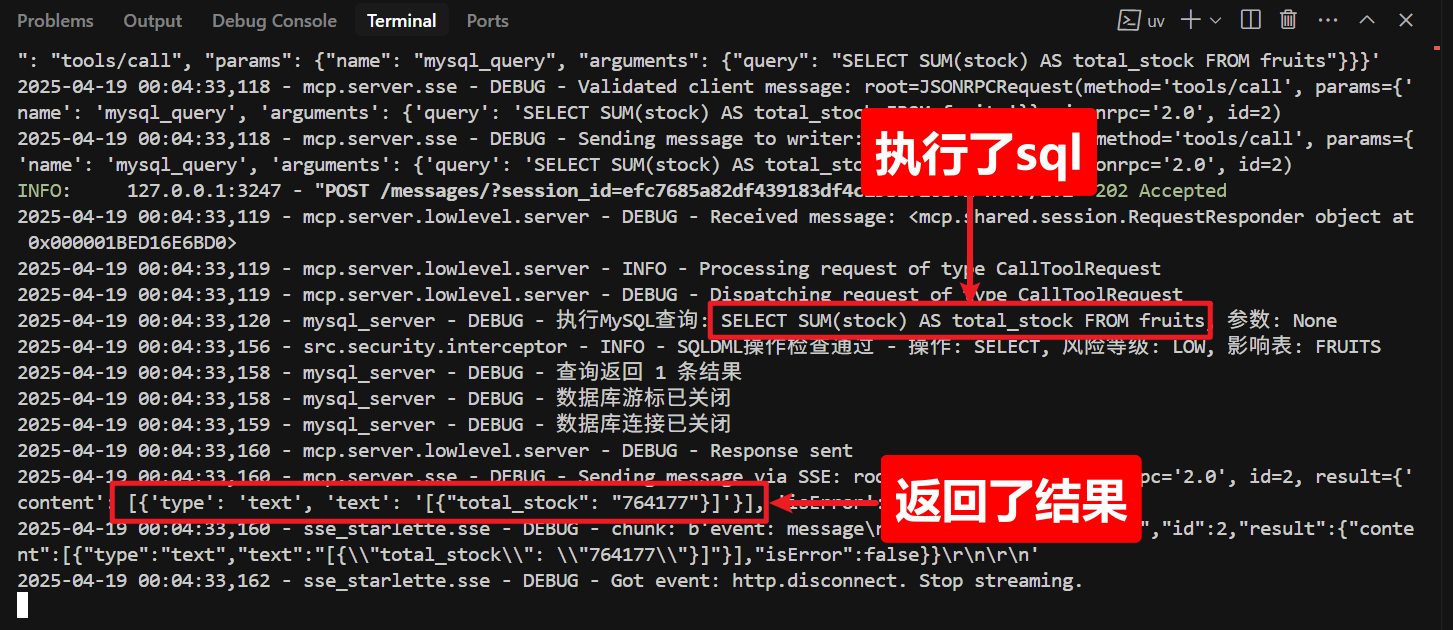
3、工作流的日志追踪
七)保存工作流
总结
MCP结合数据库的方案为Dify等知识库应用提供了高效、精准的结构化数据检索能力,显著提升了数据查询的准确性和灵活性,弥补了RAG的检索精度上的不足。
但是,这一方案也是有缺点的,与RAG每次只检索相关文本片段不同,MCP+数据库会真正执行SQL查询,若一次查询数据量过大,会消耗大量Token,甚至可能导致MCP客户端卡死。

















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









