







SSM(State Space Model)
在介绍Transformer,RNN,和Mamba之间的差异之前,我们需要先介绍一下同样是Mamba所基于的工作——SSM(State Space Model),也就是状态空间模型。
什么是状态空间模型?
SSM 是用于描述这些状态表示的模型,并根据某些输入预测它们的下一个状态可能是什么。
传统上,在时间 t 时,SSM:
- 映射输入序列 x(t)
- 到潜在状态表示 h(t)
- 并推导出预测的输出序列 y(t)
但是,它不是使用离散序列,而是将连续序列作为输入并预测输出序列。

可以用下面一个公式来表示连续序列中SSM的原理。
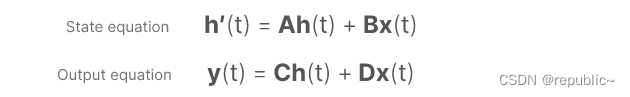
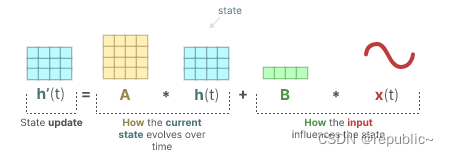
它的目标是找到这种状态表示h(t)我们可以以便从输入序列转到输出序列。由h'(t)表示下一时刻的状态空间,它可以由这一时刻的状态空间h(t)和这一时刻的输入x(t)来表示。
而这一时刻的输出y(t)又可以由这一时刻的输入 x(t) 与隐藏状态h(t)来表示。
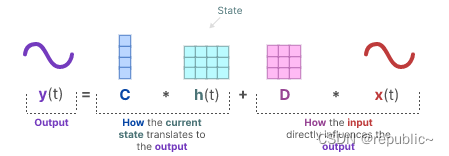
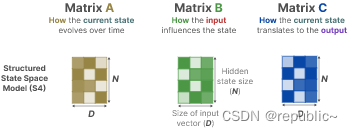
矩阵A、B、C 和 D通常也被称为参数,因为它们是可学习的。
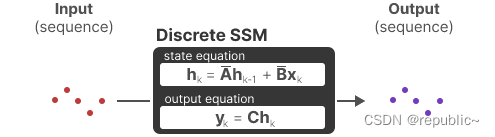
我们可以用一个架构图来直观的了解SSM模型的过程

由于矩阵 D 类似于 skip-connection,因此SSM通常被视为没有 skip-connection 的以下内容。

回到我们的简化视角,我们现在可以将矩阵 A、B 和 C 作为 SSM 的核心。

从连续信号到离散信号
在模型序列中的输入通常是离散的(如文本序列),因此我们需要对模型进行离散化。
从数学上讲,我们可以按如下方式应用零阶保持:
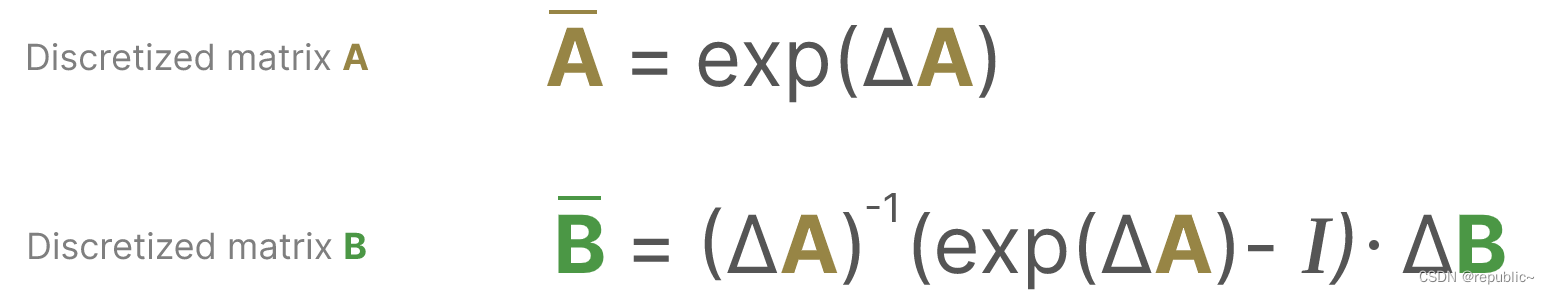
总之,它们允许我们从连续的 SSM 转到由公式表示的离散 SSM,该公式不是函数到函数x(t) → y(t),而是序列到序列。

RNN形态
如果我们考虑是离散的步长而不是连续信号,我们可以用时间步长重新表述问题:
连续时候类似的,这一时刻的隐藏状态h(t-1)会影响下一时刻的状态h(t),而这一时刻的输出y(t)又由这一时刻的输入x(t)和隐藏状态h(t)决定。这种方式和RNN十分类似,仅仅有激活函数上的一些细节差异。我们可以从折叠和展开形式的SSM观察它与RNN的差异。
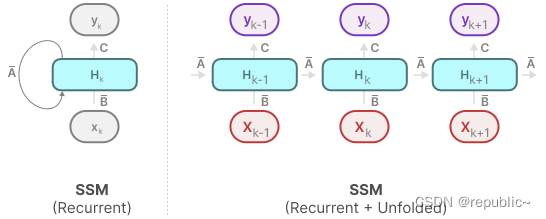
因此,这种方式具有RNN的推理速度快的优点,以及RNN所带来的训练速度慢的缺点。
CNN形态
SSM 的另一种表示形式是卷积。在经典的图像识别任务中,我们在二维上应用了卷积核派生聚合特征:
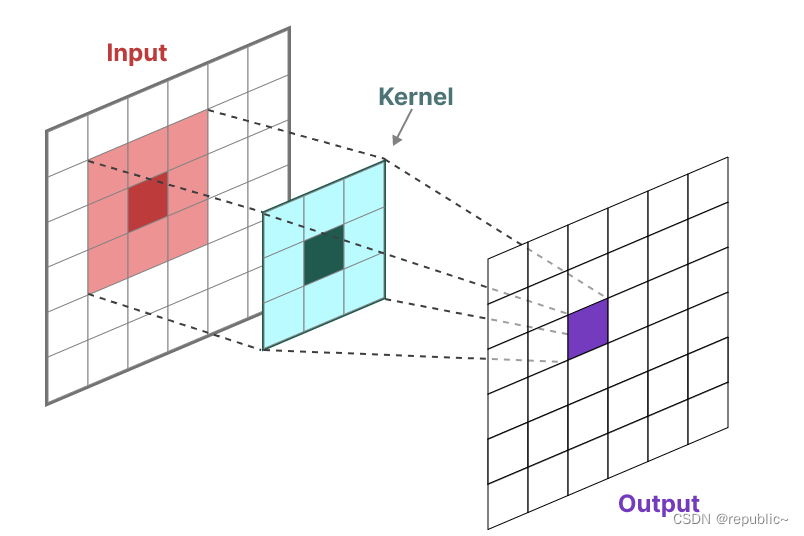
由于我们处理的是文本而不是图像,因此我们需要一个一维视角:

SSM所用的卷积核是由刚刚的公式所推到出来的
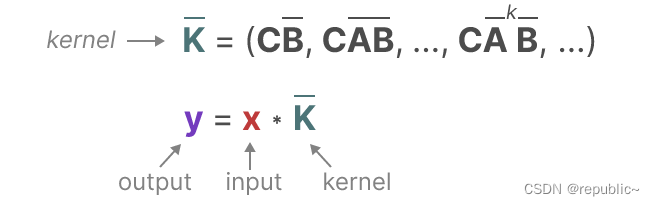
也就是说y可以完全由参数C,A,B和x来得到,而不必显式的计算隐藏状态h,比如对于输出y(2),
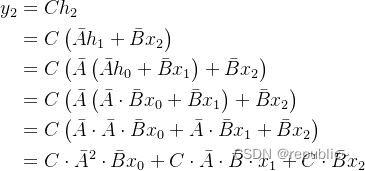
我们可以由状态空间公式将y(2)来拆分为仅由输入x(0),x(1),x(2)和参数A,B,C得到的输出。
基于这个原理,SSM具有卷积形态。比如从y(0)到y(2)的计算:
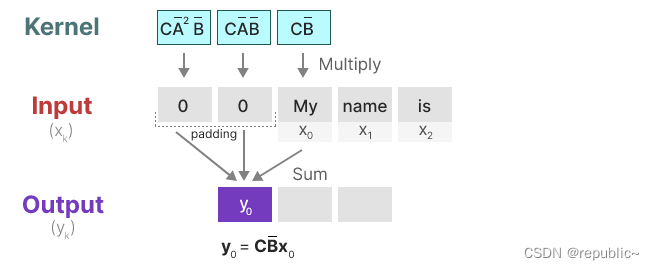
在下一步中,卷积核将移动一次,以执行计算中的下一步:
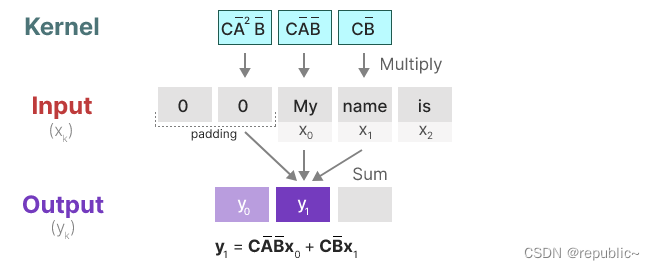
在最后一步中,我们可以看到卷积核的全部效果:

将 SSM 表示为卷积的一个主要好处是,它可以像卷积神经网络 (CNN) 一样并行训练。然而,由于内核大小固定,它们的推理并不像 RNN 那样快速和无限制。
两种形态
有了这些表示,我们可以使用一个巧妙的技巧,即根据任务选择表示。在训练期间,我们使用可以并行化的卷积表示,在推理过程中,我们使用有效的循环表示。另外,这也给了我们一些启发,我们可以将RNN,CNN,甚至Transformer都作为某种SSM模型的变体来理解。
Transformer
众所周知,Transformer具有全局依赖性。我们可以把Transformer视作某种对之前的所有信息平等的计算进隐藏状态的模型。
这样做的好处很显然,无论它收到什么输入,它都可以回顾序列中的任何早期token来推导出它的表示形式。当然它的劣势也很明显,它的自注意力机制对于全局建模,带来了大量的计算量。
自注意力机制
自注意力创建一个矩阵,将每个令牌与之前的每个令牌进行比较。矩阵中的权重由令牌对之间的相关性决定。
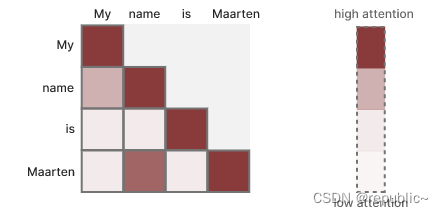
如果我们把这矩阵视为SSM中的状态矩阵,可以发现它没有经过任何的压缩,每个位置的权重都是相等的,只能通过QKV投影矩阵的参数学习来计算相关性。这种方式是有效的,但是它也很低效,带来大量的计算量。
RNN
现在,我们可以将RNN作为某种SSM的变体了。
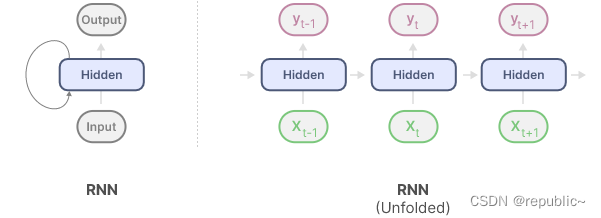
RNN 具有循环机制,允许它们将信息从上一步传递到下一步。我们可以展开这个可视化,使其更加明确。
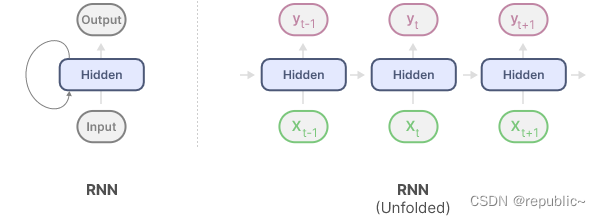
在生成输出时,RNN只需要考虑之前的隐藏状态和当前输入。它可以防止重新计算所有以前的隐藏状态,而这正是Transformer会做的事情。
换句话说,RNN可以快速进行推理,因为它与序列长度呈线性关系。从理论上讲,它甚至可以具有无限的上下文长度。
但是随着时间的流逝,RNN往往会忘记信息,因为它们只考虑隐藏状态Hidden中的信息,而这个信息是被压缩的。这个问题同样存在于SSM中。
RNN 的这种顺序性质产生了另一个问题。训练不能并行进行,因为它需要按顺序完成每个步骤。而SSM已经很好的解决了这个问题。
Mamba
如果把Transformer和RNN都视作某种SSM模型,那Mamba任务就很清晰了——找到一个好的状态空间表示,它应该被很好的压缩,不会产生遗忘的问题——正如RNN中那样,也并不完全不进行任何压缩——正如Transformer中那样。
SSM 的循环表示会创建一个小状态,该状态在压缩整个历史记录时非常有效。然而,与不压缩历史记录(通过注意力矩阵)的 Transformer 模型相比,它的强大功能要小得多。
曼巴的目标是两全其美。一个像Transformer一样强大的,和RRN一样小的状态。
输入依赖性
为此,Mamba引入另一个重要的机制——输入依赖性,正如Transformer中的那样。
为了有选择地压缩信息,我们需要参数依赖于输入。为此,让我们首先在训练期间探索SSM中输入和输出的维度:
取而代之的是,Mamba 通过合并输入的序列长度和批大小,使矩阵B和C,甚至 步长 ∆,都依赖于输入:
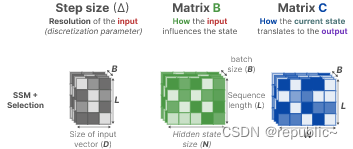
这意味着对于每个输入标记,我们现在都有不同的 B 和 C 矩阵,这解决了内容感知的问题。
它的实现非常简单,只需要对输入x(t)进行投影,就可以得到对应于x(t)的输入依赖的参数矩阵B(t),C(t),Δ(t)。
对于矩阵A,从本质上讲,矩阵 A 产生隐藏状态,因此它十分的重要,记录了之前隐藏状态的信息:
结合SSM之前的一项工作,引入Hippo矩阵来作为隐藏状态来缓解遗忘问题。
该表示可以很好地捕获最近的令牌并衰减较旧的令牌。其公式可以表示如下:

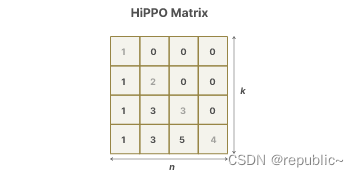
它背后的数学原理我们不做深究,我们只需要知道实验证明了Hippo矩阵来解决遗忘问题的有效性。
虽然它没有直接的输入依赖,矩阵A也由Δ的干预间接获得了输入依赖。
扫描算法
由于这些矩阵现在是动态的,因此不能使用卷积表示来计算它们,因为它假定了一个固定的核。我们只能使用循环表示,而失去了卷积提供的并行化。
为了启用并行化,Mamba通过并行扫描算法实现了这一点:
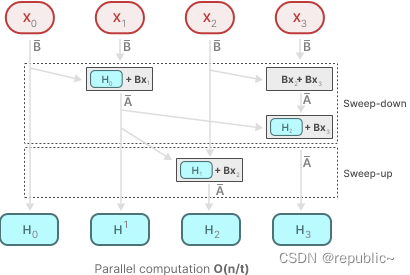
动态矩阵 B 和 C 以及并行扫描算法共同创建选择性扫描算法,以表示使用循环表示的动态和快速性质。
Mamba的架构
到目前为止,我们探索的选择性SSM可以作为一个块来实现,就像我们可以在解码器块中表示自我注意力一样。
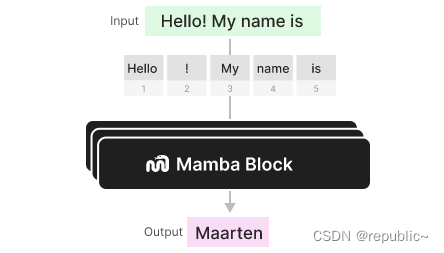
与解码器一样,我们可以堆叠多个 Mamba 块,并将它们的输出用作下一个 Mamba 块的输入:

可以看到Mamba解决之前提到的Transformer与RNN的问题,因此它具有它们的所有优点并且改善了所有的缺点。
















 1444
1444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









