









0. 前言
茫然中不知道该做什么,更看不到希望。
偶然看到coursera上有Andrew Ng教授的机器学习课程以及他UFLDL上的深度学习课程,于是静下心来,视频一个个的看,作业一个一个的做,程序一个一个的写。N多数学的不懂、Matlab不熟悉,开始的时候学习进度慢如蜗牛,坚持了几个月,终于也学完了。为了避免遗忘,在这里记下一些内容。由于水平有限,Python也不是太熟悉,英语也不够好,有错误或不当的地方,请不吝赐教。
神经网络有非常丰富的资料,在这里只是记录自己学习的过程、内容和心得。
1. 神经网络的表示
首先用一张图来表示多层神经网络的结构,如图1。
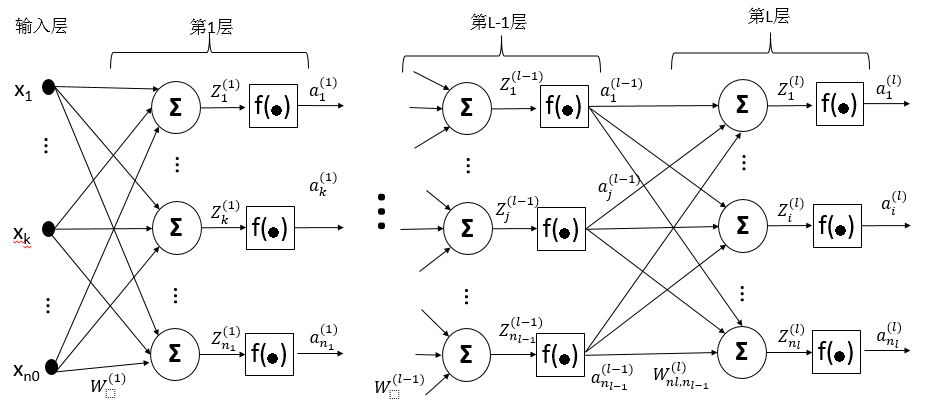
图1 神经网络结构图
1.1 符号说明
- 输入向量 x=[x1,x2,…,xn0]T 是一个列向量。
- 标签(label)
y
未在图中表示,它和
x 有相同维度。 - nl 为第L层的神经节点个数。
- W(l)∈Rnl×nl−1 为第L层的权重矩阵。截距 b(l)∈Rnl×1 未在图上表示。
-
Z(l)
表示第L层的活动水平向量,
- Z(l+1)i=Σnlj=1(W(l+1)ij×a(l)j+b(l+1)i) , a(0) 即为输入向量 x
Z(l+1)=W(l+1)×a(l)+b(l+1) ,矢量化表示。
- f(∙) 为激活函数,可以是sigmoid、tanh等。
- a(l)=f(Z(l)) 为第L层的激活向量,即输出向量。
- 若
l
层为输出层,定义假设函数
hW,b(x)=a(l)
1.2 反向传播算法
神经网络的反向传播算法是建立在最速梯度下降基础上的,希望误差的能量函数最小。对于输入向量
x
和标签
J(W,b;x,y)=12∥∥hW,b(x)−y∥∥2=12∑i=1nl(a(l)i−yi)2
我们要找到一个合适的W和b,使 J(W,b;x,y) 最小,即
minimizeW,bJ(W,b;x,y)(1)
使用梯度下降法:
W=W−α∇W(2)
b=b−α∇b(3)
α 为学习率。
下面通过推导求 ∇W,∇b 。
∂J∂W(l)ij=∂J∂Z(l)i∂Z(l)i∂W(l)ij=∂J∂a(l)i∂a(l)i∂Z(l)ia(l−1)j=∂J∂a(l)if′(Z(l)i)a(l−1)j(4)
∂J∂b(l)i=∂J∂Z(l)i∂Z(l)i∂b(l)i=∂J∂a(l)i∂a(l)i∂Z(l)i=∂J∂a(l)if′(Z(l)i)(5)
令误差项(大部分教材中,都把误差项分配到 l+1 层,但从个人编程的角度理解,把它归入到 l 层更方便)
∂J∂W(l)ij=δ(l)ia(l−1)j(7)
∂J∂b(l)i=δ(l)i(8)
或矢量化形式:
∇W(l)=∂J∂W(l)=δ(l)(a(l−1))T(9)
∇b(l)=∂J∂b(l)=δ(l)(10)
其中:
δ(l)=[δ(l)1,…,δ(l)nl]T,a(l−1)∈Rnl−1×1,∇W(l)∈Rnl×nl−1,∇b(l)∈Rnl×1
若 l 层为输出层,则:
则:
δ(l)i=∂J∂a(l)if′(Z(l)i)=(a(l)i−yi)f′(Z(l)i)(12)
或
δ(l)=(a(l)−y)∙f′(Z(l))(13)
(12)式中的“ ∙ ”是向量和矩阵中元素相乘运算符。
若 l 层是隐藏层,我们还需要对
∂J∂a(l)i=∑j=1nl+1∂J∂Z(l+1)j∂Z(l+1)j∂a(l)i=∑j=1nl+1∂J∂a(l+1)j∂a(l+1)j∂Z(l+1)j∂Z(l+1)j∂a(l)i
=∑j=1nl+1∂J∂a(l+1)jf′(Z(l+1)j)W(l+1)ji=∑jnl+1δ(l+1)jW(l+1)ji=(W(l+1)(,i))Tδ(l+1)(14)
代入(6)式,有
δ(l)i=(W(l+1)(,i))Tδ(l+1)f′(Z(l)i)(15)
矢量化后有
δ(l)=((W(l+1))Tδ(l+1))∙f′(Z(l))(16)
至此推导完成。
1.3 批量学习的函数形式
在上一节中
x
是一个向量,如果有m个向量,定义输入矩阵X和标签y:
其中 x(i) 为具有n个特征的列向量, y(i) 为表示类别的标量。
代价函数:
J(W,b)=1m∑i=1mJ(W,b;x(i),y(i))=1m∑i=1m12∥∥hW,b(x(i))−y(i)∥∥2
a(0)=X,Z(l)=W(l)×X,a(l)=f(Z(l)),l=1…nl
对于梯度
∇W(l)=1mδ(l)(a(l−1))T
∇b(l)=1m∑i=1mδ(i)
和误差项
δ(l)=(W(l))T×δ(l+1)∙f′(Z(l))
1.4 规范化
为了防止过拟合(overfiting),需要对误差函数和W梯度添加L2范式惩罚项。假定网络有L层,
J(W,b)=1m∑i=1m12∥∥hW,b(x(i))−y(i)∥∥2+λ2∑l=1L∑i=1nl∑j=1nl−1(W(l)ij)2
∇W(l)=1mδ(l)(a(l−1))T+λW(l)
2. 算法描述
重复直到收敛{
- 执行前向传播,得到各层的激活值
- 计算最后一层的
δ
- 反向传播计算各层
δ
- 计算各层W和b的梯度
- 使用梯度下降更新W和b
}















 2347
2347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









