







CA配置对应的是Band combination,每个band对应支持的 CA bandwidth class,如下表Table 5.3A.5-1。
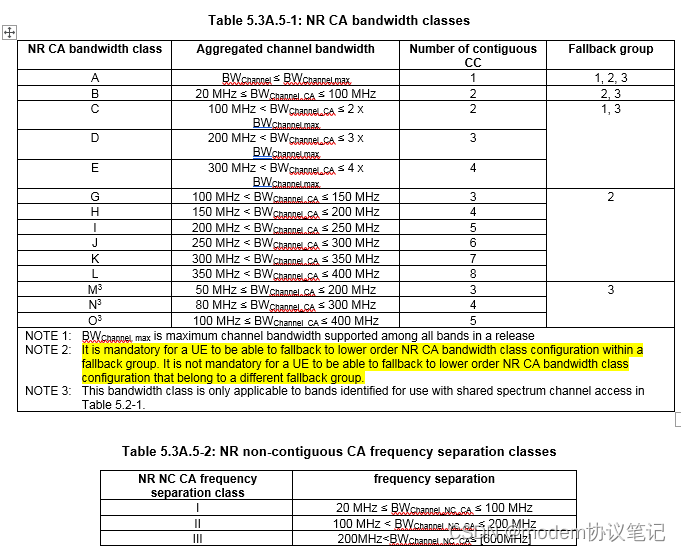
BW_channel,max对应的是协议中中规定的最大channel 带宽,FR1 R16对应的就是100MHZ。
如上述黄色字体部分,考虑的是实网下UE上报high order CA class时,结合实际资源调度情况,基站可能不能满足UE对应的CA bandwidthclass,这时可以配置lower order CA bandwidthclass,具体地,属于相同fallback group的 NR CA bandwidth class 可以回退到low order 的class,这个是强制支持的;UE是否支持属于不同fallback group的 class回退到low order class,协议上的描述没有强制要求,但是换到基站实现角度,这块就要综合考虑,对于协议上强制支持的内容,肯定要考虑进去,对于不强制支持的内容(协议上描述模棱两可的内容),基站侧应该就不会考虑,对于上面黄色字体这段话,如果基站侧采用协议不强制的规定给UE配置CA,估计是会出问题的。
具体说明下fallback group,例如CA bandwidth class O/M/N/E/D/C/B/A 属于相同的fallback group 3,则UE上报O时,网络侧可以根据实际资源调度情况将UE回退到lower order class M/N/E/D/C/B/A;上报N时可以回退到M/E/D/C/B/A等等,但是M就不能回退到fallback gourp 2中的配置。这里额外提醒下两个CA组合CA_n41C和CA_n41(2A)的区别,CA_n41C代表N41 带内连续2cc,而CA_n41(2A) 这里的2A则代表的是带内非连续2cc。

















 1188
1188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











