






请大家关注我,本文章粉丝可见,我会一直更新下去,完整代码进QQ群获取:323140750,大家一起进步、学习。
7.3.6 外部数据源
与目标变量呈现最强烈负相关的三个变量分别是EXT_SOURCE_1、EXT_SOURCE_2和EXT_SOURCE_3。这些特征代表来自外部数据源的“标准化分数”,是使用多个数据源制作的累积型信用评级。在接下来 的内容中,让我们来看看这些变量。
(1)首先,展示EXT_SOURCE特征与目标变量以及它们彼此之间的相关性。
#提取EXT_SOURCE变量并显示相关性
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
ext_data_corrs = ext_data.corr()
ext_data_corrs上述代码的功能是计算并显示目标变量'TARGET'与其他几个特定列('EXT_SOURCE_1','EXT_SOURCE_2','EXT_SOURCE_3'和'DAYS_BIRTH')之间的相关性,执行后会输出:
TARGET EXT_SOURCE_1 EXT_SOURCE_2 EXT_SOURCE_3 DAYS_BIRTH
TARGET 1.000000 -0.155317 -0.160472 -0.178919 -0.078239
EXT_SOURCE_1 -0.155317 1.000000 0.213982 0.186846 0.600610
EXT_SOURCE_2 -0.160472 0.213982 1.000000 0.109167 0.091996
EXT_SOURCE_3 -0.178919 0.186846 0.109167 1.000000 0.205478
DAYS_BIRTH -0.078239 0.600610 0.091996 0.205478 1.000000相关性矩阵将展示这些变量之间的关系,有助于理解它们是否彼此相关以及它们如何与目标变量相关联。
(2)绘制一个热力图,以可视化展示相关性矩阵的数据。这可以帮助我们更直观地理解各个变量之间的相关性,正相关或负相关的强度,以及它们与目标变量之间的关系。具体实现代码如下所示。
plt.figure(figsize = (8, 6))
sns.heatmap(ext_data_corrs, cmap = plt.cm.RdYlBu_r, vmin = -0.25, annot = True, vmax = 0.6)
plt.title('Correlation Heatmap');执行效果如图7-10所示,由此可见,所有三个EXT_SOURCE特征与目标变量都具有负相关性,这表明随着EXT_SOURCE值的增加,客户更有可能偿还贷款。同时,还可以看到DAYS_BIRTH与EXT_SOURCE_1呈正相关,这可能表明这个分数中的一个因素是客户的年龄。
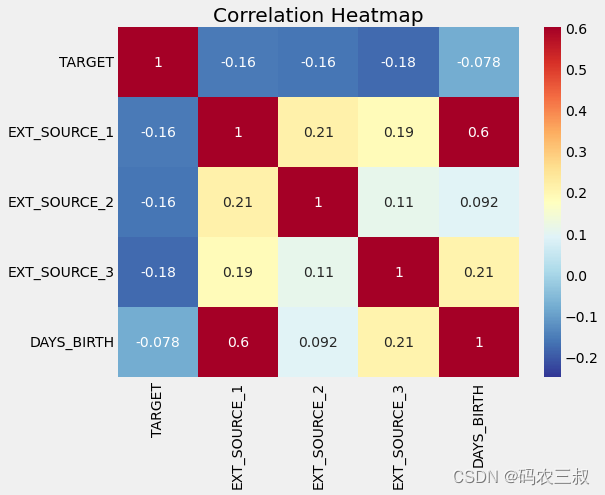
图7-10 相关性矩阵热力图
(3)接下来可以查看每个特征的分布,并根据目标变量的值进行着色,可视化展示这些变量对目标变量的影响。将对这些特征进行可视化分析,以查看它们与目标变量之间的关系。通过将不同目标变量值的数据点用不同颜色表示,可以更清楚地看到这些特征如何影响目标变量。这种可视化分析有助于了解这些特征对目标变量的预测能力以及它们如何在不同情况下变化。
# 设置图形大小为10x12
plt.figure(figsize=(10, 12))
# 遍历各个数据源
for i, source in enumerate(['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']):
# 为每个数据源创建一个新的子图
plt.subplot(3, 1, i + 1)
# 绘制已偿还贷款的分布
sns.kdeplot(app_train.loc[app_train['TARGET'] == 0, source], label='target == 0')
# 绘制未偿还贷款的分布
sns.kdeplot(app_train.loc[app_train['TARGET'] == 1, source], label='target == 1')
# 为子图添加标题
plt.title('%s按目标值的分布' % source)
plt.xlabel('%s' % source)
plt.ylabel('密度')
# 调整子图布局,增加垂直间距
plt.tight_layout(h_pad=2.5)上述代码的功能是创建三个子图,每个子图用于可视化不同的外部数据源('EXT_SOURCE_1','EXT_SOURCE_2','EXT_SOURCE_3')与目标变量的关系。绘制了每个数据源在目标变量为0和1时的分布情况,并以核密度估计(Kernel Density Estimate,KDE)的方式呈现这些分布。这样可以帮助我们了解每个数据源如何影响目标变量,并可视化不同目标值下的分布情况。执行效果如图7-11所示。
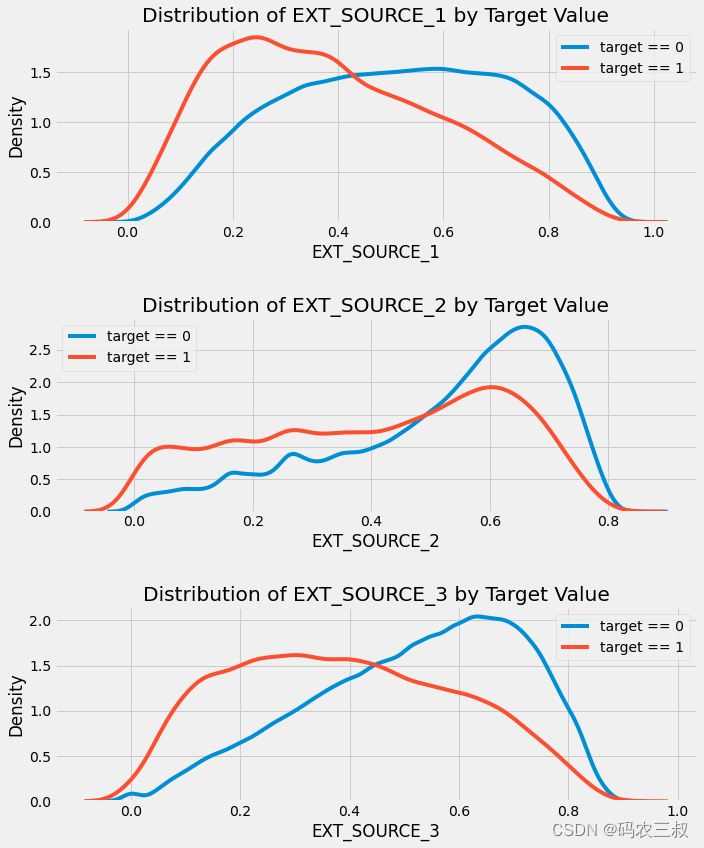
图7-11 不同的外部数据源与目标变量的关系
EXT_SOURCE_3展示了目标变量值之间的最大差异,可以清晰地看到这个特征与申请人按时偿还贷款的可能性存在某种关系。尽管这种关系不是非常强(事实上,它们都被认为是非常弱的),但这些变量仍然对机器学习模型预测申请人是否按时偿还贷款非常有用。
7.3.7 绘制Pairs Plot(成对图)
接下来制作一个EXT_SOURCE变量和DAYS_BIRTH变量的Pairs Plot(成对图),Pairs Plot是一个很好的探索工具,因为它允许我们查看多个变量对之间的关系,以及单个变量的分布情况。在这里,使用了Python的Seaborn可视化库和PairGrid函数来创建一个Pairs Plot,其中上三角部分是散点图,对角线上是直方图,下三角部分是2D核密度图和相关系数。具体实现代码如下所示。
# 复制数据以供绘图使用
plot_data = ext_data.drop(columns=['DAYS_BIRTH']).copy()
# 添加客户的年龄(以年为单位)
plot_data['YEARS_BIRTH'] = age_data['YEARS_BIRTH']
# 删除缺失值并限制在前100,000行
plot_data = plot_data.dropna().loc[:100000, :]
# 定义计算两列之间相关系数的函数
def corr_func(x, y, **kwargs):
r = np.corrcoef(x, y)[0][1]
ax = plt.gca()
ax.annotate("r = {:.2f}".format(r),
xy=(.2, .8), xycoords=ax.transAxes,
size=20)
# 创建PairGrid对象
grid = sns.PairGrid(data=plot_data, size=3, diag_sharey=False, hue='TARGET',
vars=[x for x in list(plot_data.columns) if x != 'TARGET'])
# 上三角部分是散点图
grid.map_upper(plt.scatter, alpha=0.2)
# 对角线部分是直方图
grid.map_diag(sns.kdeplot)
# 下三角部分是密度图
grid.map_lower(sns.kdeplot, cmap=plt.cm.OrRd_r)
# 添加总标题
plt.suptitle('Ext Source and Age Features Pairs Plot', size=32, y=1.05);上述代码的功能是创建一个成对图(Pairs Plot),该图可视化了EXT_SOURCE变量和年龄(YEARS_BIRTH)变量之间的关系。成对图展示了多个变量对之间的散点图、单个变量的直方图以及下三角部分的2D核密度图和相关系数。具体实现流程如下所示:
- 首先,从ext_data中复制数据,并添加客户的年龄信息。
- 然后,删除缺失值并限制数据到前100,000行。
- 定义了一个用于计算两列之间相关系数的函数corr_func。
- 创建了PairGrid对象,指定了散点图、直方图和密度图的绘制方式。
- 最后,添加总标题以描述这个Pairs Plot的内容。
绘制的成对图(Pairs Plot)效果如图7-12所示。

图7-12 绘制的成对图(Pairs Plot)
在这个成对图中,红色表示未偿还的贷款,蓝色表示已支付的贷款。我们可以看到数据内部的不同关系。EXT_SOURCE_1和DAYS_BIRTH(或者等同的YEARS_BIRTH)之间似乎存在中等程度的正线性关系,这表明这个特征可能考虑了客户的年龄。
7.3.8 特征工程
在人工智能领域,成功的大模型通常来自于特征工程:能够从数据中创建最有用特征。这些优秀的模型,通常是结构化数据梯度提升的变种。这代表了机器学习中的一个模式:特征工程的回报率大于模型构建和超参数调整。虽然选择正确的模型和最佳设置很重要,但模型只能从它所接收的数据中进行学习。确保这些数据与任务尽可能相关是数据科学家的职责(也可能有一些自动化工具来帮助我们)。
特征工程涉及到一个通用的过程,可以包括特征构建(从现有数据中添加新特征)和特征选择(选择最重要的特征或其他降维方法),可以使用许多技术来创建和选择特征。当我们开始使用其他数据源时,将进行大量的特征工程。但在本实例中,将尝试只使用两种简单的特征构建方法:多项式特征和领域知识特征。
1. 多项式特征
一个简单的特征构建方法称为多项式特征。在这种方法中,我们创建的特征是现有特征的幂次以及现有特征之间的交互项。例如,我们可以创建变量EXT_SOURCE_1^2和EXT_SOURCE_2^2,以及变量EXT_SOURCE_1 x EXT_SOURCE_2、EXT_SOURCE_1 x EXT_SOURCE_2^2、EXT_SOURCE_1^2 x EXT_SOURCE_2^2等等。这些由多个单独变量组合而成的特征被称为交互项,因为它们捕获了变量之间的相互作用。换句话说,虽然两个单独的变量本身对目标的影响可能不强,但将它们组合成一个单一的交互变量可能会显示与目标的关系。交互项在统计模型中常用于捕获多个变量的效应,但是并不经常看到它们在机器学习中使用。尽管如此,我们可以尝试一些交互项,看看它们是否有助于我们的模型预测客户是否会按时偿还贷款。
(1)首先在下面的代码中,使用EXT_SOURCE变量和DAYS_BIRTH变量创建多项式特征。通过使用Scikit-Learn中的类PolynomialFeatures可以创建多项式和交互项,可以指定一个特定的阶数。我们可以使用阶数为3来查看结果(当创建多项式特征时,我们要避免使用过高的阶数,因为随着阶数的增加,特征的数量会呈指数级增长,并且可能会出现过拟合的问题)。
# 创建新的多项式特征数据框
poly_features = app_train[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH', 'TARGET']]
poly_features_test = app_test[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
# 导入用于处理缺失值的SimpleImputer
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='median')
# 提取目标变量
poly_target = poly_features['TARGET']
# 删除目标变量列
poly_features = poly_features.drop(columns=['TARGET'])
# 需要填充缺失值
poly_features = imputer.fit_transform(poly_features)
poly_features_test = imputer.transform(poly_features_test)
# 导入PolynomialFeatures用于创建多项式特征
from sklearn.preprocessing import PolynomialFeatures
# 创建指定阶数的多项式对象
poly_transformer = PolynomialFeatures(degree=3)
# 训练多项式特征
poly_transformer.fit(poly_features)
# 转换特征
poly_features = poly_transformer.transform(poly_features)
poly_features_test = poly_transformer.transform(poly_features_test)
# 打印多项式特征的形状
print('多项式特征的形状: ', poly_features.shape)上述代码的功能是使用原始数据集中的一些特征('EXT_SOURCE_1','EXT_SOURCE_2','EXT_SOURCE_3','DAYS_BIRTH')创建多项式特征。首先,它从原始数据集中提取了相关特征,并在测试数据集上进行了相同操作。接下来,使用Imputer填充了缺失值,然后使用PolynomialFeatures创建了多项式特征。最后,打印出多项式特征的形状,以检查新特征的维度。执行后会输出:
Polynomial Features shape: (307511, 35)(2)然后通过如下代码获取创建的大量新特征的名称,它使用了polynomial_features对象的get_feature_names方法,并指定了输入特征的名称列表。
# 获取多项式特征的名称
poly_feature_names = poly_transformer.get_feature_names(input_features=['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH'])
# 打印前15个多项式特征的名称
print(poly_feature_names[:15])在上述代码中,get_feature_names方法会返回一个包含所有新特征名称的列表,通过打印前15个名称,可以查看这些新特征的一部分。这些新特征是原始特征的不同组合和幂次,以捕捉原始特征之间的复杂关系。执行后会输出:
['1',
'EXT_SOURCE_1',
'EXT_SOURCE_2',
'EXT_SOURCE_3',
'DAYS_BIRTH',
'EXT_SOURCE_1^2',
'EXT_SOURCE_1 EXT_SOURCE_2',
'EXT_SOURCE_1 EXT_SOURCE_3',
'EXT_SOURCE_1 DAYS_BIRTH',
'EXT_SOURCE_2^2',
'EXT_SOURCE_2 EXT_SOURCE_3',
'EXT_SOURCE_2 DAYS_BIRTH',
'EXT_SOURCE_3^2',
'EXT_SOURCE_3 DAYS_BIRTH',
'DAYS_BIRTH^2'](3)现在已经创建了包含35个特征的数据框,其中包括每个特征的幂次和交互项,接下来,将检查这些新特征是否与目标变量相关,具体实现代码如下所示。
# 创建包含多项式特征的数据框
poly_features = pd.DataFrame(poly_features,
columns=poly_transformer.get_feature_names(['EXT_SOURCE_1', 'EXT_SOURCE_2',
'EXT_SOURCE_3', 'DAYS_BIRTH']))
# 添加目标变量
poly_features['TARGET'] = poly_target
# 计算特征与目标的相关性
poly_corrs = poly_features.corr()['TARGET'].sort_values()
# 显示与目标相关性最高的前10个和最低的5个特征
print(poly_corrs.head(10))
print(poly_corrs.tail(5))print(poly_corrs.tail(5))
上述代码的功能是创建一个包含多项式特征的数据框,并计算这些特征与目标变量之间的相关性。最后,打印了与目标相关性最高的前10个和最低的5个特征。这可以帮助我们了解哪些新特征与目标变量之间存在强烈的相关性,这些特征可能对模型的性能产生积极影响。执行后会输出:
EXT_SOURCE_2 EXT_SOURCE_3 -0.193939
EXT_SOURCE_1 EXT_SOURCE_2 EXT_SOURCE_3 -0.189605
EXT_SOURCE_2 EXT_SOURCE_3 DAYS_BIRTH -0.181283
EXT_SOURCE_2^2 EXT_SOURCE_3 -0.176428
EXT_SOURCE_2 EXT_SOURCE_3^2 -0.172282
EXT_SOURCE_1 EXT_SOURCE_2 -0.166625
EXT_SOURCE_1 EXT_SOURCE_3 -0.164065
EXT_SOURCE_2 -0.160295
EXT_SOURCE_2 DAYS_BIRTH -0.156873
EXT_SOURCE_1 EXT_SOURCE_2^2 -0.156867
Name: TARGET, dtype: float64
DAYS_BIRTH -0.078239
DAYS_BIRTH^2 -0.076672
DAYS_BIRTH^3 -0.074273
TARGET 1.000000
1 NaN
Name: TARGET, dtype: float64(4)现在已经创建了多项式特征,并计算了它们与目标变量的相关性,接下来,将这些特征添加到训练数据和测试数据的副本中,并构建模型以比较使用这些特征和不使用这些特征的效果。具体实现代码如下所示。
# 将多项式特征添加到测试数据框中
poly_features_test = pd.DataFrame(poly_features_test,
columns=poly_transformer.get_feature_names(['EXT_SOURCE_1', 'EXT_SOURCE_2',
'EXT_SOURCE_3', 'DAYS_BIRTH']))
# 将多项式特征合并到训练数据框中
poly_features['SK_ID_CURR'] = app_train['SK_ID_CURR']
app_train_poly = app_train.merge(poly_features, on='SK_ID_CURR', how='left')
# 将多项式特征合并到测试数据框中
poly_features_test['SK_ID_CURR'] = app_test['SK_ID_CURR']
app_test_poly = app_test.merge(poly_features_test, on='SK_ID_CURR', how='left')
# 对齐数据框
app_train_poly, app_test_poly = app_train_poly.align(app_test_poly, join='inner', axis=1)
# 打印新数据框的形状
print('包含多项式特征的训练数据形状: ', app_train_poly.shape)
print('包含多项式特征的测试数据形状: ', app_test_poly.shape)上述代码的功能是将多项式特征添加到训练数据和测试数据的副本中,然后对齐这两个数据框,以确保它们具有相同的特征。最后,打印出包含多项式特征的训练数据和测试数据的形状,以检查新特征是否已成功添加到数据中。执行后会输出:
包含多项式特征的训练数据形状: (307511, 275)
包含多项式特征的测试数据形状: (48744, 275)2. 领域知识特征
(1)创建一些与贷款违约相关的特征,尽管称其为“领域知识”可能不太准确,但它们是根据有限的金融知识尝试生成的特征。这些特征试图捕捉客户是否会违约贷款的重要因素。具体实现代码如下所示。
# 复制训练和测试数据以进行领域特征工程
app_train_domain = app_train.copy()
app_test_domain = app_test.copy()
# 创建以下五个特征,灵感来自于Aguiar的脚本
# CREDIT_INCOME_PERCENT: 贷款金额相对于客户收入的百分比
# ANNUITY_INCOME_PERCENT: 贷款年金相对于客户收入的百分比
# CREDIT_TERM: 还款期限(以月计算,因为年金是每月应还金额)
# DAYS_EMPLOYED_PERCENT: 工作天数相对于客户年龄的百分比
app_train_domain['CREDIT_INCOME_PERCENT'] = app_train_domain['AMT_CREDIT'] / app_train_domain['AMT_INCOME_TOTAL']
app_train_domain['ANNUITY_INCOME_PERCENT'] = app_train_domain['AMT_ANNUITY'] / app_train_domain['AMT_INCOME_TOTAL']
app_train_domain['CREDIT_TERM'] = app_train_domain['AMT_ANNUITY'] / app_train_domain['AMT_CREDIT']
app_train_domain['DAYS_EMPLOYED_PERCENT'] = app_train_domain['DAYS_EMPLOYED'] / app_train_domain['DAYS_BIRTH']
app_test_domain['CREDIT_INCOME_PERCENT'] = app_test_domain['AMT_CREDIT'] / app_test_domain['AMT_INCOME_TOTAL']
app_test_domain['ANNUITY_INCOME_PERCENT'] = app_test_domain['AMT_ANNUITY'] / app_test_domain['AMT_INCOME_TOTAL']
app_test_domain['CREDIT_TERM'] = app_test_domain['AMT_ANNUITY'] / app_test_domain['AMT_CREDIT']
app_test_domain['DAYS_EMPLOYED_PERCENT'] = app_test_domain['DAYS_EMPLOYED'] / app_test_domain['DAYS_BIRTH']上述代码的功能是根据一些假设的贷款违约相关因素,创建了新的领域特征,例如贷款金额与客户收入的比例、贷款年金与客户收入的比例、还款期限和工作天数与客户年龄的比例。这些特征可以帮助模型更好地理解贷款违约的可能性。
(2)接下来可视化新领域知识变量,通过绘制KDE图(核密度估计图),并根据目标变量的值进行颜色标记,以便观察这些变量的分布。具体实现代码如下所示。
import matplotlib.pyplot as plt
import seaborn as sns
# 创建一个图形,指定图形大小
plt.figure(figsize=(12, 20))
# 遍历新特征
for i, feature in enumerate(
['CREDIT_INCOME_PERCENT', 'ANNUITY_INCOME_PERCENT', 'CREDIT_TERM', 'DAYS_EMPLOYED_PERCENT']):
# 创建新的子图
plt.subplot(4, 1, i + 1)
# 绘制已偿还贷款的KDE图
sns.kdeplot(app_train_domain.loc[app_train_domain['TARGET'] == 0, feature], label='target == 0')
# 绘制未偿还贷款的KDE图
sns.kdeplot(app_train_domain.loc[app_train_domain['TARGET'] == 1, feature], label='target == 1')
# 添加图标题和标签
plt.title('按目标值分布的%s' % feature)
plt.xlabel('%s' % feature)
plt.ylabel('密度')
# 调整子图布局
plt.tight_layout(h_pad=2.5)上述代码的功能是创建一个包含四个子图的图形,每个子图表示一个领域知识变量(如贷款金额与客户收入的比例、贷款年金与客户收入的比例等),如图7-13所示。在每个子图中,通过KDE图可视化已偿还贷款(target == 0)和未偿还贷款(target == 1)的分布,以便观察这些变量在不同目标值下的分布情况。这可以帮助我们了解这些变量与目标变量之间的关系。

"贷款金额与收入百分比(按目标值)"和"年金与收入百分比(按目标值)"的分布图和"贷款期限(按目标值)"和"工作天数百分比(按目标值)"的分布图
图7-13 领域知识变量分布图
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











