







行为识别阅读笔记(paper+ parted code):Beyond Frame-level CNN Saliency-Aware 3-DCNN with LSTM for Video Action Recognition
这篇文章是发篇在IEEESignal Processing2016上的一篇文章,算是比较久的文章。文章使用的网络结构是C3D+LSTM,没啥创新之处,个人觉得文章的创新点主要在于使用了视频运动目标显著性检测来作为网络的输入,以提高实验效果。在UCF101和HMDB51上的实验结果还没双流法的效果好,对比的对象都是一些比较low的方法,并没有和state-of-the-art进行比较。这里就不过多的对文章评论了,直接看文章具体内容。
一.网络框架
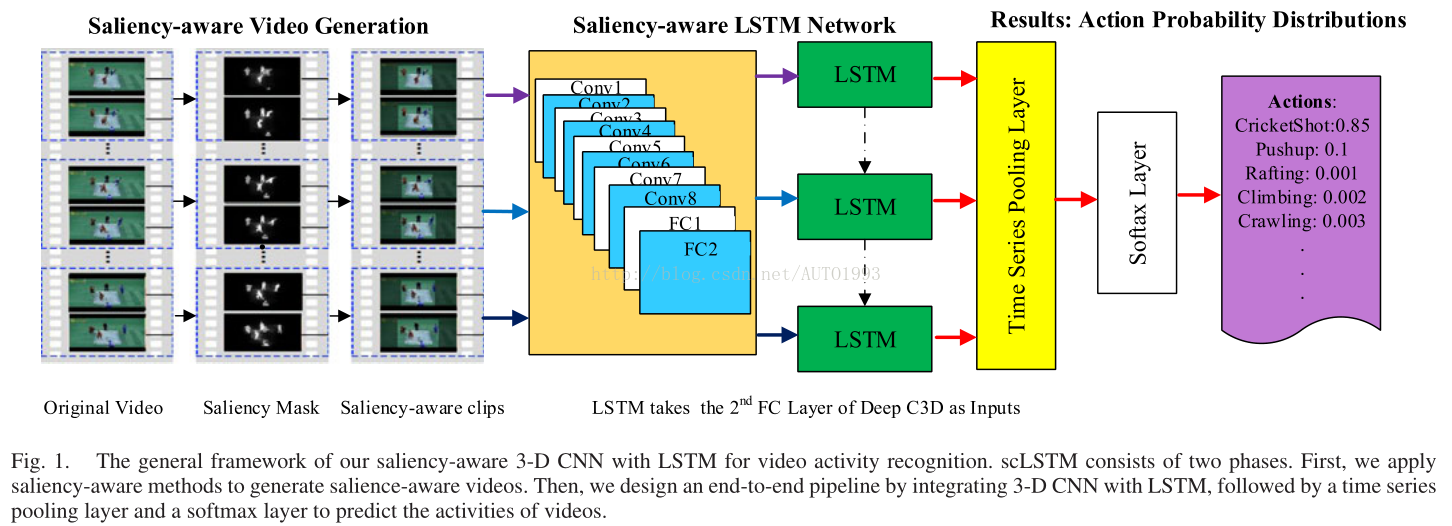
框架主要有俩部分:
(1)saliency-aware videogeneration:这部分主要是使用视频运动目标显著性分割的方法来生成一个saliency-aware map M,每一帧都对应一个M,然后对每一帧的M进行二值化(二值分割,阈值选取M的均值),就可以得到相应的每帧的saliency mask,如上图示。文章使用的视频运动目标显著性方法的源码链接:
https://github.com/shenjianbing/SaliencySeg
(2)C3D+LSTM:C3D用于对每个video clips进行编码,提取时空特征,对于包含多个video clips的单个视频,使用LSTM提取多个video clips之间的temporal 关系。在文章中每个video clips使用的是16帧,每个视频的video clips数量是10,LSTM使用的是seq-to-seq模型,意味着输出也是一个序列,所以后面接了一个time series pooling 层。
最后我跑了一下文章使用的视频目标显著检测方法的源码,显著性计算依然使用的是光流,速度巨慢,计算一帧光流需要2-3s,不过的得到运动显著性效果还是不错,如下图示:
原图:

显著性检测:
















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









