






一、引言
逻辑回归(Logistic Regression)是一种广泛应用的统计学和机器学习算法,主要用于解决二分类问题,即预测一个离散的目标变量,通常取值为0或1,例如判断一封邮件是否为垃圾邮件。尽管名字中含有“回归”,但实际上它是一种分类算法,而不是线性回归。
二、逻辑回归原理
核心思想:
逻辑回归的核心思想是将线性回归的结果通过一个非线性的sigmoid函数(逻辑函数)转换,以得到0到1之间的概率值。这个概率值可以解释为属于某一类的概率。形式上,逻辑回归的预测函数是:
[ P(Y=1|X) = \frac{1}{1 + e^{-\beta_0 - \beta_1X_1 - \ldots - \beta_pX_p}} ]
其中,( Y ) 是二元因变量,( X_1, X_2, ..., X_p ) 是特征变量,( \beta_0, \beta_1, ..., \beta_p ) 是模型参数,( e ) 是自然对数的底数。
模型的训练通常通过最大似然估计法来求解最佳参数 ( \beta )。在分类时,通常设定一个阈值(如0.5),当预测概率大于阈值时,预测结果为1,否则为0。
基本原理:
逻辑回归(Logistic Regression)是一种统计和机器学习中的监督学习方法,主要用于解决二分类问题。以下是其基本原理:
1.模型假设:
逻辑回归假设因变量(目标变量)Y是基于一个线性组合的特征X的伯努利分布的对数几率(log-odds)。
对数几率是概率P(Y=1)与概率P(Y=0)的比值的对数:[ \log\left(\frac{P(Y=1|X)}{P(Y=0|X)}\right) ]
2.Sigmoid函数:
为了将线性模型转换为0到1之间的概率,逻辑回归使用了sigmoid函数(也称为 logistic 函数): [ f(z) = \frac{1}{1 + e^{-z}} ]
其中,( z ) 是线性组合 ( \beta_0 + \beta_1X_1 + \beta_2X_2 + ... + \beta_pX_p ),( \beta ) 是模型参数,( X ) 是特征向量。
3 模型预测:
通过sigmoid函数,我们可以将线性得分 ( z ) 转换为概率值 ( P ): [ P(Y=1|X) = f(z) = \frac{1}{1 + e^{-\beta_0 - \sum_{i=1}^{p}\beta_iX_i}} ]
优缺点分析:
优点:简单、快速、易于解释、适用于大型数据集。
缺点:对非线性关系处理能力有限,容易受到异常值影响,且在特征之间存在高度相关性(多重共线性)时可能不稳定。
三、代码分析
1.导包
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
import numpy as np
import warnings2.忽略警告
warnings.filterwarnings('ignore')3.数据文件读取
# 读取data.xlsx文件
def DataSet():
data = pd.read_excel('data.xlsx')
return data
# 将data.xlsx文件转化为矩阵
def ChangeData1(data):
data = np.array(data)
for i in range(data.shape[0]):
if data[i][1] == '乌黑':
data[i][1] = 0
elif data[i][1] == '青绿':
data[i][1] = 1
elif data[i][1] == '浅白':
data[i][1] = 2
if data[i][2] == '蜷缩':
data[i][2] = 0
elif data[i][2] == '稍蜷':
data[i][2] = 1
elif data[i][2] == '硬挺':
data[i][2] = 2
if data[i][3] == '沉闷':
data[i][3] = 0
elif data[i][3] == '浊响':
data[i][3] = 1
elif data[i][3] == '清脆':
data[i][3] = 2
if data[i][4] == '模糊':
data[i][4] = 0
elif data[i][4] == '稍糊':
data[i][4] = 1
elif data[i][4] == '清晰':
data[i][4] = 2
if data[i][5] == '凹陷':
data[i][5] = 0
elif data[i][5] == '稍凹':
data[i][5] = 1
elif data[i][5] == '平坦':
data[i][5] = 2
if data[i][6] == '软粘':
data[i][6] = 0
elif data[i][6] == '硬滑':
data[i][6] = 1
if data[i][7] == '否':
data[i][7] = 0
elif data[i][7] == '是':
data[i][7] = 1
return data
dataset = DataSet()
data2 = ChangeData1(dataset)
4.转化数据集
x = pd.DataFrame(data2[:, 1:7], columns=[1, 2, 3, 4, 5, 6]) # 第一个切片表示数据行数,第二个切片表示数据列数,columns表示列名
print(x) # 查看表格x的数据
target = data2.astype(int) # 将数据转化为整型
y = pd.DataFrame(target[:, 7:8], columns=['target'])
print(y) # 查看表格y的数据

5.划分数据集
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1)
print(x_train)
print(y_train)

6.创建逻辑回归模型,预测,打印分类报告
# 创建逻辑回归模型
model = LogisticRegression()
# 训练模型
model.fit(x_train, y_train)
# 预测
y_pred = model.predict(x_test)
# 打印分类报告
print(classification_report(y_test, y_pred))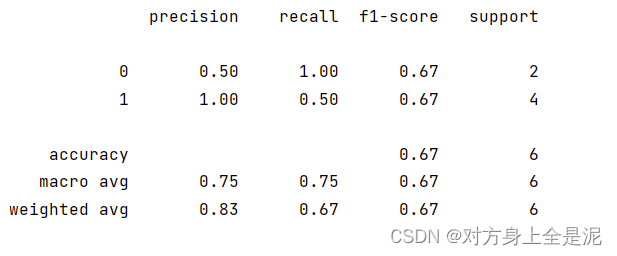
7.全部代码
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
import numpy as np
import warnings
# 忽略警告
warnings.filterwarnings('ignore')
# 读取data.xlsx文件
def DataSet():
data = pd.read_excel('data.xlsx')
return data
# 将data.xlsx文件转化为矩阵
def ChangeData1(data):
data = np.array(data)
for i in range(data.shape[0]):
if data[i][1] == '乌黑':
data[i][1] = 0
elif data[i][1] == '青绿':
data[i][1] = 1
elif data[i][1] == '浅白':
data[i][1] = 2
if data[i][2] == '蜷缩':
data[i][2] = 0
elif data[i][2] == '稍蜷':
data[i][2] = 1
elif data[i][2] == '硬挺':
data[i][2] = 2
if data[i][3] == '沉闷':
data[i][3] = 0
elif data[i][3] == '浊响':
data[i][3] = 1
elif data[i][3] == '清脆':
data[i][3] = 2
if data[i][4] == '模糊':
data[i][4] = 0
elif data[i][4] == '稍糊':
data[i][4] = 1
elif data[i][4] == '清晰':
data[i][4] = 2
if data[i][5] == '凹陷':
data[i][5] = 0
elif data[i][5] == '稍凹':
data[i][5] = 1
elif data[i][5] == '平坦':
data[i][5] = 2
if data[i][6] == '软粘':
data[i][6] = 0
elif data[i][6] == '硬滑':
data[i][6] = 1
if data[i][7] == '否':
data[i][7] = 0
elif data[i][7] == '是':
data[i][7] = 1
return data
dataset = DataSet()
data2 = ChangeData1(dataset)
x = pd.DataFrame(data2[:, 1:7], columns=[1, 2, 3, 4, 5, 6]) # 第一个切片表示数据行数,第二个切片表示数据列数,columns表示列名
print(x) # 查看表格x的数据
target = data2.astype(int) # 将数据转化为整型
y = pd.DataFrame(target[:, 7:8], columns=['target'])
print(y) # 查看表格y的数据
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1)
print(x_train)
print(y_train)
# 创建逻辑回归模型
model = LogisticRegression()
# 训练模型
model.fit(x_train, y_train)
# 预测
y_pred = model.predict(x_test)
# 打印分类报告
print(classification_report(y_test, y_pred))
四、总结
逻辑回归在此场景中的意义在于,它能够分析和理解特征与目标变量之间的关系,从而建立一个预测模型,用于根据输入特征预测目标变量的类别。在这个例子中,模型可能用于预测某种条件下的结果,例如疾病诊断、市场趋势预测等。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









