






一、引言
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的统计分类算法。它的主要思想是,通过历史数据,对每个类别建立经验概率公式,然后当新样本进来时,用各个类别的概率经验公式分别进行预测,最终,属于哪个类别的概率最大,就认为是哪个类别。核心思想是利用贝叶斯定理来计算给定一个观测数据时某个类别出现的概率。
二、朴素贝叶斯算法原理
朴素贝叶斯(Naive Bayes)的原理基于概率论中的贝叶斯定理,用于分类任务。以下是朴素贝叶斯分类的基本原理和步骤:
(1)贝叶斯定理:
贝叶斯定理描述了在给定一些证据(或特征)的情况下,某一假设(或类别)的概率如何更新。贝叶斯定理可以表示为:
[ P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} ]
其中:
( P(A|B) ) 是后验概率,即在已知 B 发生的情况下 A 发生的概率。
( P(B|A) ) 是似然概率,即在已知 A 发生的情况下 B 发生的概率。
( P(A) ) 是先验概率,即在没有考虑任何其他信息时 A 发生的概率。
( P(B) ) 是证据概率或归一化常数,确保后验概率的总和为1。
(2)特征独立性假设:
朴素贝叶斯的关键假设是所有特征在给定类别下都是条件独立的。这意味着特征 ( x_i ) 的出现不受其他特征 ( x_j ) 的影响。这简化了计算,因为可以将联合概率分解为单个特征的条件概率的乘积: [ P(x_1, x_2, ..., x_n | C_k) = P(x_1 | C_k) \cdot P(x_2 | C_k) \cdot ... \cdot P(x_n | C_k) ]
分类决策:
根据所有类别的后验概率,朴素贝叶斯分类器选择具有最高后验概率的类别作为预测结果: [ \hat{C} = \arg\max_{C_k} P(C_k | x_1, x_2, ..., x_n) ]
(3)参数估计:
在训练阶段,需要估计先验概率 ( P(C_k) ) 和条件概率 ( P(x_i | C_k) )。这些可以通过极大似然估计或贝叶斯估计方法得到,例如计数频率或考虑平滑技术来处理未见过的特征值。
实际应用中的处理:
(4)拉普拉斯平滑:
为了避免在计算条件概率时遇到0概率(特别是对于未在训练集中出现的特征值),通常会使用拉普拉斯平滑或者 Lidstone 平滑。
多项式模型:在文本分类中,通常使用多项式模型,其中特征是词频,而类别是文档的类别。
三、代码实现
(1)数据准备
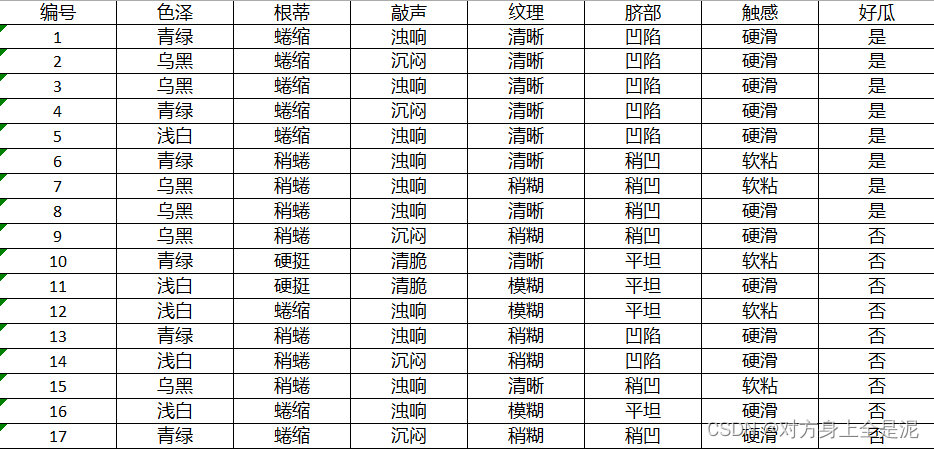
(2)读取data.xlsx文件,将data.xlsx文件转化为矩阵
import pandas as pd
import numpy as np
# 读取data.xlsx文件
def DataSet():
data = pd.read_excel('data.xlsx')
return data
# 将data.xlsx文件转化为矩阵
def ChangeData1(data):
data = np.array(data)
for i in range(data.shape[0]):
if data[i][1] == '乌黑':
data[i][1] = 0
elif data[i][1] == '青绿':
data[i][1] = 1
elif data[i][1] == '浅白':
data[i][1] = 2
if data[i][2] == '蜷缩':
data[i][2] = 0
elif data[i][2] == '稍蜷':
data[i][2] = 1
elif data[i][2] == '硬挺':
data[i][2] = 2
if data[i][3] == '沉闷':
data[i][3] = 0
elif data[i][3] == '浊响':
data[i][3] = 1
elif data[i][3] == '清脆':
data[i][3] = 2
if data[i][4] == '模糊':
data[i][4] = 0
elif data[i][4] == '稍糊':
data[i][4] = 1
elif data[i][4] == '清晰':
data[i][4] = 2
if data[i][5] == '凹陷':
data[i][5] = 0
elif data[i][5] == '稍凹':
data[i][5] = 1
elif data[i][5] == '平坦':
data[i][5] = 2
if data[i][6] == '软粘':
data[i][6] = 0
elif data[i][6] == '硬滑':
data[i][6] = 1
if data[i][7] == '否':
data[i][7] = 0
elif data[i][7] == '是':
data[i][7] = 1
return data

(3)划分训练集和测试集,划分好瓜数据和坏瓜数据
# 划分训练集和测试集
def SplitData(data, k):
train_data = []
test_data = []
for i in range(len(data)):
if i % k == 0:
test_data.append(data[i].tolist())
else:
train_data.append(data[i].tolist())
return train_data, test_data
# 划分好瓜数据和坏瓜数据
def Good_Bad_Split(data):
bad_melon = []
good_melon = []
for i in range(len(data)):
if data[i][7] == 0:
bad_melon.append(data[i])
else:
good_melon.append(data[i])
return bad_melon, good_melon
(4)统计各属性的个数
# 统计各属性的个数
def Analysis(data):
result = []
色泽1 = []
根蒂2 = []
敲声3 = []
纹理4 = []
脐部5 = []
触感6 = []
好坏7 = []
# 统计乌黑的个数
num = 0
for i in range(len(data)):
if data[i][1] == 0:
num += 1
色泽1.append(num)
# 统计青绿的个数
num = 0
for i in range(len(data)):
if data[i][1] == 1:
num += 1
色泽1.append(num)
# 统计浅白的个数
num = 0
for i in range(len(data)):
if data[i][1] == 2:
num += 1
色泽1.append(num)
# 统计蜷缩的个数
num = 0
for i in range(len(data)):
if data[i][2] == 0:
num += 1
根蒂2.append(num)
# 统计稍蜷的个数
num = 0
for i in range(len(data)):
if data[i][2] == 1:
num += 1
根蒂2.append(num)
# 统计硬挺的个数
num = 0
for i in range(len(data)):
if data[i][2] == 2:
num += 1
根蒂2.append(num)
# 统计沉闷的个数
num = 0
for i in range(len(data)):
if data[i][3] == 0:
num += 1
敲声3.append(num)
# 统计浊响的个数
num = 0
for i in range(len(data)):
if data[i][3] == 1:
num += 1
敲声3.append(num)
# 统计清脆的个数
num = 0
for i in range(len(data)):
if data[i][3] == 2:
num += 1
敲声3.append(num)
# 统计模糊的个数
num = 0
for i in range(len(data)):
if data[i][4] == 0:
num += 1
纹理4.append(num)
# 统计稍糊的个数
num = 0
for i in range(len(data)):
if data[i][4] == 1:
num += 1
纹理4.append(num)
# 统计清晰的个数
num = 0
for i in range(len(data)):
if data[i][4] == 2:
num += 1
纹理4.append(num)
# 统计凹陷的个数
num = 0
for i in range(len(data)):
if data[i][5] == 0:
num += 1
脐部5.append(num)
# 统计稍凹的个数
num = 0
for i in range(len(data)):
if data[i][5] == 1:
num += 1
脐部5.append(num)
# 统计平坦的个数
num = 0
for i in range(len(data)):
if data[i][5] == 2:
num += 1
脐部5.append(num)
# 统计软粘的个数
num = 0
for i in range(len(data)):
if data[i][6] == 0:
num += 1
触感6.append(num)
# 统计硬滑的个数
num = 0
for i in range(len(data)):
if data[i][6] == 1:
num += 1
触感6.append(num)
# 统计否的个数
num = 0
for i in range(len(data)):
if data[i][7] == 0:
num += 1
好坏7.append(num)
# 统计是的个数
num = 0
for i in range(len(data)):
if data[i][7] == 1:
num += 1
好坏7.append(num)
# 将特征添加到result中
result.append(色泽1)
result.append(根蒂2)
result.append(敲声3)
result.append(纹理4)
result.append(脐部5)
result.append(触感6)
result.append(好坏7)
return result优化版
def Analysis2(data):
result = []
色泽1 = []
根蒂2 = []
敲声3 = []
纹理4 = []
脐部5 = []
触感6 = []
好坏7 = []
# 统计乌黑的个数
num = 1
for i in range(len(data)):
if data[i][1] == 0:
num += 1
色泽1.append(num)
# 统计青绿的个数
num = 1
for i in range(len(data)):
if data[i][1] == 1:
num += 1
色泽1.append(num)
# 统计浅白的个数
num = 1
for i in range(len(data)):
if data[i][1] == 2:
num += 1
色泽1.append(num)
# 统计蜷缩的个数
num = 1
for i in range(len(data)):
if data[i][2] == 0:
num += 1
根蒂2.append(num)
# 统计稍蜷的个数
num = 1
for i in range(len(data)):
if data[i][2] == 1:
num += 1
根蒂2.append(num)
# 统计硬挺的个数
num = 1
for i in range(len(data)):
if data[i][2] == 2:
num += 1
根蒂2.append(num)
# 统计沉闷的个数
num = 1
for i in range(len(data)):
if data[i][3] == 0:
num += 1
敲声3.append(num)
# 统计浊响的个数
num = 1
for i in range(len(data)):
if data[i][3] == 1:
num += 1
敲声3.append(num)
# 统计清脆的个数
num = 1
for i in range(len(data)):
if data[i][3] == 2:
num += 1
敲声3.append(num)
# 统计模糊的个数
num = 1
for i in range(len(data)):
if data[i][4] == 0:
num += 1
纹理4.append(num)
# 统计稍糊的个数
num = 1
for i in range(len(data)):
if data[i][4] == 1:
num += 1
纹理4.append(num)
# 统计清晰的个数
num = 1
for i in range(len(data)):
if data[i][4] == 2:
num += 1
纹理4.append(num)
# 统计凹陷的个数
num = 1
for i in range(len(data)):
if data[i][5] == 0:
num += 1
脐部5.append(num)
# 统计稍凹的个数
num = 1
for i in range(len(data)):
if data[i][5] == 1:
num += 1
脐部5.append(num)
# 统计平坦的个数
num = 1
for i in range(len(data)):
if data[i][5] == 2:
num += 1
脐部5.append(num)
# 统计软粘的个数
num = 1
for i in range(len(data)):
if data[i][6] == 0:
num += 1
触感6.append(num)
# 统计硬滑的个数
num = 1
for i in range(len(data)):
if data[i][6] == 1:
num += 1
触感6.append(num)
# 统计否的个数
num = 1
for i in range(len(data)):
if data[i][7] == 0:
num += 1
好坏7.append(num)
# 统计是的个数
num = 1
for i in range(len(data)):
if data[i][7] == 1:
num += 1
好坏7.append(num)
# 将特征添加到result中
result.append(色泽1)
result.append(根蒂2)
result.append(敲声3)
result.append(纹理4)
result.append(脐部5)
result.append(触感6)
result.append(好坏7)
return result
(5)计算坏好瓜及其各属性概率
# 计算坏瓜概率
def Calculate_bad_probability(data):
result = (data[6][0] / (data[6][0] + data[6][1]))
return result
# 计算好瓜概率
def Calculate_good_probability(data):
result = (data[6][1] / (data[6][1] + data[6][0]))
return result
# 计算坏瓜各属性的概率
def Calculate_bad(data):
for i in range(len(data) - 1):
for j in range(len(data[i])):
data[i][j] = data[i][j] / data[6][0]
return data
# 计算好瓜各属性的概率
def Calculate_good(data):
for i in range(len(data) - 1):
for j in range(len(data[i])):
data[i][j] = data[i][j] / data[6][1]
return data

(6)判断坏好瓜
# 判断坏瓜好瓜
def Judge(Bad, Good, PBad, PGood, test_data):
JBad = 1
JGood = 1
for i in range(0, 6):
JBad = JBad * PBad[i][test_data[i + 1]]
JGood = JGood * PGood[i][test_data[i + 1]]
JBad = JBad * Bad
JGood = JGood * Good
if JBad > JGood:
return 0
else:
return 1(7)统计正确率
# 统计正确率
def Accuracy(Bad, Good, PBad, PGood, test_data):
judge = 0
for i in range(len(test_data)):
judge = Judge(Bad, Good, PBad, PGood, train_data[i])
if judge == test_data[i][6]:
judge += 1
P_right=judge / len(test_data)
return P_right(8)全部代码
import pandas as pd
import numpy as np
# 读取data.xlsx文件
def DataSet():
data = pd.read_excel('data.xlsx')
return data
# 将data.xlsx文件转化为矩阵
def ChangeData1(data):
data = np.array(data)
for i in range(data.shape[0]):
if data[i][1] == '乌黑':
data[i][1] = 0
elif data[i][1] == '青绿':
data[i][1] = 1
elif data[i][1] == '浅白':
data[i][1] = 2
if data[i][2] == '蜷缩':
data[i][2] = 0
elif data[i][2] == '稍蜷':
data[i][2] = 1
elif data[i][2] == '硬挺':
data[i][2] = 2
if data[i][3] == '沉闷':
data[i][3] = 0
elif data[i][3] == '浊响':
data[i][3] = 1
elif data[i][3] == '清脆':
data[i][3] = 2
if data[i][4] == '模糊':
data[i][4] = 0
elif data[i][4] == '稍糊':
data[i][4] = 1
elif data[i][4] == '清晰':
data[i][4] = 2
if data[i][5] == '凹陷':
data[i][5] = 0
elif data[i][5] == '稍凹':
data[i][5] = 1
elif data[i][5] == '平坦':
data[i][5] = 2
if data[i][6] == '软粘':
data[i][6] = 0
elif data[i][6] == '硬滑':
data[i][6] = 1
if data[i][7] == '否':
data[i][7] = 0
elif data[i][7] == '是':
data[i][7] = 1
return data
# 划分训练集和测试集
def SplitData(data, k):
train_data = []
test_data = []
for i in range(len(data)):
if i % k == 0:
test_data.append(data[i].tolist())
else:
train_data.append(data[i].tolist())
return train_data, test_data
# 划分好瓜数据和坏瓜数据
def Good_Bad_Split(data):
bad_melon = []
good_melon = []
for i in range(len(data)):
if data[i][7] == 0:
bad_melon.append(data[i])
else:
good_melon.append(data[i])
return bad_melon, good_melon
# 统计各属性的个数
def Analysis(data):
result = []
色泽1 = []
根蒂2 = []
敲声3 = []
纹理4 = []
脐部5 = []
触感6 = []
好坏7 = []
# 统计乌黑的个数
num = 0
for i in range(len(data)):
if data[i][1] == 0:
num += 1
色泽1.append(num)
# 统计青绿的个数
num = 0
for i in range(len(data)):
if data[i][1] == 1:
num += 1
色泽1.append(num)
# 统计浅白的个数
num = 0
for i in range(len(data)):
if data[i][1] == 2:
num += 1
色泽1.append(num)
# 统计蜷缩的个数
num = 0
for i in range(len(data)):
if data[i][2] == 0:
num += 1
根蒂2.append(num)
# 统计稍蜷的个数
num = 0
for i in range(len(data)):
if data[i][2] == 1:
num += 1
根蒂2.append(num)
# 统计硬挺的个数
num = 0
for i in range(len(data)):
if data[i][2] == 2:
num += 1
根蒂2.append(num)
# 统计沉闷的个数
num = 0
for i in range(len(data)):
if data[i][3] == 0:
num += 1
敲声3.append(num)
# 统计浊响的个数
num = 0
for i in range(len(data)):
if data[i][3] == 1:
num += 1
敲声3.append(num)
# 统计清脆的个数
num = 0
for i in range(len(data)):
if data[i][3] == 2:
num += 1
敲声3.append(num)
# 统计模糊的个数
num = 0
for i in range(len(data)):
if data[i][4] == 0:
num += 1
纹理4.append(num)
# 统计稍糊的个数
num = 0
for i in range(len(data)):
if data[i][4] == 1:
num += 1
纹理4.append(num)
# 统计清晰的个数
num = 0
for i in range(len(data)):
if data[i][4] == 2:
num += 1
纹理4.append(num)
# 统计凹陷的个数
num = 0
for i in range(len(data)):
if data[i][5] == 0:
num += 1
脐部5.append(num)
# 统计稍凹的个数
num = 0
for i in range(len(data)):
if data[i][5] == 1:
num += 1
脐部5.append(num)
# 统计平坦的个数
num = 0
for i in range(len(data)):
if data[i][5] == 2:
num += 1
脐部5.append(num)
# 统计软粘的个数
num = 0
for i in range(len(data)):
if data[i][6] == 0:
num += 1
触感6.append(num)
# 统计硬滑的个数
num = 0
for i in range(len(data)):
if data[i][6] == 1:
num += 1
触感6.append(num)
# 统计否的个数
num = 0
for i in range(len(data)):
if data[i][7] == 0:
num += 1
好坏7.append(num)
# 统计是的个数
num = 0
for i in range(len(data)):
if data[i][7] == 1:
num += 1
好坏7.append(num)
# 将特征添加到result中
result.append(色泽1)
result.append(根蒂2)
result.append(敲声3)
result.append(纹理4)
result.append(脐部5)
result.append(触感6)
result.append(好坏7)
return result
# 统计各属性的个数(优化)
def Analysis2(data):
result = []
色泽1 = []
根蒂2 = []
敲声3 = []
纹理4 = []
脐部5 = []
触感6 = []
好坏7 = []
# 统计乌黑的个数
num = 1
for i in range(len(data)):
if data[i][1] == 0:
num += 1
色泽1.append(num)
# 统计青绿的个数
num = 1
for i in range(len(data)):
if data[i][1] == 1:
num += 1
色泽1.append(num)
# 统计浅白的个数
num = 1
for i in range(len(data)):
if data[i][1] == 2:
num += 1
色泽1.append(num)
# 统计蜷缩的个数
num = 1
for i in range(len(data)):
if data[i][2] == 0:
num += 1
根蒂2.append(num)
# 统计稍蜷的个数
num = 1
for i in range(len(data)):
if data[i][2] == 1:
num += 1
根蒂2.append(num)
# 统计硬挺的个数
num = 1
for i in range(len(data)):
if data[i][2] == 2:
num += 1
根蒂2.append(num)
# 统计沉闷的个数
num = 1
for i in range(len(data)):
if data[i][3] == 0:
num += 1
敲声3.append(num)
# 统计浊响的个数
num = 1
for i in range(len(data)):
if data[i][3] == 1:
num += 1
敲声3.append(num)
# 统计清脆的个数
num = 1
for i in range(len(data)):
if data[i][3] == 2:
num += 1
敲声3.append(num)
# 统计模糊的个数
num = 1
for i in range(len(data)):
if data[i][4] == 0:
num += 1
纹理4.append(num)
# 统计稍糊的个数
num = 1
for i in range(len(data)):
if data[i][4] == 1:
num += 1
纹理4.append(num)
# 统计清晰的个数
num = 1
for i in range(len(data)):
if data[i][4] == 2:
num += 1
纹理4.append(num)
# 统计凹陷的个数
num = 1
for i in range(len(data)):
if data[i][5] == 0:
num += 1
脐部5.append(num)
# 统计稍凹的个数
num = 1
for i in range(len(data)):
if data[i][5] == 1:
num += 1
脐部5.append(num)
# 统计平坦的个数
num = 1
for i in range(len(data)):
if data[i][5] == 2:
num += 1
脐部5.append(num)
# 统计软粘的个数
num = 1
for i in range(len(data)):
if data[i][6] == 0:
num += 1
触感6.append(num)
# 统计硬滑的个数
num = 1
for i in range(len(data)):
if data[i][6] == 1:
num += 1
触感6.append(num)
# 统计否的个数
num = 1
for i in range(len(data)):
if data[i][7] == 0:
num += 1
好坏7.append(num)
# 统计是的个数
num = 1
for i in range(len(data)):
if data[i][7] == 1:
num += 1
好坏7.append(num)
# 将特征添加到result中
result.append(色泽1)
result.append(根蒂2)
result.append(敲声3)
result.append(纹理4)
result.append(脐部5)
result.append(触感6)
result.append(好坏7)
return result
# 计算坏瓜概率
def Calculate_bad_probability(data):
result = (data[6][0] / (data[6][0] + data[6][1]))
return result
# 计算好瓜概率
def Calculate_good_probability(data):
result = (data[6][1] / (data[6][1] + data[6][0]))
return result
# 计算坏瓜各属性的概率
def Calculate_bad(data):
for i in range(len(data) - 1):
for j in range(len(data[i])):
data[i][j] = data[i][j] / data[6][0]
return data
# 计算好瓜各属性的概率
def Calculate_good(data):
for i in range(len(data) - 1):
for j in range(len(data[i])):
data[i][j] = data[i][j] / data[6][1]
return data
# 判断坏瓜好瓜
def Judge(Bad, Good, PBad, PGood, test_data):
JBad = 1
JGood = 1
for i in range(0, 6):
JBad = JBad * PBad[i][test_data[i + 1]]
JGood = JGood * PGood[i][test_data[i + 1]]
JBad = JBad * Bad
JGood = JGood * Good
if JBad > JGood:
return 0
else:
return 1
# 统计正确率
def Accuracy(Bad, Good, PBad, PGood, test_data):
judge = 0
for i in range(len(test_data)):
judge = Judge(Bad, Good, PBad, PGood, train_data[i])
if judge == test_data[i][6]:
judge += 1
P_right=judge / len(test_data)
return P_right
data = DataSet().values # 读取表格数据
data2 = ChangeData1(data) # 将数据集转化为数字形式
train_data, test_data = SplitData(data2, 10) # 将数据集分为训练集和测试集
train_data_bad, train_data_good = Good_Bad_Split(train_data)
train_data_analysis = Analysis(train_data) # 统计所有瓜各属性的个数
train_data_bad_analysis = Analysis(train_data_bad) # 统计坏瓜各属性的个数
train_data_good_analysis = Analysis(train_data_good) # 统计好瓜各属性的个数
train_data_analysis2 = Analysis2(train_data) # 统计所有瓜各属性的个数(优化)
train_data_bad_analysis2 = Analysis2(train_data_bad) # 统计坏瓜各属性的个数(优化)
train_data_good_analysis2 = Analysis2(train_data_good) # 统计好瓜各属性的个数(优化)
Bad = Calculate_bad_probability(train_data_analysis)
Good = Calculate_good_probability(train_data_analysis)
PBad = Calculate_bad(train_data_bad_analysis)
PGood = Calculate_good(train_data_good_analysis)
judge = Judge(Bad, Good, PBad, PGood, train_data[8])
P_right = Accuracy(Bad, Good, PBad, PGood, test_data)
# print(data)
# print(data2)
print(train_data)
print(test_data)
print(train_data_bad)
print(train_data_good)
# print(train_data_analysis)
# print(train_data_bad_analysis)
# print(train_data_good_analysis)
# print(train_data_analysis2)
# print(train_data_bad_analysis2)
# print(train_data_good_analysis2)
print(Bad)
print(Good)
print(PBad)
print(PGood)
# print(train_data_analysis[1][1])
# print(len(test_data[0]))
# print(judge)
print(P_right)四、分析与总结
朴素贝叶斯分类器有以下优点和缺点:
优点:
数学基础稳固:朴素贝叶斯算法基于概率论中的贝叶斯定理,有坚实的数学理论基础。
计算高效:由于假设特征之间相互独立,计算每个特征对类别影响的乘积比计算复杂的联合概率要简单得多,这使得朴素贝叶斯在大数据集上运行速度快。
模型简单:朴素贝叶斯模型结构简单,易于理解和实现。
缺点:
朴素假设:它假定特征之间是独立的,这个假设在许多真实世界的数据集中往往不成立,导致模型的准确性受到影响。
表达能力有限:朴素贝叶斯模型无法捕捉复杂的非线性关系,限制了其在复杂模式识别上的能力。
对异常值敏感:异常值可能对模型的先验概率和条件概率估计造成显著影响,降低分类效果。
总结:尽管朴素贝叶斯有一些局限性,但在某些特定的应用场景,如文本分类和垃圾邮件过滤,它仍然表现得相当有效。















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









