






一、决策树的工作原理:
决策树是一种监督学习算法,主要用于分类问题,也可以用于回归问题。它通过学习数据的特征来构建一个树状模型,这个模型能够用来做预测。以下是决策树工作原理的简单步骤:
1.数据准备:首先,需要准备带有标签(类别)的数据集,数据集中的每个样本都有一个或多个特征和一个目标变量。
2.选择特征:算法选择一个特征作为分割点,这个特征应能最大程度地减少数据的不纯度或增加信息增益。常用的评估标准有信息熵、基尼不纯度等。
3.创建节点:基于选定的特征,数据被分成不同的子集,每个子集对应一个内部节点(决策节点)。
4.分裂过程:这个过程会递归地对每个子集重复以上步骤,直到满足停止条件。
停止条件可能包括:
所有样本属于同一类别
样本数量低于某个阈值
没有更多特征可选
达到预设的最大树深度
5.创建叶子节点:当停止条件满足时,创建叶子节点,分配最常见的类别(对于分类问题)或平均值(对于回归问题)。
6.(更进一步优化)剪枝:为了防止过拟合,决策树可能会进行剪枝,即删除一些非必要的分支,以提高泛化能力。
7.预测:新样本沿着树从根节点到叶节点路径上的决策规则进行分类或回归。
二、决策树的应用场景:
1.分类问题:
分类问题:
医学诊断:通过病人的医疗历史、症状和检查结果,预测疾病类型。
信贷评估:银行和金融机构使用决策树来评估贷款申请人的信用风险。
邮件过滤:识别垃圾邮件和非垃圾邮件。
市场细分:确定消费者群体并制定营销策略。
2.风险管理:
金融风控:分析客户的信用评分、收入、债务等信息,决定是否批准贷款。
保险业:评估保险索赔的风险等级。
3.客户关系管理:
客户流失分析:预测客户可能取消订阅或停止购买产品。
客户满意度:理解影响客户满意度的因素。
三、决策树构建:
ID3:信息增益:
熵(Entropy):事物的不确定性,越不确定,熵越大。一个随机变量X的熵的计算如下:
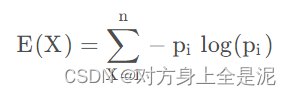
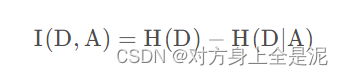
随机变量均匀分布时,熵达到最大。即均匀分布的不确定性最强。而n类平均分布的熵会小于n+1类平均分布的熵。信息增益越大,说明变量带来的信息越多,即越有用。
C4.5: 信息增益率:
特征熵:特征熵可以用来衡量样本在使用某特征划分后的分布的不确定性。取值数目越多,分割后各取值得到的样本分布得越均匀,则特征熵越大。可以用它作为分母,来惩罚取值多的特征,以纠正ID3的偏好。
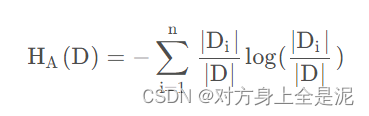

信息增益率越大,说明变量带来的信息越多,即越有用。
CART:基尼指数:
Gini指数:衡量一个分割的纯净度。Gini指数越小,说明此分割越纯净,此分割中的绝大部分样本属于同一类。随机抽取两个样本,其类别不一致的概率, 类似于 p(1-p)。
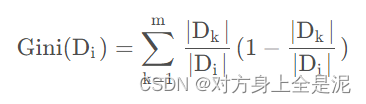
基尼指数越小,说明变量带来的信息越多,即越有用。
四、代码分析:
使用基尼指数构建决策树,但是未成功
思路分析:
1.读取表格数据
2.转化表格数据为矩阵,方便后续计算
3.统计各特征下不同属性的个数
4.计算基尼指数,取最小的特征作为划分依据(只实现到这一步)
5.将划分后的数据存入多叉树,在重复执行3,4两步,直到决策树划分满足停止条件
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取data.xlsx文件
def DataSet():
data = pd.read_excel('data.xlsx')
return data
# 将data.xlsx文件转化为矩阵
def ChangeData1(data):
for i in range(data.shape[0]):
if data[i][1] == '乌黑':
data[i][1] = 0
elif data[i][1] == '青绿':
data[i][1] = 1
elif data[i][1] == '浅白':
data[i][1] = 2
if data[i][2] == '蜷缩':
data[i][2] = 0
elif data[i][2] == '稍蜷':
data[i][2] = 1
elif data[i][2] == '硬挺':
data[i][2] = 2
if data[i][3] == '沉闷':
data[i][3] = 0
elif data[i][3] == '浊响':
data[i][3] = 1
elif data[i][3] == '清脆':
data[i][3] = 2
if data[i][4] == '模糊':
data[i][4] = 0
elif data[i][4] == '稍糊':
data[i][4] = 1
elif data[i][4] == '清晰':
data[i][4] = 2
if data[i][5] == '凹陷':
data[i][5] = 0
elif data[i][5] == '稍凹':
data[i][5] = 1
elif data[i][5] == '平坦':
data[i][5] = 2
if data[i][6] == '软粘':
data[i][6] = 0
elif data[i][6] == '硬滑':
data[i][6] = 1
if data[i][7] == '否':
data[i][7] = 0
elif data[i][7] == '是':
data[i][7] = 1
return data
# 统计各属性的个数
def Analysis(data):
result = []
色泽1 = []
根蒂2 = []
敲声3 = []
纹理4 = []
脐部5 = []
触感6 = []
# 统计乌黑的个数
num = 0
for i in range(data.shape[0]):
if data[i][1] == 0:
num += 1
色泽1.append(num)
# 统计青绿的个数
num = 0
for i in range(data.shape[0]):
if data[i][1] == 1:
num += 1
色泽1.append(num)
# 统计浅白的个数
num = 0
for i in range(data.shape[0]):
if data[i][1] == 2:
num += 1
色泽1.append(num)
# 统计蜷缩的个数
num = 0
for i in range(data.shape[0]):
if data[i][2] == 0:
num += 1
根蒂2.append(num)
# 统计稍蜷的个数
num = 0
for i in range(data.shape[0]):
if data[i][2] == 1:
num += 1
根蒂2.append(num)
# 统计硬挺的个数
num = 0
for i in range(data.shape[0]):
if data[i][2] == 2:
num += 1
根蒂2.append(num)
# 统计沉闷的个数
num = 0
for i in range(data.shape[0]):
if data[i][3] == 0:
num += 1
敲声3.append(num)
# 统计浊响的个数
num = 0
for i in range(data.shape[0]):
if data[i][3] == 1:
num += 1
敲声3.append(num)
# 统计清脆的个数
num = 0
for i in range(data.shape[0]):
if data[i][3] == 2:
num += 1
敲声3.append(num)
# 统计模糊的个数
num = 0
for i in range(data.shape[0]):
if data[i][4] == 0:
num += 1
纹理4.append(num)
# 统计稍糊的个数
num = 0
for i in range(data.shape[0]):
if data[i][4] == 1:
num += 1
纹理4.append(num)
# 统计清晰的个数
num = 0
for i in range(data.shape[0]):
if data[i][4] == 2:
num += 1
纹理4.append(num)
# 统计凹陷的个数
num = 0
for i in range(data.shape[0]):
if data[i][5] == 0:
num += 1
脐部5.append(num)
# 统计稍凹的个数
num = 0
for i in range(data.shape[0]):
if data[i][5] == 1:
num += 1
脐部5.append(num)
# 统计平坦的个数
num = 0
for i in range(data.shape[0]):
if data[i][5] == 2:
num += 1
脐部5.append(num)
# 统计软粘的个数
num = 0
for i in range(data.shape[0]):
if data[i][6] == 0:
num += 1
触感6.append(num)
# 统计硬滑的个数
num = 0
for i in range(data.shape[0]):
if data[i][6] == 1:
num += 1
触感6.append(num)
# 将特征添加到result中
result.append(色泽1)
result.append(根蒂2)
result.append(敲声3)
result.append(纹理4)
result.append(脐部5)
result.append(触感6)
return result
# 利用基尼指数划分决策树的第一步: 求出各属性的基尼指数并取最小的下标
def Gini1(data):
result = []
min = 0
色泽1 = 1 - (data[0][0] / (data[0][0] + data[0][1] + data[0][2])) ** 2 - (
data[0][1] / (data[0][0] + data[0][1] + data[0][2])) ** 2 - (
data[0][2] / (data[0][0] + data[0][1] + data[0][2])) ** 2
根蒂2 = 1 - (data[1][0] / (data[1][0] + data[1][1] + data[1][2])) ** 2 - (
data[1][1] / (data[1][0] + data[1][1] + data[1][2])) ** 2 - (
data[1][2] / (data[1][0] + data[1][1] + data[1][2])) ** 2
敲声3 = 1 - (data[2][0] / (data[2][0] + data[2][1] + data[2][2])) ** 2 - (
data[2][1] / (data[2][0] + data[2][1] + data[2][2])) ** 2 - (
data[2][2] / (data[2][0] + data[2][1] + data[2][2])) ** 2
纹理4 = 1 - (data[3][0] / (data[3][0] + data[3][1] + data[3][2])) ** 2 - (
data[3][1] / (data[3][0] + data[3][1] + data[3][2])) ** 2 - (
data[3][2] / (data[3][0] + data[3][1] + data[3][2])) ** 2
脐部5 = 1 - (data[4][0] / (data[4][0] + data[4][1] + data[4][2])) ** 2 - (
data[4][1] / (data[4][0] + data[4][1] + data[4][2])) ** 2 - (
data[4][2] / (data[4][0] + data[4][1] + data[4][2])) ** 2
触感6 = 1 - (data[5][0] / (data[5][0] + data[5][1])) ** 2 - (data[5][1] / (data[5][0] + data[5][1])) ** 2
result.append(色泽1)
result.append(根蒂2)
result.append(敲声3)
result.append(纹理4)
result.append(脐部5)
result.append(触感6)
# 取result中值最小的下标为min
for i in range(len(result)):
if result[i] < result[min] and result[i] != 0:
min = i
print(result)
return min + 1
# 利用基尼指数划分决策树的第二步:利用下标划分数据集
def ChangeData2(data, min):
result = []
result1 = []
result2 = []
result3 = []
if min == 6:
for i in range(data.shape[0]):
if data[i][6] == 0:
result1.append(data[i])
elif data[i][6] == 1:
result2.append(data[i])
result.append(result1)
result.append(result2)
else:
for i in range(data.shape[0]):
if data[i][6] == 0:
result1.append(data[i])
elif data[i][6] == 1:
result2.append(data[i])
elif data[i][6] == 2:
result3.append(data[i])
result.append(result1)
result.append(result2)
result.append(result3)
return result
# 定义一个多叉树
class TreeNode:
def __init__(self, value):
self.value = value
self.data = data
self.children = []
def add_child(self, node):
self.children.append(node)
# 深度优先遍历多叉树
def dfs(node, visit=lambda node: print(node.data)):
visit(node)
for child in node.children:
dfs(child, visit)
data = DataSet().values # 读表
print(data)
data2 = ChangeData1(data) # 转换表格数据为数字
print(data2)
data3 = Analysis(data2) # 统计各属性的个数
print(data3)
data4 = Gini1(data3) # 利用基尼指数划分决策树的第一步:求出各属性的基尼指数并取最小的下标
print(data4)
data5 = ChangeData2(data2, data4) # 利用基尼指数划分决策树的第二步:利用下标划分数据集
print(data5[0])
print(data5[1])
# root = TreeNode(1)
# root.data = data2
# child1 = TreeNode(2)
# child1.data=data5[0]
# child2 = TreeNode(3)
# child2.data=data5[1]
#
# root.add_child(child1)
# root.add_child(child2)
# print("DFS Traversal:")
# dfs(root)
五、总结:
决策树易于理解和解释,但可能会因为选择的特征和树的结构导致过拟合或欠拟合。现代的决策树算法,如ID3、C4.5、CART和随机森林,都包含优化策略来提高性能和稳定性。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









