







目录
8. 计算量(FLOPs,浮点运算数,时间复杂度,对应于GPU算力)
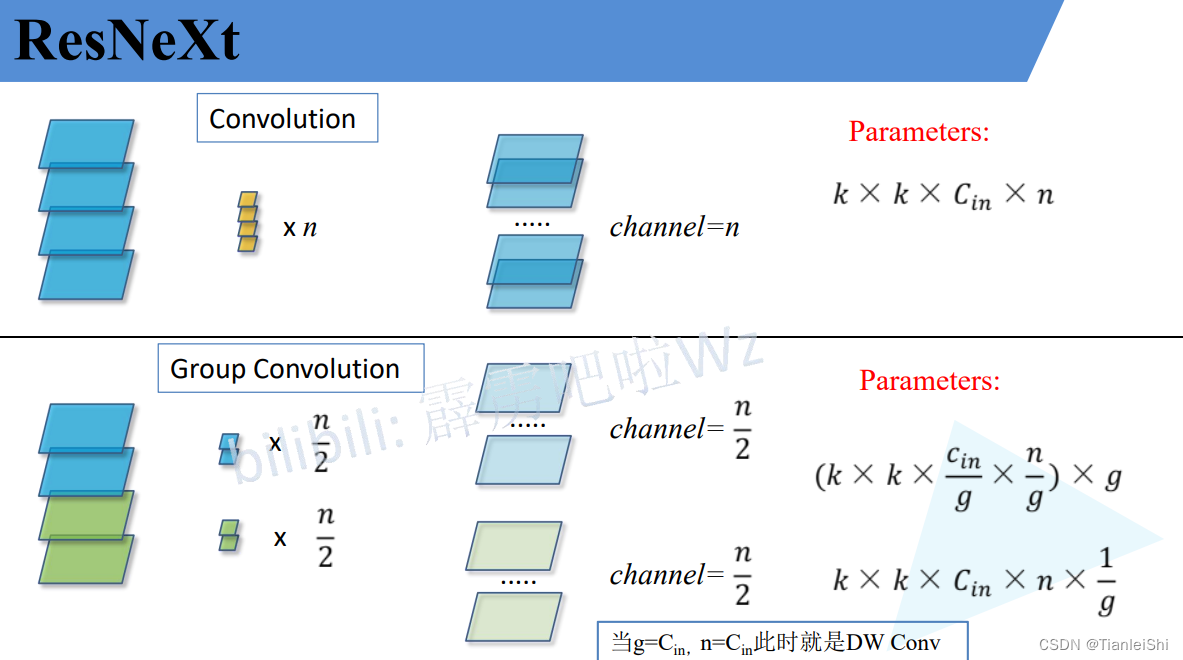
2. 深度卷积(Depthwise Convolution)
5. 转置卷积(Transposed Convolution)
6. 可变形卷积(Deformable Convolution)
背景介绍
💡 CNN优化加速问题
- 模型的存储问题。数百层网络有大量权值参数,保存权值参数对设备的内存要求很高。
- 模型的速度问题。在实际应用中,往往是毫秒级别,为了达到实际应用标准,要么提高处理器性能,要么减少计算量(FLOPs)。
- 自2012年神经网络问世,CNN在图像分类、分割、目标检测等领域获得广泛应用。CNN网络架构设计,又指Backbone设计,主要是根据任务的数据集特点以及相关的评价指标来确定一个网络结构的输入图像分辨率、深度、每一层宽度、拓扑结构等细节。
- 目前AI技术应用的一个趋势是在端侧平台上部署高性能的CNN模型,并能在真实场景中实时(大于30帧)运行,如移动端/嵌入式设备。这些平台的特点是内存资源少,处理器性能不高,功耗受限,这使得目前精度最高的模型由于对内存和计算资源的超额要求使得根本无法在上面部署且达到实时性的要求。
- 虽然可以通过知识蒸馏,通道剪枝,(低比特)量化等一系列手段来降低模型参数量和计算量,但仍然远远不够,且在精度和帧率之间各种trade-off也非常繁琐。
- 所以直接设计轻量级的架构,然后结合剪枝量化是最有效的解决办法。

CNN优化加速策略
- 模型轻量化:设计更高效的“网络计算方式”(主要针对卷积方式),从而使网络参数减少的同时,不损失网络性能。eg:SqueezeNet、MobileNet、ShuffleNet、Xception等
- 模型压缩(Model Compression):在已经训练好的模型上进行压缩,使得网络携带更少的网络参数,从而解决内存问题,同时可以解决速度问题。
常用Efficient-AI技术有:蒸馏、剪枝、量化、权重共享、低秩分解、注意力模块轻量化、动态网络架构/训练方式、 更轻的网络架构、NAS(神经架构搜索)、硬件支持、编译器支持
1. 知识蒸馏
- 一种简单而有效的模型压缩/训练方法,将教师模型(规模大、表现好)所学习到的知识迁移到学生模型(规模小,表现不如大模型好)上,使学生模型具有规模小的同时表现好的特点
- 常见的知识蒸馏方法有KD算法(两个损失函数加权平均)、TAS算法(多级知识蒸馏,利用一个中等规模的网络(助教)弥补学生模型和教师模型的差距)
2. 量化
- 不需要设计更小的模型架构,而是采用更低位的固定表达(比如8bit、4bit、2bit、1bit)代替32位浮点参数
- 通过降低模型精度的方式来减少模型的存储空间,所需计算资源大大减少
- TensorFlow Lite toolkit中有量化的工具可以供我们使用 (MobileBERT直接使用了这个工具,进一步压缩了4倍大小)
- 一种极端的量化方式是二值量化(binarization),仅用-1和+1表示权重,每个权重仅占用1bit,所以模型压缩到了原来的1/32,效率极高
- 量化的有效性
- 量化会损失精度(相当于给网络引入noise),而神经网络对噪声不太敏感,所以控制好量化程度,能尽可能避免精度影响
- 量化后,权重的位数少了,所需存储空间和计算资源减少
- 从体系结构考虑,量化能够节能和减少芯片面积
3. 剪枝
- 找出网络中冗余的部分并删除,这部分不再参与前向或反向传播,较少模型的计算量和存储量
- 常见的剪枝
- 连接权重:权重剪枝类似mask为0,理论上这样做不减小模型大小,但是可以通过稀疏矩阵实现,从而减小模型的存储压力
- 神经元:给冗余的神经元剪枝,相当于drop-out,减小了模型大小,性能损失不大
- 权重矩阵:类似减少attention机制中的multi-head数量
4. 低秩分解
- 从分解矩阵计算的角度对模型计算过程优化,通过线性代数方法将参数矩阵分解为一系列小矩阵组合,使小矩阵的组合在表达能力上和原始卷积层一样
- 可保持模型精度,同时极大降低参数存储所占空间,按照从浅到深的顺序逐层做低秩近似
5. 权重共享/参数共享
- 通过在多个layer之间共享模型的参数,实现参数量的减小,从而使模型具有更小的模型和更高的效率
6. 动态网络架构(自适应宽度和高度)
- 通过自适应的方式减少模型的深度或宽度,可以达到轻量化模型的目的
7. 注意力模块轻量化
- Transformer是基于attention机制的,过多的attention计算会导致较大的计算量,所以可以通过自适应注意力机制、审视注意力机制中重要的部分,都能压缩模型
8. 更轻的网络架构设计
- 直接对模型的内部结构做改进,用计算量更小的方式替换模型中一些计算量大的模块
- (补充)接下来将介绍MobileNet、ShuffleNet、EfficientNet轻量化网络架构
9. 权重共享NAS
- NAS自动地优化神经网络,能够使网络在一定条件的限制下(比如FLOPs,延迟,内存占用等因素)达到最高的精度
- Weight-Sharing NAS构建一个集成了搜索空间内所有网络的超网络。主要分为两个阶段:超网络的训练和超网络的采样/评估
- 目前Weight-Sharing NAS存在的两大挑战是:如何制定搜索空间,如何训练超网络
- Weight-Sharing NAS联合训练超网络和自网络以降低训练成本,超网络训练直接决定了搜索网络的准确率,要考虑两点:如何在训练时采样子网络;如何促使子网络汇聚
10. 硬件加速
11. 编译器支持
- Compiler tool对于高效执行是至关重要的,为SOTA高效网络架构和操作提供支持(如Depthwise/Group Convolutions, Attention Layers)
- 也为multi-pathway架构中的layer scheduling提供支持(通过避免DRAM访问实现显著的性能/能耗优化,通过避免存储瓶颈实现显著的的延迟优化)
基本概念
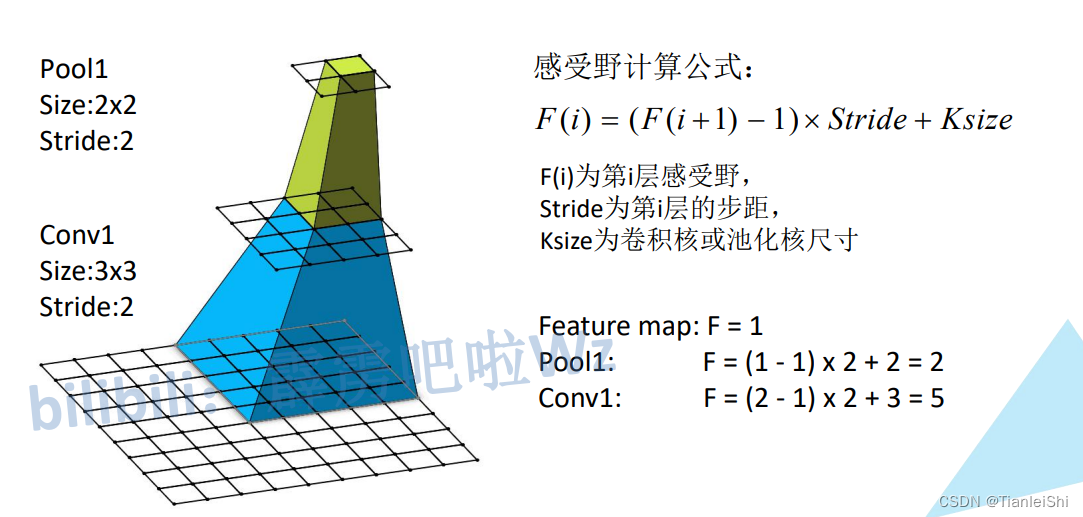
1. 感受野(Receptive Field)
- 概念:在CNN中,决定某一层输出结果中一个元素所对应的输入层的区域大小。神经元感受野的范围越大表示其能接触到的原始图像范围就越大,也意味着它能学习更为全局,语义层次更高的特征信息,相反,范围越小则表示其所包含的特征越趋向局部和细节。
- 感受野的范围可以用来大致判断每一层的抽象层次,并且我们可以很明显地知道网络越深,神经元的感受野越大。
- 感受野计算:
- 卷积输出计算:
eg:图中Feature map(F = 1)对应原图感受野为5×5
2. 分辨率(Resolution)
- 概念:输入模型的图像尺寸,即长宽大小。
- 通常情况下会根据模型下采样次数n和最后一次下采样后feature map的分辨率k×k来决定输入分辨率的大小,即:
- 在ImageNet分类任务中,通常设置的5次下采样,并且考虑到其原始图像大多数在300分辨率左右,所以把最后一个卷积特征大小设定为7×7,将输入尺寸固定为224×224×3。
- 在目标检测任务中,很多采用的是416×416×3的输入尺寸,当然由于很多目标检测模型是全卷积的结构,通常可以使用多尺寸训练的方式,即每次输入只需要保证是32×的图像尺寸大小就行,不固定具体数值。但这种多尺度训练的方式在图像分类当中是不通用的,因为分类模型最后一层是全连接结构,即矩阵乘法,需要固定输入数据的维度。
3. 深度(Depth)
- 神经网络的深度决定了网络的表达能力
- 早期的backbone设计都是直接使用卷积层堆叠的方式,它的深度即神经网络的层数,后来的backbone设计采用了更高效的module(或block)堆叠的方式,每个module是由多个卷积层组成,它的深度也可以指module的个数,这种说法在神经架构搜索(NAS)中出现的更为频繁。
- 通常而言网络越深表达能力越强,但深度大于某个值可能会带来相反的效果,所以它的具体设定需要不断调参得到。
4. 宽度(Width)
- 神经网络某一层学到的信息量。有时指CNN中最大的通道数,由卷积核数量最多的层决定。
- 通常,卷积核的数量随着层数越来越多,直到最后一层达到最大。这是因为越到深层,特征图的分辨率越小,所包含的信息越高级,所以需要更多的卷积核来学习。通道越多效果越好,但带来的计算量也会大大增加。
- 卷积核数量的具体设定也是一个调参的过程,并且各层通道数会按照8×的倍数来确定,这样有利于GPU的并行计算。
5. 下采样(Down-Sampling)
- 作用:①减少计算量,防止过拟合;②增大感受野,使得后面的卷积核能够学到更加全局的信息。
- 设计:
- 采用stride为2的池化层,如Max-pooling或Average-pooling,目前通常使用Maxpooling,因为它计算简单且最大响应能更好保留纹理特征;
- 采用stride为2的卷积层,下采样的过程是一个信息损失的过程,而池化层是不可学习的,用stride为2的可学习卷积层来代替pooling可以得到更好的效果,当然同时也增加了一定的计算量。
- 双线性插值,向下插值来代替池化(比maxpooling计算量更大,但保留的信息更丰富)
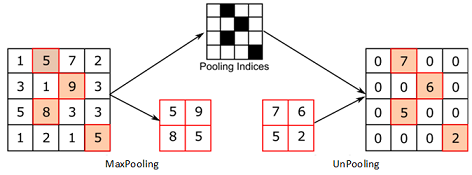
6. 上采样(Up-Sampling)
- 使图像由小分辨率映射到大分辨率的操作
- 实现方式:
- 插值,一般使用的是双线性插值,因为效果最好,虽然计算上比其他插值方式复杂,但是相对于卷积计算可以说不值一提
- 转置卷积又或是说反卷积,通过对输入feature map间隔填充0,再进行标准的卷积计算,可以使得输出feature map的尺寸比输入更大
- Max Unpooling,在对称的max pooling位置记录最大值的索引位置,然后在unpooling阶段时将对应的值放置到原先最大值位置,其余位置补0
7. 参数量(Params,空间复杂度,占用显存的量)
参数量是指网络中可学习变量的数量,包括卷积核的权重weight(主要),批归一化(BN)的缩放系数γ,偏移系数β,有些没有BN的层可能有偏置bias。参数量越大,对运行平台的内存要求越高,参数量的大小是轻量化网络设计的一个重要评价指标。
- 一般一个参数是一个float,也就是4个字节。1kb=1024字节
- 计算:
- 卷积层:卷积核尺寸 ×(图像channel + 偏置)× 卷积核个数
- 池化层:无需参数
- 全连接层:
- Conv → FC:前一层特征图尺寸 × 前一层卷积核个数 × 全连接层神经元个数
- FC → FC:输入神经元个数 × 输出神经元个数
8. 计算量(FLOPs,浮点运算数,时间复杂度,对应于GPU算力)
- FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
- FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指每秒浮点运算次数,理解为计算量。可以用来衡量算法/模型的复杂度。
- 计算量的要求在于芯片的floaps,指的是GPU的运算能力。网络执行时间的长短。
- 神经网络的前向推理过程基本上都是乘累加计算,所以它的计算量也是指的前向推理过程中乘加运算的次数,通常用FLOPs来表示
- 计算量越大,在同一平台上模型运行延时越长,尤其是在移动端/嵌入式这种资源受限的平台上想要达到实时性的要求就必须要求模型的计算量尽可能地低
- 但这个不是严格成正比关系,也跟具体算子的计算密集程度(即计算时间与IO时间占比)和该算子底层优化的程度有关。
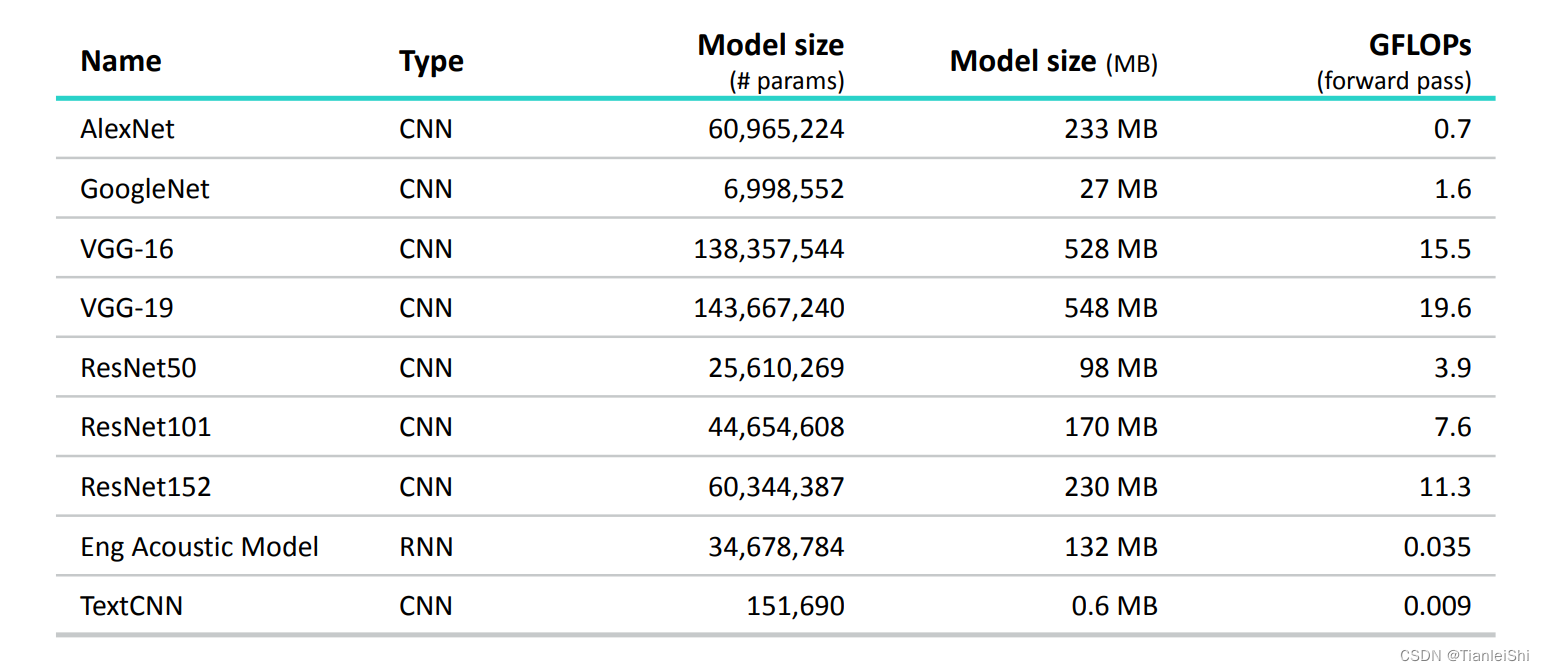
💡 下图为各个经典网络的模型尺寸和计算量对比
- 以AleNet为例,参数量6000万,设每个参数都是float,也就是一个参数四个字节。总的字节数是24000万字节=24000万/1024/1024 ≈ 233MB
- 为什么模型之间差距这么大:这与模型设计有关,其中模型里面最费参数的就是全连接层,例如alex和vgg,有很多全连接层。而ResNet、InceptionV1(GoogleNet)只有一个全连接层
- DenseNet模型不算大(参数量不大,因为只有一个fc),但是计算量大,因为每一次都把上一个feature加进来。
9. 模型尺寸
- 指模型的大小,一般用参数量来衡量(单位是“个”,常转换成MB)
- 在实际计算时除了包含参数量以外,还包括网络架构信息和优化器信息等。比如存储一个一般的CNN模型(ImageNet训练)需要大于300MB。
卷积类型
1. 标准卷积(Convolution)
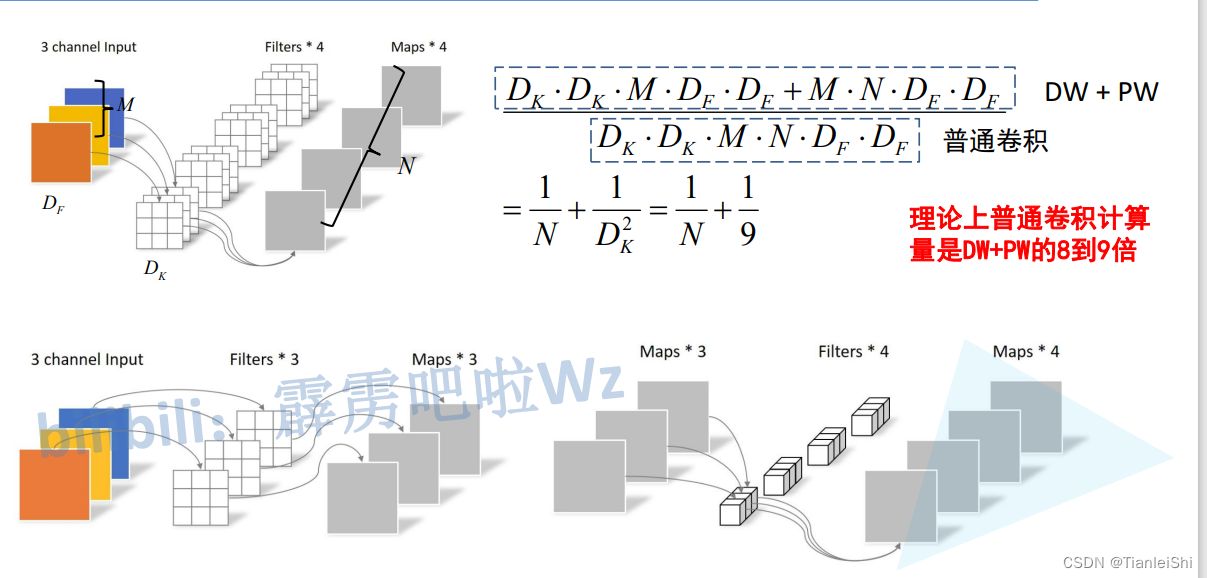
2. 深度卷积(Depthwise Convolution)
- 标准卷积中的每个卷积核都要与特征图的所有层进行计算,所以每个卷积核的通道数等于输入特征图的通道数,通过设定卷积核的数量可以控制输出特征图的通道数
- DW卷积是单通道的,它不能改变输出特征图的通道数,所以通常会在后面接上一个1×1的标准卷积(PW卷积)来控制输出通道数,称为深度可分离卷积
- 深度可分离卷积计算量如下图所示,深度卷积之前一直被吐槽在GPU上运行速度还不如一般的标准卷积,因为depthwise 的卷积核复用率比普通卷积要小很多,计算和内存访问的比值比普通卷积更小,因此会花更多时间在内存开销上,而且per-channel的矩阵计算很小不容易并行导致的更慢,但理论上计算量和参数量都是大大减少的,只是底层优化的问题。
3. 分组卷积(Group Convolution)
- 分组卷积最早在AlexNet中出现,当时作者在训练模型时为了减少显存占用而将feature map分组然后给多个GPU进行处理,最后把多个输出进行融合
- 但由于feature map组与组之间相互独立,存在信息的阻隔,所以ShuffleNet提出对输出的feature map做一次channel shuffle的操作,即通道混洗,打乱原先的顺序,使得各个组之间的信息能够交互起来。
4. 空洞卷积(Dilated Convolution)
- 针对图像语义分割问题中下采样会降低图像分辨率,丢失信息而提出的一种卷积思路。通过间隔取值扩大感受野,让原本3×3的卷积核,在相同参数量和计算量下拥有更大的感受野
- 扩张率系数(dilation rate),定义了间隔的大小,标准剪辑相当于dilation rate = 1的空洞卷积
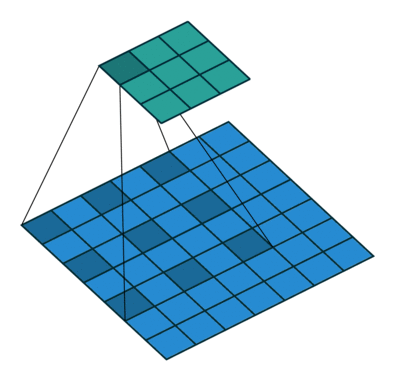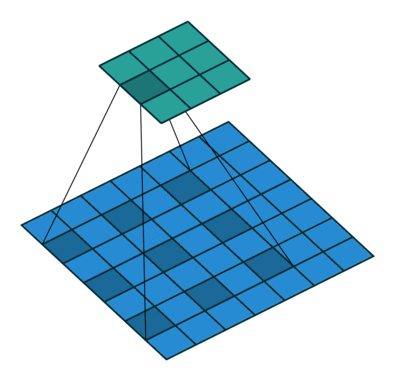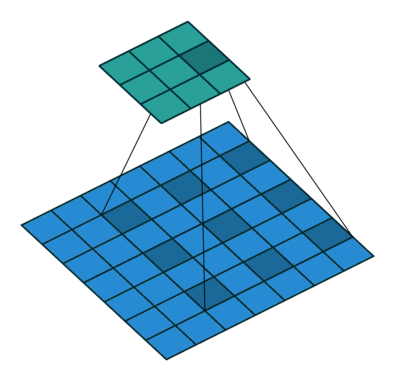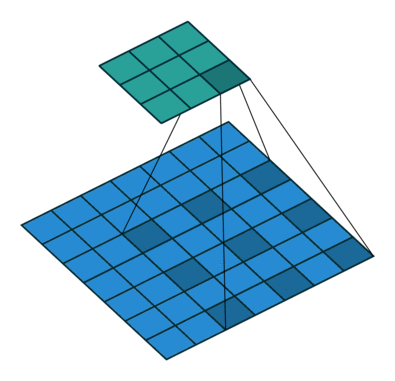
5. 转置卷积(Transposed Convolution)
- 又称反卷积,它和空洞卷积的思路正好相反,是为上采样而生,也应用于语义分割当中
- 计算过程与空洞卷积正好相反,先对输入的feature map间隔补0,卷积核不变,然后使用标准的卷积进行计算,得到更大尺寸的特征图
6. 可变形卷积(Deformable Convolution)
- 以上的卷积计算都是固定的,每次输入不同的图像数据,卷积计算的位置都是完全固定不变,即使是空洞卷积/转置卷积,0填充的位置也都是事先确定的
- 可变性卷积是指卷积核上对每一个元素额外增加了一个h和w方向上偏移的参数,然后根据这个偏移在feature map上动态取点来进行卷积计算,这样卷积核就能在训练过程中扩展到很大的范围
- 显而易见的是可变性卷积虽然比其他卷积方式更加灵活,可以根据每张输入图片感知不同位置的信息,类似于注意力,从而达到更好的效果,但是它比可行变卷积在增加了很多计算量和实现难度,目前感觉只在GPU上优化的很好,在其他平台上还没有见到部署
其他操作
1. 池化(pooling)
- 和depthwise卷积类似,只是把乘累加操作替换成取最大/取平均操作
- 最大池化和平均池化
- 全局平均池化
- 全局平均池化的操作是对一个维度为(C,H,W)的feature map,在HW方向整个取平均,然后输出一个长度为C的向量,这个操作一般在分类模型的最后一个feature map之后出现,然后接一个全连接层就可以完成分类结果的输出了
- 早期的分类模型都是把最后一个feature map直接拉平成C×H×W的向量,然后再接全连接层,但是显然可以看出来这个计算量极大,甚至有的模型最后一个全连接层占了整个模型计算量的50%以上,之后由研究人员发现对这个feature map做一个全局平均池化,然后再加全连接层可以达到相似的效果,且计算量降低到了原来的1/HW。
- 最大向上池化
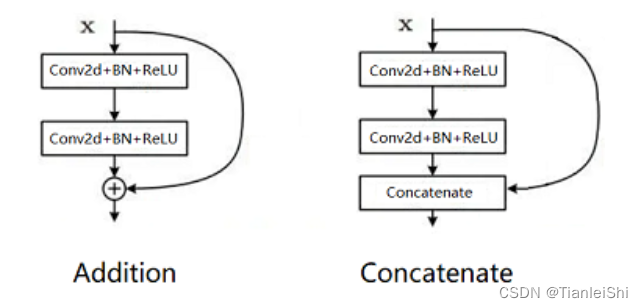
2. Addition、Concatenate分支
- Addition和Concatenate分支操作统称为shortcut,如下图所示,操作极为简单
- Addition是在ResNet中提出,两个相同维度的feature map相同位置点的值直接相加,得到新的相同维度feature map,这个操作可以融合之前的特征,增加信息的表达
- Concatenate操作是在Inception中首次使用,被DenseNet发扬光大,和addition不同的是,它只要求两个feature map的HW相同,通道数可以不同,然后两个feature map在通道上直接拼接,得到一个更大的feature map,它保留了一些原始的特征,增加了特征的数量,使得有效的信息流继续向后传递
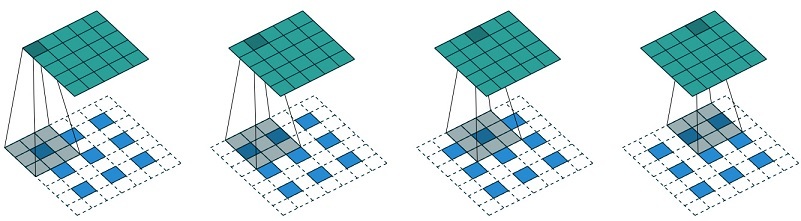
3. Channel shuffle
- channel shuffle是ShuffleNet中首次提出,主要是针对分组卷积中不同组之间信息不流通,对不同组的feature map进行混洗的一个操作
- 如下图所示,假设原始的feature map维度为(1,9,H,W),被分成了3个组,每个组有三个通道,那么首先将这个feature map进行reshape操作,得到(1,3,3,H,W),然后对中间的两个大小为3的维度进行转置,依然是(1,3,3,H,W),最后将通道拉平,变回(1,9,H,W),就完成了通道混洗,使得不同组的feature map间隔保存,增强了信息的交互

常用激活函数
激活函数的非线性是神经网络发挥作用最重要的因素之一,而对于实际部署,激活函数的实现也是很重要的一个方面,实现的不好对加速效果影响很大,这里主要讲几个部署当中常见的激活函数。
1. ReLU系列
ReLU 函数是深度学习中较为流行的一种激活函数,相比于 sigmoid 函数和 tanh 函数,它具有如下优点:
- 当输入为正时,不存在梯度饱和问题。
- 计算速度快得多。ReLU 函数中只存在线性关系,因此它的计算速度比 sigmoid 和 tanh 更快。
当然,它也有缺点:
- Dead ReLU 问题。当输入为负时,ReLU 完全失效,在正向传播过程中,这不是问题。有些区域很敏感,有些则不敏感。但是在反向传播过程中,如果输入负数,则梯度将完全为零,sigmoid 函数和 tanh 函数也具有相同的问题;
- 我们发现 ReLU 函数的输出为 0 或正数,这意味着 ReLU 函数不是以 0 为中心的函数。
- 这里主要指常用的ReLU,ReLU6和leaky ReLU
- ReLU:比较好部署,小于0的部分为0,大于0的部分为原始值,只需判断一下符号位
- ReLU6:与ReLU相比也只是在正向部分多了个阈值,大于6的值等于6,在实现时多了个比较也不算麻烦
- leaky ReLU:和ReLU正向部分一样,都是大于0等于原始值,但负向部分却是等于原始值的1/10,浮点运算的话乘个0.1就好了,如果因为量化要实现整数运算,这块可以做个近似,如0.1用13>>7来代替,具体实现方法多种多样 ,还算简单
2. Sigmoid系列
在什么情况下适合使用 Sigmoid 激活函数呢?
- Sigmoid 函数的输出范围是 0 到 1。由于输出值限定在 0 到 1,因此它对每个神经元的输出进行了归一化
- 用于将预测概率作为输出的模型。由于概率的取值范围是 0 到 1,因此 Sigmoid 函数非常合适
- 梯度平滑,避免「跳跃」的输出值
- 函数是可微的。这意味着可以找到任意两个点的 sigmoid 曲线的斜率
- 明确的预测,即非常接近 1 或 0
Sigmoid 激活函数有哪些缺点?
- 倾向于梯度消失
- 函数输出不是以 0 为中心的,这会降低权重更新的效率
- Sigmoid 函数执行指数运算,计算机运行得较慢。
- 主要指sigmoid,还有和他相关的swish
,
- sigmoid对低性能的硬件非常不友好,因为涉及到大量的指数运算和除法运算
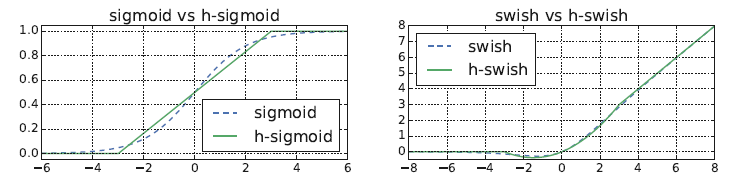
- h-sigmoid和h-swish函数
,
- 这里的h指的是hardware的意思,这两个函数对硬件比较友好
- 下图可以看出,在保证精度的同时又能大大方便硬件的实现
- 当然要直接实现sigmoid也是可以的,毕竟sigmoid是有限输出,当输入小于-8或大于8的时候,输出基本上接近于-1和1,可以根据这个特点设计一个查找表,速度也超快,且我们实测对精度没啥影响
参考来源:
(12条消息) 太阳花的小绿豆的博客_CSDN博客-深度学习,软件安装,Tensorflow领域博主
CNN 模型所需的计算力flops是什么?怎么计算? - 知乎 (zhihu.com)
(12条消息) 【轻量化深度学习】Efficient On-Device Deep Learning Research_Mr.zwX的博客-CSDN博客_轻量化深度学习
激活函数 | 深度学习领域最常用的10个激活函数,详解数学原理及优缺点 - 腾讯云开发者社区-腾讯云 (tencent.com)

















 161
161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









