







2.2 随机向量
若随机变量 X 1 , X 2 , ⋯ , X n X_{1}, X_{2}, \cdots, X_{n} X1,X2,⋯,Xn定义在同一个样本空间 Ω \Omega Ω上, 则称 ( X 1 , X 2 , ⋯ , \left(X_{1}, X_{2}, \cdots,\right. (X1,X2,⋯,, X n X_{n} Xn) 为一个 n n n维随机向量或 n n n维随机变量。
我们虽然可以仿照一维随机变量定义多维随机变量的分布函数,但分布函数在多维中意义不大,这里仅给出其定义.
X = ( X 1 , ⋯ , X n ) X=\left(X_{1}, \cdots, X_{n}\right) X=(X1,⋯,Xn)为一个 n n n维随机向量, 对任意实数 x 1 , ⋯ , x n x_{1}, \cdots, x_{n} x1,⋯,xn, 称 n n n元函数 F ( x 1 , ⋯ , x n ) = P ( X 1 ⩽ x 1 , X 2 ⩽ x 2 , ⋯ , X n ⩽ x n ) F\left(x_{1}, \cdots, x_{n}\right)=P\left(X_{1} \leqslant x_{1}, X_{2} \leqslant x_{2}, \cdots, X_{n} \leqslant x_{n}\right) F(x1,⋯,xn)=P(X1⩽x1,X2⩽x2,⋯,Xn⩽xn)为随机向量 X = ( X 1 , ⋯ , X n ) X=\left(X_{1}, \cdots, X_{n}\right) X=(X1,⋯,Xn)的分布函数。
下面介绍连续性随机向量和连续型随机向量的分布.
2.2.1 离散型随机向量的分布
设
n
n
n维随机向量
X
=
(
X
1
,
⋯
,
X
n
)
X=\left(X_{1}, \cdots, X_{n}\right)
X=(X1,⋯,Xn)的每一个分量
X
i
X_{i}
Xi都是一维离散型随机变量,
i
=
1
,
2
,
⋯
,
n
i=1,2, \cdots, n
i=1,2,⋯,n, 则称
X
X
X为离散型的。若
{
a
i
1
,
a
i
2
,
⋯
}
\left\{a_{i 1}, a_{i 2}, \cdots\right\}
{ai1,ai2,⋯}为
X
i
X_{i}
Xi的全部可能值, 则对
j
k
=
1
,
2
,
⋯
,
k
=
1
,
2
,
⋯
,
n
j_{k}=1,2, \cdots, \quad k=1,2, \cdots, n
jk=1,2,⋯,k=1,2,⋯,n, 概率
p
(
j
1
,
j
2
,
⋯
,
j
n
)
=
P
(
X
1
=
a
1
j
1
,
X
2
=
a
2
j
2
,
⋯
,
X
n
=
a
n
j
n
)
p\left(j_{1}, j_{2}, \cdots, j_{n}\right)=P\left(X_{1}=a_{1 j_{1}}, X_{2}=a_{2 j_{2}}, \cdots, X_{n}=a_{n j_{n}}\right)
p(j1,j2,⋯,jn)=P(X1=a1j1,X2=a2j2,⋯,Xn=anjn)
称为随机向量
X
=
(
X
1
,
⋯
,
X
n
)
X=\left(X_{1}, \cdots, X_{n}\right)
X=(X1,⋯,Xn)的概率函数或概率分布率。
多项分布
多项分布式最重要的离散型多维分布,其定义如下:
设 A 1 , A 2 , ⋯ , A n A_{1}, A_{2}, \cdots, A_{n} A1,A2,⋯,An是 某一试验之下的完备事件群.现在将试验独立地重复 N N N次, 而以 X i X_{i} Xi记在这 N N N次试验中事 件 A i A_{i} Ai出现的次数, i = 1 , ⋯ , n i=1, \cdots, n i=1,⋯,n, 则 X = ( X 1 , ⋯ , X n ) X=\left(X_{1}, \cdots, X_{n}\right) X=(X1,⋯,Xn)的概率分布为多项分布,记为 M ( N ; p 1 , ⋯ , p n ) M\left(N ; p_{1}, \cdots, p_{n}\right) M(N;p1,⋯,pn).
易得其公式为
P ( X 1 = k 1 , X 2 = k 2 , ⋯ , X n = k n ) = N ! k 1 ! k 2 ! ⋯ k n ! p 1 k p 2 k ⋯ p n n k n P\left(X_{1}=k_{1}, X_{2}=k_{2}, \cdots, X_{n}=k_{n}\right)=\frac{N !}{k_{1} ! k_{2} ! \cdots k_{n} !} p_{1}^{k} p_{2}^{k} \cdots p_{n^{n}}^{k_{n}} P(X1=k1,X2=k2,⋯,Xn=kn)=k1!k2!⋯kn!N!p1kp2k⋯pnnkn
该公式直观理解就是将 N N N个相异物体分成 n n n堆, 各堆依次有 k 1 , k 2 , ⋯ , k n k_{1}, k_{2}, \cdots, k_{n} k1,k2,⋯,kn件,每件物品有 p i p_i pi的概率分到第 i i i堆.
2.2.2 连续型随机向量的分布
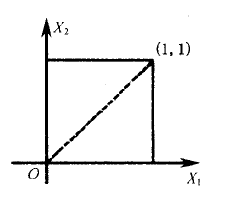
与离散型随机向量的定义不 同, 连续型随机向量不能简单地定义为 “其各分量都是一维连续型随机变量的 那种随机向量”.举一个例子:设 X 1 ∼ X_{1} \sim X1∼ R ( 0 , 1 ) , X 2 = X 1 R(0,1), X_{2}=X_{1} R(0,1),X2=X1, 则 随 机 向量 ( X 1 , X 2 ) \left(X_{1}, X_{2}\right) (X1,X2)的两个分量 X 1 , X 2 X_{1}, X_{2} X1,X2都是连续型的.但 ( X 1 , X 2 ) (X_1,X_2) (X1,X2)只能在单位正方形的对角线上取值,其概率之和必然为0.故不是连续型随机向量.
连续型随机向量的定义如下:
设 X = ( X 1 , ⋯ , X n ) X=\left(X_{1}, \cdots, X_{n}\right) X=(X1,⋯,Xn)是一个 n n n维随机向量.其取值可视为 n n n维欧氏空间 R n R^{n} Rn中的一个点. 如果 X X X的全部取值能充满 R n R^{n} Rn中某一区域,则称它是连续型的.
若
f
(
x
1
,
⋯
,
x
n
)
f\left(x_{1}, \cdots, x_{n}\right)
f(x1,⋯,xn)是定义在
R
n
R^{n}
Rn上的非负函数,使对
R
n
R^{n}
Rn中的任何集合
A
A
A, 有
P
(
X
∈
A
)
=
∫
A
⋯
∫
f
(
x
1
,
⋯
,
x
n
)
d
x
1
⋯
d
x
n
P(X \in A)=\int_{A} \cdots \int f\left(x_{1}, \cdots, x_{n}\right) \mathrm{d} x_{1} \cdots \mathrm{d} x_{n}
P(X∈A)=∫A⋯∫f(x1,⋯,xn)dx1⋯dxn
则称
f
f
f是
X
X
X的(概率)密度函数,反应了
X
X
X落在某点
(
x
1
,
⋯
,
x
n
)
\left(x_{1}, \cdots, x_{n}\right)
(x1,⋯,xn)的概率大小.
二维正态分布
二维正态分布的概率密度函数如下.该分布记为 N ( a , b , σ 1 2 , σ 2 2 , ρ ) N\left(a, b, \sigma_{1}^{2}, \sigma_{2}^{2}, \rho\right) N(a,b,σ12,σ22,ρ)
p
(
x
,
y
)
=
1
2
π
σ
1
σ
2
1
−
ρ
2
exp
{
−
1
2
(
1
−
ρ
2
)
[
(
x
−
μ
1
σ
1
)
2
−
2
ρ
(
x
−
μ
1
σ
1
)
(
y
−
μ
2
σ
2
)
+
(
y
−
μ
2
σ
2
)
2
]
}
\begin{aligned} p(x, y)=& \frac{1}{2 \pi \sigma_{1} \sigma_{2} \sqrt{1-\rho^{2}}} \exp \left\{-\frac{1}{2\left(1-\rho^{2}\right)}\left[\left(\frac{x-\mu_{1}}{\sigma_{1}}\right)^{2}\right.\right.\\ &\left.\left.-2 \rho\left(\frac{x-\mu_{1}}{\sigma_{1}}\right)\left(\frac{y-\mu_{2}}{\sigma_{2}}\right)+\left(\frac{y-\mu_{2}}{\sigma_{2}}\right)^{2}\right]\right\} \end{aligned}
p(x,y)=2πσ1σ21−ρ21exp{−2(1−ρ2)1[(σ1x−μ1)2−2ρ(σ1x−μ1)(σ2y−μ2)+(σ2y−μ2)2]}
二维正态分布的一个例子为一群人身高和体重的联合分布.
2.2.3 边缘分布
边缘分布说白了就是求随机向量某个分量的分布.
其公式为
离 散 型 : P ( X 1 = a 1 k ) = ∑ j 2 , ⋯ , j n p ( k , j 2 , ⋯ , j n ) , k = 1 , 2 , ⋯ 离散型: P\left(X_{1}=a_{1 k}\right)=\sum_{j_{2}, \cdots, j_{n}} p\left(k, j_{2}, \cdots, j_{n}\right), k=1,2, \cdots 离散型:P(X1=a1k)=j2,⋯,jn∑p(k,j2,⋯,jn),k=1,2,⋯
连 续 型 : f 1 ( x 1 ) = ∫ − ∞ ∞ ⋯ ∫ − ∞ ∞ f ( x 1 , x 2 , ⋯ , x n ) d x 2 ⋯ d x n 连续型: f_{1}\left(x_{1}\right)=\int_{-\infty}^{\infty} \cdots \int_{-\infty}^{\infty} f\left(x_{1}, x_{2}, \cdots, x_{n}\right) \mathrm{d} x_{2} \cdots \mathrm{d} x_{n} 连续型:f1(x1)=∫−∞∞⋯∫−∞∞f(x1,x2,⋯,xn)dx2⋯dxn
这些公式也可以看作是全概率公式.
例如,对于离散情况,要求
P
(
X
1
=
a
1
k
)
P(X_1=a_{1k})
P(X1=a1k).可以将事件A记为
{
X
1
=
a
1
k
}
\{X_1=a_{1k}\}
{X1=a1k},将事件
B
i
B_i
Bi记为
{
X
2
=
j
2
,
⋯
,
X
n
=
j
n
}
\{X_2=j_2,\cdots,X_n=j_n\}
{X2=j2,⋯,Xn=jn},穷尽
j
2
,
⋯
,
j
n
j_2,\cdots,j_n
j2,⋯,jn的所有取值情况,求该情况下事件
A
A
A发生的条件概率
p
(
k
,
j
2
,
⋯
,
j
n
)
p\left(k, j_{2}, \cdots, j_{n}\right)
p(k,j2,⋯,jn),再累加起来记为事件A发生的概率.
P
(
A
)
=
P
(
B
1
)
P
(
A
∣
B
1
)
+
P
(
B
2
)
P
(
A
∣
B
2
)
+
⋯
=
∑
j
2
,
⋯
,
j
n
p
(
k
,
j
2
,
⋯
,
j
n
)
\begin{aligned} P(A)&=P\left(B_{1}\right) P\left(A \mid B_{1}\right)+P\left(B_{2}\right) P\left(A \mid B_{2}\right)+\cdots \\ &=\sum_{j_{2}, \cdots, j_{n}} p\left(k, j_{2}, \cdots, j_{n}\right) \end{aligned}
P(A)=P(B1)P(A∣B1)+P(B2)P(A∣B2)+⋯=j2,⋯,jn∑p(k,j2,⋯,jn)
下面给出离散型和连续型的例子.
多项分布的边缘分布
设 X = ( X 1 , ⋯ , X n ) X=\left(X_{1}, \cdots, X_{n}\right) X=(X1,⋯,Xn)服从多项分布 M ( N ; p 1 , ⋯ , M\left(N ; p_{1}, \cdots,\right. M(N;p1,⋯,, p n p_{n} pn), 要求其边缘分布. 例如,考虑 X 1 X_{1} X1, 我们把事件 A 1 A_{1} A1作为一方, A 2 + ⋯ + A n A_{2}+\cdots+A_{n} A2+⋯+An作为一方(它就是 A ˉ 1 ) \left.\bar{A}_{1}\right) Aˉ1), 那么, X 1 X_{1} X1就 是在 N N N次独立试验中,事件 A 1 A_{1} A1发生的次数,而在每次试验中 A 1 A_{1} A1发生的概率保持为 p 1 p_{1} p1, 经过这一分析, 不待计算就可以明了: X 1 X_{1} X1的分布就是二项分布 B ( N , p 1 ) B\left(N, p_{1}\right) B(N,p1).
陈希孺在书中给出了详细的代数方法的证明过程,但正如陈希孺所说,学学概统更重要的式要形成概率思维,分析各种公式的概率意义和直观意义.所以这里不给出证明.
二维正态分布的边缘分布
若 ( X 1 , X 2 ) \left(X_{1}, X_{2}\right) (X1,X2)有二维正态分布 N ( a , b , σ 2 1 , σ 2 2 , ρ ) N\left(a, b, \sigma_{2}^{1}, \sigma_{2}^{2}, \rho\right) N(a,b,σ21,σ22,ρ), 则 X 1 X_{1} X1, X 2 X_{2} X2的边缘分布分别是一维正态分布 N ( a , σ 1 2 ) N\left(a, \sigma_{1}^{2}\right) N(a,σ12)和 N ( b , σ 2 2 ) N\left(b, \sigma_{2}^{2}\right) N(b,σ22).
二维正态分布揭示了一个有趣的事实:一个随机向量 X = X= X= ( X 1 , ⋯ , X n ) \left(X_{1}, \cdots, X_{n}\right) (X1,⋯,Xn)的分布 F F F足以决定其任一分量 X i X_{i} Xi的 ( \left(\right. (边缘)分布 F i F_{i} Fi, 但反过来不对: 即使知道了所有 X i X_{i} Xi的边缘分布 F i , i = 1 , ⋯ , n F_{i}, i=1, \cdots, n Fi,i=1,⋯,n, 也足以决定 X X X的分布 F F F.因为同样的 N ( a , σ 1 2 ) N\left(a, \sigma_{1}^{2}\right) N(a,σ12)和 N ( b , σ 2 2 ) N\left(b, \sigma_{2}^{2}\right) N(b,σ22),有不同的 ρ \rho ρ取值.
这个现象的解释是:边 缘分布只分别考虑了单个变量 X i X_{i} Xi的情况,而末涉及它们之间的 关系,而这个信息却是包含在 ( X 1 , ⋯ , X . ) \left(X_{1}, \cdots, X_{.}\right) (X1,⋯,X.)的分布之内的,.在二维正态分布中, ρ \rho ρ这个参数正好刻画 了两分量 X 1 X_{1} X1和 X 2 X_{2} X2之间的关系.
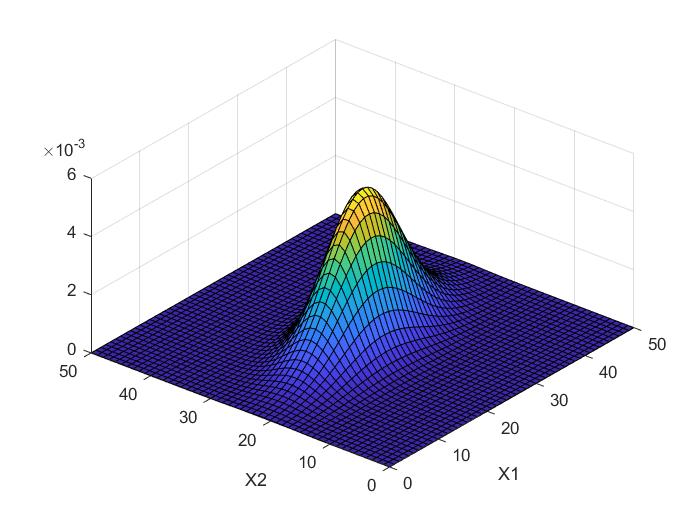
例如,我们用matlab作图,考察
N
(
25
,
16
)
N\left(25, 16\right)
N(25,16)和
N
(
25
,
64
)
N\left(25, 64\right)
N(25,64)在不同
ρ
\rho
ρ下的概率密度.下面三张图展示了
ρ
=
0
,
0.5
,
−
0.5
\rho=0,0.5,-0.5
ρ=0,0.5,−0.5时对应的概率密度.同时我们可以看到,
N
(
a
,
b
,
σ
2
1
,
σ
2
2
,
ρ
)
N\left(a, b, \sigma_{2}^{1}, \sigma_{2}^{2}, \rho\right)
N(a,b,σ21,σ22,ρ)的概率密度函数在
X
O
Y
XOY
XOY平面的投影是一个椭圆.
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









