







2.1 一维随机变量
2.1.1 随机变量的概念
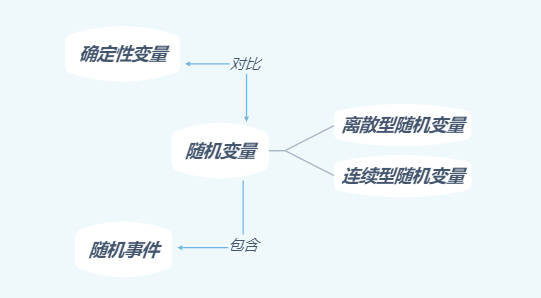
所谓随机变量,就是其值随机会而定的变量.例如骰子的点数X,在试验前无法确定它将取何值,但一旦试验结束,点数就确定了.而与之相对的就是确定变量,其取值遵循某种严格的规律,在试验前就能准确预知出来.例如骰子自由落体的距离H,我不需要进行试验就可根据自由落体定律计算出每个时刻对应的落体高度。
第一章提到的随机事件,实际上是包含随机变量这个更广泛的范围之内。例如事件:骰子的点数大于等于3可以用 { X ≥ 3 } \{X\ge 3\} {X≥3}表示。更进一步的,我们可以使用指示变量Y。
随机变量又可以分为离散型随机变量与连续型随机变量。
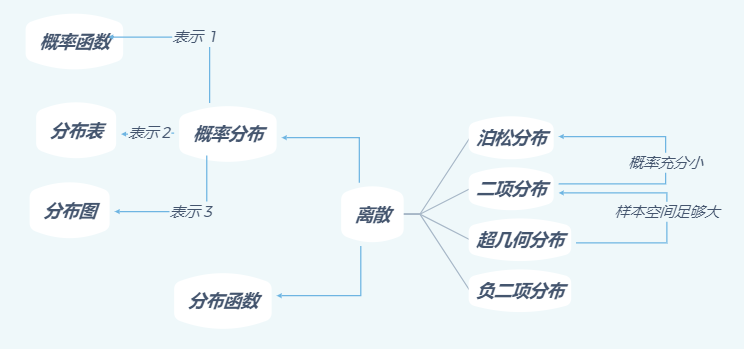
2.1.2 离散型随机变量的分布及其重要例子
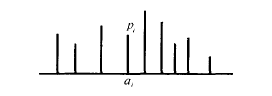
设
X
X
X为离散型随机变量, 其全部可能值为
{
a
1
\left\{a_{1}\right.
{a1,
a
2
⋯
}
\left.a_{2} \cdots\right\}
a2⋯}. 则
p
i
=
P
(
X
=
a
i
)
,
i
=
1
,
2
,
⋯
p_{i}=P\left(X=a_{i}\right), i=1,2, \cdots
pi=P(X=ai),i=1,2,⋯
称为
X
X
X的概率函数.
显然有
p
i
⩾
0
,
p
1
+
p
2
+
⋯
=
1
p_{i} \geqslant 0, p_{1}+p_{2}+\cdots=1
pi⩾0,p1+p2+⋯=1
概率函数也称为
X
X
X的概率分布,其还有如下两种表现形式.

设
X
X
X为一随机变量,则函数
P
(
X
⩽
x
)
=
F
(
x
)
,
−
∞
<
x
<
∞
P(X \leqslant x)=F(x),-\infty<x<\infty
P(X⩽x)=F(x),−∞<x<∞
称为
X
X
X的分布函数
对任何随机变量 X X X, 其分布函数 F ( x ) F(x) F(x)具有下面的一般性质:
1.
F
(
X
)
F(X)
F(X)是单调非降的: 当
(
x
1
<
x
2
)
\left(x_{1}<x_{2}\right)
(x1<x2)时, 有
F
(
x
1
)
⩽
F
(
x
2
)
F\left(x_{1}\right) \leqslant F\left(x_{2}\right)
F(x1)⩽F(x2).
2. 当
x
→
∞
x \rightarrow \infty
x→∞时,
F
(
x
)
→
1
F(x) \rightarrow 1
F(x)→1; 当
x
→
−
∞
x \rightarrow-\infty
x→−∞时,
F
(
x
)
→
0
F(x) \rightarrow 0
F(x)→0,
下面介绍常见的离散型随机变量的分布
二项分布
若随机变量
X
X
X的概率函数为
p
k
=
P
(
X
=
k
)
=
C
n
k
p
k
q
n
−
k
,
k
=
0
,
1
,
⋯
,
n
p_{k}=P(X=k)=C_{n}^{k} p^{k} q^{n-k}, k=0,1, \cdots, n
pk=P(X=k)=Cnkpkqn−k,k=0,1,⋯,n
其中
0
<
p
<
1
,
q
=
1
−
p
0<p<1, q=1-p
0<p<1,q=1−p, 则称
X
X
X服从参数为
n
,
p
n, p
n,p的二项分布, 记为
X
∼
B
(
n
,
p
)
X \sim B(n, p)
X∼B(n,p)
这个分布的现实意义为从有放回的抽查 n n n个元件,元件次品率为 p p p,检查出次品的个数为 X X X。
下面讨论当 k k k取何值时概率有最大值。
- 当 ( n + 1 ) p (n+1) p (n+1)p为整数时, p k p_{k} pk在 k = ( n + 1 ) p − 1 k=(n+1) p-1 k=(n+1)p−1和 k = ( n + 1 ) p k=(n+1) p k=(n+1)p达到最大,
- 当 ( n + 1 ) p (n+1) p (n+1)p不是整数时, p k p_{k} pk在 k = [ ( n + 1 ) p ] k=[(n+1) p] k=[(n+1)p]达到最大。其中, [ x ] [x] [x]表示不超过 x x x的最大整数。
泊松分布
如果随机变量
X
X
X的概率函数为
p
k
=
P
(
X
=
k
)
=
λ
k
k
!
e
−
λ
,
k
=
0
,
1
,
2
,
⋯
p_{k}=P(X=k)=\frac{\lambda^{k}}{k !} e^{-\lambda}, \quad k=0,1,2, \cdots
pk=P(X=k)=k!λke−λ,k=0,1,2,⋯
其中
λ
>
0
\lambda>0
λ>0为常数, 则称
X
X
X服从参数为
λ
\lambda
λ的泊松分布, 记为
X
∼
P
(
λ
)
X \sim P(\lambda)
X∼P(λ)。
这个分布的现实意义为描述大量试验中稀有事件出现频数概率模型。
泊松分布可以作为二项分布的极限而得到。一般地说,若 X ∼ B ( n , p ) X \sim B(n, p) X∼B(n,p), 其中 n n n很大, p p p很小而 n p = λ n p=\lambda np=λ不太大 时,则 X X X的分布接近于泊松分布 P ( λ ) . P(\lambda) . P(λ).
为了帮助直观理解这个结论,陈希孺给出了一个例子:在一定时间内某交通路口所发生的事故个数。
为方便计,设所观察的这段时间为
[
0
,
1
)
[0,1)
[0,1). 取一个很大的自然数
n
n
n, 把时间段
[
0
,
1
)
[0,1)
[0,1)分为等长的
n
n
n段:
l
1
[
0
,
1
n
)
,
l
2
=
[
1
n
,
2
n
)
,
⋯
,
l
i
=
[
i
−
1
n
,
i
n
)
,
⋯
l
n
=
[
n
−
1
n
,
1
)
\begin{aligned} l_{1}\left[0, \frac{1}{n}\right), l_{2} &=\left[\frac{1}{n}, \frac{2}{n}\right), \cdots, l_{i}=\left[\frac{i-1}{n}, \frac{i}{n}\right), \cdots \\ l_{n} &=\left[\frac{n-1}{n}, 1\right) \end{aligned}
l1[0,n1),l2ln=[n1,n2),⋯,li=[ni−1,ni),⋯=[nn−1,1)
作几个假定:
-
在每段 l i l_{i} li内,恰发生一个事故的概率,近似地与这段时 间之长 1 n \frac{1}{n} n1成正比,即可取为 λ / n . \lambda / n . λ/n.又假定在 n n n很大因而 1 / n 1 / n 1/n很小 时,在 l i l_{i} li这么短暂的一段时间内,要发生两次或更多的事故是不 可能的. 因此,在 l i l_{i} li时段内不发生事故的概率为 1 − 1 / n 1-1 / n 1−1/n.而这体现了事件的稀有性。
-
l 1 , ⋯ , l n l_{1}, \cdots, l_{n} l1,⋯,ln各段是否发生事故是独立的.
根据以上假定, X X X应服从二项分 布 B ( n , λ / n ) B(n, \lambda / n) B(n,λ/n). 于是
P ( X = i ) = ( n i ) ( λ n ) i ( 1 − λ n ) n − i P(X=i)=\left(\begin{array}{l} n \\ i \end{array}\right)\left(\frac{\lambda}{n}\right)^{i}\left(1-\frac{\lambda}{n}\right)^{n-i} P(X=i)=(ni)(nλ)i(1−nλ)n−i
将 n n n取极限即可推出泊松分布。
超几何分布
如果随机变量 X X X的概率函数为
P ( X = m ) = ( M m ) ( N − M n − m ) / ( N n ) P(X=m)=\left(\begin{array}{l}M \\ m\end{array}\right)\left(\begin{array}{c}N-M \\ n-m\end{array}\right) /\left(\begin{array}{l}N \\ n\end{array}\right) P(X=m)=(Mm)(N−Mn−m)/(Nn)
则称 X X X服从超几何分布。
该分布的现实意义为无放回的抽样。若 n / N n / N n/N很小,则 放回与不放回差别不大. 由此可见,在这种情况下超几何分布应与 二项分布很接近. 确切地说,若 X X X服从超几何分布 则当 n n n固定, M / N = p M / N=p M/N=p固定, N → ∞ N \rightarrow \infty N→∞时, X X X近似地服从二项分布 B ( n , p ) B(n, p) B(n,p)
负二项分布
如果随机变量 X X X的概率函数为
P ( X = i ) = b ( r − 1 ; i + r − 1 , p ) p = ( i + r − 1 r − 1 ) p r ( 1 − p ) i P(X=i)=b(r-1 ; i+r-1, p) p=\left(\begin{array}{c}i+r-1 \\ r-1\end{array}\right) p^{r}(1-p)^{i} P(X=i)=b(r−1;i+r−1,p)p=(i+r−1r−1)pr(1−p)i
则称 X X X服从负二项分布。
该分布的现实意义为同样为抽样检查,不过不同的是预先定一个数 r r r, 一个一个地元件中抽样检查,直到发现第 r r r个次品为 止.以 X X X记到当时为止已检出的合格品个数.
当 r = 1 r=1 r=1时, P ( X = i ) = p ( 1 − p ) i P(X=i)=p(1-p)^{i} P(X=i)=p(1−p)i。这称为几何分布。
2.1.3 连续型随机变量的分布及重要例子
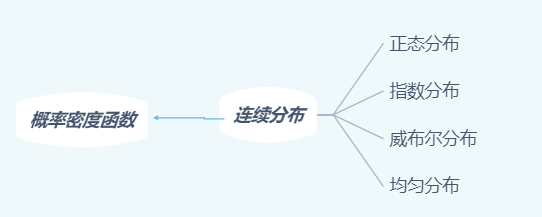
连续型随机变量的概率分布与离散型大不相同。例如,如在靶面上指定一个几何意义下的点(即只有位置而无任何向度),则 “射击时正好命中该点”的概率,也只能取为 0 .那么参照离散型用 P ( X = i ) P(X=i) P(X=i)刻画就毫无意义。
为了刻画连续型随机变量的概率分布,我们引入了概率密度函数:
设连续性随机变量 X X X有概率分布函数 F ( x ) F(x) F(x), 则 F ( x ) F(x) F(x)的导数 f ( x ) = F ′ ( x ) f(x)=F^{\prime}(x) f(x)=F′(x), 称为 X X X的概率密度函数.
连续型随机变量 X X X的密度函数 f ( x ) f(x) f(x)都具有以下三条基本性质:
1.
f
(
x
)
⩾
0
f(x) \geqslant 0
f(x)⩾0
2.
∫
−
∞
∞
f
(
x
)
d
x
=
1
\int_{-\infty}^{\infty} f(x) \mathrm{d} x=1
∫−∞∞f(x)dx=1
- 对任何常数 a < b a<b a<b有
P ( a ⩽ X ⩽ b ) = F ( b ) − F ( a ) = ∫ a b ( x ) d x P(a \leqslant X \leqslant b)=F(b)-F(a)=\int_{a}^{b}(x) \mathrm{d} x P(a⩽X⩽b)=F(b)−F(a)=∫ab(x)dx
有了概率密度函数这个工具后,下面介绍常见的连续性随机变量分布。
正态分布
若随机变量
X
X
X的密度函数为
p
(
x
)
=
1
2
π
σ
e
−
(
x
−
μ
)
2
2
σ
2
,
−
∞
<
x
<
∞
p(x)=\frac{1}{\sqrt{2 \pi} \sigma} e^{-\frac{(x-\mu)^{2}}{2 \sigma^{2}}}, \quad-\infty<x<\infty
p(x)=2πσ1e−2σ2(x−μ)2,−∞<x<∞
其中
μ
,
σ
(
>
0
)
\mu, \sigma(>0)
μ,σ(>0)为常数, 则称
X
X
X服从参数为
μ
,
σ
2
\mu, \sigma^{2}
μ,σ2的正态分布, 记为
X
∼
N
(
μ
,
σ
2
)
X \sim N\left(\mu, \sigma^{2}\right)
X∼N(μ,σ2)
正态分布的现实意义为一般事物常为中间多两头少的分布,例如一群人的身高或体重。
当
μ
=
1
,
σ
2
=
1
\mu=1, \sigma^{2}=1
μ=1,σ2=1时, 便成为
f
(
x
)
=
e
−
x
2
/
2
/
2
π
f(x)=\mathrm{e}^{-x^{2} / 2} / \sqrt{2 \pi}
f(x)=e−x2/2/2π
它是正态分布
N
(
0
,
1
)
N(0,1)
N(0,1)的密度函数. 其密度函数和分布函数常分别记为
φ
(
x
)
\varphi(x)
φ(x)和
Φ
(
x
)
\Phi(x)
Φ(x),
若 X ∼ N ( μ , σ 2 ) X \sim N\left(\mu, \sigma^{2}\right) X∼N(μ,σ2), 则 Y = ( X − μ ) / σ ∼ N ( 0 , 1 ) Y=(X-\mu) / \sigma \sim N(0,1) Y=(X−μ)/σ∼N(0,1)
指数分布
若随机变量
X
X
X的概率密度函数为
p
(
x
)
=
{
λ
e
−
λ
x
x
⩾
0
0
x
<
0
p(x)=\left\{\begin{array}{ll} \lambda e^{-\lambda x} & x \geqslant 0 \\ 0 & x<0 \end{array}\right.
p(x)={λe−λx0x⩾0x<0
其中
λ
>
0
\lambda>0
λ>0为常数, 则称
X
X
X服从参数为
λ
\lambda
λ的指数分布, 记为
X
∼
E
(
λ
)
X \sim E(\lambda)
X∼E(λ)。
X
X
X的分布函数为
F
(
x
)
=
{
1
−
e
−
λ
x
x
⩾
0
0
其他
F(x)=\left\{\begin{array}{cc} 1-e^{-\lambda x} & x \geqslant 0 \\ 0 & \text { 其他 } \end{array}\right.
F(x)={1−e−λx0x⩾0 其他
该分布的现实意义为一批无老化元件的寿命。“无老化”.就是说:“元件在时刻
x
x
x尚 能正常工作的条件下,其失效率总保持为某个常数
λ
>
0
\lambda>0
λ>0, 与
x
x
x无关”.
威布尔分布
元件无老化在现实中是不可能的。失效率 p p p应取为一个 x x x的增函数,例如 λ x m \lambda x^{m} λxm
此时便得到威布尔分布。
其分布函数为
F
(
x
)
=
1
−
e
−
(
λ
/
m
+
1
)
x
n
+
1
F(x)=1-\mathrm{e}^{-(\lambda / m+1) x^{n+1}}
F(x)=1−e−(λ/m+1)xn+1
取
α
=
m
+
1
(
α
>
1
)
\alpha=m+1(\alpha>1)
α=m+1(α>1), 并把
λ
/
(
m
+
1
)
\lambda /(m+1)
λ/(m+1)记为
λ
\lambda
λ, 得出
F
(
x
)
=
1
−
e
−
λ
x
n
,
x
>
0
F(x)=1-\mathrm{e}^{-\lambda x^{n}}, x>0
F(x)=1−e−λxn,x>0
而 F ( x ) = 0 F(x)=0 F(x)=0当 x ⩽ 0 x \leqslant 0 x⩽0. 此分布之密度函数为
f ( x ) = { λ a x a − 1 e − λ x a , x > 0 0 , x ⩽ 0 f(x)=\left\{\begin{array}{lr} \lambda a x^{a-1} \mathrm{e}^{-\lambda x^{a}}, & x>0 \\ 0, & x \leqslant 0 \end{array}\right. f(x)={λaxa−1e−λxa,0,x>0x⩽0















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









