







给出如上一个打分矩阵R(5,4),“——”表示未打分,
n行m列,n表示user个数,m表示item个数
问题是:如何得到未打分的商品进行有效的预测?
——矩阵分解的思想可以解决这个问题,其实这种思想可以看作是有监督的机器学习问题(回归问题)
矩阵R可以近似表示为P与Q的乘积:R(n,m)≈ P(n,K)*Q(K,m)
将原始的评分矩阵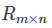 分解成两个矩阵
分解成两个矩阵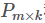 和
和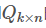 的乘积:
的乘积: 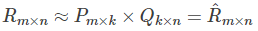
n,k表示n个user和k个特征值间的关系矩阵 Q(k,m)表示m个item和k个特征值间的关系矩阵 现在就是求矩阵 Q ,P
最终推导结果为:

代码:
#矩阵分解在打分预估系统中得到了成熟的发展和应用 # from pylab import * import matplotlib.pyplot as plt from math import pow import numpy def matrix_factorization(R,P,Q,K,steps=5000,alpha=0.0002,beta=0.02): Q=Q.T # .T操作表示矩阵的转置 result=[] for step in range(steps): #bushu for i in range(len(R)): #N for j in range(len(R[0])): #M if R[i][j]>0: #非负项 eij=R[i][j]-numpy.dot(P[i,:],Q[:,j]) # .dot(P,Q) 表示矩阵内积 for k in range(K): P[i][k]=P[i][k]+alpha*(2*eij*Q[k][j]-beta*P[i][k]) Q[k][j]=Q[k][j]+alpha*(2*eij*P[i][k]-beta*Q[k][j]) eR=numpy.dot(P,Q) e=0 for i in range(len(R)): for j in range(len(R[0])): if R[i][j]>0: e=e+pow(R[i][j]-numpy.dot(P[i,:],Q[:,j]),2) for k in range(K): e=e+(beta/2)*(pow(P[i][k],2)+pow(Q[k][j],2)) result.append(e) #把新生成的e加到原来的e中 if e<0.001: break return P,Q.T,result if __name__ == '__main__': R=[ [5,3,0,1], [4,0,0,1], [1,1,0,5], [1,0,0,4], [0,1,5,4] ] R=numpy.array(R) N=len(R) M=len(R[0]) K=2 P=numpy.random.rand(N,K) #随机生成一个 N行 K列的矩阵 Q=numpy.random.rand(M,K) #随机生成一个 M行 K列的矩阵 nP,nQ,result=matrix_factorization(R,P,Q,K) print("原始的评分矩阵R为:\n",R) R_MF=numpy.dot(nP,nQ.T) print("经过MF算法填充0处评分值后的评分矩阵R_MF为:\n",R_MF) # print(result[4999]) #-------------损失函数的收敛曲线图--------------- n=len(result) x=range(n) plt.plot(x,result,color='b',linewidth=6) plt.title("Convergence curve") plt.xlabel("generation") plt.ylabel("loss") plt.show()















 398
398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









