






背景
在矩阵分解出现之前,推荐系统领域主要的应用为协同过滤。当然,当今协同过滤仍然是推荐系统中影响力最大和应用最广泛的模型。但是协同过滤有一个天然的缺陷,就是其对稀疏数据的处理比较弱,头部效应比较明显,泛化能力比较差。
简单的来说,以Netflix为例,协同过滤就是尽可能的找到和你相似的用户,将他们喜欢的电影推荐给你。这里面的问题就是,如果一个电影虽然很符合你的兴趣,但是你的朋友却很少有评价或观看过,那么协同过滤就很难将这个电影推荐给你,因为没有评价就不确定这个电影与你看过的电影是否有很近的相似度。那么矩阵分解的出现,很好的解决了协同过滤存在的问题,同时也在近15年无论是工业还是学术上,都占据着举足轻重的地位。
矩阵分解的提出其实是数学上的发展,SVD分解法(奇异值分解)在很久之前就被广泛应用于数学领域,但是真正开始对于推荐系统推荐系统产生影响,源自于2006年Simon Funk的一篇博客,而他的方法也被Netflix Prize的冠军Koren称为Latent Factor Model 隐语义模型(LFM),也有很多人叫它为Funk-SVD。但是其实隐语义模型是个很大的领域,我们这里所讲到矩阵分解也只是隐语义模型比较重要的一部分。这篇文章还是能找到,我将它放在这里。有兴趣的朋友可以仔细的读一遍。
Try This at Homesifter.org/~simon/journal/20061211.html正在上传…重新上传取消
矩阵分解的原理
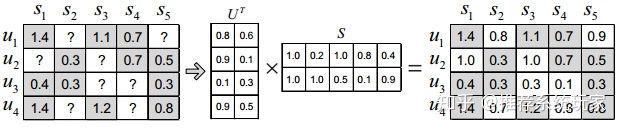
首先来概括的说下矩阵分解的原理。 上图中每一行u代表每个用户,每一列s代表每个物品,矩阵中的数字代表着用户对物品的打分。?代表着用户没有给这个物品打过分。在实际数据中,我们通过数据构建的矩阵如上图一样并不是一个满秩的矩阵。在Netflix真实的数据集里,矩阵的稠密度仅有3%左右。那么就意味着,矩阵中有绝大部分的评分是空白的。如何得到这些空白的评分呢?矩阵分解的就是为了解决这个问题。
矩阵分解算法将 m×n 维的矩阵R分解为 m×k 的用户矩阵 U 和 k×n 维的物品矩阵 S 相乘的形式。其中, m 为用户的数量,n为物品的数量,k为隐向量(Latent Factor)的维度。 k 的大小决定了隐向量表达能力的强弱,实际应用中,其取值要经过多次的实验来确定。在得到了 用户矩阵U和物品矩阵 S 后,将两个矩阵相乘,就可以得到一个满秩的矩阵。那么,我们就对未被评价过的物品,有了一个预测评分。接下来,可以将评分进行排序,推荐给用户。这就是矩阵分解对于推荐系统最基本的用途。
用大白话总结一下,矩阵分解的目的就是通过分解之后的两矩阵内积,来填补缺失的数据,用来做预测评分。矩阵分解的核心是将矩阵分解为两个低秩的矩阵的乘积,分别以 k维的隐因子向量表示,用户向量和物品向量的内积则是用户对物品的偏好度,即预测评分。值得注意的是k的选取是通过实验和经验而来的,因此矩阵分解的可解释性不强。
矩阵分解的方法以及发展历程
矩阵分解基本的方法有三种:
- 特征值分解(Eigendecomposition)
- 奇异值分解SVD(Singular Value Decomposition)
- Funk - SVD (Simon Funk SVD)
查过很多资料,矩阵分解的方法真的太多太多。看过王喆的《深度学习推荐系统》,他将梯度下降作为第三种。我个人觉得将梯度下降作为矩阵分解的方法之一让我感到非常的困惑。因为在我的理解里,梯度下降(Gradient Descent)是如何求解矩阵的方法。也就是说,以上三种是矩阵分解的方法,而如何求分解的结果,即矩阵求解,我们用的是梯度下降法,最小二乘法等等。
这方面的概念在各种书籍和知乎上也非常模糊,因为研究者并没有严谨的在术语上区分。我个人认为这是因为这方面的概念涉及数学,计算机等多个领域,很难进行清晰的划分。很多材料上,Funk-SVD和奇异值分解都叫做SVD,而有些教材将Funk-SVD就叫做矩阵分解。而其实矩阵分解是隐语义模型(LFM)的重要分支。隐语义模型(LFM)包括了隐含类别模型(latent class model)、隐含主题模型(latent topic model)、矩阵分解(matrix factorization)等。其中,矩阵分解包括特征值分解,Funk-SVD和SVD。同时Funk - SVD 是SVD加入线性回归思想的改进版本。名字的不明确以及分类的不清晰会给刚开始学习推荐系统的朋友们造成很大的困扰。因此,我很清晰的列出了以上三种。如果有不对的地方,或者有朋友有更清晰的框架,也希望及时告诉我。
下面我们来看下这三种方法原理以及在推荐系统中的应用:
1.特征值分解
A 为n阶矩阵,若数 λ 和n维非0列向量 v→ 满足 Av→=λv→ ,那么数 λ 称为 A 的特征值, v→ 称为 A 的对应于特征值 λ 的特征向量。
简单的可以理解为, λ 为矩阵变换的大小, v→ 为矩阵变换的方向。
需要强调的是,特征值只能作用于方阵,因此对于我们推荐系统用户-物品的矩阵不太合适。而特征值分解在PCA(主成分分析)中进行降维或人脸识别中运用却非常广泛,我们会在相关的文章里详细说。
这里有个非常具象化的的视频来理解特征值和特征向量:
推荐系统玩家 之 特征向量与特征值_哔哩哔哩 (゜-゜)つロ 干杯~-bilibiliwww.bilibili.com/video/BV1yi4y1s7jV/正在上传…重新上传取消
那么有没有一个方法可以不仅限于方阵的分解呢?
2.奇异值分解
假设一个矩阵 M 是一个 m×n 的矩阵,则一定存在一个分解 :
M=UΣVT
其中 U 是 m×m 的正交矩阵, V 是 n×n 的正交矩阵, Σ是 m×n 的对角矩阵。 Σ 对角线上的元素就称为 M 的奇异值。
https://blog.csdn.net/u012037852/article/details/81274340
我们以一个例子来看看奇异值在推荐系统以及机器学习中的应用:

由上图可知,矩阵A为 6×4 的用户评分矩阵,6个用户对4个物品有一共19个评分。0代表没有给过评分。接着,我们用SVD进行分解可得:



分解后, U 矩阵为 6×6 的正交矩阵, V 为 4×4 的正交矩阵。 S 则为对角矩阵即公式中的 Σ 。那么,我们选取 S 中较大的 k 个元素作为隐含特征。删除 S 的其他维度以及 U 和 V 对应的维度,至此,矩阵分解就完成了。
这里为什么要从对角矩阵中选 k 个元素呢?因为,对角阵有一个特殊的性质,它的所有元素都非负,且依次减小。这个减小也特别快,在很多情况下,前10%的和就占了全部元素之和的99%以上,也就是说我们可以使用最大的 k 个值和对应大小的 U 、 V 矩阵来近似描述原始的评分矩阵。这就是SVD做降维用法的核心思想。 我们在这里选择 k=2,那么S 对角矩阵就降维成:

同样的, U 矩阵变成了 6×2 维, V 矩阵变成了 4×2 维。
SVD的降维效果又是怎样体现出来的呢?我们将处理过的 USV 三个矩阵相乘做内积,可以得到一个新的 6×4 的矩阵 A′ :

经过SVD降维后的矩阵A'
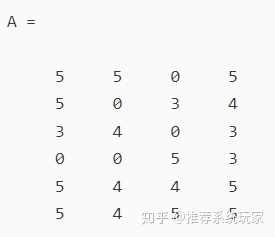
SVD降维前的矩阵A
由此我们可以非常清晰的看出矩阵 A 和矩阵 A′ 数据很接近,同时又对空白评分进行了填充。以上就是SVD分解的意义,同时可以延伸应用在数据有损压缩以及图像处理,以及主成分分析(PCA)中。
需要注意的是,SVD的降维不体现在内积回乘上。这也是我最开始不理解的地方。很多人问,内积乘回来的矩阵和原始矩阵一样大,哪里降维了?
举个例子,若原始矩阵是 60×40=2400 的数据量。SVD分解后,当 k =10时, U 矩阵为 60×10 = 600 的数据量, S 对角矩阵为 10×10=100 数据量, V 矩阵为 40×10 = 400 的数据量。那么分解后的数据量为 600+100+400 = 1100 的数据量。而这 1100 的数据量足以拟合原矩阵 2400 的数据量。这就是降维的精髓所在。
然而SVD虽然解决了特征值分解只能用于方阵的问题,但是SVD同样也有缺点。
- SVD 需要原始的共现矩阵是稠密的。如果矩阵非常稀疏,求出奇异值的效果就会很差。而在推荐系统的场景中,很少有数据稠密的状态,这就使得奇异值分解在应用前需要进行数据填充。
- 传统的SVD的在求奇异值时,计算复杂度非常的高。
那么,有没有一个模型可以解决数据稀疏的问题呢?
3. Funk - SVD
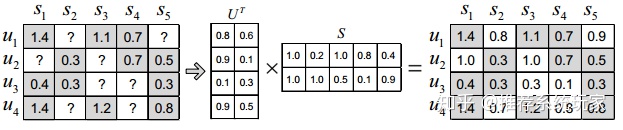
Mm×n=Um×kTSk×n
Funk-SVD是我最开始接触的矩阵分解的方法,也是我在推荐系统中运用最多的方法。Funk-SVD提出是因为SVD在分解成三个矩阵的时候非常的耗时同时空间复杂度也很高,在面对稀疏数据时,SVD无法进行分解。而Funk-SVD完美的解决了SVD的不足,它仅将矩阵分解为两个矩阵,分解的目标是让分解后的两个矩阵乘积得到的评分矩阵和原始矩阵更拟合,也就是说与原始评分的残差最小。
细看这个矩阵 M ,对于每个用户 i 和物品 j 我们都有一个评分 ,ri,j,就是原始矩阵种有评分的位置。当我们进行分解后,对于每个评分 r 我们都可以用分解后的向量 r^= qjTpi 来近似。我们的目标就是 r^→r ,也就是让()r−r^=(ri,j−pjTqi) 尽可能的小。在这里我们选择均方差作为损失函数:
Loss=argmin∑i,j(ri,j−qjTpi)2
为了防止过拟合,我们加入正则化项:
Loss=argmin∑i,j(ri,j−qjTpi)2+(||pi||+||qj||)2
那么如何来拟合原始矩阵呢?这就涉及到一个非常家喻户晓的方法,也就是梯度下降法。(我们不再这里展开讲梯度下降法,因为梯度下降法包含了很多原理和公式,我们将在下一篇详细讲解。)
至此,这就是Funk-SVD的原理。其解决了SVD在稀疏数据下不能工作的缺点。同时有很高的精度,也可以离线进行计算,并且具有很好的扩展性,在其方法上衍生出了很多优秀的算法例如SVD++等等。那么Funk-SVD就没有劣势么?答案显然不是。Funk-SVD由于需要迭代优化损失函数,因此其训练过程比较耗时,同时推荐结果不具有很好的可解释性。
以上就是矩阵分解在推荐系统中的基本方法。推荐算法从1992年发展至今已经有了28个年头,从最开始的协同过滤,到矩阵分解,再到现在的深度学习。推荐系统一直促进着人类的信息发展同时也催生出了像头条,阿里,美团这样的科技公司。我希望我在未来的时间里,能够继续深入推荐系统,同时也希望和大家进行讨论。如果文章中有错误或者不清楚的地方,希望大家能及时予以指正。














 3929
3929











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









