






从这一节开始开始我们正式开始学习 SD (Stable Diffusion)
第一节我们从 Web UI 开始讲解
基于使用最多的 文生图 模块来讲解
一、WEB UI 页面
如果你使用是SD,
那么你进入到 web ui 页面后可以看到下面这个页面
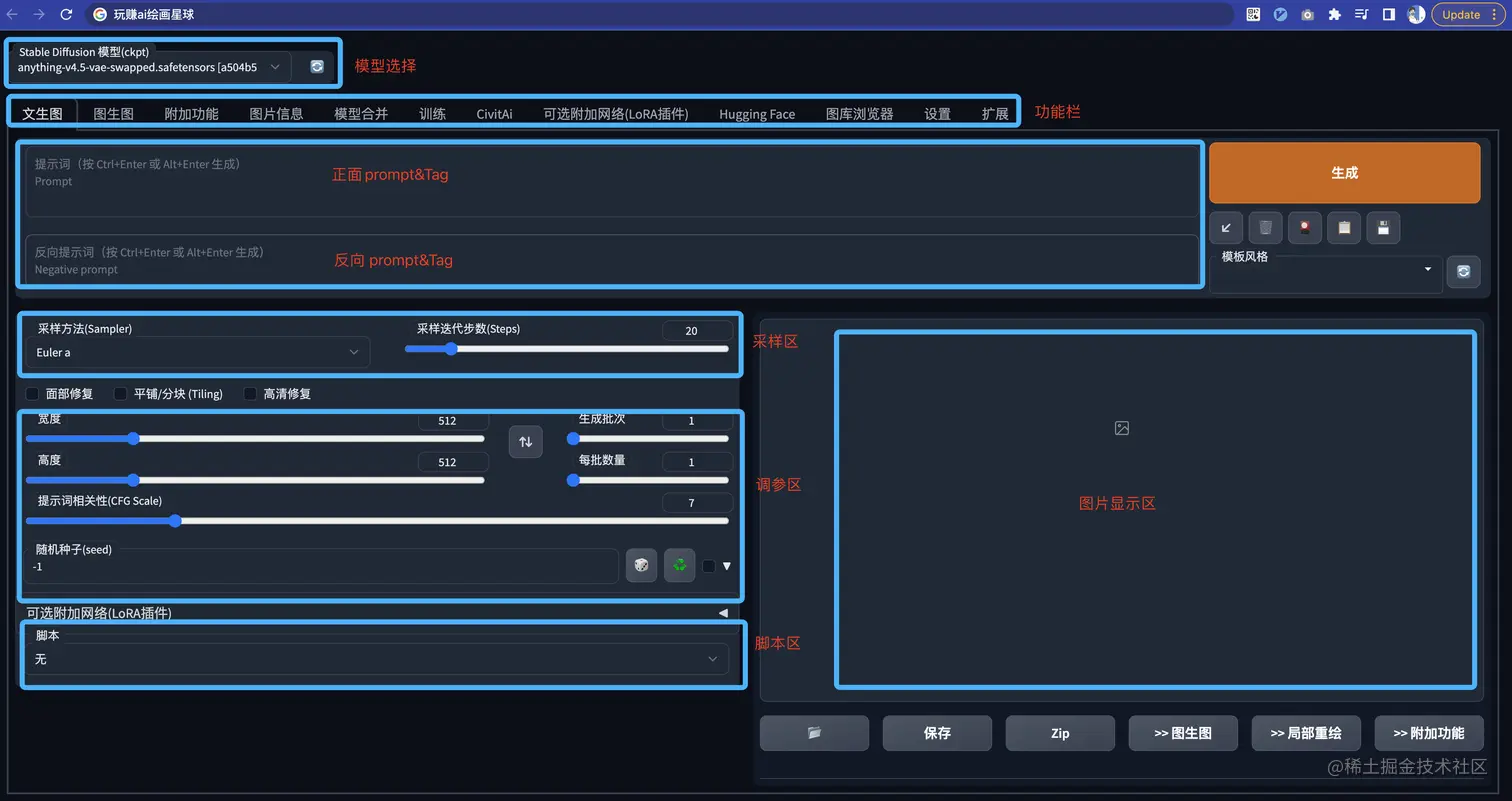
其中:
- 模型选择: 模型对于 SD 绘图来说非常重要,不同的模型类型、质量会很大程度的决定最终的出图效果(模型相关的课程会在后面细讲)
- Prompt区: 如果你使用过 ChatGPT 你应该知道 Prompt 是什么。说的直白点就是你想让 SD 帮忙生成什么样的图,反向 Prompt 就是你不想让 SD 出生的图里有这些东西。后续课程也会详细的讲解如何更好的编写 Prompt
- 功能栏: 包括了常见的 文生图、图生图、模型获取、模型训练等功能。不同的功能页面也不同,这一节课,我们先针对最长使用的 文生图 模块页面来讲解
- 采样区: 采用什么样的绘画方式算法,以及“画多少笔” 来绘图。一定程度上决定出图的质量
- 调参区: 设置分辨率、每次出图的批次、出图抽象性(和 prompt 关联性的程度)
- 脚本区: 通过配置脚本可以提高效率;比如批量出图、多参数的出图效果比较(课程中会大量使用)
接下来会进一步的介绍每个模块的使用。
二、模型选择
直白点说,
模型就是“模型训练师”们通过大量的图片进行训练得到的具备某种风格的模型。
我们使用某个模型后,
后续在出图的整体方向就会更靠近这个模型的风格。
你安装好之后默认可以看到两个模型
- anything : 二次元风格模型
- Deliberate:真人风格模型
三、Prompt 区
如果你学习过如何更好的编写 ChatGPT 的 prompt,
你会发现 Prompt 的编写都会遵守一定的范式,
这样得出来的效果才可能更贴近我们的想法。
选择完模型之后,
我们就可以给予这个模型风格,
告诉 SD prompt 画出什么样的图。
比如:直接告诉 SD 画一个女孩
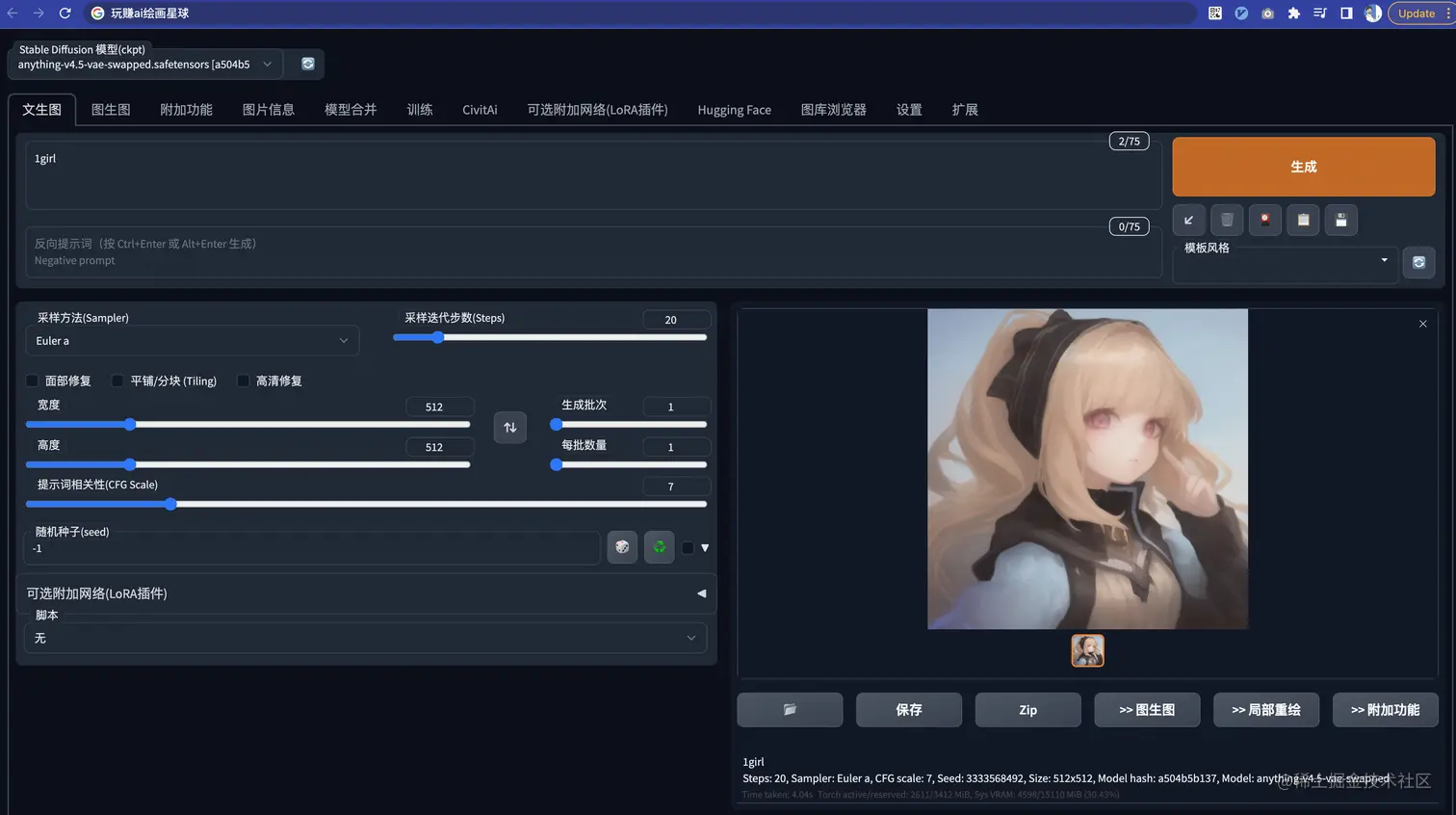
虽然能出来一个 女孩,
emmm… 但是这个质量吧,还是很差的,
实事上呢,
是我们的 prompt 写的太差劲了 导致的
如果我们完善一点 (丰富一些 prompt )
会发现效果质量立竿见影;而我们只是加入了一些通用的 prompt 提示语
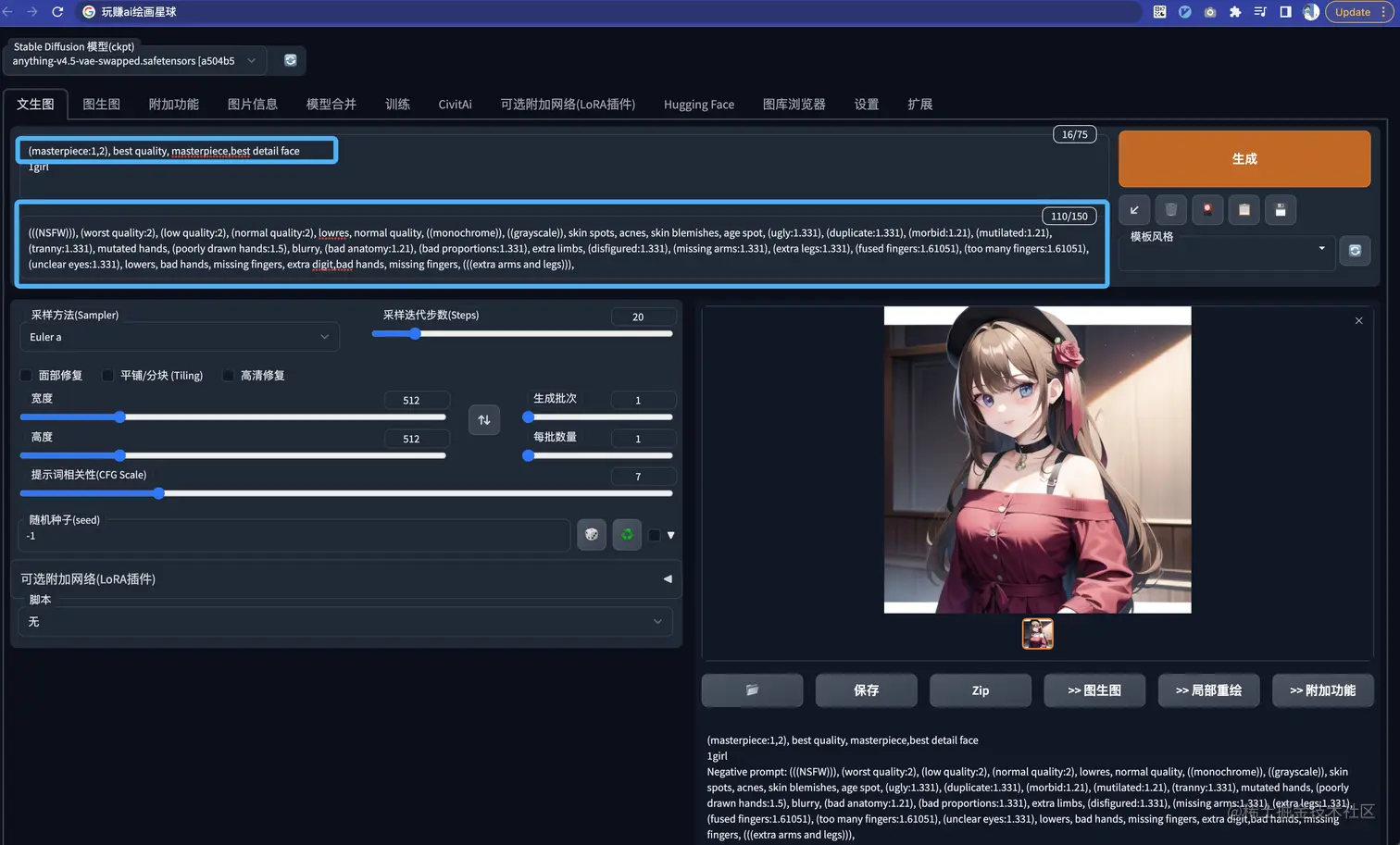
- 正向的 prompt: 说白就是要高画质、更多的细节
(masterpiece:1,2), best quality, masterpiece,best detail face
- 反向的 prompt: 不要少胳膊断腿,要是一个正常的图
(((NSFW))), (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
其中的一些细节,
比如 提示语的语法格式、公式、权重、模版和tag大全,我们会在 prompt 和 tag 课程中细讲。
有个比较有意思的 反向 tag 叫 NSFW(no sutiable for work)
一般情况尽量把这个加入到反向词中,特别是工作场合。不然惊喜可能随时都会出现(各种18+)…
想想在工作的时候,你信誓旦旦给你的同事来一张漂亮的小姐姐,结果…
如果你不太信的话,可以直接把 NSFW 放在正向里面试试…
四、采样区
采样区做的事就是,我们该用什么样的采样方式来画,画多少笔(多细致)
1.采样方式
由于采样方式的原理比较深奥,涉及到很多的算法,我直接给结论,
我更加推荐使用下面这三个:
- Euler a
- DDIM
- DPM ++ 2M Karras
我们可以试试这三个不同采样方法的效果

整体的质量是非常好的,出图速度相对也会快很多
2. 采样步数
采样步数相当于是作画的时候画多少笔。
同样的也是先给结论,建议在 20-40之间,出图效果会更好。并不是越高越好
来看看效果

会发现步数到了60其实也还好,
但同时需要考虑到性价比,步数越高也就意味着耗费的资源会越多,对机器的配置会更高。
所以一般我们的步数设置到 20-40之间就可以了。
接着上节课,我们继续讲解 Stable Diffusion Web UI 的使用。
这节课我们会讲解 面部修复,高清修复和调参区的内容
五、脸部修复
面部修复的适用在画真人、三次元的场景,特别是在画全身的时候
一般在画全身,由于脸部占比的空间比较小,那么绘制出来的效果就会比较差
1.面部修复
SD 支持直接一键进行脸部修复,但这效果可能不是非常好,也不是最终方案
举个例子:
模型选择:Realistic Vision V2.0 (如何下载模型可以参照课程
在没有开启面部修复的情况,脸部非常不自然(特别是在画全身的时候)

开启面部修复后:
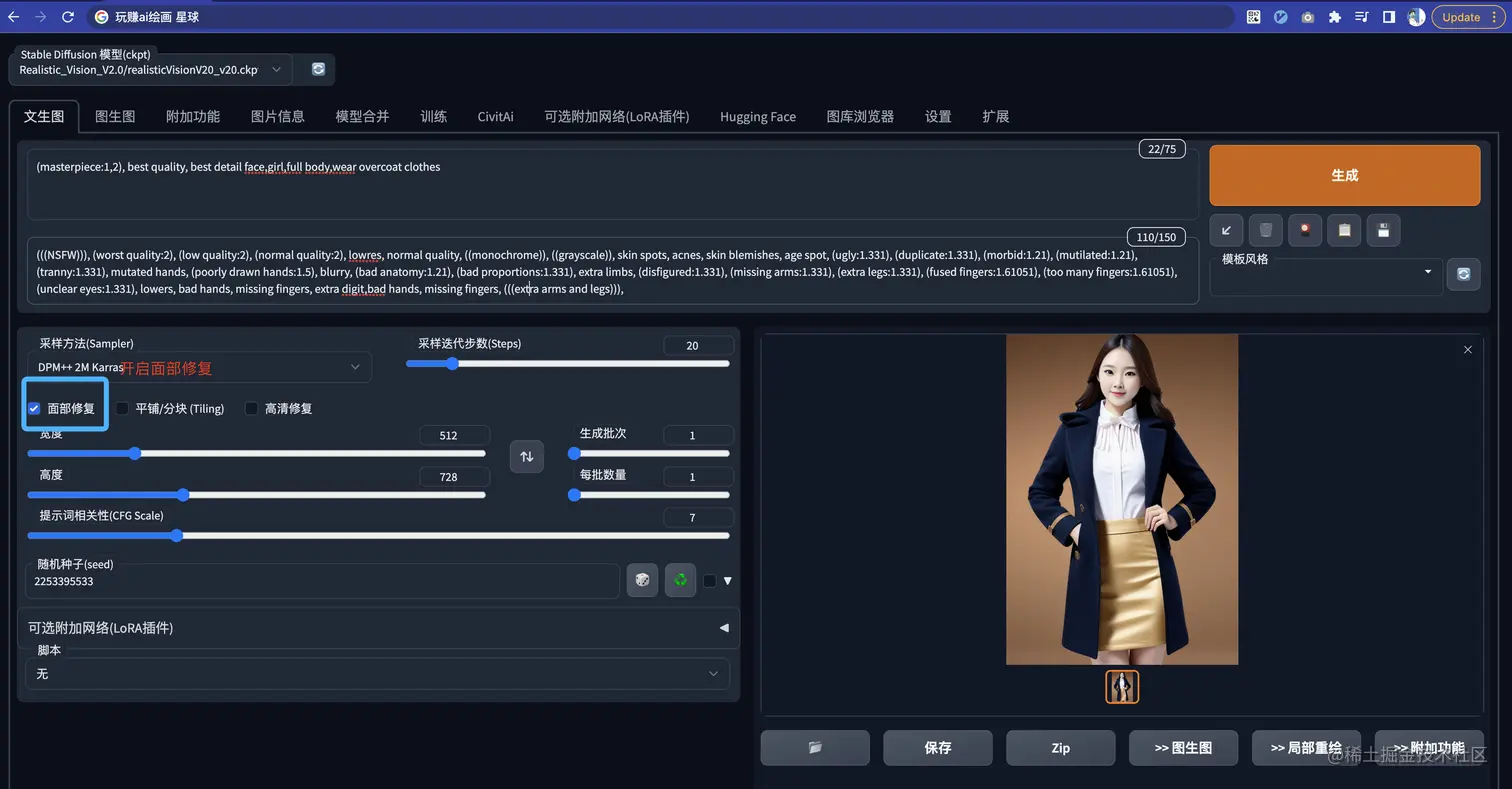
出图的效果,脸部就自然了非常多

2.高清修复
高清修复的原理相当于是把原分辨率的图放大进行绘制,
绘制结束后再做一个还原,从而达到脸部的优化。
这样对于电脑的资源消耗会更大。
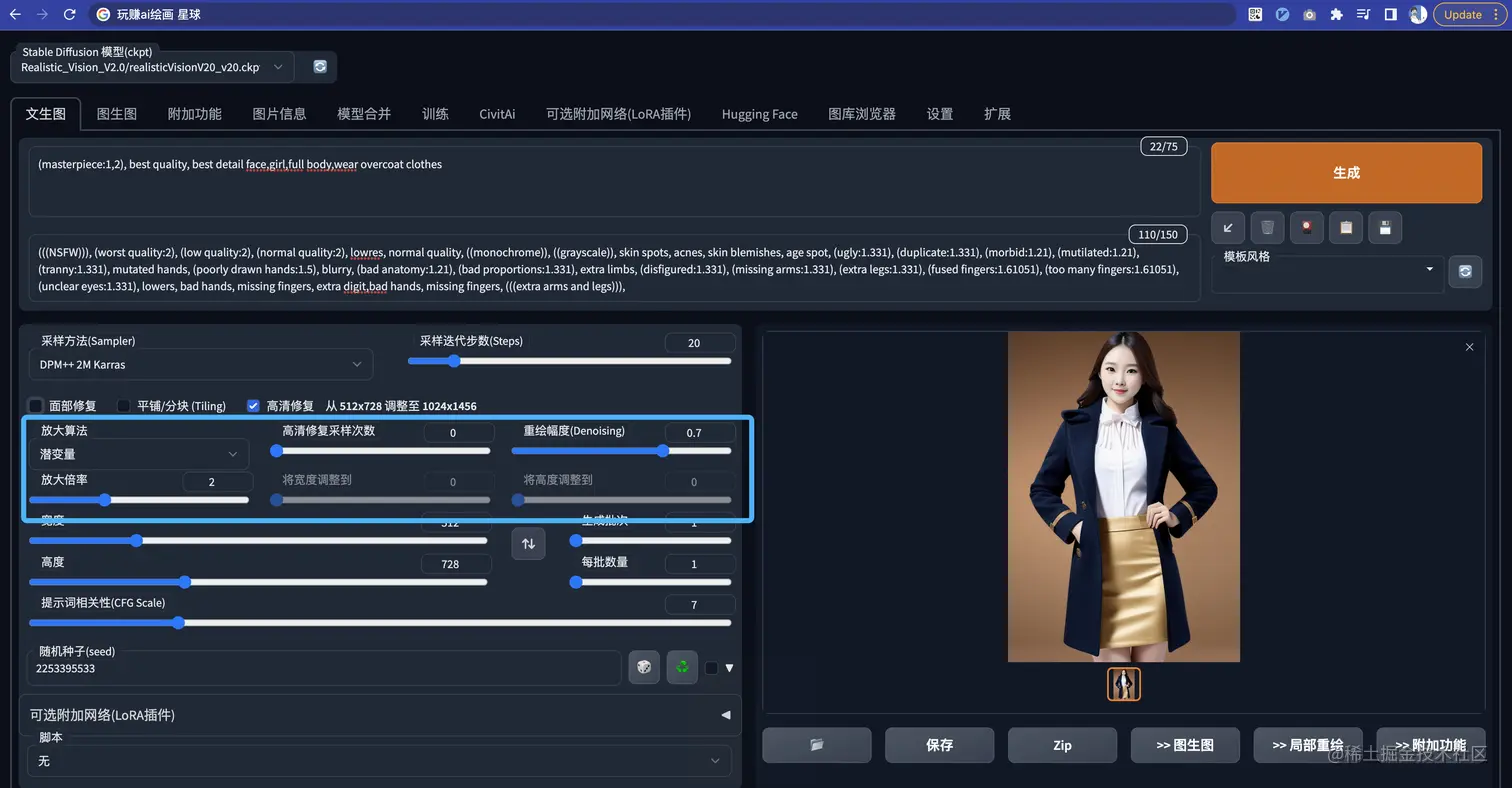
其中有几个参数可以来说说:
- 放大算法: 这块可以直接给结论;大家如果要改善真人、三次元的脸部直接使用 R-ESRGAN 4x+ ;如果是二次元的使用 R-ESRGAN 4x+ Anime6B
- 高清修复采样次数: 建议直接给0,表示直接使用原有出图的采样步数即可
- 重绘幅度(Denoising): “放飞程度“,在修复的时候和原图的相似关系,越小表示越相似,越大最后的图就和原图没啥关系了
- 放大倍率: 一般给到2倍即可。太大基本上电脑配置吃不消
我们可以来看看使用高清修复后优化的样子:

耗时要远大于不修复的出图时间,
但是效果也是比普通的面部修复要好。
主要是可以根据自己的需要调节参数。
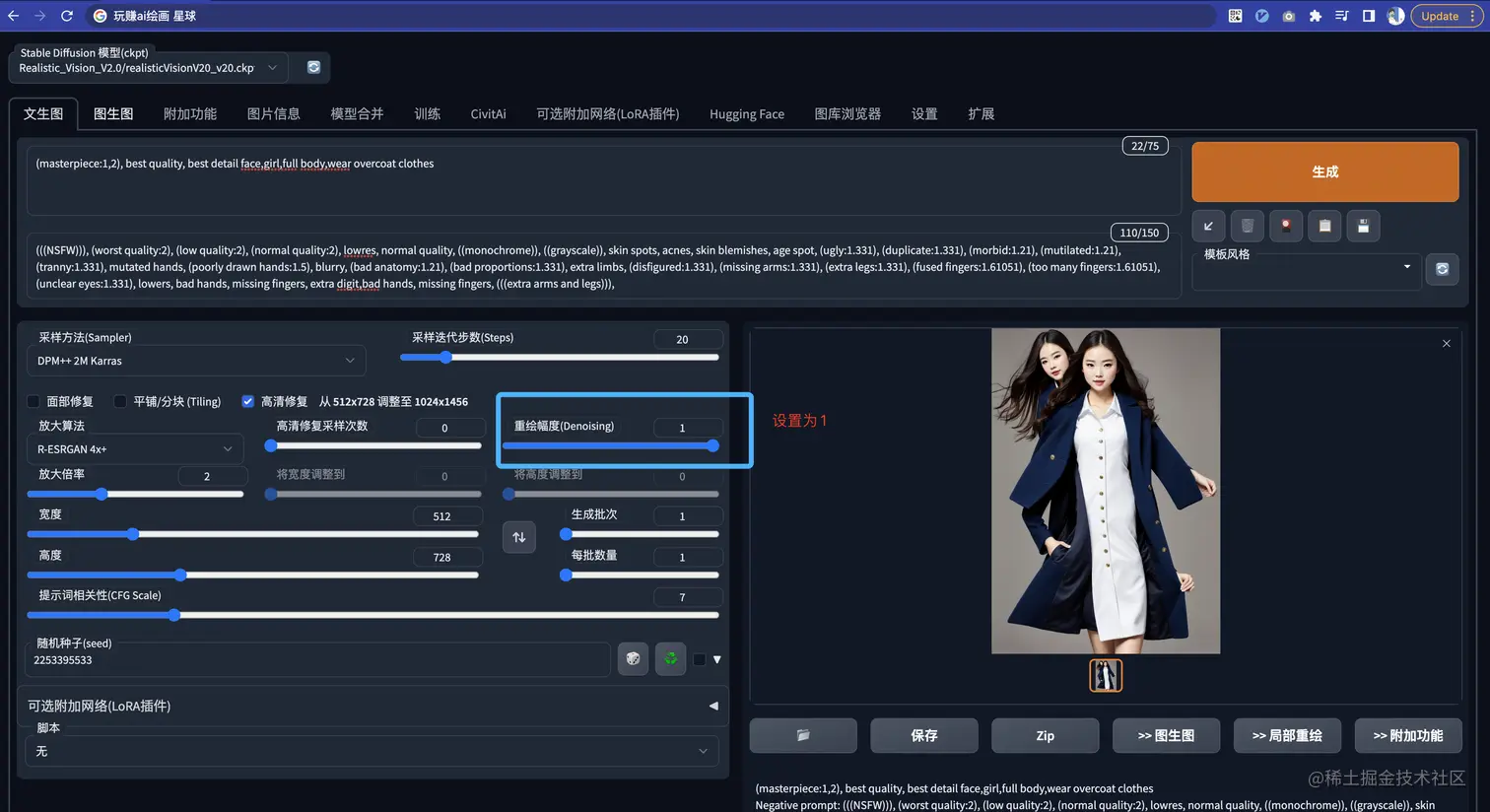
如果我们把重绘幅度拉满,
会发现和原图就不太像了,甚至会… Emmm…
六、调参区
前面讲到的模型决定了出图的大方向
Prompt 决定了最终的图是什么样
调参区 则决定了一次出多少张图,分辨率以及随机性
1.分辨率 高度&宽度
1.1 如何设置合适的大小
当我们默认进入 SD Web UI 页面后的默认高度和宽度就是 512*512.
这是因为综合各方面来说这个分辨率的性价比是最高的
- 在 SD 的最初模型 SD 1.5 训练的图片的分辨率大部分都是 512*512,所以在出图的时候,这个分辨率的效果也是最好的
- 基于性能的考量,512*512 可以比较好的满足质量的要求。对于机器的配置的要求也能适中。如果分辨率设置的比较大,那么电脑的显卡可能就会崩掉,导致SD报错
考虑到SD的最初模型几乎都是 512*512 ,
所以我们想要比较好的效果的时候,
至少应该要有个参数是在 512-768 之前,
这样出图的质量都可以得到保障。
设置的分辨率是:768*320
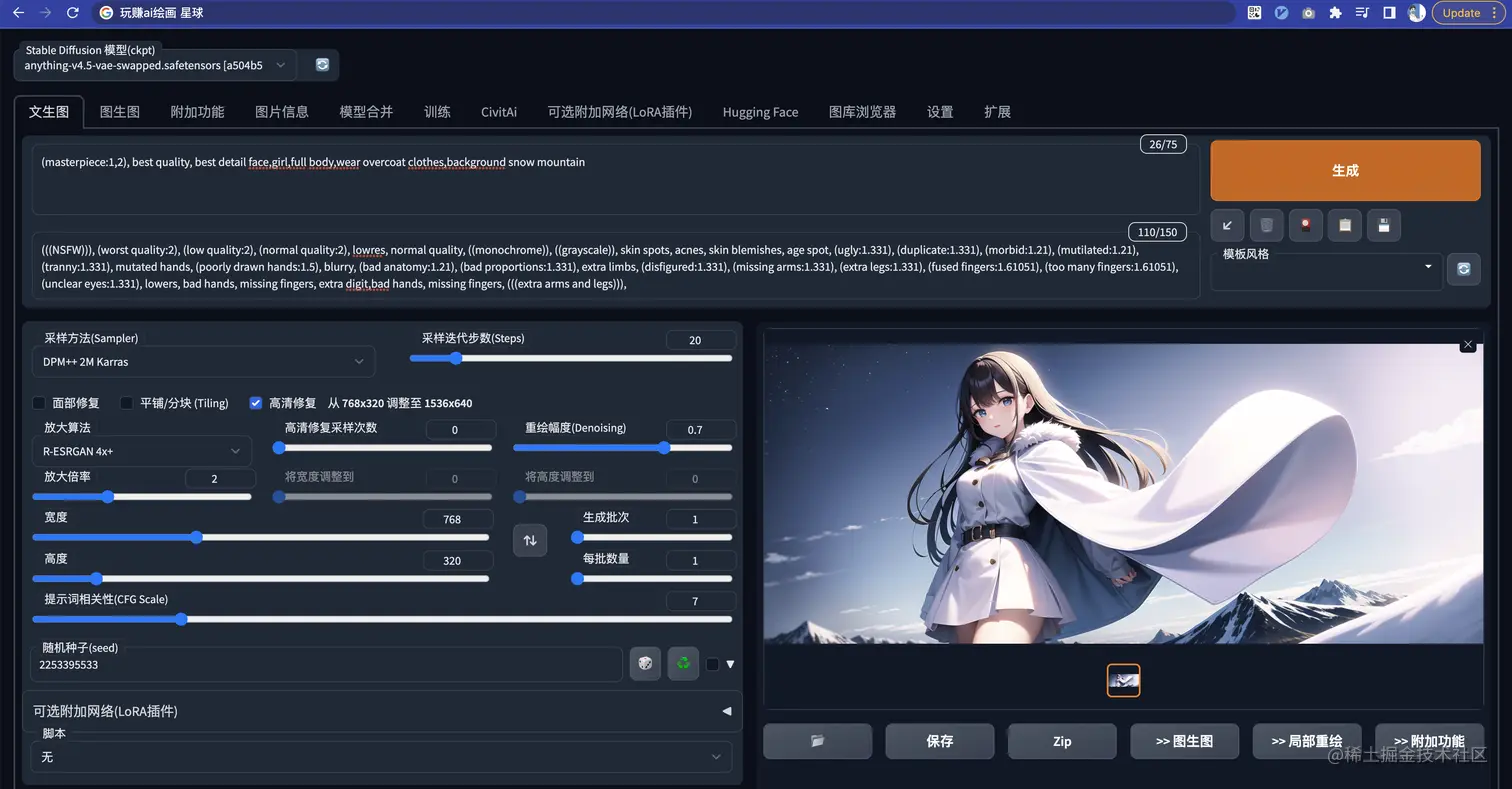

1.2.妙用画身体
我们可以来思考一个问题,如果画一个全身的人出来?
第一反应是不是就是在 prompt 里面提出来对吧?
加上 full body ,我们可以来看看效果

出来的效果空间感很差,
为了不出现拉伸的情况,SD 会自动的做一些裁剪。
所以,我们可以调整分辨率来实现画全身的场景
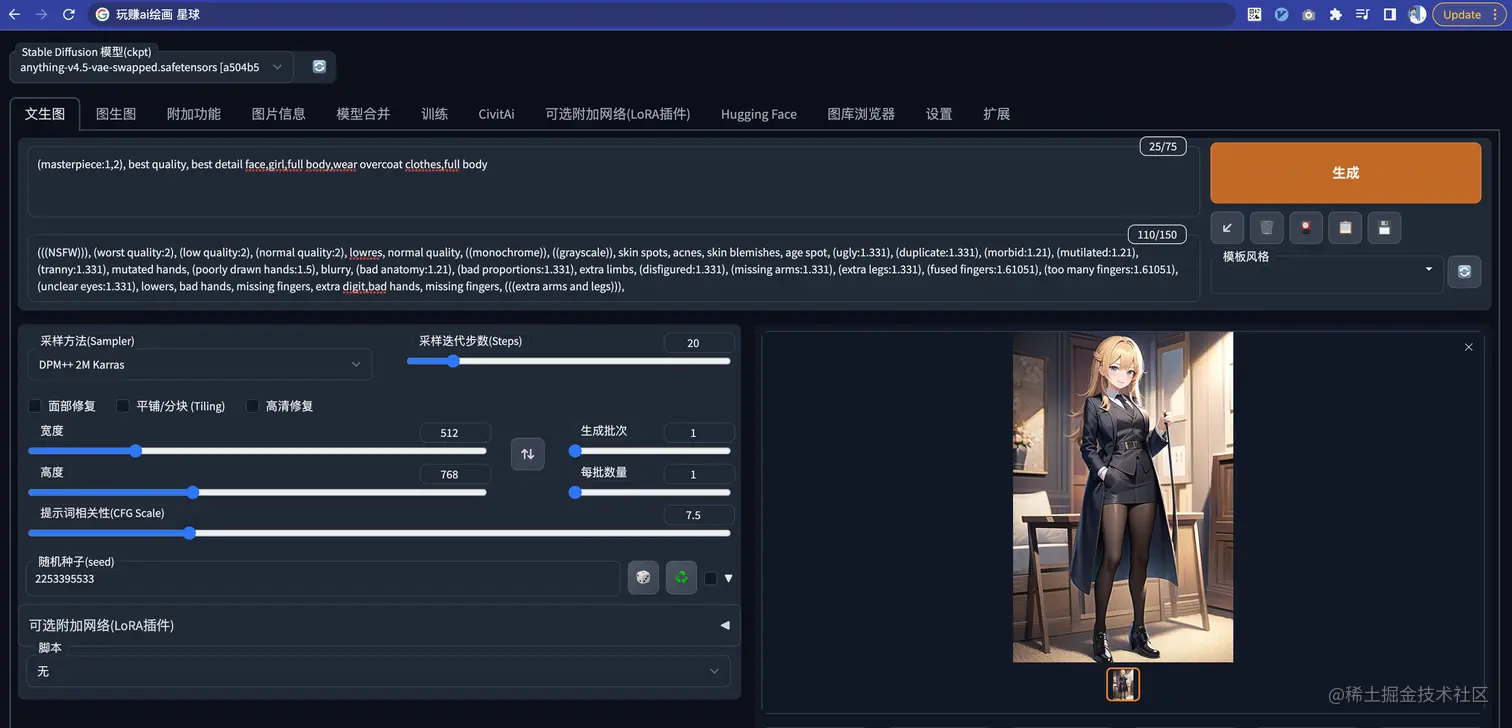

这个看起来是不是就非常完美了!
当想要画全身的时候可以考虑用这种方式。
当然了,细心的同学们会发现,手指还是有问题,我们后续会讲到如何优化!
2.批次VS每批数量
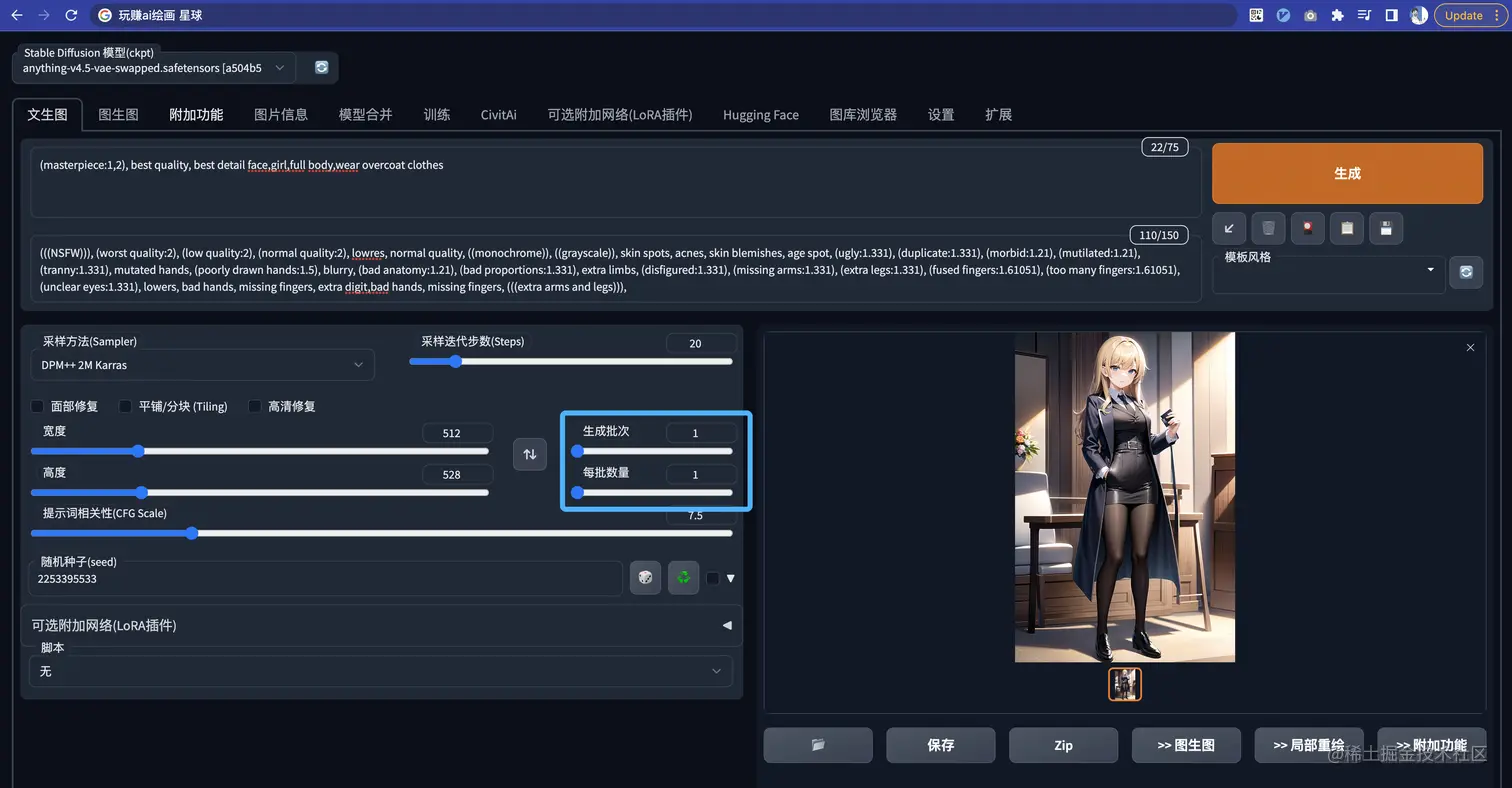
这个就很好理解了
(相当于有一个马路,生成批次决定了有几辆车按顺序通过,每批数量决定了有几个车道可以并行通过)
- 生成批次:可以理解成点击一次生成会循环生成多少个数量的图
- 每批数量:表示一个批次里一次生成多少张图(一批会有一个概览图)

那我们选择哪种方式批量出图呢?
如果你的配置比较高,那么可以使用 每批数量 的方式出图,会更快。
否则就加大批次,每一批生成一个
七、随机种子 DNA
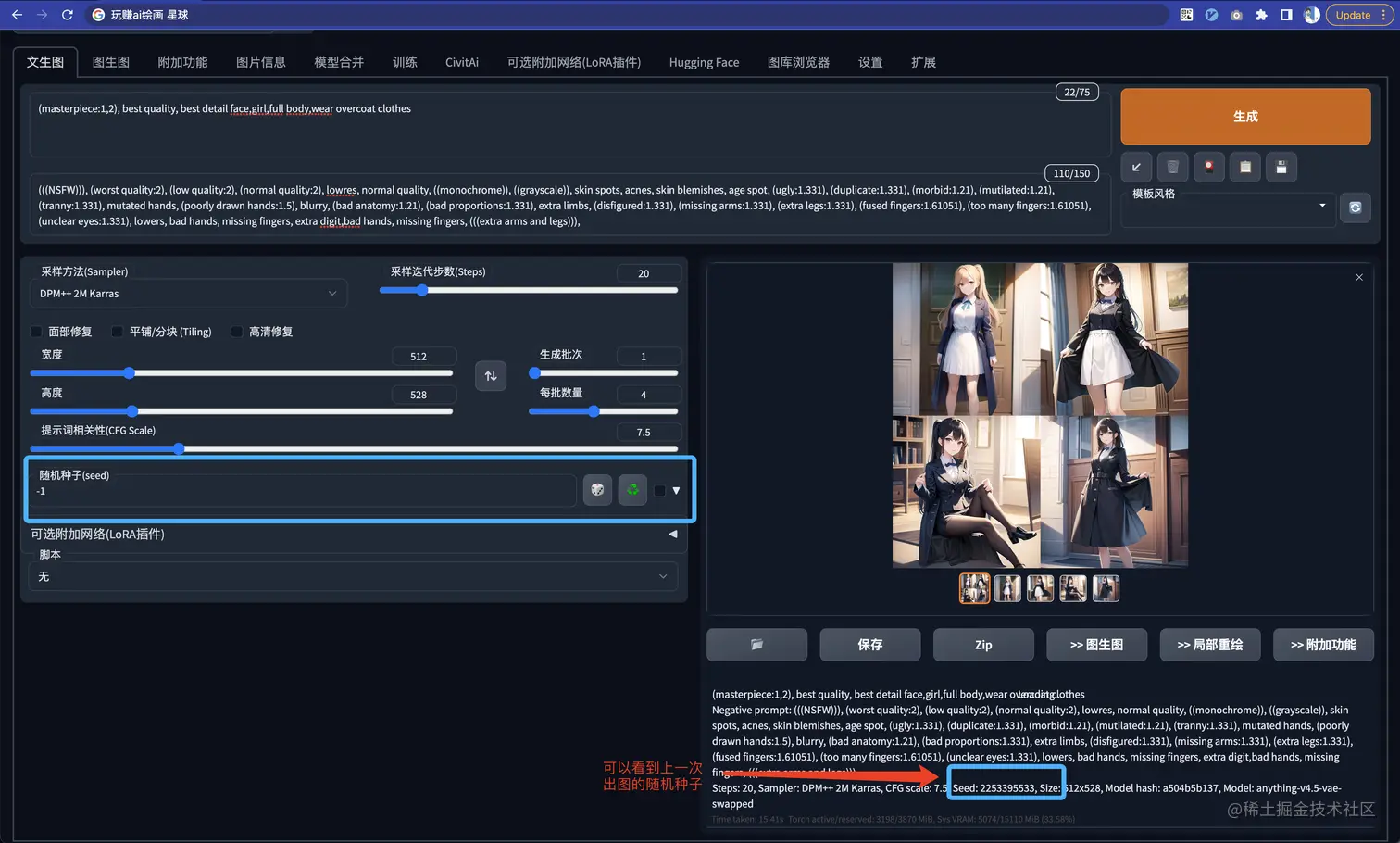
1.随机种子
可能会有同学发现前面我们出的图几乎都是一个样子。
只有细微的不同,这个就是固定了随机种子导致的。
默认随机种子的值是 -1,表示每次出图都会随机一个种子,根据这个种子进行出图。
如果我们想要固定某个形象,那么把对应种子的值填在这,那么每次出图的效果大致都会一样。
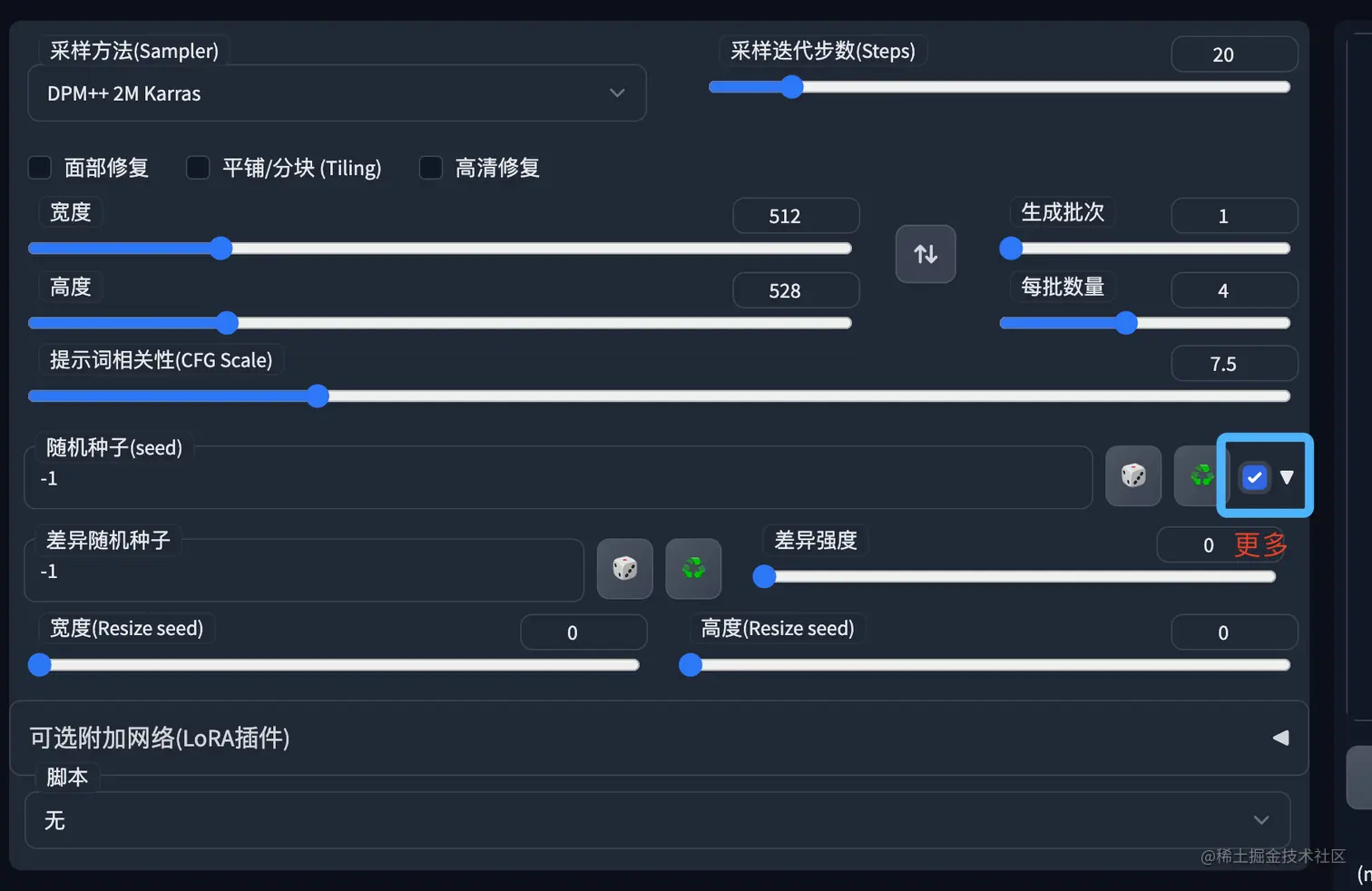
2.差异种子
如果我们点开更多,会发现还有更多参数
- 随机种子会和差异种子进行融合
- 差异强度:融合后的效果到底更偏向随机种子还是差异种子;如果是0,那么相当于没有设置差异种子;如果是1那么相当于是没有设置随机种子
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方添加,即可前往免费领取!


















 1568
1568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









