







原理: 利用多元线性回归模型根据多个因素预测客户价值,当模型搭建完成后,就可以对不同价值的客户采用不同的业务策略。
源码和数据下载链接见文章末尾链接。
目录:
- 1、案例背景
- 2、案例主要应用技术
- 3、案例数据
- 4、案例过程
- 4.1、导库
- 4.2、数据读取
- 4.3、数据探索
- 4.4、数据预处理
- 4.4.1、重复值处理
- 4.4.2、异常值处理
- 4.4.3、缺失值处理
- 4.5、特征工程
- 4.5.1、特征相关性分析
- 4.5.2、目标相关性分析
- 4.5.3、特征构造
- 4.6、模型搭建
- 4.6.1、构建特征值和目标值
- 4.6.2、划分训练和测试集
- 4.6.3、模型搭建
- 4.7、线性回归方程构造
- 4.8、模型评估
- 4.9、评估结果解读
- 5、案例数据结论
一、案例背景:
客户价值预测就是指客户未来一段时间能带来多少利润,其利润的来源可能来自于信用卡的年费、取现手续费、分期手续费、境外交易手续费用等。而分析出客户的价值后,在进行营销、电话接听、催收、产品咨询等各项服务时,就可以针对高价值的客户进行区别于普通客户的服务,有助于进一步挖掘这些高价值客户的价值,并提高这些高价值客户的忠诚度。
二、案例主要应用技术
本案例用到的主要技术包括:
- 数据建模: 线性回归模型LinearRegression
- 模型评估:statsmodels
- 模型可视化:matplotlib 、seaborn 画图
- 主要用到的库包括:pandas 和 Sklearn
本案例使用的开发工具是 jupyter notebook,故很多地方直接写对象,就能输出结果,不需要写print(),如果是在其他的编辑器,在输出时,需要加上print()。
三、案例数据
以下是数据概览:
特征变量数:5
数据记录数:128
是否有NA值:有
是否有异常值:有
以下是本数据集的5个特征变量,包括:
load_amount : 历史贷款金额,整数型变量。
loan_time :贷款次数,整数型变量。
edu:学历,分类型变量, 值域[高中, 本科,研究生]。
salary:薪水,整数型变量。
sex:性别,值域为男或女。
目标变量value :客户价值打分,整数型变量。
四、案例过程
4.1、导库
import pandas as pd # pandas库
from sklearn.preprocessing import LabelEncoder # 编号处理
from sklearn.model_selection import train_test_split # 划分训练集和测试集
from sklearn.linear_model import LinearRegression # LinearRegression 线性回归模型
import statsmodels.api as sm # 模型评估
import matplotlib.pyplot as plt # 画图
import seaborn as sns # 画图
plt.rcParams["font.sans-serif"]='SimHei' # 中文乱码
plt.rcParams['axes.unicode_minus']=False # 负号无法正常显示
%config InlineBackend.figure_format='svg' # 像素清晰
pandas:常用的数据读取、 展示、处理和数据保存库。
LabelEncoder :sklearn库中数据预处理的preprocessing 包下的整数编码类,用来将非数值对象转换为数值类型。
train_test_split :sklearn库中用来划分训练集和测试集的类。
LinearRegression:sklearn库中linear_model 包下面的线性回归类,用来建立线性回归模型。
statsmodels.api :引入线性回归模型评估相关库。
matplotlib.pyplot :引入matplotlib库进行模型可视化画图。
seaborn :引入seaborn 库进行可视化画图。
除了上述库以外,还需要关于使用pandas读Excel需要的附属库。如果之前没有安装过这个库, 需要在系统终端命令行窗口使用pip install xlrd 完成安装。这个库无需导入,在Pandas读取Excel时会自动调用。
用pip install xlwt
4.2、数据读取
df = pd.read_excel('Customer_value.xlsx')
4.3、数据探索
数据形状:
df.shape
打印输出:(128, 6)
shape方法用来查看当前数据的形状,返回一个二维的数据元祖,逗号前面的数值表示128行,逗号后面的数值表示6列。
数据类型:
df.info()
返回结果如下:

info方法用来查看数据的类型和缺失情况:
- 从整体看,数据总共有128条,范围是[0,127], 总共有6列。从具体字段看,value(客户价值)是整数型,共128条未缺失,缺失值为0。loan_amount(贷款金额)是整数型,共128条未缺失,缺失值为0。loan_time(贷款次数)是整数型,共128条未缺失,缺失值为0。edu(教育程度)是object对象,需要处理成数值,共128条未缺失,缺失值为0。salary (薪水) 是整数型,共126条未缺失,缺失值为2。sex(性别) 是object对象,需要处理成数值,共128条未缺失,缺失值为0。
- 统计的结果:总共的类型有 整数型字段4个,object对象2个。
- 内存使用情况:6.1kb的内存
查看前几行:
df.head()
head方法用来显示指定数据(N)的前N数据,不指定N的话,默认显示前5条。
数据概览:
df.describe()
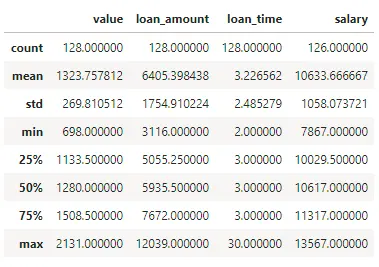
describe方法用来显示数据中所有为数值类型的数据记录数、均值、标准差、最小值、 25%、 50%、75%分位数数据,最大值。
4.4、数据预处理
经过数据的探索,我们知道了数据中有缺失值,有非数值对象。这样就需要做2个数据预处理的工作,处理缺失值,和将非数值对象转换为数值对象。在此之前,我们先看看有无重复值。
4.4.1、重复值处理
重复数据查询:
df[df.duplicated()]
输出结果:

duplicated()函数可以查询重复的内容。可以看到第62行记录重复了,被代码筛选了出来。
查看重复的数量:
df.duplicated().sum()
输出结果为:1。说明数据中只有一行数据重复了。
删除重复数据:
df = df.drop_duplicates()
需要注意的是,drop_duplicates()函数并不改变原表格结构,所以需要进行重新赋值,或者在其中设置inplace参数为True。
再次查看数据类型:
df.info()

可以看到从整体看,数据的数量变成了127行了,比之前的128少了一行,说明重复值删除成功。
4.4.2、异常值处理
处理完了重复值,我们再来看看数据中有无异常值。
查看异常值,我们可以用箱体图进行观察。查看整体的异常情况:
df.boxplot()
输出结果:
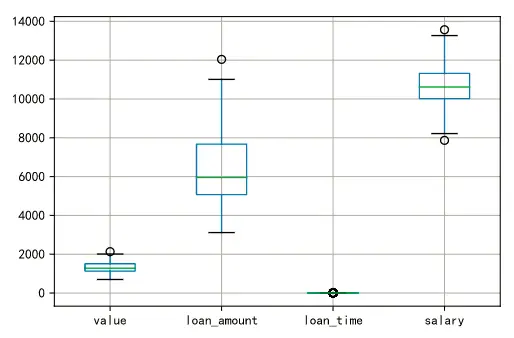
可以看到value,loan_amount,loan_time,salary中分别有异常值。不过,异常值是否都直接删除,需要我们结合具体的业务来考虑。value(客户价值)只超过最大值一点,可以不删除。loan_amount(贷款金额)也只比最大值大一点,不是大的很过分,可以考虑不删除,同理,薪水的异常值也可以认为是可接受的范围内。由于load_time(贷款次数)的数据量纲和其他的不一致,我们可以单独查看:
df[['loan_time']].boxplot()
输出结果:
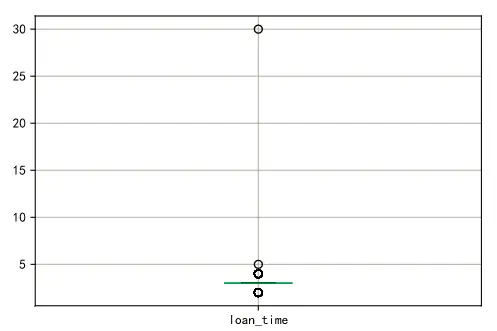
我们可以看到,有一个贷款次数,是要远远大于其他数据的,结合实际业务情况,我们可以认为这个是异常值,(贷款这么多次,银行的征信还能过得去吗)。当然最保险的做法是和业务人员再进行一次确认,然后进行异常值删除。这里,我们暂且认为这个贷款次数30次的人就是异常值。
我们可以找到这条记录:
df[df['loan_time']==30]
输出结果:

删除异常值:
df = df.drop(df[df['loan_time']==30].index)
查看结果:
df[df['loan_time']==30]
输出结果:

可以看到数据中已经查不到原来的这条异常记录了。
4.4.3、缺失值处理
之所以把缺失值放在异常值处理之后,是因为,缺失值通常用平均值,中位数等方法填补,如果数据中有异常值的话,求平均会影响到缺失值的数值。
刚才已经通过数据探索,发现了salary(薪水)一列中有缺失值,那么我们可以用代码将其筛选出来:
df[df['salary'].isnull()]
输出结果:
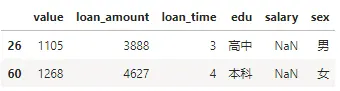
可以看到26行和60行的薪水一列是缺失的。
缺失值通常处理的方法是删除,平均值填补,中位数填补。根据实际情况,我们这里用平均值法填补。
df = df.fillna(df.mean())
再次确认填补效果:
df.info()
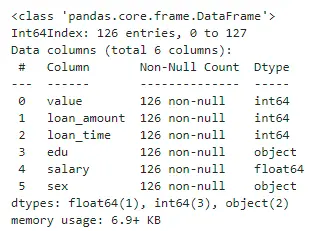
可以看到,数据中已经没有缺失值了。至此,数据预处理的工作已经做完,下面我们开始特征工程的工作。
4.5、特征工程
首先我们查看是否还具有多重共线性的数据,我们查看特征之间的相关性。
4.5.1、相关性分析
首先获取所有的特征变量:
feature = df.drop(['value'],axis=1)
feature.head()

然后我们查看特征之间的相关性,得到相关性矩阵:
corr = feature.corr()
corr
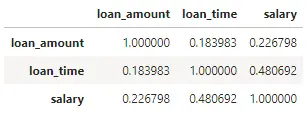
我们将特征矩阵进行热力图可视化展示:
plt.figure(figsize=(10,6))
ax = sns.heatmap(corr, xticklabels=corr.columns, yticklabels=corr.columns,
linewidths=0.2, cmap="RdYlGn",annot=True)
plt.title("Correlation between variables")
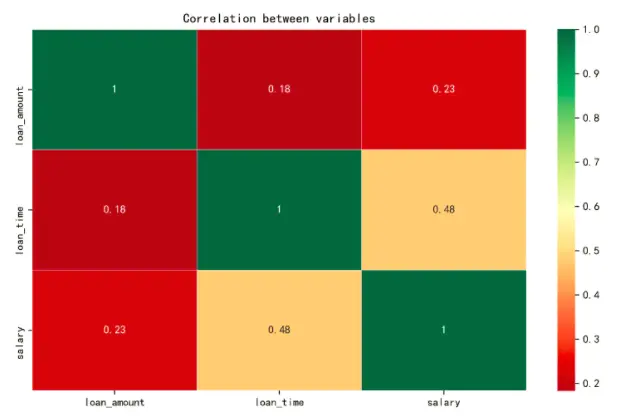
从图中,我们可以看出特征之间没有很强的相关性,没有需要处理的共线性的问题。需要注意的是,特性矩阵只会分析数值类型的特征,不会分析非数值对象的特征。
4.5.2、目标相关性分析
df_onehot = pd.get_dummies(df)
df_onehot.head()

plt.figure(figsize=(15,4))
df_onehot.corr()['value'].sort_values(ascending=False).plot(kind='bar')
plt.title('Correlation between value and variables ')

可以看到目标对象value(客户价值)跟贷款金额,薪水,贷款次数高度相关,和性别无关。和学历相关,其中,和本科成正相关,和高中成负相关,跟研究生学历关系不大,这可能是样本中研究生比例小造成的。说明学历对客户价值还是有一定影响的。
我们可以看一下样本中学历构成情况:
df['edu'].value_counts()

研究生只有4例。
4.5.3、特征构造
非数值型对象是不能直接进行机器建模学习的,所以我们要处理非数值对象,将其转换为数值对象。这里,我们要用到LabelEncoder函数。
le = LabelEncoder()
edu = le.fit_transform(df['edu'])
df['edu'] = edu
sex = le.fit_transform(df['sex'])
df['sex'] = sex
df.head()
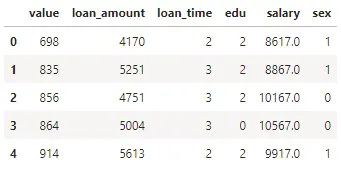
通过LabelEncoder函数,我们将原来的数值转换成为了数值,这样就为后面的机器学习建模做好了准备。有的小伙伴会问:那原来edu(学历)中的高中,本科,研究生怎么和数值1,2对应呢?这是个好问题啊,我们可以这样来做。即通过LabelEncoder转换前后的计数我们可以进行比较,具体方法如下:
首先我们做一下转换前的计数:
df['edu'].value_counts()

df['sex'].value_counts()
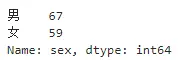
然后我们做一下转换之后的计数:
df['edu'].value_counts()
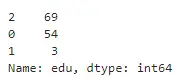
df['sex'].value_counts()
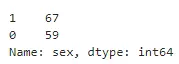
这样,对应关系就一目了然,不用我再说了吧!
4.6、模型搭建
4.6.1、构建特征值和目标值
# 构建特征值X 和目标值 Y
X = df.drop('value',axis=1)
y = df['value']
x是包含了除value以外的所有列,y只是value这一列。
4.6.2、划分训练和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
test_size=0.2,表示用20%的数据测试,用80%的数据来训练。得到的结果为X的训练集X_train, X的测试集X_test, y的训练集 y_train, y的测试集 y_test。
4.6.3、模型搭建
regr = LinearRegression()
regr.fit(X, y)
y_pred = regr.predict(X_test)
4.7、线性回归方程构造
regr.coef_

print('各系数为:' + str(regr.coef_))
print('常数项系数k0为:' + str(regr.intercept_))

最后得到的线性方程为:y = 129 + 0.059x1 + 95x2 - 53x3 + 0.054x4 + 7.53*x5
4.8、模型评估
X2 = sm.add_constant(X)
est = sm.OLS(y, X2).fit()
est.summary()

x = len(y_pred)
plt.plot(range(x), y_pred, label='预测值')
plt.plot(range(x), y_test, label='真实值')
plt.title('真实值和预测值对比走势图')
plt.xticks([])
plt.legend()
plt.show()
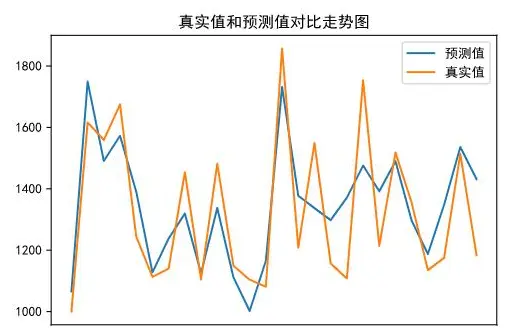
regr.score(X_test, y_test)
输出结果:准确率为0.6470898016296844
4.9、评估结果解读
1、coef列,就是常数项(const)和特征变量(loan_amount, load_time, edu, salary, sex)前的系数,即截距b和斜率系数,可以看到,这和之前求出的结果是一致的。
2、对模型评估而言,需要关心的几个指标有 R-squared、Adj.R-squared 和P值的信息。
2.1、这里的R-squared为0.548, Adj.R-squared为0.529,说明模型的线性拟合程度还不是特别好,可能因为案例额数据量偏少,不过在此数据量条件下也算可以接受的结果。
2.2、对P值而言,大部分的P值都较小,的确与目标变量(客户价值)是显著相关的,而sex这一特征的P值达到了0.819,说明性别和目标变量是没有显著相关性的,这个结论也符合经验认知。之后的建模中就可以舍去这一特征变量了。
五、案例数据结论
1、从特征的相关性来看,目标对象value(客户价值)跟贷款金额,薪水,贷款次是呈现高度相关的。这说明用户历史贷款的记录越多,客户的给企业带来了利润,客户的价值自然要高。
2、客户价值和性别无关。
3、客户价值和学历相关,其中,和本科成正相关,和高中成负相关,跟研究生学历关系不大,可能学历太低风险性会高一点,客户的价值相对低一点。案例中研究生学历太少,导致结果是跟研究生学历关系不大。
4、模型的整体准确率只有0.65,R-squared为0.548, Adj.R-squared为0.529,说明模型的拟合程度不是特别满意,可能是案例的数量偏少。不过在此数据量条件下也算可以接受的结果。
数据下载:客户价值数据表 (访问密码: 7287)















 1286
1286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









