






前言
Hi大家好,我叫延捷,是一名计算机视觉算法工程师,也是叉烧的老朋友了。我们计划发布一系列关于多模态大模型的文章,帮助大家快速、精准地了解多模态大模型的前世今生,并且深入各个多模态大模型领域优秀的工作,希望能给大家一个脉络性的盘点,一起学习,共同进步。
Introduction
上一期我们介绍LLaVA-NeXT的若干延伸工作,并且也跟大家分享LLaVA系列的集大成之作LLaVA-OneVision。本期则会详细介绍一下另外一个在多模态大模型领域相当优秀的工作Qwen-VL,同时Qwen2-VL的技术报告在8月29号刚刚发布,也会跟大家同步介绍这个最新的工作。同样地我并不会过多列举一些不必要的论文细节和指标,而是会着重讲述:
“心路历程”:一个系列工作逐步发展的路径,作者是如何根据当前工作的缺点一步步优化的,并且会总结出每篇工作的highlight,在精而不在多;
“数据细节”:各个工作中对数据处理的细节,包括但不限于数据的收集,采样时的分布,如何清洗/重建noisy数据,如何进行数据预处理,视频抽样的方案等,这些对算法工程师来说是同样重要的一环;
“前人肩膀”:各个工作中隐藏着一些非常值得盘的消融实验,站在前人的肩膀上,使用这些已有的消融实验结论,不仅能帮助我们更好地理解论文,更能在实际工作中少做些不必要的实验and少走弯路。
我这边将详细介绍Qwen-VL,也会简单过一下Qwen2-VL的技术报告,作为一个广受关注的多模态大模型,相信大家会从本文中收获不少。
Qwen-VL
《Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond》(2023)
核心是沿用了BLIP系列的VisionEncoder+Projector+LLM经典架构,简化了Instruction BLIP中较为设计冗杂的Q-Former,也更加适配交错的多轮图文对话,并且在【加强局部/细粒度信息提取】和【精细化数据清洗】上都提出了相当值得借鉴的方案。
首先是模型结构:
视觉编码器:CLIP预训练的ViT-bigG(patch_size == 14);
Projector:包含256个learnable img queries的单层cross-attention,q为queries,k和v为视觉编码器的输出结果,并且给输入的img queries和img encodings都加上了2D绝对位置编码(个人认为这里加入位置编码还是很重要的,尤其是对细粒度图像理解);
LLM:Qwen-7B
训练方面,参照Instruction-BLIP,也是分为了3个阶段:
Pre-training:共1.4 Billion数据量的弱标签&网络爬取的图像文本对数据,22.7%中文+77.3%英文,同时训练视觉编码器和图文对齐Projector,输入图像尺寸为224224,并且基础学习率均为210^-4;

Qwen-VL的1阶段预训练的数据分布和训练策略
Multi-task Pre-training:共76.8 Million数据量的细粒度&高质量标注的多任务数据,其中也包含了交错的图文对话数据,训练所有模型参数,输入图像尺寸为448*448;
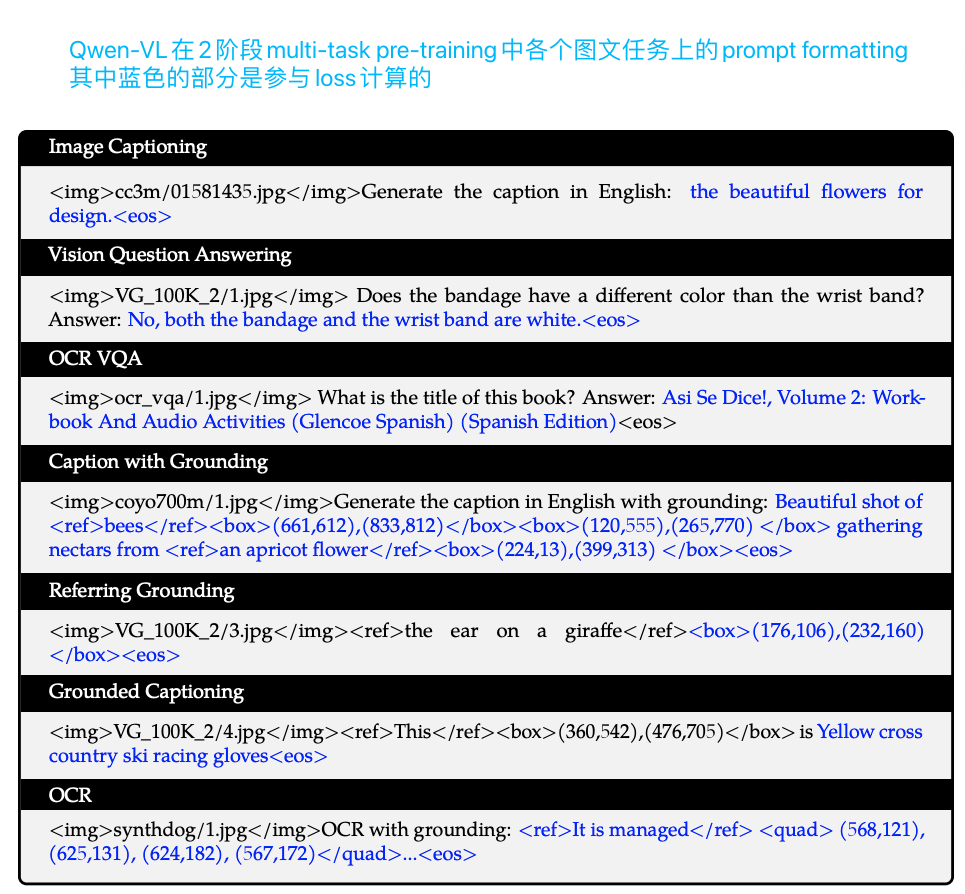
Qwen-VL的2阶段多任务预训练的prompt formatting
SFT:使用了Instruction tuning的方式来增强模型的指令跟随能力,只训练图文对齐Projector和LLM,输入图像尺寸仍然为448*448;值得关注的是,Qwen-VL提出现在使用MML来生成instruction prompt的方式大多都只针对于单个的图文对,为此Qwen-VL结合人工标注+模型生成+策略拼接构建了一批交错多图像的instruction tuning数据,并且在训练过程中混入了一部分纯文本对话数据,总共3阶段SFT数据总共为350k;

Qwen-VL中3阶段Instruction Tuning的一些训练细节
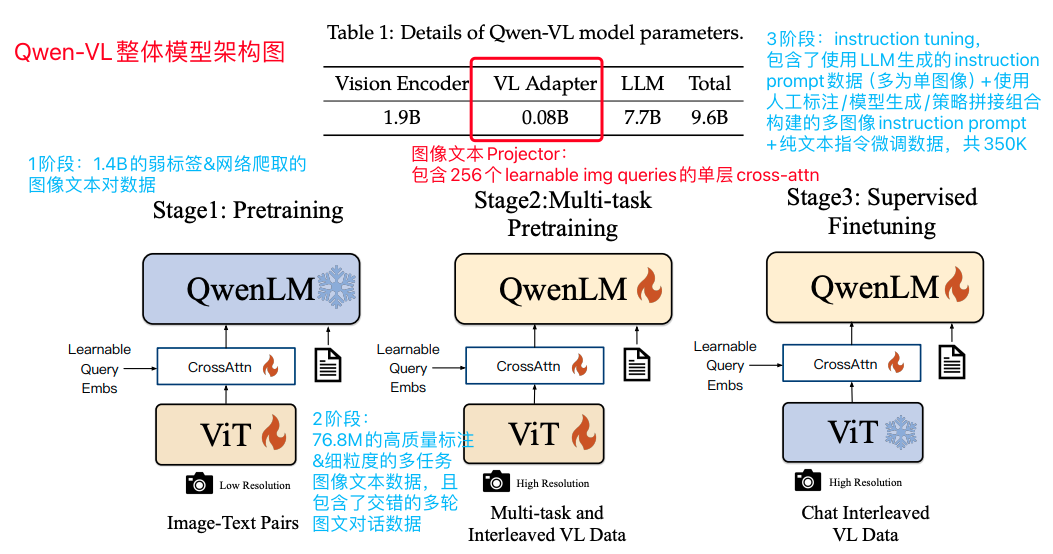
Qwen-VL中整体模型架构图,跟Instruction-BLIP一样分为了3阶段
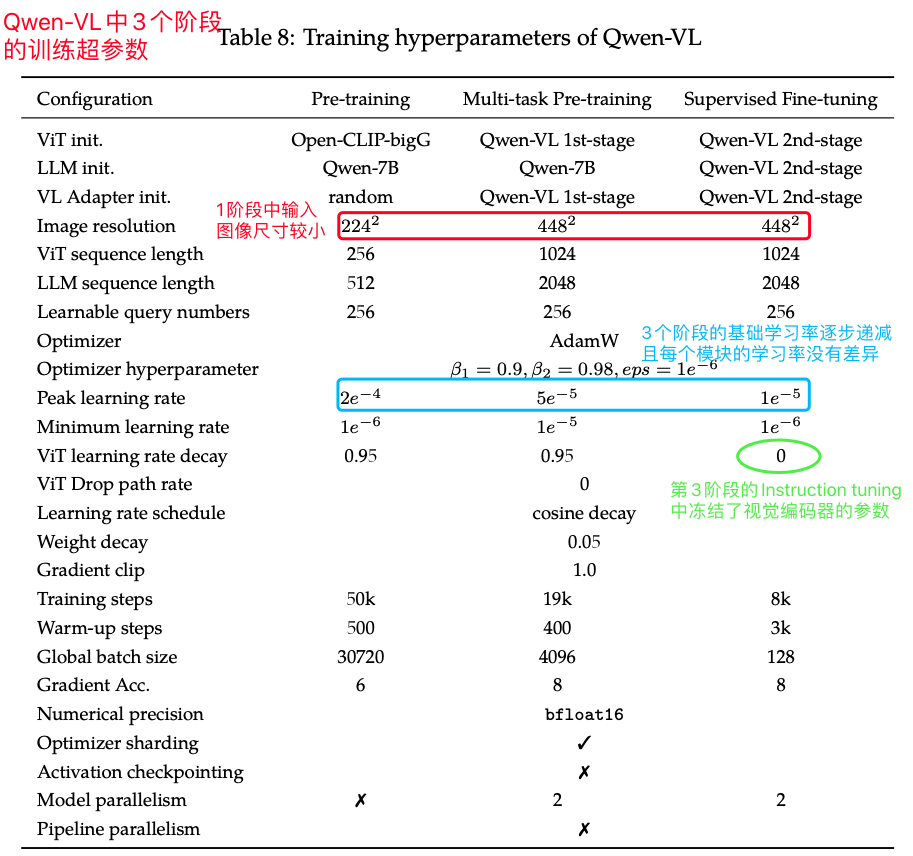
Qwen-VL训练3个阶段的超参数,学习率逐步递减
我们根据Qwen-VL展示出来的超参数图可以发现,并没有像LLaVA-NeXT系列一样,把视觉编码器学习率设为Projector和LLM的1/5~1/10(个人认为对CLIP系列预训练好了的视觉编码器用相对小的学习率是比较好的做法)。
Highlights:
在Qwen-VL中的图文Projector设计:为一个包含256个learnable queries的单层cross-attention,对比BLIP-v2中仅包含32个的learnable img queries但设计更复杂的Q-Former,Qwen-VL的做法也体现出:对于Projector来说不需要多复杂的网络结构,但是不能在img token层面进行有损压缩(同时LLaVA-NeXT-Ablations中的结论也印证了img tokens数量对模型最终效果的影响是很大的);Qwen-VL的论文中也展现了关于img tokens的消融实验。

64个img tokens比起256个img tokens,初始loss更低,但最终收敛后效果不好
加强局部/细粒度信息提取方面:
a. 为了加强LLM对文字和图片的区别度,在经过图文Projector后,给img tokens加入了两个特殊token<img>和</img>;
b. 为了提高对局部区域的细粒度信息提取能力,对grounding和detection类的数据,将bbox信息进行归一化到[0, 1000)中,并按照(x0, y0, x1, y1)的格式,前后再加入两个特殊token<box>和</box>进行区分;
c. 为了强调bbox框中的信息,把数据中对bbox中描述用两个特殊token<ref>和</ref>进行修饰;
总的来说,这一系列做法我认为是一个相当优雅的方式,很显式地让模型提高对局部区域关注,细粒度信息理解能力也能随之提高。并且还能很轻松地扩展到其他需要关注的信息上,比如你的下游任务需要十分关注bbox中的信息,甚至可以额外对bbox中的小图做tokenize,再引入一个额外的token标记来加强模型对这方面的理解。对不同模态数据的融合也可以用类似的做法,我个人是很喜欢这种看上去简单,却有很好拓展性,并且能适配各个不同场景的工作。

Qwen-VL对bbox信息的特殊处理——用特殊的token来控制
Qwen-VL对数据的精细化清洗:在1阶段的pre-training中,Qwen-VL使用的的是公开数据集的图像文本对,其中包含了大量的噪声,为了清洗数据,Qwen-VL做了如下几个步骤:
移除图像长宽比过大的对
移除图像过小的对
根据CLIP评分移除质量较差的对(不同的数据集使用的不同的阈值)
移除文本中含有非英文或非中文字符的对
移除文本中含有表情符号的对
移除文本长度过短或过长的对
清理文本中的HTML标签部分
根据特定不规则模式清理文本(个人认为就是一些硬规则+正则表达式)

Qwen-VL在1阶段时对5B的noisy数据的清洗流程
清洗后1阶段训练数据从5B减少到了1.4B,过滤的比例还是相当大的,并且上面的清洗方式可以直接在我们的工作中用到。笔者之前的文章中就提到,对于算法工程师来说,在大模型时代可能无法像之前一样十分精细地清洗每一条或者每一批的数据,但是对大规模noisy数据的清洗、过滤、伪标签等方案依然能直接提升效果,我们在提升模型技术的同时,更需要同步地提高对大规模数据的敏感度,如何利用开源or手头上的工具提升数据质量是我们必须掌握的能力。
Qwen2-VL
《Qwen2-VL: To See the World More Clearly》(2024)
https://qwenlm.github.io/blog/qwen2-vl/
Qwen2-VL刚刚发布,并没有提供论文,只有一篇较为简单的技术报告,这里我就简单跟大家介绍下技术报告中一些个人觉得有意思的地方。
原生动态分辨率:Qwen2-VL提到比起Qwen-VL,一个改变就是能支持任意分辨率的图像输入,并且跟据图像的输入大小,转换为动态数量的img tokens,保证了模型输入与图像信息的一致性。个人理解就是类似LLaVA-NeXT系列中的AnyRes技术,笔者根据技术文档猜测做法其实比AnyRes更简单,单纯把图片进按照14 * 14的patch进行tokenize,再加上一个2*2的池化层(或者一个线性插值,核心就是再缩小4倍),这也证实,从最新的技术角度来看,使用固定数量的learnable img queries并不是一个很好的方案,或多或少会带来信息有损压缩。
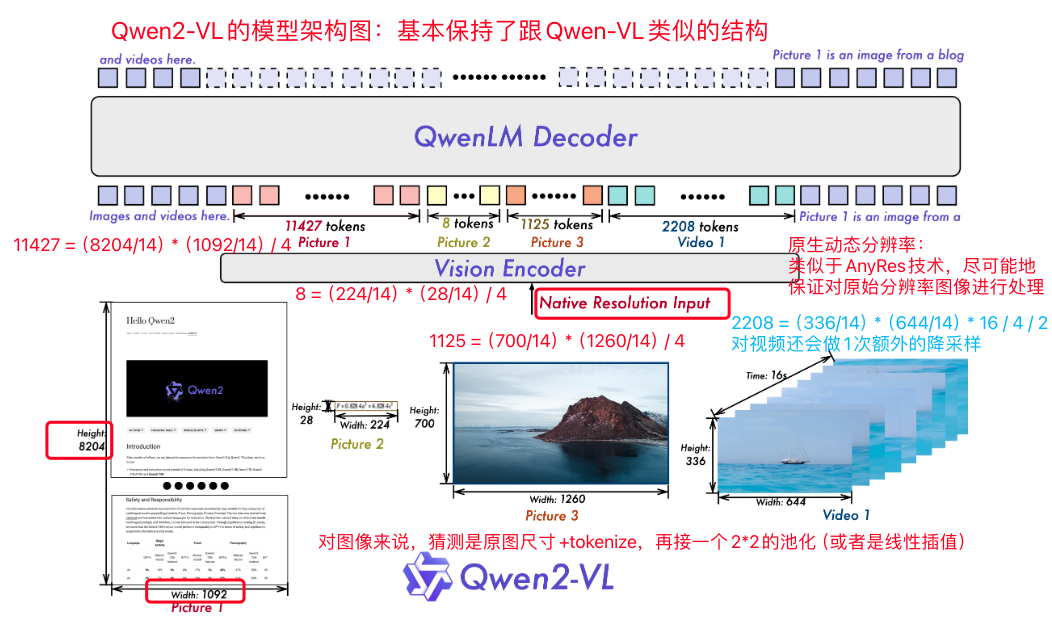
Qwen2-VL的模型架构,修改了Qwen-VL中使用固定数量learnable img queries的单层cross-attn Projector建模方式
多模态旋转位置嵌入(M-ROPE):原始ROPE只能针对一维序列的位置信息,M-ROPE分解为了时间、高度、宽度三个部分,个人理解就是让位置嵌入对图像2D信息和视频3D信息更加敏感的操作,笔者对这个work的有效性略有存疑,不确定这个改动是否真的能显著地提升模型效果。

Qwen2-VL提出的多模态旋转位置嵌入(M-ROPE)
Reference
https://arxiv.org/pdf/2308.12966
https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct















 2084
2084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









