






目录
一、背景与目的
评分模型在我们日常生活中无处不在,比如逛淘宝时看到的商家评分,点外卖时的商家评分,打开支付宝时的信用分,打车时的司机评级等,这背后都是基于各自业务的一套完整的评分体系。有了评分,对企业来说可以对商家的经营能力、用户的风险等级等有一个清晰的量化结果,对于用户来说,能够清晰的知道为自己提供服务的商家或者司机到底处于一个什么样的水平,可以选择更优质的商家、司机。因此,评分体系无论是对公司或用户来说,都是一个很有价值的事情。
二、评分模型
评分模型,其本质是对评价主体建立一套量化的评分结果,那么如何量化呢,就需要对主体建立一套评价指标,并为这些指标分配一些权重,通过权重的组合,得到最终的评分。这里有三个关键的问题:第一是根据所需的业务目的,梳理出合适的指标;第二是指标权重的分配要在满足业务目的的情况下,尽可能的客观。
2.1 评价主体的指标体系及得分
第一个问题是业务问题,举例来说,作为一个零售业态品牌,需要对平台商家进行经营能力评估,具体来说可能会从品质、服务、效率等各方面对其进行考察,而每一方面的衡量指标又有不止一个,最终建立的评估模型可能是这样的
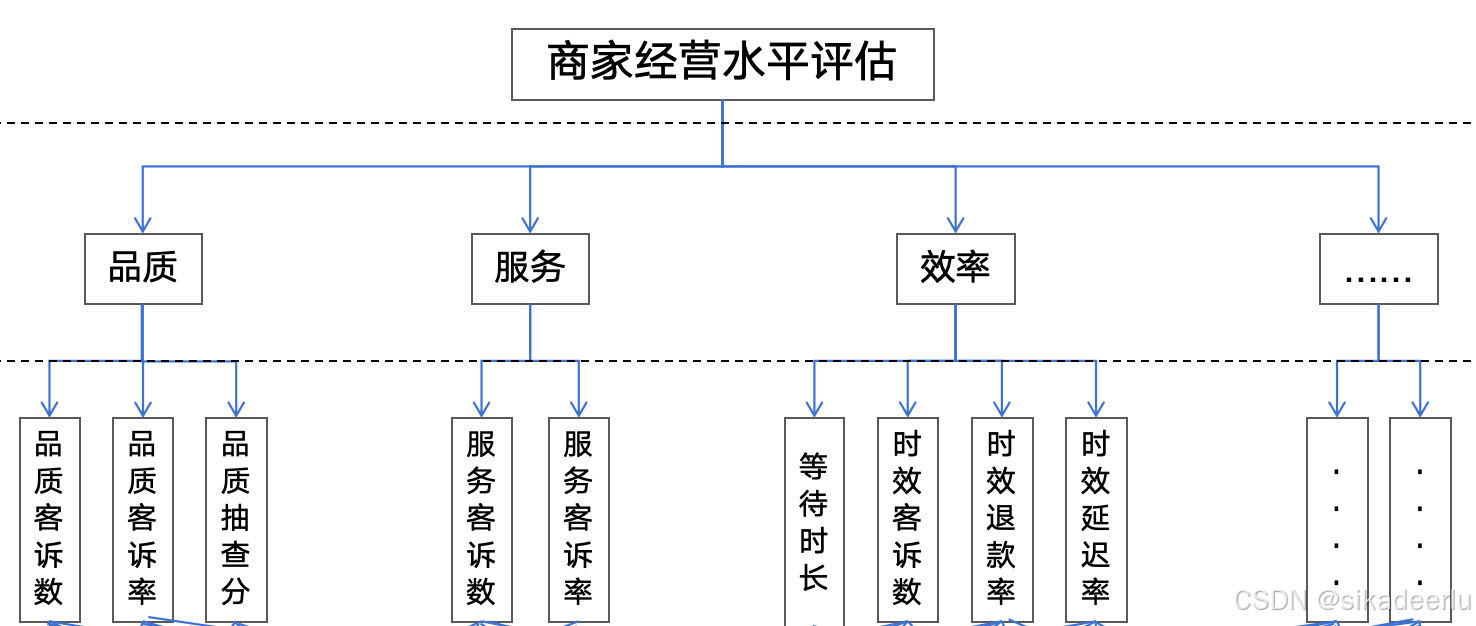 商家的经营水平可以量化为一个得分,这个得分包含品质、服务、效率以及其他项,每一项的得分又由其下对应的指标加权得到,其计算思路如下:
商家的经营水平可以量化为一个得分,这个得分包含品质、服务、效率以及其他项,每一项的得分又由其下对应的指标加权得到,其计算思路如下:
(1)最终得分
= 品质项权重 * 品质项得分 + 服务项权重 * 服务项得分 + 效率项权重 * 效率项得分 + ……
(2)单项得分
例如品质项得分(其他项类似)
= 品质客诉率权重 * 品质客诉率得分 + 品质客诉数权重 * 品质客诉数得分 + 品质抽查分权重 * 品质抽查分得分
(3)指标得分
对于指标来说需考虑是正向、负向还是区间指标,具体方法在下方介绍。这里以品质客诉率这个负项指标为例进行简单说明 ,对其进行归一化,将其转化为0-1之间的数,这样对其打分就较为方便。
2.2 权重确定
确定权重的方法整体上分为两大类,主观赋权和客观赋权,主观赋权是主要依据专家的经验得到的权重,有专家打分、AHP层次分析法两种,这里主要介绍一下AHP层次分析法,客观赋权则是依据指标本身数据分布得到的权重,常用的有变异系数法、CRITIC法。
2.1.1 主观赋权
1、AHP层次分析法
AHP层次分析法是主观赋权和客观赋权相结合的一种确定权重的方法,该方法首先会通过专家对各个待判定指标建立重要性对比判定矩阵,然后再根据重要性的程度得到权重。具体操作分为4步:
(1)构造层次评价模型
首先需要确认目标层、准则层、方案层分别是什么,对该案例来说目标层是对商家的经营水平进行打分,找到不同等级的店铺,那么划分的准则是品质、服务、效率等,对于品质项,又有品质客诉数、品质客诉率、品质抽查分作为子准则,其他准则层下也有对应的子准则,子准则往下是方案层,也就是各个商家即我们要评估的对象。
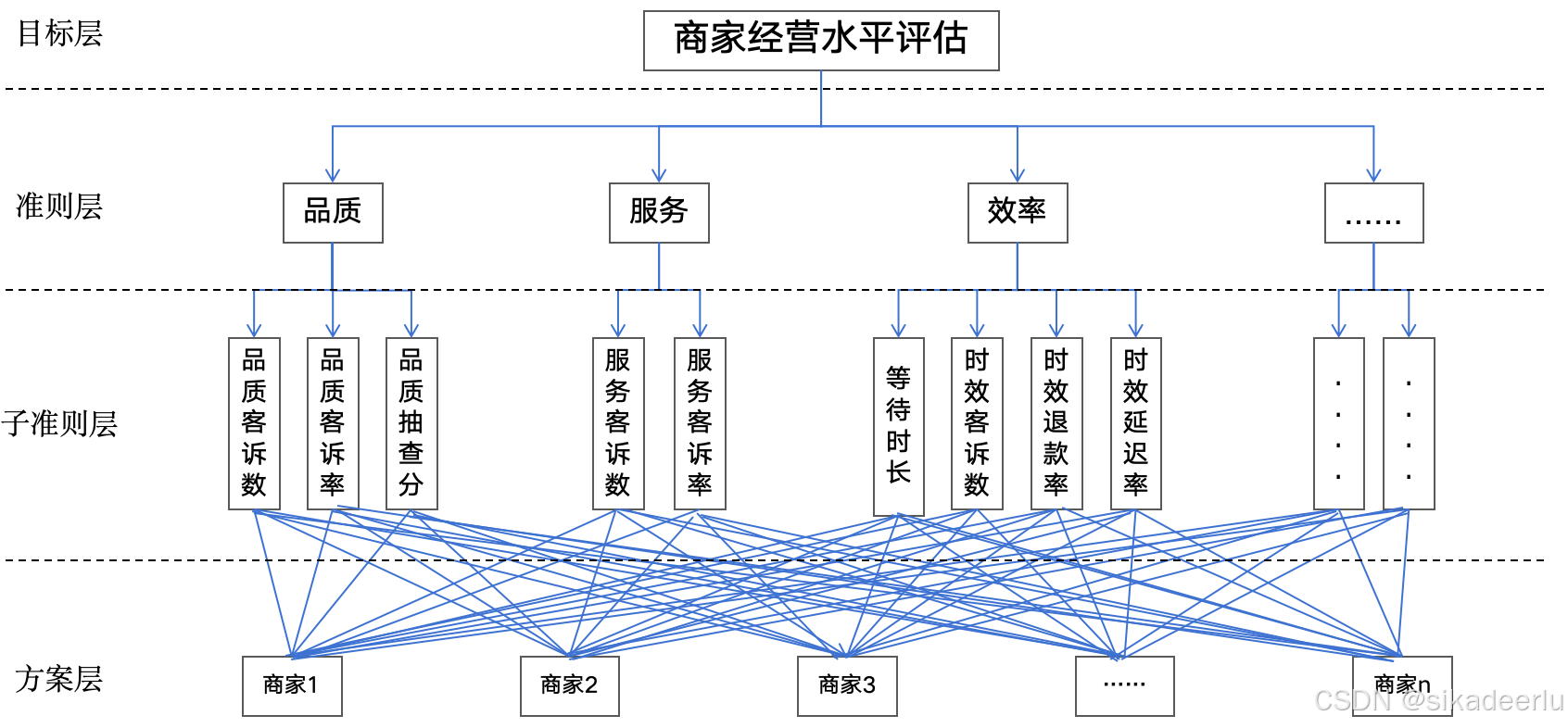
(2)构造判断矩阵
这里以准则层的五个要素A、B、C、D、E为例来看一下如何构造判断矩阵,首先需要对各个因素进行两比较,得到重要性判断矩阵,通常使用的对比准则如下:

a_ij表示第i个要素和第j个要素对目标A的影响程度之比,如下是通过专家经验得到的准则层的判断矩阵:
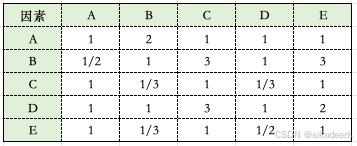
(3)计算权重
可通过方根法、和法等计算判断矩阵计算每个因素的权重,这里以方根法为来说明计算过程:
a. 计算每一行的乘积的m次方根,得到一个m维向量
,
是第i 个因素 相对于 第j 个因素的重要性,以A这个因素为例,其结果为:
b. 计算权向量
将如上得到的m维向量进行归一化即为各个因素的权向量,,具体的计算过程如下

(4)一致性检验
一致性检验的含义看判断矩阵的构建是否存在逻辑问题,具体来说就是,如果你认为A比B重要,B又比C重要,而在对B相较于C做重要性判定的时候,如果出现了小于1的情况,则就是犯了逻辑错误。判定的过程如下:
a. 计算判断矩阵的最大特征根
b. 计算一致性指标C.I.
c. 计算随机性一致性比值C.R.
,R.I.可通过查表得到,

当C.R.<0.1时,表明判断矩阵的一致性程度在容许范围内,此时可用上一步的得到的权向量作为权重。如果C.R. >= 0.1 ,则需要对判断矩阵进行修正。
2.1.2 客观赋权
1、变异系数法
该方法的思路是根据指标本身的分布的差异性作为指标重要性的评估标准。其出发点是如果一个指标在样本上分布差异越大,则说明该指标对主体拉开差异的可能性越大,就越重要;而如果该指标在样本上的分布差异较小,就越不重要。例如对于评估学生的综合得分时,大多数学生的思想政治得分差异不大,不太好拉开很大的差距,这个学科的权重就会小一些;而像英语、数学,学生的成绩可能会差异比较大,比较能拉开差距,这些学科的权重就会大一些。
(1)计算变异系数
其的计算方法如下, 为第i个样本的第j项指标对应的值,
为第j个指标的均值,
为第j个指标的方差,
为第j个指标的变异系数:
(2)计算权重
最终第j项指标的权重,可根据该项指标变异系数在所有指标变异系数总和的占比决定:
变异系数法的计算较为简单,这里就不再赘述案例。
2、CRITIC法
CRITIC法会综合考虑指标的对比强度和冲突性,对比强度用标准差表示,标准差越大说明该指标的对比强度越大,则越重要。冲突性用相关系数表示,即指标之间的相关性,如果两个指标之间的相关性越大,说明指标之间的冲突性越小,其权重就应该越小。就该方法相较变异系数法,考虑了指标之间的相关性,会对相关性较大的指标进行惩罚,以避免指标之间的信息重叠。
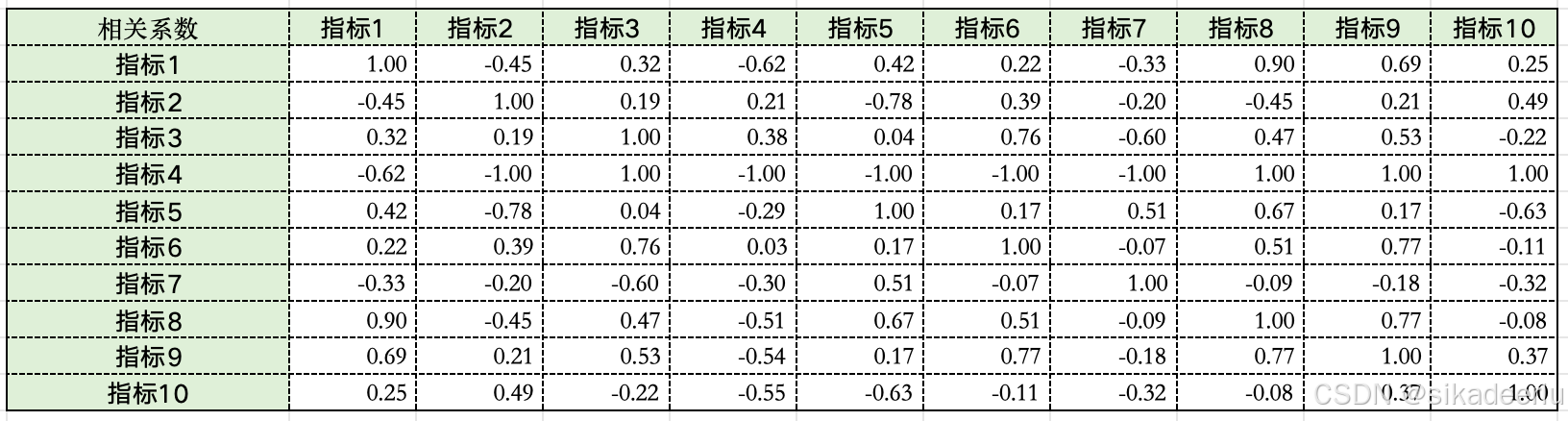
如下是一些示例数据,有10个指标(都为正向指标)5个店铺,看一下如何得到权重。

在计算之前首先需要对每个指标进行归一化,以避免量纲不统一无法对比,归一化的方法在下一节会详细介绍。
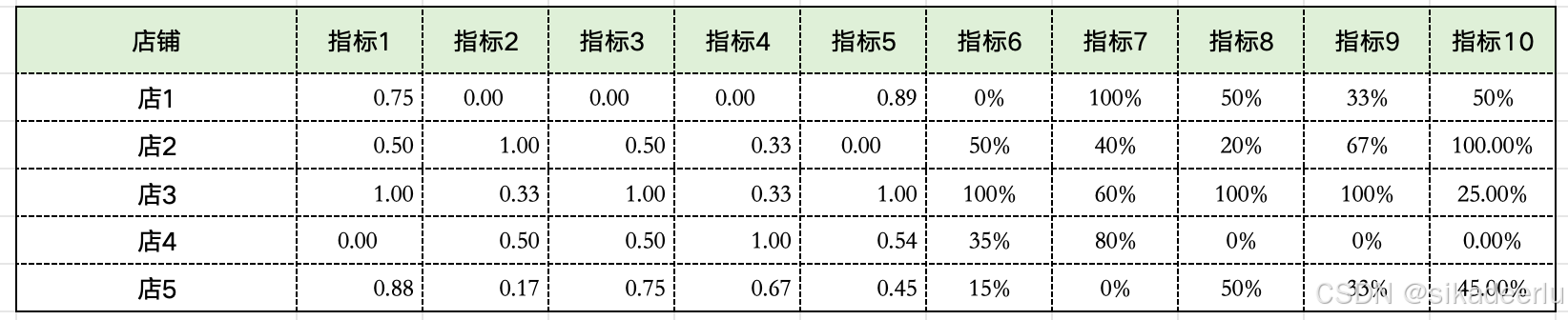
(1)计算指标之间的对比强度(标准差)
为第i个样本的第j项指标对应的值,因为这里用的是标准差,一般需要对指标先统一进行归一化处理,消除量纲不同带来的影响,如下是各个指标表的标准差计算结果:

(2)计算指标之间的冲突性(相关系数)
为第j项指标与其他指标之间的相关系数,如下是各个指标之间的相关系数:
(3)计算指标的信息量
为第j项指标最终的信息量,由对比强度和冲突性两个指标共同决定,信息量越大说明指标的重要性越高。

(4)计算指标的权重
为最终第j项指标的权重,即通过信息量的占比来决定,如下最终得到的权重结果:

2.3 指标得分
指标得分举例来说就是对第个j样本的指标项进行打分,看其在所有样本中应该得多少分。在计算时需要考虑指标对于整体评估目标的影响是正向还是负项,即指标是越大越好、越小越小,还是处于某一个区间的越好。对于平台商家的经营水平评估这个目标来说,品质客诉率指标是负项指标,越低越好;品质抽查分这个指标是正常指标,越高越好;而周转率这个指标,就应该是区间指标,处于某个区间是好的,太高说明可能存货不足,影响销售,而太多说明可能存在存货积压,占用过多资金。 为了方便处理一般会将指标缩放到0到1之间,其处理方法如下:
1、正向指标
2、负向指标
3、区间指标
例如指标的最佳区间是[a, b],则正向化的公式为:
其中 。
三、实操与代码
在实际操作中,我的一些经验是,准则层的权重主要由专家经验直接分配权重得到,这样也可以根据业务的侧重点有些侧重。措施层因为指标较多,用critic方法可根据指标的分布、及相关性情况,自动得到指标的权重。以下是关键计算步骤的核心参考代码:
-- 1、措施层:指标归一化,正向、负向、区间三种不同类型指标的归一化
-- 2、措施层:指标得分,指标归一化结果 * 指标权重
-- 3、准则层:措施层单项得分 = 指标1得分 + 指标2得分 + 指标3得分
-- 4、目标层:最终目标得分 = 准则1得分 * 准则1权重 + 准则2得分 * 准则2权重
-- 5、目标层:最终得分排名
-- 1、措施层:指标归一化,正向、负向、区间三种不同类型指标的归一化
-- 指标最大值、最小值、均值计算
, min(indicator1) over(partition by col1, col2) indicator1_min
, max(indicator1) over(partition by col1, col2) indicator1_max
, avg(indicator1) over(partition by col1, col2) indicator1_avg
-- 正向指标归一化,指标为空 用均值代替,可根据业务情况调整
, case when indicator1 is not null then (indicator1 - indicator1_min)/(indicator1_max - indicator1_min)
else (indicator1_avg - indicator1_min)/(indicator1_max - indicator1_min) end as indicator1_norm
-- 负向指标归一化,指标为空 用最小值代替,可根据业务情况调整
, case when indicator1 is not null then (indicator1_max - indicator1)/(indicator1_max - indicator1_min)
else (indicator1_max - indicator1_min)/(indicator1_max - indicator1_min) end as indicator1_norm
-- 区间指标归一化,最佳指标 xbest 这里是 均值, 正向化指标: M = max(|xi - xbest|),转换后 1 - |xi - xbest|/M ,指标为空时,得分为0,可根据业务情况调整
, case when indicator1 is not null then 1 -
abs(indicator1 - indicator1_avg)/greatest(abs(indicator1_avg - semi_diff_rate_lt7_min) ,
abs(semi_diff_rate_lt7_avg - semi_diff_rate_lt7_max))
else 0 end semi_diff_rate_lt7_norm
-- 2、措施层:指标得分,指标归一化结果 * 指标权重
, indicator1_norm * indicator1_weight as indicator1_score
-- 3、准则层:措施层单项得分 = 指标1得分 + 指标2得分 + 指标3得分
, indicator1_score + indicator2_score + indicator3_score as criterion1_score -- 准则层1得分
-- 4、目标层:最终目标得分 = 准则1得分 * 准则1权重 + 准则2得分 * 准则2权重
, criterion1_score * criterion1_weight + criterion2_score * criterion2_weight as finnal_score
-- 5、目标层:最终得分排名及分位数
, row_number() over(partition by col1, col2 order by finnal_score desc) finnal_score_rn -- 排名
, count(1) over(partition by col1, col2) nums -- 总数
, finnal_score_rn/nums finnal_score_pct -- 分位数四、可视化方案参考
有了每个评价主体每个周期的的得分之后,不仅可以得到与自己历史对比的变化情况,也可以与同类群体进行比较,找差距和提升空间。
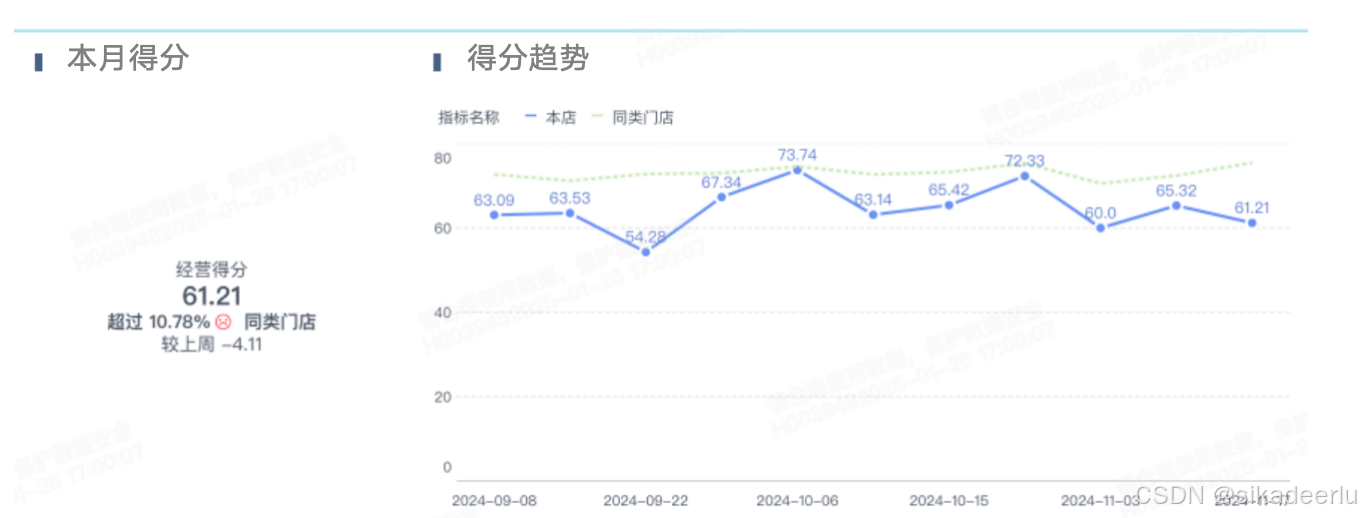
4.1 综合得分趋势及水平
首先是当期得分趋势的可视化,可以用上期、同类群体的得分进行参考,让用户清晰的了解自己的变化与所处的水平。
4.2 各项得分表现
其次也可对各准则层得分进行可视化,让用户知道自己的薄弱项和提升空间。

参考资料:

















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









