







1、Abstract
RPN和Siamese网络结合起来用于tracking取得了不错的效果。但是,对于相似干扰物和大的尺度变化这些问题,Siamese-RPN表现不好。为了解决这些问题,提出了一个多级tracking网络(Siamese Cascaded RPN,简称C-RPN),这个多级网络由孪生网络中的一系列从高深层到低浅层组成的RPN级联而成。
C-RPN的优点:
- 每个RPN都用前一阶段的RPN的输出来训练,这种方式促进了hard负采样,使训练样本更加平衡。对于难区分的背景,级联的RPN更具有辨别力。
- 提出了一个新的模块,FTB(feature transfer block),对于每个RPN来说,可以充分利用多级特征。进一步提高了C-RPN对高层次语义信息和低层次空间信息的识别能力。
- 通过多步回归,C-RPN通过在前阶段调整anchor box,逐步细化目标在各RPN中的位置和形状,使定位更加准确。
2、Introduction
视觉跟踪在近几年取得了很大进步,但是仍然有很多挑战,比如遮挡、尺度变化等等。由于Siamese网络在跟踪应用上的速度和精度的平衡而引起了巨大的关注。Siamese网络将跟踪问题变成一个匹配问题,目的是从大量的视频中离线学习出一个通用的相似性函数。之前的工作one-stage的Siamese-RPN,就是将之前用于目标检测的RPN加入到Siamese网络中用于跟踪。该方法利用RPN提取方案,同时从多个尺度进行分类和定位,取得了良好的性能。RPN的使用避免了将耗时金字塔目标尺度估计,实现超实时解决方案。
(1)问题和动机
在有相似语义干扰的情况下,Siamese-RPN在跟踪中很容易漂移到背景中,作者列出了两点原因。
- 训练样本分布不平衡
正样本远小于负样本,导致Siamese网络训练效果不好。
大多数负样本是easy负样本(非相似无语义背景,non-similar no-semantic background),在学习判别分类器时作用很小。 - 低层空间特征没有得到充分挖掘
只用到了最后一层的特征,只包含更多的用于辨别目标和背景的语义信息。在tracking中,背景中的干扰物和目标可能属于同一类别,有相似的语义特征。在这种情况下,高层语义特征在区分目标/背景方面的辨别作用较小。
为了解决这些问题,one-stage的Siamese-RPN应用了单步回归去进行把目标定位,使用预先定义的anchor box。当这些anchor box与目标有很高的重叠时,这些框能有很好的效果。然而,对于无模型的视觉跟踪,没有关于目标对象的先验信息,很难估计目标的尺度如何变化。在单步回归中使用预先定义的粗糙的anchor box不足以精确定位。
在two-stage的目标检测(Faster R-CNN)中,类别不平衡问题得到了解决。第一个proposal阶段中快速过滤掉大部分背景样本,第二个分类阶段采用采样启发式算法,比如固定前背景比,在前景和背景之间保持可控的平衡。此外,即使对于形状极端的物体,两步回归也能实现精确定位。
在two-stage检测器的启发下,作者提出了一种多级跟踪框架,通过级联一系列的RPNs来解决类不平衡问题,同时充分挖掘各层的特征来实现鲁棒的视觉跟踪。
(2)Contribution
1、提出了一个新的多级tracking 网络结构C-RPN, 利用hard负采样来解决类别不平衡问题。
在Siamese网络中,C-RPN由一系列从高层级联到低层的RPN组成。在每个阶段, RPN进行分类和定位,并输出该阶段anchor box的分类得分和回归偏移量。然后过滤掉easy negative anchors,剩下的作为hard negative anchors,作为下一阶段RPN的训练样本。通过这个过程,C-RPN实现逐层的hard负采样。结果表明,训练样本的分布顺序更加均衡,RPNs分类器在识别难度较大的干扰物时,具有更强的分类能力。见图。

图片是GroundTruth,Siamese-RPN,C-RPN在两个序列上的对比,面对两个大的挑战,上面的视频具有相似干扰,下面的视频具有大尺度变化。
同时C-RPN对于目标可以更精确的定位,C-RPN不是在单个回归步骤中使用预定义的粗anchor box,而是由多个回归步骤组成。在每个阶段,anchor box(包括位置和大小)由回归器调整,这为下一阶段的回归器提供了更好的初始化。C-RPN逐步细化目标边界框,使得定位效果更好。见上图。
2、设计了一个新的特征转换模块(feature transfer block,FTB),用来充分挖掘视觉跟踪的高层语义特征和低层空间特征。FTB没有在一个RPN中单独使用单层的特征,而是将高层的特征融合到低层的RPN中,进一步提高了它对复杂背景的识别能力,使得C-RPN的性能更好。
3、实现一个基于C-RPN的跟踪器。
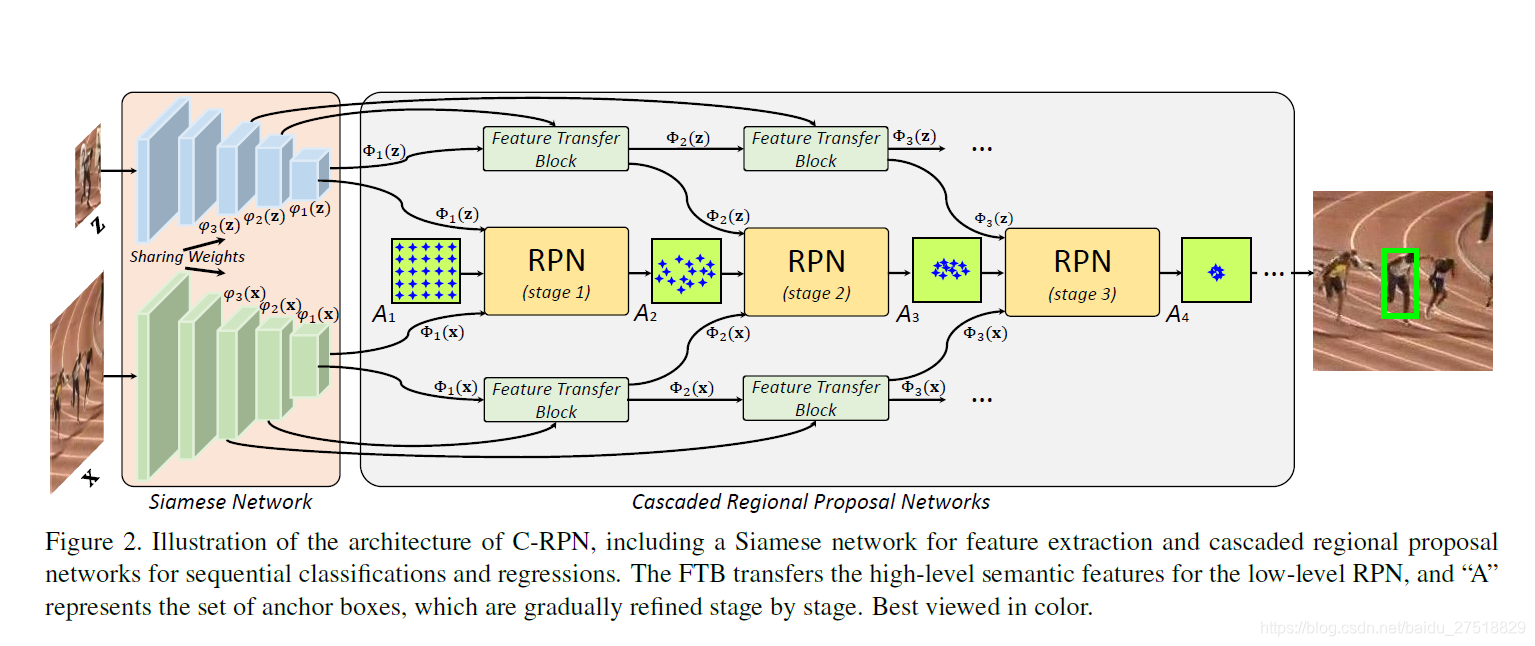
3、Siamese Cascaded RPN (C-RPN)
C-RPN包含两个子网络:Siamese网络和级联RPN。利用Siamese网络提取目标模板x和搜索区域z的特征。然后,C-RPN接收每个RPN的x和z特征。不是只使用来自一个层的特性,而是应用特性传输块(FTB)来融合来自高层层的特性来实现RPN。RPN同时对z的特征图进行分类和定位,根据分类得分和回归偏移量,滤除easy负anchor(负置信度大于预设阈值的锚)。细化剩余anchors的位置和尺寸,用于下一阶段RPN的训练。
1、Siamese Network
Siamese网络由两个相同的分支z-branch和x-branch组成,分别用于从目标模板z和搜索区域x中提取特征。这两个分支共享参数,以确保对z分支和x分支进行相同的转换,这对于相似性度量学习很重要。
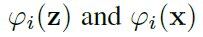
φ_i (z)和φ_i (x)用来表示N层Siamese网络中第i层卷积中z分支和x分支的特征转换。
2、OneStage RPN in Siamese Network
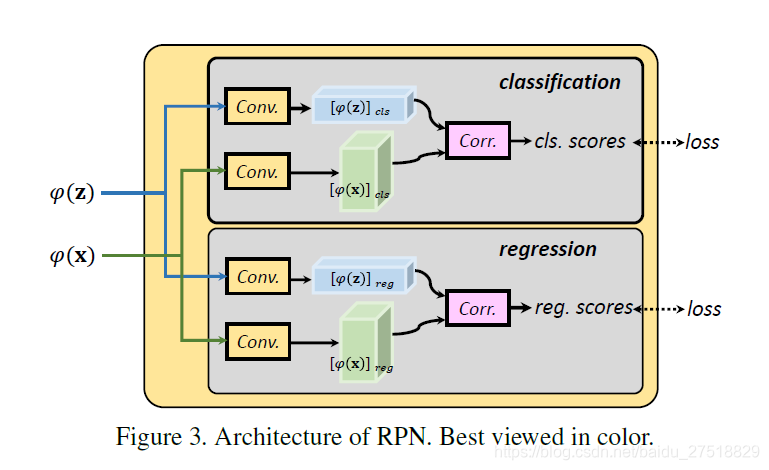
包含两个分支,用于anchor的分类和回归。输入是Siamese网络分支x和分支z经过最后一层特征转换产生的φ_1 (z)和φ_1 (x),输出是anchor的分类得分和回归偏移量。
通过两个卷积层将φ_1 (z)转换成合适的形式,通道数分别变成256×2k和256×4k,分别用于分类和回归。
通过两个卷积层将φ_1 (x)的通道数保持不变。
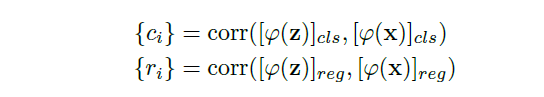
corr(a,b)表示a和b的相关性,a作为卷积的核函数。c_i是二维向量,分别表示anchor分类的正负置信度。r_i是4维向量,分别表示anchor到groundtruth的中心点的偏移量dx,dy,dw,dh。
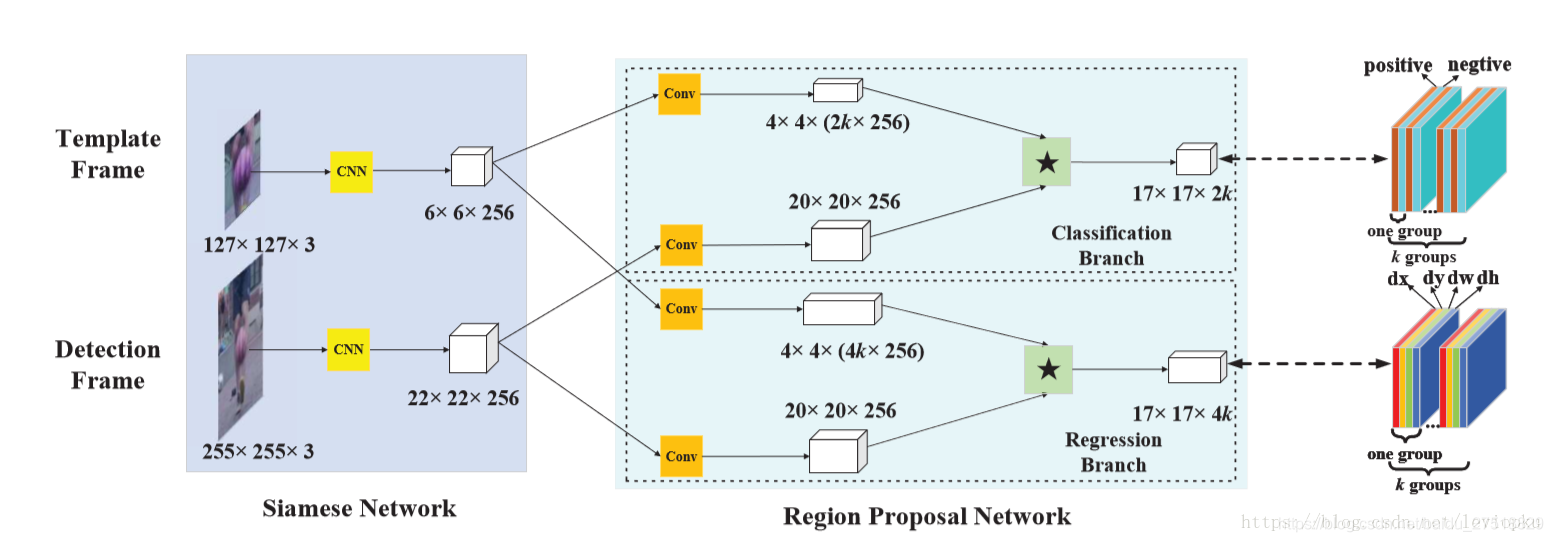
3、Cascaded RPN
之前的Siamese-RPN忽略了类别不平衡问题,并且只用了最后一层的高层语义特征,这样不能挖掘多层特征。
所以,作者提出了这个由一串RPN组成的多阶段跟踪网络。
对于每一个阶段的 RPN,其利用 FTB 模块来融合来自第l个 convolutional layer 的特征 以及 high-level feature,融合后的特征可以用下面的公式进行表达:
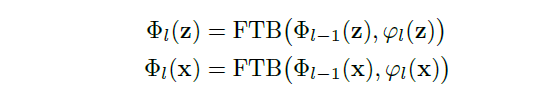
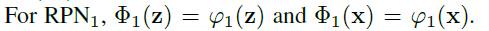
第l阶段的回归置信度和回归偏移量计算方式如下:

用A_l表示第l阶段的anchor集。利用分类分数,可以过滤掉A_l中负置信度大于预设阈值的anchor,剩下的anchor加入用于训练下一阶段RPN的anchor集A_l+1。为了更好地初始化RPN_l+1的回归器,利用RPN_l中的回归结果{r_i}对A_l+1中锚点的中心位置和大小进行了细化。
bounding box精确性的提高:

损失函数:
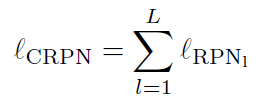
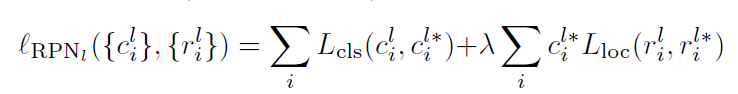
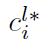
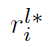
这两项分别表示anchor i的label和anchor i和groundtruth之间的真实距离。
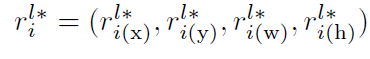
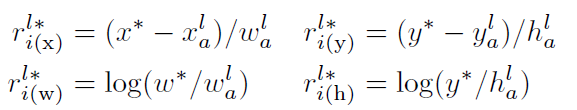
这里最后一个公式中的y**应该是h**。x**表示的是groundtruth,xl_a表示的时第l*阶段的anchor。
C-RPN中的锚在前一阶段被回归器逐步调整,计算为:
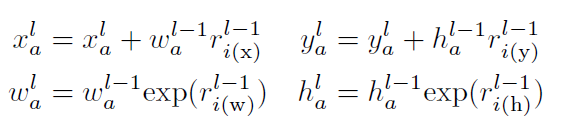
由于过滤了easy负锚点,每个RPN的训练样本分布逐渐趋于平衡。因此,每个RPN的分类器在识别难识别的干扰物时,具有较强的序列识别力。此外,多层特征融合进一步提高了处理复杂背景的识别率。下图表示不同阶段的RPN的辨别能力。

4、Feature Transfer Block(FTB)

FTB,为了融合多层特征。其中,反卷积层用于匹配不同源的特征尺寸。然后,使用元素求和的方法融合不同的特征,接下来一个ReLU层。最后,应用插值对融合后的特征进行缩放,使输出分类图和回归图对所有RPN具有相同的分辨率。
5、训练和跟踪
训练:使用对同一视频序列进行随机采样产生的图像对进行训练,考虑到目标尺度在连续两帧中变化平稳,对每个anchor采用不同比例的尺度。anchor的比例设置为: [0:33; 0:5; 1; 2; 3]。对于每个RPN,都采用了目标检测的策略测定正负训练样本。将正样本定义为IOU大于阈值T_pos的anchor,负样本定义为IOU小于阈值T_neg的anchor。从一个图像对最多生成64个样本。
跟踪:将跟踪定义为多级检测。对于每个视频,在第一帧中预先提取目标模板的特性。在新帧中,根据上一帧的结果提取感兴趣的区域,然后利用C-RPN对该区域进行检测。在每个阶段,RPN输出anchor的分类得分和回归偏移量。负置信度大于阈值的anchor被丢弃,其余的anchor就进行细化然后加入下一阶段的RPN。在最后一个阶段L之后,将剩下的anchor作为目标方案,利用策略确定最优的anchor作为最终跟踪结果。选择策略:通过高斯窗口抑制和形状抑制得到加权后的分数,从中选出分数最高的anchor,作为最后检测的目标位置。

4、Experiments
L of stages 设置为 3。
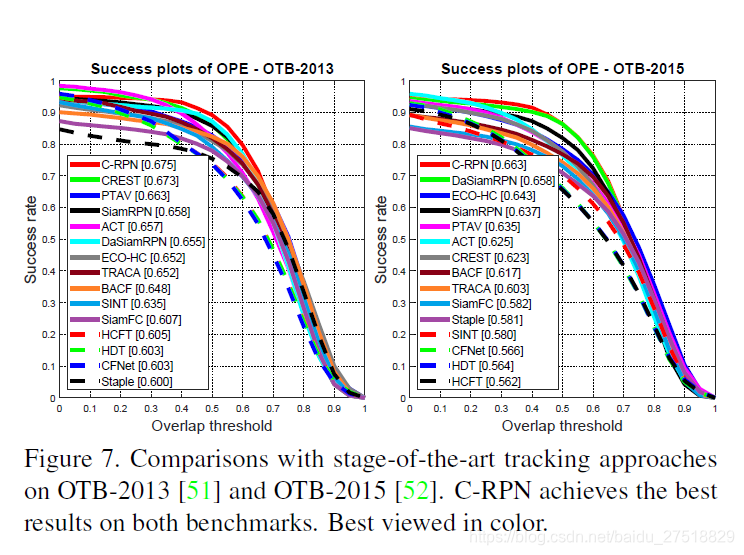
在OTB2013和OTB2015上进行实验
36 fps,在不使用额外训练数据的情况下,C-RPN的性能比DaSiamRPN分别高出2.0%和0.5%。
在VOT2016和VOT2017上进行实验
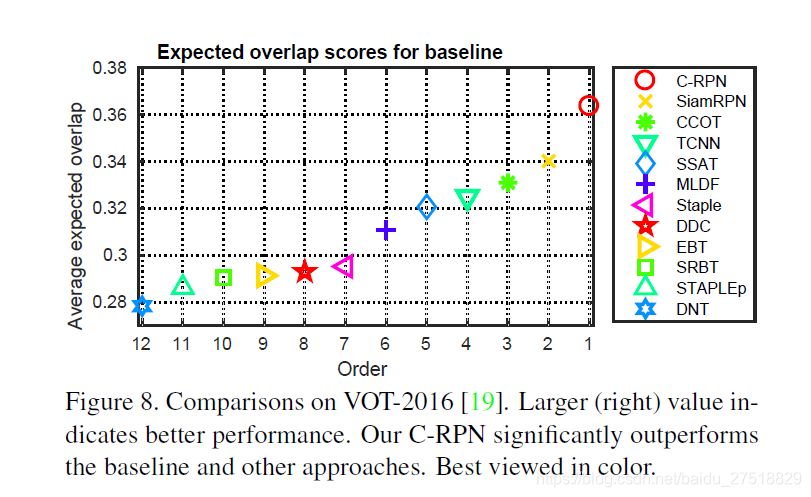
平均重叠期望(EAO)是对每个跟踪器在一个短时图像序列上的非重置重叠的期望值,是VOT评估跟踪算法精度的最重要指标。
EFO(Equivalent Filter Operations )是VOT2014提出来的一个衡量tracking速度的新单位,在利用vot-toolkit评价tracker之前,先会测量在一个600×600的灰度图像上用30×30最大值滤波器进行滤波的时间,以此得出一个基准单位,再以这个基础单位衡量tracker的速度,以此减少硬件平台和编程语言等外在因素对tracker速度的影响。
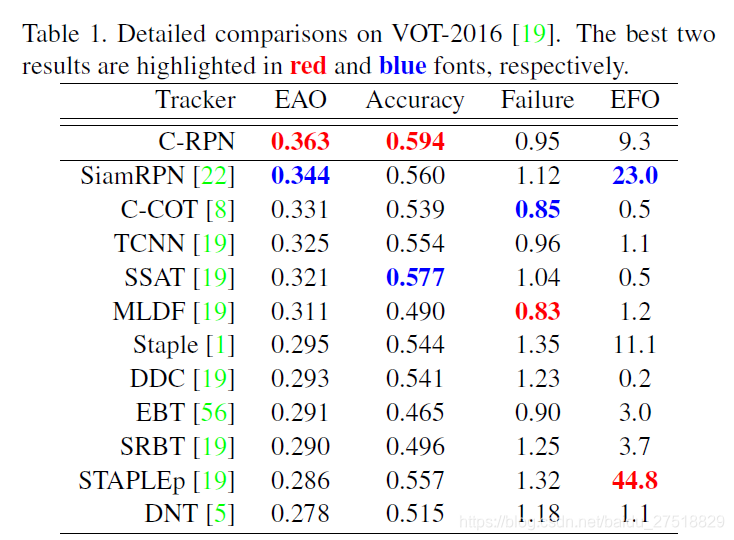
准确率(Accuracy)是指跟踪器在单个测试序列下的平均重叠率(两矩形框的相交部分面积除以两矩形框的相并部分的面积)。
鲁棒性(Robustness)是指单个测试序列下的跟踪器失败次数,当重叠率为0时即可判定为失败。

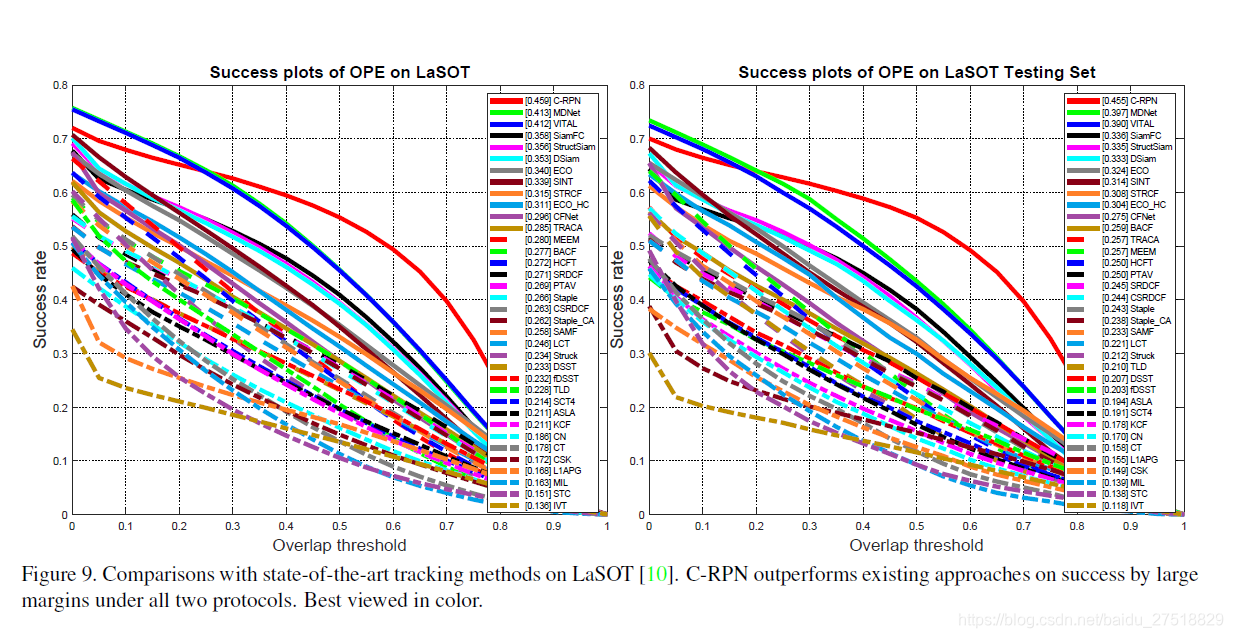
在LaSOT上进行实验

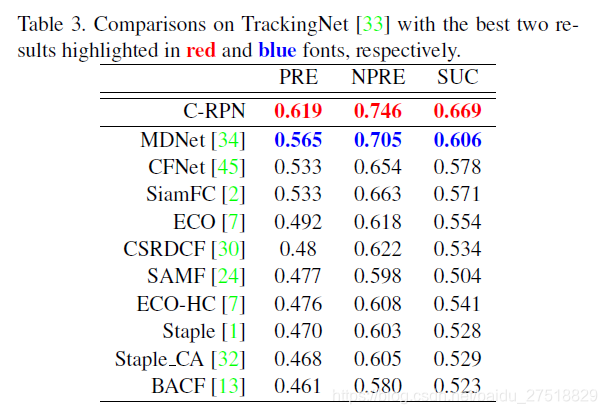
在TrackingNet上进行实验
TrackingNet包含3万+个视频以及1420万个标注框。
NPRE(normalized precision)是为了因为精度的度量对图像尺度的大小和bounding box的大小比较敏感,归一化后可以更加准确的体现精度。
PRE(precision),追踪算法估计的目标位置(bounding box)的中心点与人工标注(ground-truth)的目标的中心点,这两者的距离小于给定阈值的视频帧的百分比
SUC(success),当某一帧的OS(重合率得分,overlap score)大于设定的阈值时,则该帧被视为成功的(Success),总的成功的帧占所有帧的百分比即为成功率(Success rate)
消融实验
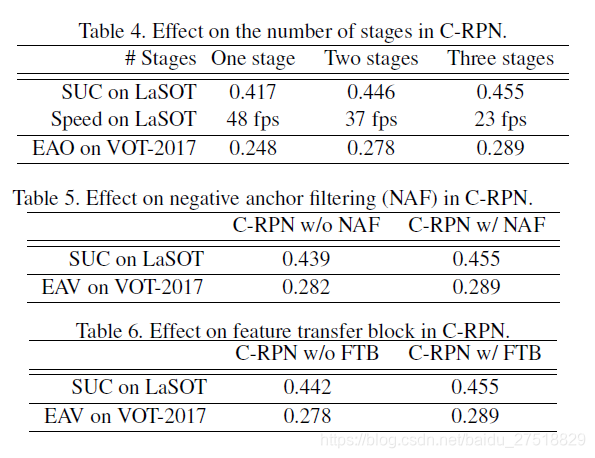
第二阶段的改善程度高于第三阶段。这表明最困难的背景是在第二阶段处理。增加更多阶段,可能会有更大的提升,但是也增加了计算量。
结果表明,去除C-RPN中的负anchor后,LaSOT的SUC由0.439提高到0.455,EAO由0.282提高到0.289,分别提高了1.6%和0.7%,这说明均衡的训练样本对于训练更具识别性的RPN至关重要。
FTB在不损失太多效率的情况下,将LaSOT上的SUC从0.442提高到0.455,提高1.3%,而在VOT-2017上的EAO从0.278提高到0.289,提高1.1%,验证了多级特征融合在提高性能方面的有效性。
5、Conclusion
在本文中,作者提出了一个新的多阶段框架C-RPN跟踪。与以前的技术相比,C-RPN通过在级联架构中进行hard负采样,在处理复杂的背景(例如类似的干扰)方面表现出了更强的性能。此外,FTB支持跨层的有效特性利用,以实现更有辨别力的表示。C-RPN使用多个回归步骤逐步细化目标边界框,从而实现更精确的定位。在6个流行基准上的广泛实验中,C-RPN始终能够实现最先进的结果并实时运行。














 606
606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









