









发表在ECCV2018上
作者的知乎讲解:https://zhuanlan.zhihu.com/p/42546692
三个问题:
1.常见的siam类跟踪方法只能区分目标和无语义信息的背景,当有语义的物体是背景时,也就是有干扰物(distractor)时,表现不是很好。
2.大部分siam类跟踪器在跟踪阶段不能更新模型,训练好的模型对不同特定目标都是一样的。这样带来了高速度,也相应牺牲了精度。
3.在长时跟踪的应用上,siam类跟踪器不能很好的应对全遮挡、目标出画面等挑战。
针对这三个问题
1.
作者发现,训练数据中的非语义背景和具有语义的干扰物背景的数据不平衡进一步学习的主要障碍。高质量的训练数据非常重要,Diverse categories of positive pairs can promote the generalization ability,Semantic negative pairs can improve the discriminative ability.为此,在训练阶段,作者引入现有的检测数据集来充实正样本数据,以此来提升跟踪器的泛化能力;接着,作者又充实了困难负样本数据,以此来提升跟踪器的判别能力。如下图:

前一项工作(SiamRPN)所用的训练集ILSVRC2015-VID和Youtube-BB所包含的种类不太充分,为了提高跟踪器的泛化能力,作者在此基础上又引入了ILSVRC2015和COCO数据集静态图片,通过一系列增强手段(平移、调整大小、灰度化等)来扩充了正样本对的种类。
为了提高判别能力,在负样本中,作者发现有语义的背景和类内干扰物都很少,所以增加了不同类别的困难负样本来避免跟踪结果飘逸,以及增加了相同类别的困难负样本来更加关注目标的细节表达。
2.
数据上做了增强后,在跟踪特定目标时,还是很难将一般模型转化为特定视频域所用,这时候上下文信息就显得很重要了,为此作者设计了干扰物感知模型(distractor-aware module),怎么说呢?
也就是在跟踪时,上一帧上选择出好多proposals,最高的值是跟踪结果,通过非极大值抑制,选出大于某阈值的一些proposals就是干扰物
di
d
i
,然后到跟踪帧时,响应得分要减去这些干扰物与搜索区域的响应,最终位置如下面公式所示,
a^
a
^
是权重因子,设为0.5,每个干扰物的权重
ai
a
i
设为1,
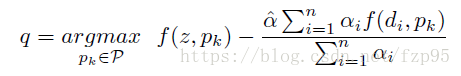
因为互相关操作是线性的,遵从结合律,所以可以写成下式:
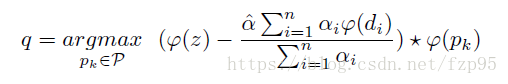
加入增量学习:
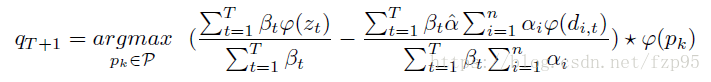
这里
βt=∑t−1i=0(η1−η)i
β
t
=
∑
i
=
0
t
−
1
(
η
1
−
η
)
i
,
η=0.01
η
=
0.01
3.
DaSiamRPN可以很好的应对长时跟踪问题,作者提出了在短时跟踪和失败情况的切换法,即跟踪失败时,采用局部到全局的搜索策略来重新检测目标。
DaSiamRPN的detection score可以很好的指示出跟踪目标丢失,然后就可以启动local-to-global search strategy了也就是放大搜索框。

















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









