







在过去六个月,一种强大的新型神经网络工具出现应用于自然语言处理。新型的方法可以总结为四步骤:嵌入(embed),编码(encode),加入(attend),预测(predict)。本篇文章解释了新方法的各个部分。并在最近的两个系统中展示如何使用。
当人们思考机器学习的改善时,他们通常会考虑效率与准确率,但是这最重要的问题是通用性。比如,如果你想要在社交平台上编写程序来检测带有辱骂信息,你应该能够问题延伸为需要文本来预测类别的问题。因此不管是检测带有辱骂信息的帖子还是辨明垃圾邮件,如果这两种问题采用同样类型的输入,和输出同样类型的输出。我们可以采用相同的模型代码,并且可以通过在不同的数据数据上得到不同的解决问题方式。——采用相同的工程演绎不同的问题。
基于深度学习的四步法处理文本
词嵌入表示,即词向量是现在自然语言处理最流行的方法。词嵌入可以将分离的词当做有关联的单元,而不是完全不同的ID。可是大多数自然语言处理问题要求理解很长的文本,不单单是独立的词语。在将 文本嵌入一个词向量后,双向RNN用来编码向量为词矩阵。这个矩阵可以理解为词向量。词向量对于分词文本的上下文很敏感。最后让人疑惑的是一个加入机制,是的你的句子矩阵转换为句子向量,来准备预测。
1:词嵌入(embed)
一个嵌入表可以将一个很长,稀疏的,二进制向量表示为很短,高位,具有连续的词向量,比如,我们火车的文本是一组ASCII类别的序列,将会有256个可能的值,因此我们需要将每一个值用二进制来表示需要256维。对于a来说,只有属于97的值会是1,其他值为0 。a=0000…1…0000.(256) b表示为在98位置为1,其余为0.。这种方式叫做one-hot编码,不同值代表不同的向量。
大多数神经网络模型开始与将本文分词为词语,然后嵌入这些词语到词向量里面,奇特的模型将词向量延伸到其他信息里面。比如创建一个词袋通常是非常有用的。除了word IDS 你可以学习标签嵌入,将标签嵌入连接到单词嵌入。这使得你将一些有用的位置敏感的信息加入词表示中。可是,这会有很多强有力的方法使得词表达特定的上下文。
2: 词编码(Encode)
给定一个词向量序列,彪马这部分可以计算一个城市为句子矩阵的表示方式。其中每一行表示句子其他部分上下文中的每个标记含义。
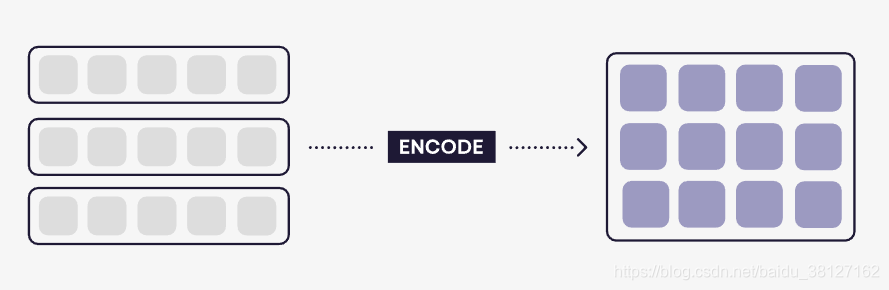
这个技术可以用bidirectional RNN来实现,LSTM和GRU体系结构已经显示了很好的效果。每一个标注都可以用两部分来计算,一部分是通过前向传播,另一个是后向传播。为了得到全部的词向量,我们简单的将两个粘贴一起,下面是简单的代码:
def encode(fwd_rnn, bwd_rnn, word_vectors):
fwd_out = ndarray((len(word_vectors), fwd_rnn.nr_hidden), dtype='float32')
bwd_out = ndarray((len(word_vectors), bwd_rnn.nr_hidden), dtype='float32')
fwd_state = fwd_rnn.initial_state()
bwd_state = bwd_rnn.initial_state()
for i in range(len(word_vectors)):
fwd_state = fwd_rnn(word_vectors[i], fwd_state)
bwd_state = bwd_rnn(word_vectors[-(i+1)], bwd_state)
fwd_out[i] = fwd_state
bwd_out[-(i+1)] = bwd_state
return concatenate([fwd_state, bwd_state])
我认为双向RNN将是一个随着时间而变得更加具有洞察力、更有效。可是RNN大部分的直接应用是读取文本,然后从文本中预测信息。编码(encode)所做的功能是计算一个中间表示方式,特别是每一个标注特征。重要的是这个表示我们可以通过在上下文的标记来反向表达。我们可以学习到词语 “pick up” 与词语“pick on”的不同。甚至我们可以通过分离标记来处理这两个词语。这是NLP模型最大的挪点,但是现在我们解决了。
3:载入(Attend)
载入(attend)步骤将编码(encode)步骤产生的矩阵表示减少到单个向量。以至于可以通过一个标准的前向传播网络预测。载入步骤区别于其他类似操作的机制典型的优点是作为辅助上下文向量的输入。

通过减少矩阵到向量,你必然会丢失信息。这就是为什么上下文向量是至关重要的:它告诉你丢弃哪些信息。因此,“摘要”向量是适合于网络来计算它。最近的研究表明,载入机制是一种灵活的技术,它的新变体可以用来创建优雅和强大的解决方案。例如,Palikh等人。(2016)引入两个句子矩阵的载入机制,并输出一个向量。
杨等人。(2016)引入一个载入机制,它采用一个矩阵并输出一个向量。而不是从输入的某个方面派生的上下文向量。“摘要”是参照作为模型参数学习的上下文向量来计算的。这使得注载入机制是纯粹的还原操作,它可以用来代替任何和或平均池步骤。
4:预测(Predict)
一旦文本或文本对被简化为单个向量,我们就可以学习目标表示——类标签、实值、向量等。我们也可以通过使用网络作为状态机的控制器,例如基于转换的解析器来进行结构化预测。

有趣的是,大多数NLP模型通常支持较浅的前馈网络。这意味着一些最新的计算机视觉最重要的技术,如剩余连接和批量标准化,到目前为止对NLP社区的影响相对较小。
转载来自:https://explosion.ai/blog/deep-learning-formula-nlp














 591
591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









