






改进点:主要集中在改进召回率和定位,同时保持分类精度
yolov2融合了大量想法,如下表所示:

(1)BN层
批量归一化导致收敛的显着改善,而不需要其他形式的正则化。通过在YOLO中的所有卷积层上添加批量归一化,我们在mAP中获得超过2%的改进效果。批量规范化也有助于规范模型。使用批次标准化,我们可以从模型中去掉dropout,而不会过度拟合。
(2)高分辨率分类器
yolov1:先用224*224在ImageNet上训练分类器,然后再在448*448上训练检测器。
yolov2:先用224*224在ImageNet上训练分类器,再用448*448的分辨率在ImageNet上微调10个epoch,然后再在448*448上训练检测器。增加中间这一步可以使网络的filter适应高分辨率的输入。这种高分辨率分类网络使我们增加了近4%的mAP。
(3)Convolutional with Anchor Boxes
yolov1使用fc预测偏移量(x,y相对于ceil左上角的偏移量)。
yolov2使用conv层代替fc预测。
yolov2引入anchor box,预测Anchor Box的偏移值与置信度。
(4)Dimension Clusters
使用k-means聚类,以自动找到好的先验bbox。
我们真正想要的是好的iou得分,这个框的尺寸是不相关的。
使用距离公式:k=5
![]()
(5)Direct location prediction
RPN输出的tx,ty是是相对于anchor的左上角的偏移,这种方式没有任何限制,使得无论在什么位置进行预测,任何anchor boxes可以在图像中任意一点结束,模型随机初始化后,需要花很长一段时间才能稳定预测敏感的物体位置。xa,ya,wa,ha是anchor的坐标位置。
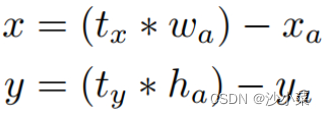
虽然和RPN都是用了anchor,但yolov2使用yolov1 的方式输出tx,ty-输出值是相对于ceil的。而tw,th是相对于anchor的。
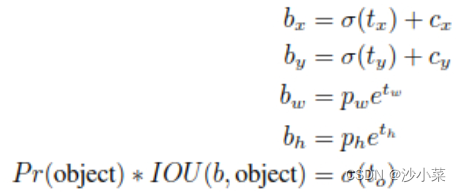
bx,by表示最终预测的bbox的中心点的坐标(此处仍然是归一化的值。)
(6)Fine-Grained Features
细粒度特征,13*13的特征对于大目标预测是足够的,但是它仍可以从用于定位小目标的细粒度特征中获得好处。
只使用一个passthrough layer将26×26×512特征映射转换为13×13×2048。该特征与后面的特征concat在一起,尺寸是12*13*3072,最后再接一个conv层。
(7)多尺度训练
每迭代10个batch我们的网络随机选择一个新的图像尺寸大小。由于我们的模型以32的因子下采样,我们从以下32的倍数中抽取:{320,352,…,608}。因此,最小的选项是320×320,最大的是608×608.我们调整网络的大小,并继续训练。
(8)darknet19
darknet19有19个conv层 ,5个maxpool和1个avgpool。
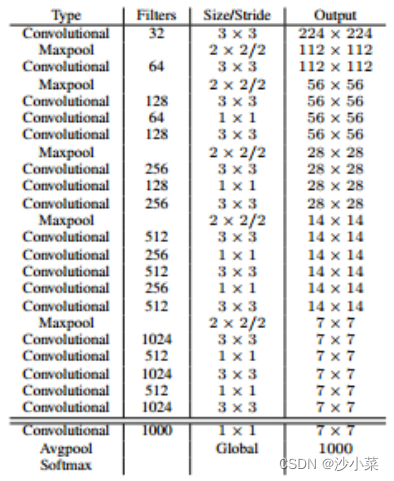
darknet19用作检测训练时,去掉5conv层后面连接的一个conv层,并用3个conv替代。
并使用passthrough,passthrough的输出和这3个conv的输出concat后,连接一个conv层。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









