




 YOLOv2通过引入BatchNormalization加速训练并提高准确性,使用高分辨率预训练分类网络提升mAP,采用Darknet-19网络结构减少计算量。文章还讨论了卷积核和滤波器概念,以及YOLOv2如何利用AnchorBox和K-means聚类优化定位。此外,介绍了细粒度特征和多尺度训练策略,以适应不同尺寸的输入图像。
YOLOv2通过引入BatchNormalization加速训练并提高准确性,使用高分辨率预训练分类网络提升mAP,采用Darknet-19网络结构减少计算量。文章还讨论了卷积核和滤波器概念,以及YOLOv2如何利用AnchorBox和K-means聚类优化定位。此外,介绍了细粒度特征和多尺度训练策略,以适应不同尺寸的输入图像。
文章目录
YOLO v2概述
YOLO v1虽然检测速度快,但在定位方面不够准确,并且召回率较低。为了提升定位准确度,改善召回率,YOLO v2在YOLO v1的基础上提出了几种改进策略,如下图所示,一些改进方法能有效提高模型的mAP。
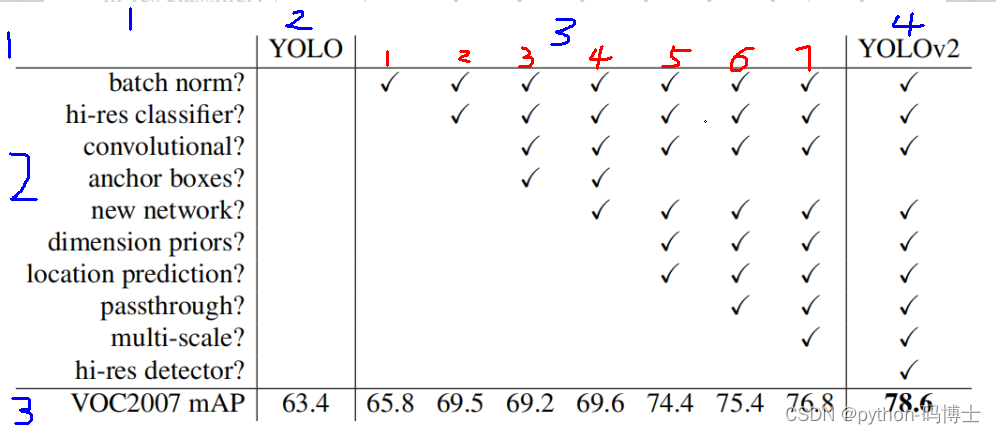
这个图片的第2行第1列是进行改进的点,第2行第3列应该看红色数字标注的列,有√就是有改进,空白就是没改进,第2行第4列就是今天咱们的主角yolo V2,集所有BUFF于一身得到最强mAP值,第3行是对应的mAP值。下面我们按顺序逐一讲解:
Batch Normalization(批归一化)
- 舍弃了Dropout。因为Dropout经常在全连接层用到,为了防止过拟合。在这里也就表示去掉了全连接层。不知道的复习一下神经网络基础算法。
- 那么既然没有了全连接层,对图像输入的大小还有要求吗?当然是没有了,因为只有全连接层的参数限制了输入图像的大小,卷积层又不影响。
- 每一个卷积层后都加入Batch Normalization,也就是网络的每一层都做归一化,收敛起来相对简单。
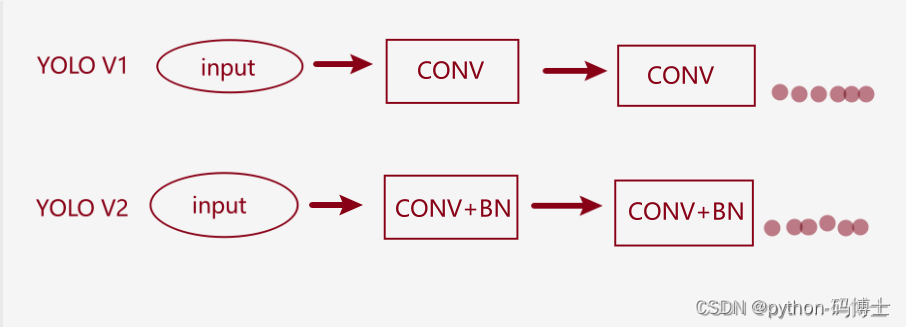
可以这样理解,加上BN之后就相当于月考,有利于下一步的发展。不加BN相当于年考,中间学的怎么样不清楚。 - 从第一张图可以看到,经过Batch Normalization之后的网络会提升2%的mAP。
- 目前Batch Normalization已经成为网络模型必备处理方法了。也就是一个学校发现月考挺好,然后其他学校纷纷效仿,最终全国统一了。
High Resolution Classifier(高分辨率预训练分类网络)
- V1训练的时候用的224224,测试的时候用的448448。效果并不是很好,V2在训练时额外加了10次448*448的微调,使得mAP提升了约4%。
- 为什么 V1不用224224呢?可能是因为当时设备不允许啊!训练时间也要呈平方倍增长。比如224224训练用了10h,448*448就要用100h,伤不起。

New Network:Darknet-19
YOLO v2采用Darknet-19,其网络结构如下图所示,包括19 1919个卷积层和5 55个max pooling层,主要采用3 × 3卷积和1 × 1卷积,这里1 × 1卷积可以压缩特征图通道数以降低模型计算量和参数,每个卷积层后使用BN层以加快模型收敛同时防止过拟合。最终采用global avg pool 做预测。采用 YOLO v2,模型的mAP值没有显著提升,但计算量减少了。
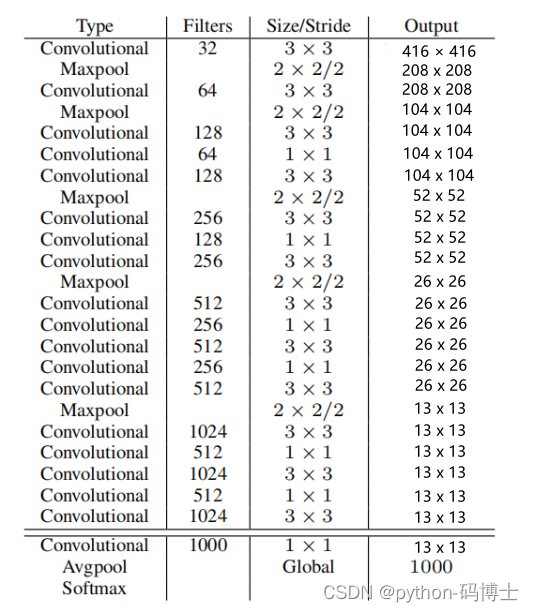
- 实际输入图像大小416x416,为什么是416x416?首先要可以整除 2 5 2^5 25,因为5次降采样后h和w的一个像素点相当于原始图像的32个像素点,最后做还原用到。
- 最终得到13*13的Grid Cell。
- 缩减网络,让图片的输入分辨率为416x416,目的是让后面产生的卷积特征图宽高都为奇数,这样就可以产生一个center cell。因为大物体通常占据了图像的中间位置,可以只用一个中心的cell来预测这些物体的位置,否则就要用中间的4个cell来进行预测,这个技巧可稍稍提升效率。也就是所有大物体的中心点都落在了center cell,如果是偶数的话,所有大物体的中心位置就可能分布在4个cell中。
各参数计算方法:
神经网络中的filter (滤波器)与kernel(内核)的概念
可参考 :https://blog.csdn.net/m0_54634272/article/details/128519246
-
kernel(内核): 是一个2维矩阵,长 × 宽;
-
filter(滤波器):是一个三维立方体,长× 宽 × 深度, 其中深度便是由多少张内核构成;
-
两者之间的关系:可以说 kernel 是filter 的基本元素, 多张kernel 组成一个filter;
-
那么, 一个filter 中应该包含多少张 kernel 呢?
答:是由输入的通道个数所确定, 即,输入通道是3个特征时,则后续的每一个filter中包含3张kernel ;
filter输入通道是包含128个特征时, 则一个filter中所包含kernel 数是128张。 -
那么一层中应该有多少个filter 构成呢?
答: 我们想要提取多少个特征,即我们想要输出多少个特征,那么这一层就设置多少个filter; -
一个filter 负责提取某一种特征,N个filter 提取 N 个特征;
-
Filters(卷积核个数):是可以人为指定的,在
out_channels设置,如果设置为2,就会生成两个形状相同,初始参数不同的filter。 -
Size:卷积核的大小
-
Stride(步长):往往决定了输出特征图的大小。h/stride和w/stride。
-
Q:为什么要加入1x1的卷积层
- A:我们以下面这张图举例,经过Maxpool层之后特征图的个数翻倍了。3x3的卷积无非是特征浓缩的过程。
3x3接3x3和3x3接1x1再接3x3的效果是差不多的,不过第二种节省了很多参数。还保持了整体网络结构没有太大影响。

- A:我们以下面这张图举例,经过Maxpool层之后特征图的个数翻倍了。3x3的卷积无非是特征浓缩的过程。
-
Q:maxpool特征图个数翻倍?
- A:池化操作就是用一个kernel,比如2x2的,就去输入图像上对应2x2的位置上,选取这四个数字中最大的作为输出结果。这就叫最大池化。
输出通道=输入通道
这里特征图翻倍是因为作者设置了out_channels=2
- A:池化操作就是用一个kernel,比如2x2的,就去输入图像上对应2x2的位置上,选取这四个数字中最大的作为输出结果。这就叫最大池化。
-
Q:1x1节省了参数?
- A:参数的概念:确定一个卷积层的结构所需要的信息(例如:kernel_size, stride, padding, input_channels, output_channels),看下这张图,显然是(1)图的计算量和参数少。
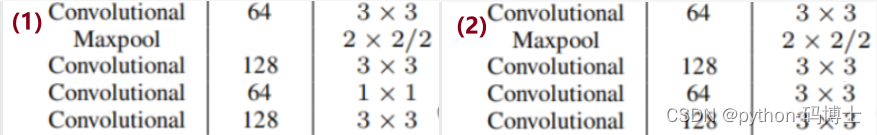
- A:参数的概念:确定一个卷积层的结构所需要的信息(例如:kernel_size, stride, padding, input_channels, output_channels),看下这张图,显然是(1)图的计算量和参数少。
Anchor卷积
在YOLO-V1中使用全连接层进行bounding box预测,这会丢失较多的空间信息,导致定位不准。YOLO-V2借鉴了Faster R-CNN中anchor的思想,我们知道Faster R-CNN中的anchor就是在卷积特征图上进行滑窗采样,每个中心预测9个不同大小和比例的anchor。
总的来说YOLO-V2移除了全连接层(以获得更多的空间信息)使用anchor boxes去预测bounding boxes。并且YOLO-V2中的anchor box可以同时预测类别和坐标。具体做法如下:
- 跟
YOLO-V1比起来,去掉最后的池化层,确保输出的卷积特征图有更高的分辨率。 - 使用卷积层降采样(
factor=32),使得输入卷积网络的416x416的图片最终得到13x13的卷积特征图(416/32=13)。 - 由
anchor box同时预测类别和坐标。因为YOLO-V1是由每个cell来负责预测类别的,每个cell对应的两个bounding box负责预测坐标。YOLO-V2中不再让类别的预测与每个cell绑定一起,而是全部都放到anchor box中去预测。
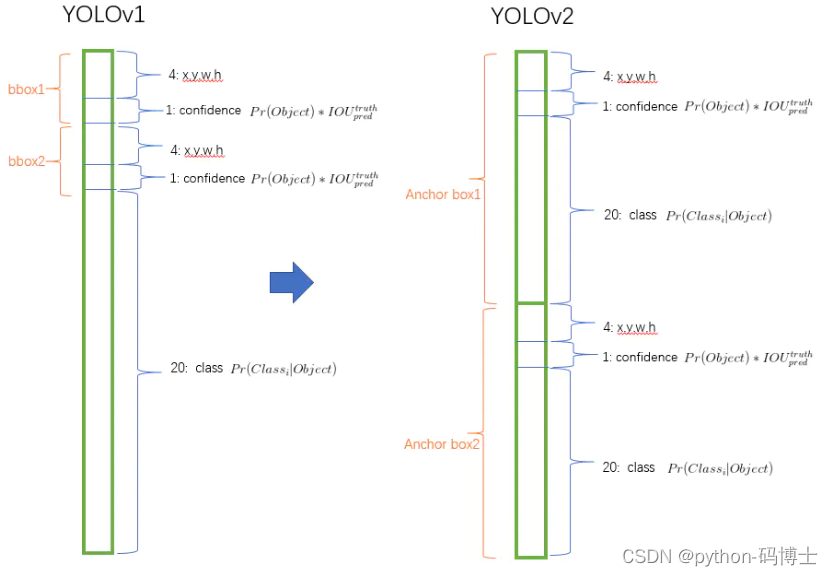
加入了anchor之后,我们来计算下,假设每个cell预测9个anchor,那么总计会有13x13x9=1521个boxes,而之前的网络仅仅预测了7x7x2=98个boxes。具体每个网格对应的输出维度如下图:
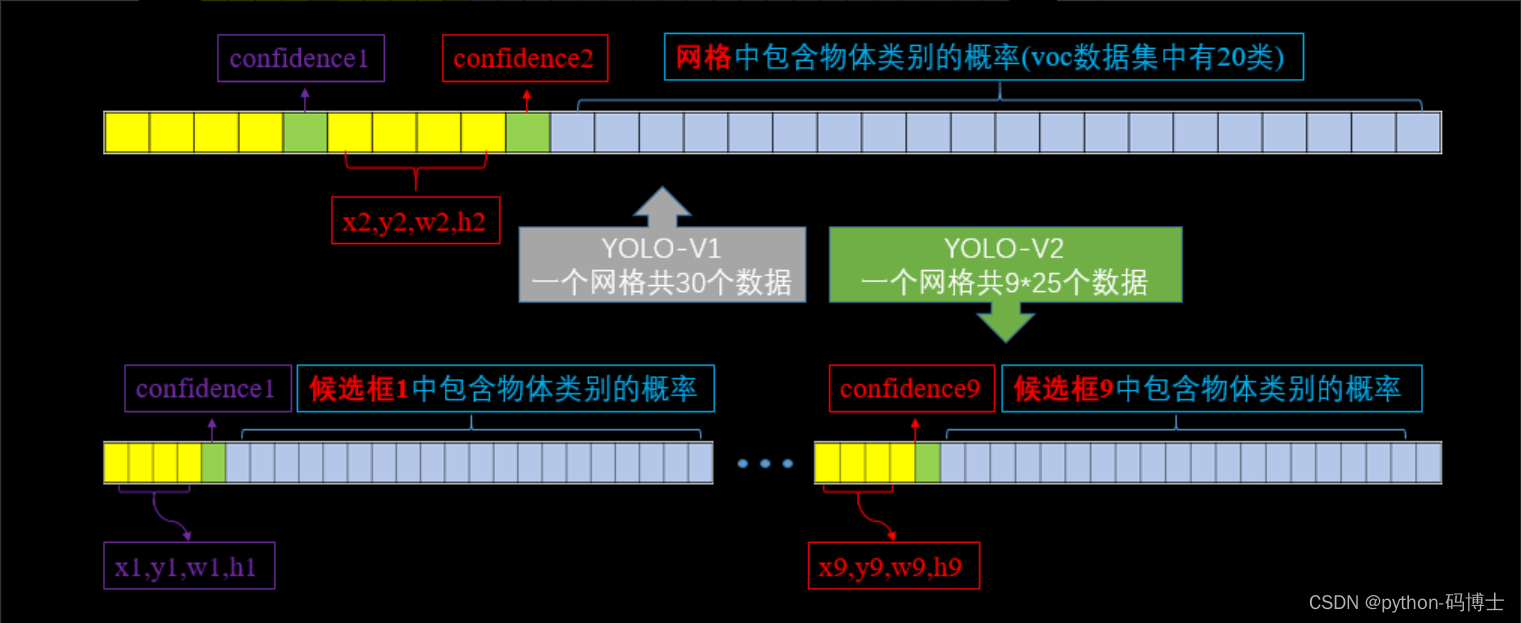
YOLOV1和YOLOV2网格输出维度对比
我们知道YOLO-V1输出7x7x30的检测结果,如上图,其中每个网格输出的30个数据包括两个候选框的位置,有无包含物体的置信度,以及网格中包含物体类别的20个概率值。
YOLO-V2对此做了些改进,将物体类别的预测任务交给了候选框,而不再是网格担任了,那么假如是9个候选框,那么就会有9x25=225个数据的输出维度,其中25为每个候选框的位置,有无物体的置信度以及20个物体类别的概率值。这样的话,最后网络输出的检测结果就应该是13x13x225,但是上面网络框架中是125,是怎么回事儿呢?我们接着看。
Dimension Clusters(Anchor Box的宽高由聚类产生)
在Faster R-CNN和SSD中,先验框都是手动设定的,带有一定的主观性。 YOLO v2采用k-means聚类算法对训练集中的边界框做了聚类分析,选用boxes之间的IOU值作为聚类指标。综合考虑模型复杂度和召回率,最终选择5 个聚类中心,得到5个先验框,发现其中中扁长的框较少,而瘦高的框更多,更符合行人特征。通过对比实验,发现用聚类分析得到的先验框比手动选择的先验框有更高的平均IOU值,这使得模型更容易训练学习。
- Faster R-CNN和SSD的做法
- 大致就是这么个意思:设定了3种长宽不同的比例,然后根据物体可能的大小设定3个不同的尺寸,最终得到9个Anchor Box。但是这样真的好吗?不太符合现实中的物体。
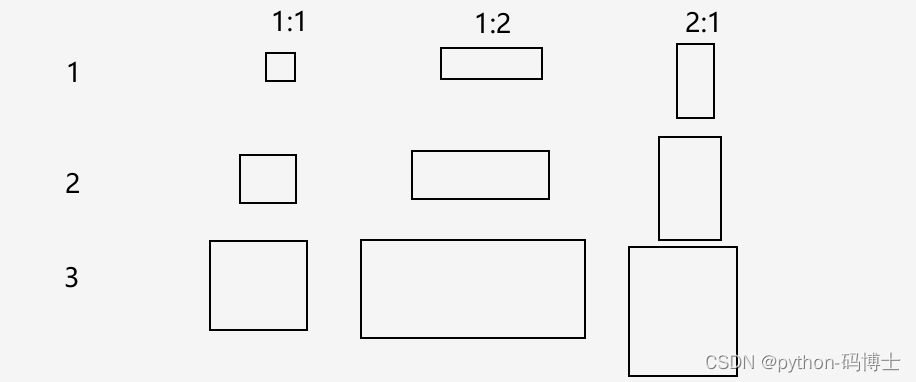
- YOLO V2聚类提取先验框的做法
- 首先数据集是我真实需要的,我想从这里面提取出5类框,这样做显然更符合实际情况。于是就按照大小、长宽比等根据K-mean算法得到了更接近实际的5类先验框。
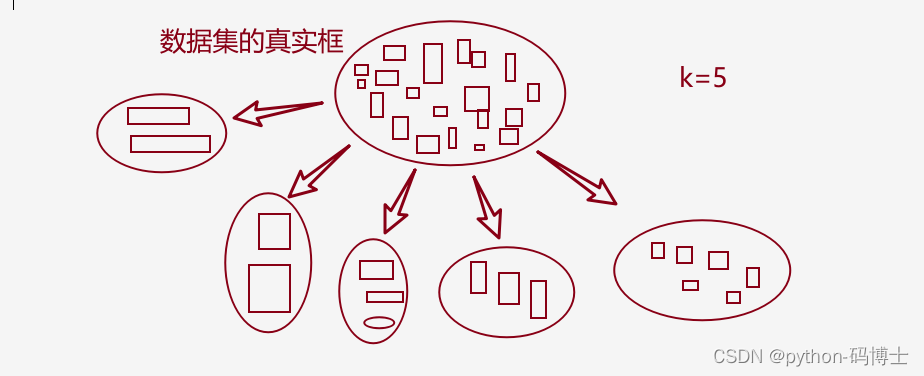
- 首先数据集是我真实需要的,我想从这里面提取出5类框,这样做显然更符合实际情况。于是就按照大小、长宽比等根据K-mean算法得到了更接近实际的5类先验框。
K-means聚类中的距离
在使用anchor时,Faster R-CNN中anchor boxes的个数和宽高维度往往是手动精选的先验框(hand-picked priors),如果能够一开始就选择了更好的,更有代表性的先验boxes维度,那么网络就应该更容易学到精准的预测位置。YOLO-V2中利用K-means聚类方法,通过对数据集中的ground truth box做聚类,找到ground truth box的统计规律。以聚类个数k为anchor boxes个数,以k个聚类中心box的宽高为anchor box的宽高。
可以复习一下K-means聚类算法:
基础聚类算法:K-means算法
但是,如果按照标准的k-means使用欧式距离函数,计算距离的时候,大boxes比小boxes产生更多的error。但是,我们真正想要的是产生好的IoU得分的boxes(与box大小无关),因此采用了如下距离度量方式:
d
(
b
o
x
,
c
e
n
t
r
o
i
d
s
)
=
1
−
I
O
U
(
b
o
x
,
c
e
n
t
r
o
i
d
s
)
d(box,centroids) = 1 - IOU(box,centroids)
d(box,centroids)=1−IOU(box,centroids)
假设有两个框,一个是3x5,一个框是5x5,那么欧式距离计算为:
(
2.5
−
1.5
)
2
+
(
2.5
−
2.5
)
2
=
1
\sqrt{{(2.5-1.5)^2+(2.5-2.5)^2}}=1
(2.5−1.5)2+(2.5−2.5)2=1
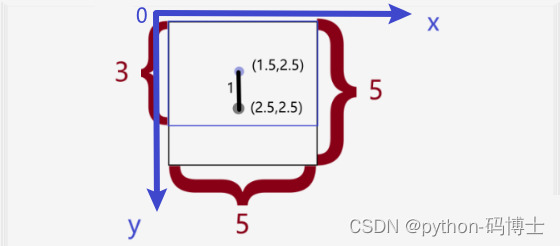
IoU的计算如下,为了统计宽高聚类,这里默认中心点是重叠的:
(
3
∗
5
)
/
(
5
∗
5
)
=
0.6
(3*5)/(5*5)=0.6
(3∗5)/(5∗5)=0.6
当两个框无限接近时,IOU值也就趋于1,此时
d
(
b
o
x
,
c
e
n
t
r
o
i
d
s
)
d(box,centroids)
d(box,centroids)接近于0,K-means聚类算法将这样的框聚在一起。
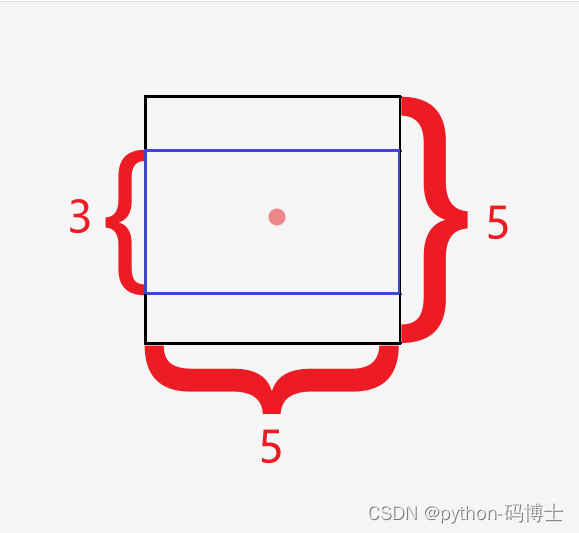
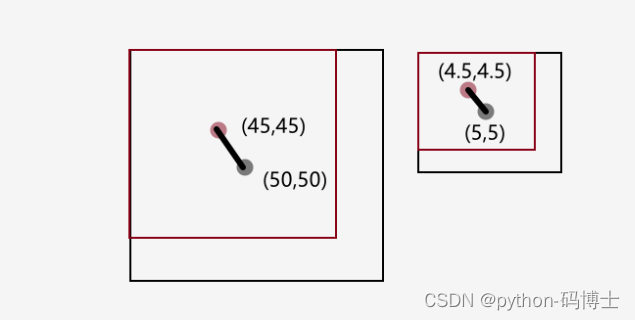
- Q:为什么说不使用欧式距离呢?
- A:距离度量如果使用标准的欧氏距离,大盒子会比小盒子产生更多的错误。例100x100和90x90的盒子与10x10和9x9的盒子。因此这里使用其他的距离度量公式。
- 说人话:k不是等于5嘛。这样做会把大多数小中盒子聚在一起,而大盒子占据了其他4份,显然不科学。
-
(
50
−
45
)
2
+
(
50
−
45
)
2
=
50
\sqrt{{(50-45)^2+(50-45)^2}}=50
(50−45)2+(50−45)2=50
(
5
−
4.5
)
2
+
(
5
−
4.5
)
2
=
0.5
\sqrt{{(5-4.5)^2+(5-4.5)^2}}=0.5
(5−4.5)2+(5−4.5)2=0.5
这里,为了得到较好的聚类个数,算法里做了组测试,如下图,随着k的增大IoU也在增大,但是复杂度也在增加。
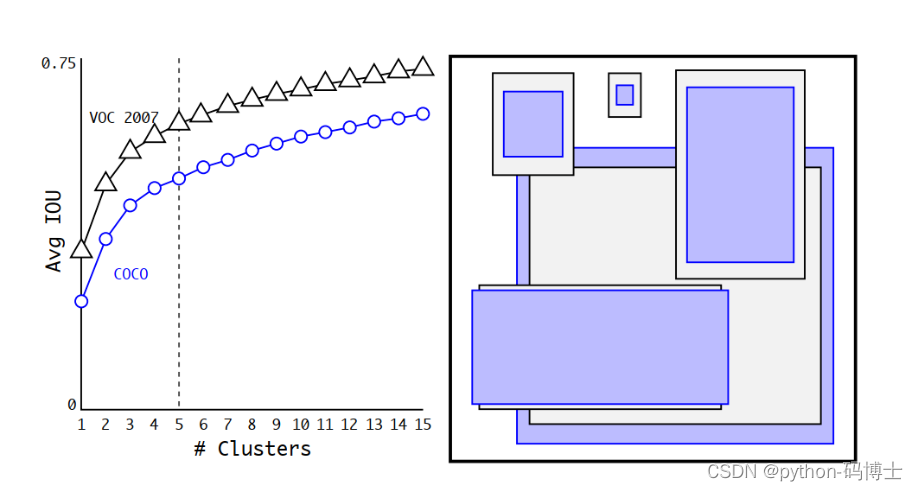
k-means聚类个数的选择
所以平衡复杂度和IoU之后,最终得到k值为5。可以从右边的聚类结果上看到5个聚类中心的宽高与手动精选的boxes是完全不同的,扁长的框较少,瘦高的框较多(黑丝框对应VOC2007数据集,紫色框对应COCO数据集)。 这样就能明白为什么上面网络框架中的输出为什么是13x13x125了,因为通过聚类选用了5个anchor。
- 虽然说k值越大分的越细,差距也就越小,但是也不能设置太多的
anchor boxes吧,而且在5之后曲线上升的就不是那么快了,所以选了一个折中的值5。 - 通过增加anchor boxes的方法虽然mAP值有所下降,但是查全率(Recall)提升了7个点。

直接位置预测(Directed Location Prediction)
Yolo v2同RPN等网络一样使用了卷积来生成anchor boxes的位置信息。但它在使用像Faster-RCNN或SSD中那样来进行位置偏离计算的方法来预测predicted box的位置时发现训练时非常容易出现震荡。如下为RPN网络所用的位置计算公式:
x
=
x
p
+
w
p
∗
t
x
x = x_p+w_p *t_x
x=xp+wp∗tx
y
=
y
p
+
h
p
∗
t
y
y = y_p+h_p *t_y
y=yp+hp∗ty
- bbox :中心为 ( x p , y p ) (x_p,y_p) (xp,yp);宽高为 ( w p , h p ) (w_p,h_p) (wp,hp)
- 当tx=1时,则将bbox在x轴向右移动wp;tx=-1,则将bbox在y轴向左移动wp。y也是同样的逻辑
- 上面的坐标转换很容易懂,但不好训练。因为 x,y 并没有遵守什么约束,所以可能预测的 bbox 会遍布一张图片任何角落。
- V2中没有使用偏移量,而是选择相对gride cell 的偏移量。
根据上面的学习,我们知道这里用到了类似Faster R-CNN中的anchor,但是使用anchor boxes有一个问题,就是会使得模型不稳定,尤其是早期迭代的时候。大部分的不稳定现象出现在预测box的中心坐标时,所以YOLO-V2没有用Faster R-CNN的预测方式。
YOLO-V2位置预测(tx,ty)就是预测边界框中心点相对于对应cell左上角位置的相对偏移值,为了将边界框中心点约束在当前cell中,使用了sigmoid函数处理偏移值,这样预测的偏移值就在(0,1)范围内了(每个cell的尺度看作1)。
- Q:为什么加上sigmoid之后就是(0,1)了呢?
- A:看图就知道了
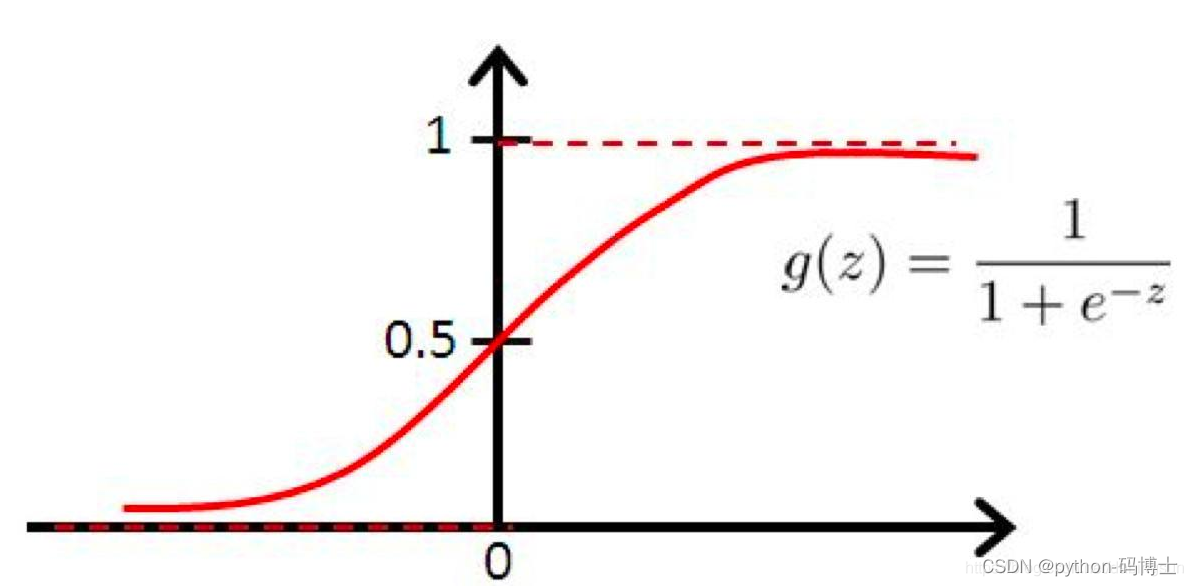
- A:看图就知道了
我们具体来看以下这个预测框是怎么产生的?
在网格特征图(13x13)的每个cell上预测5个anchor,每一个anchor预测5个值:(tx,ty,tw,th,t0)。如果这个cell距离图像左上角的边距为(cx,cy),cell对应的先验框(anchor)的长和宽分别为(pw,ph),那么网格预测框为下图蓝框。如下图:
P
r
(
o
b
j
e
c
t
)
∗
I
O
U
(
b
,
o
b
j
e
c
t
)
=
σ
(
t
0
)
Pr(object)*IOU(b,object) = \sigma(t_0)
Pr(object)∗IOU(b,object)=σ(t0)
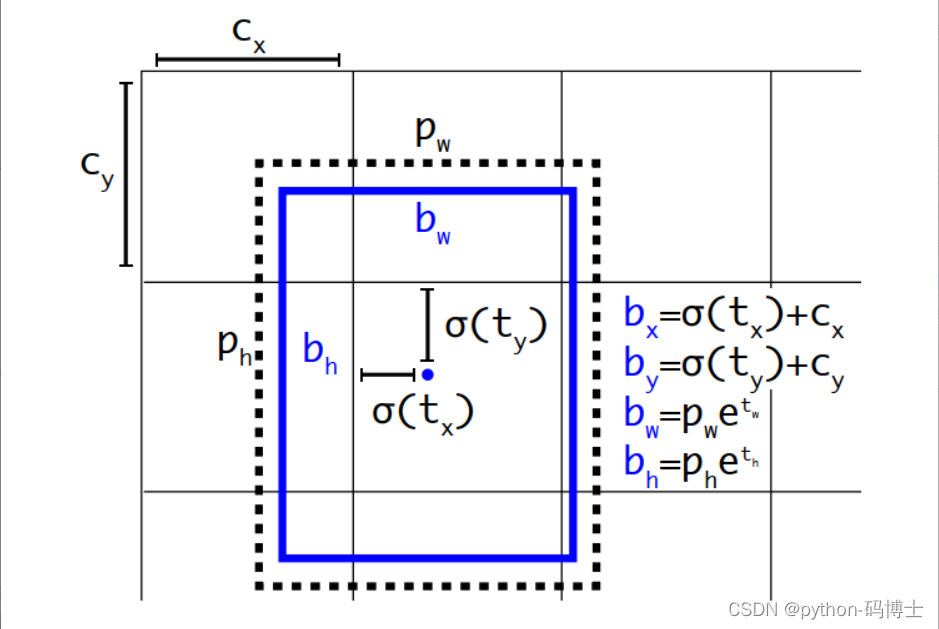
其中
b
x
,
b
y
,
b
w
,
b
h
,
σ
b_x,b_y,b_w,b_h,σ
bx,by,bw,bh,σ 分别代表predict box的中心坐标x,y和它的长和宽,还有目标为物体b的概率。
候选框如何生成?
总的来说,虚线框为anchor box就是通过先验聚类方法产生的框,而蓝色的为调整后的预测框。算法通过使用维度聚类和直接位置预测这亮相anchor boxes的改进方法,将mAP提高了5%。接下来,我们继续看下还有哪些优化?
细粒度特征(Fine-Grained Features)
感受野
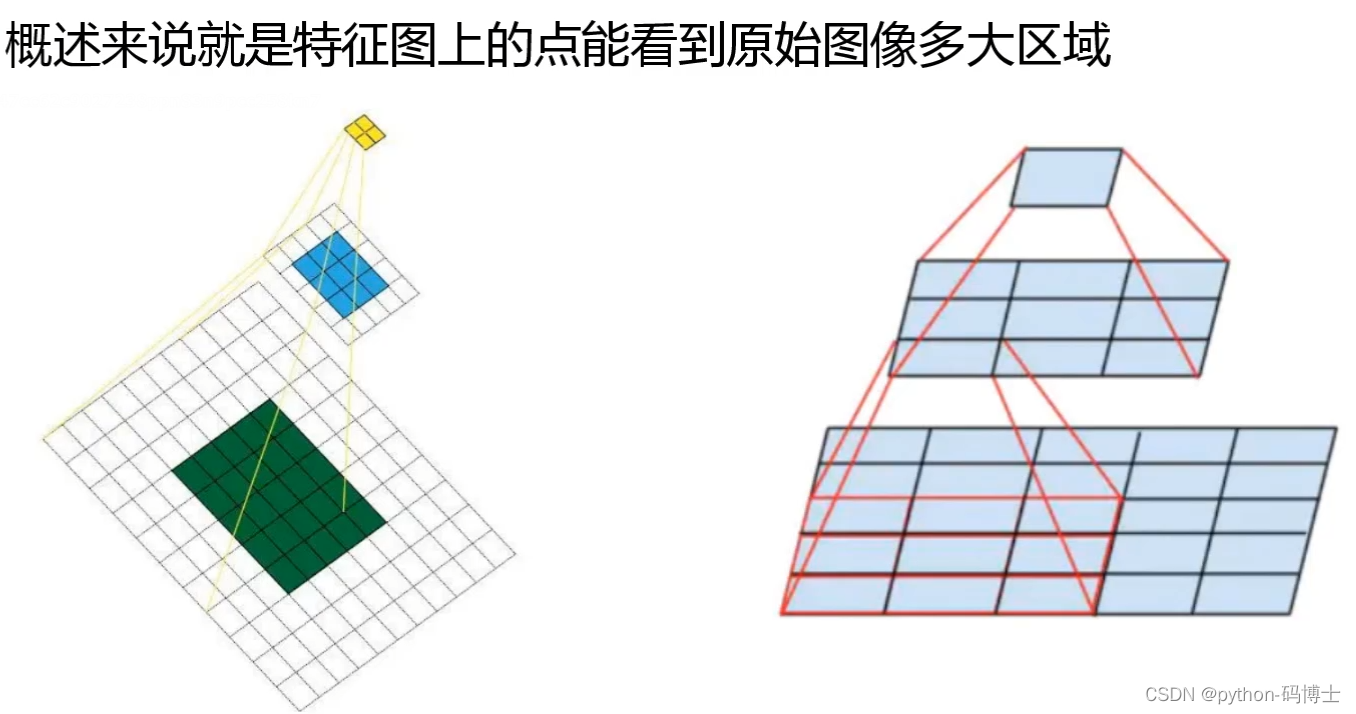
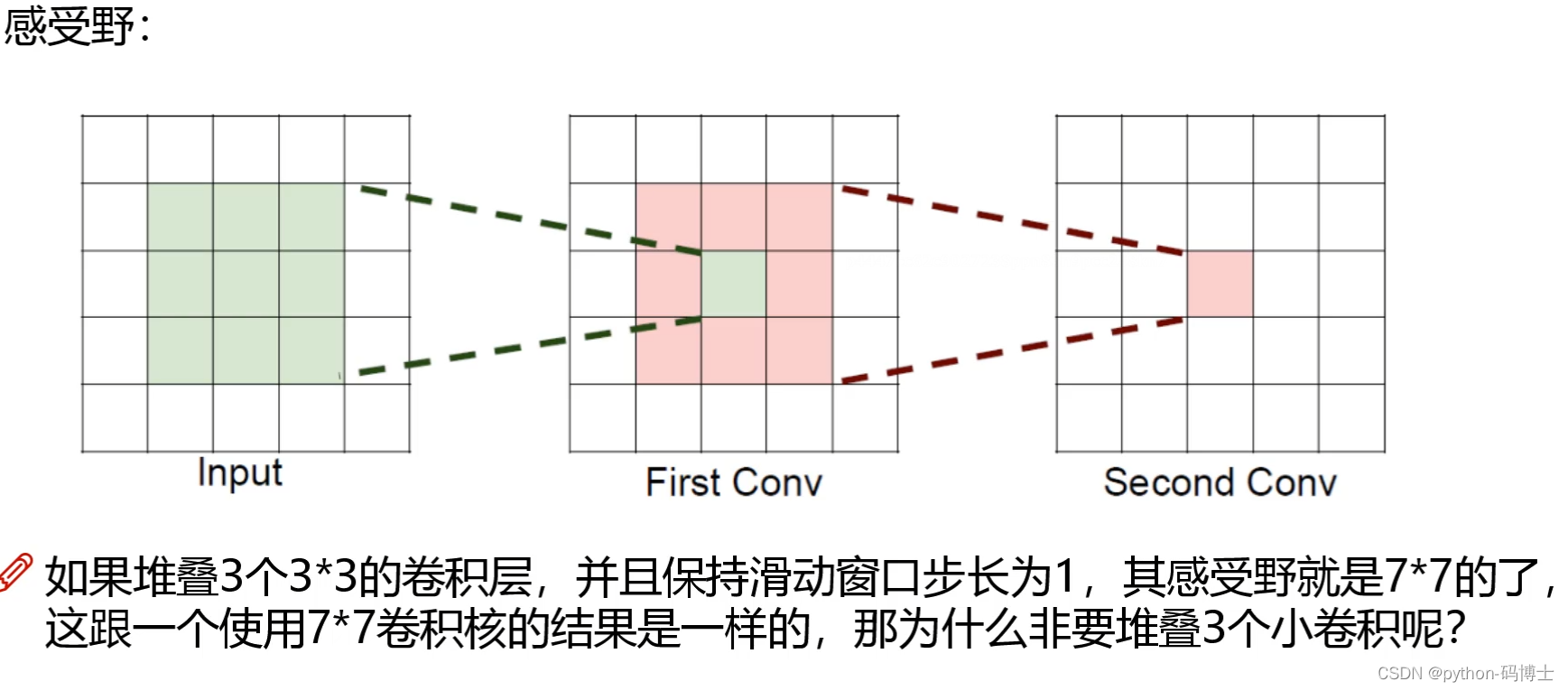

3个3*3卷积核的优势:
- 省参数
- 每一次卷积之后都要进行BN,相当于月考,而一个7X7的卷积核就相当于期末考。
SSD通过不同Scale的Feature Map来预测Box,实现多尺度,不熟悉的可以看下面:
目标检测算法SSD结构详解
而YOLO-V2则采用了另一种思路:通过添加一个passthrough layer,来获取之前的26x26x512的特征图特征,也就是前面框架图中的第25步。对于26x26x512的特征图,经过重组之后变成了13x13x2048个新的特征图(特征图大小降低4倍,而channels增加4倍),这样就可以与后面的13x13x1024特征图连接在一起形成13x13x3072大小的特征图,然后再在此特征图的基础上卷积做预测。如下图:
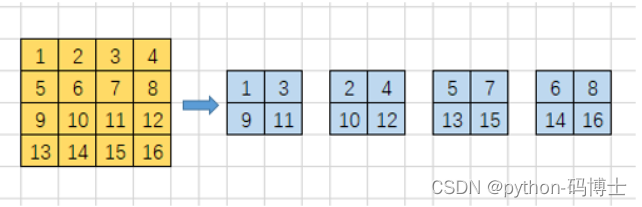
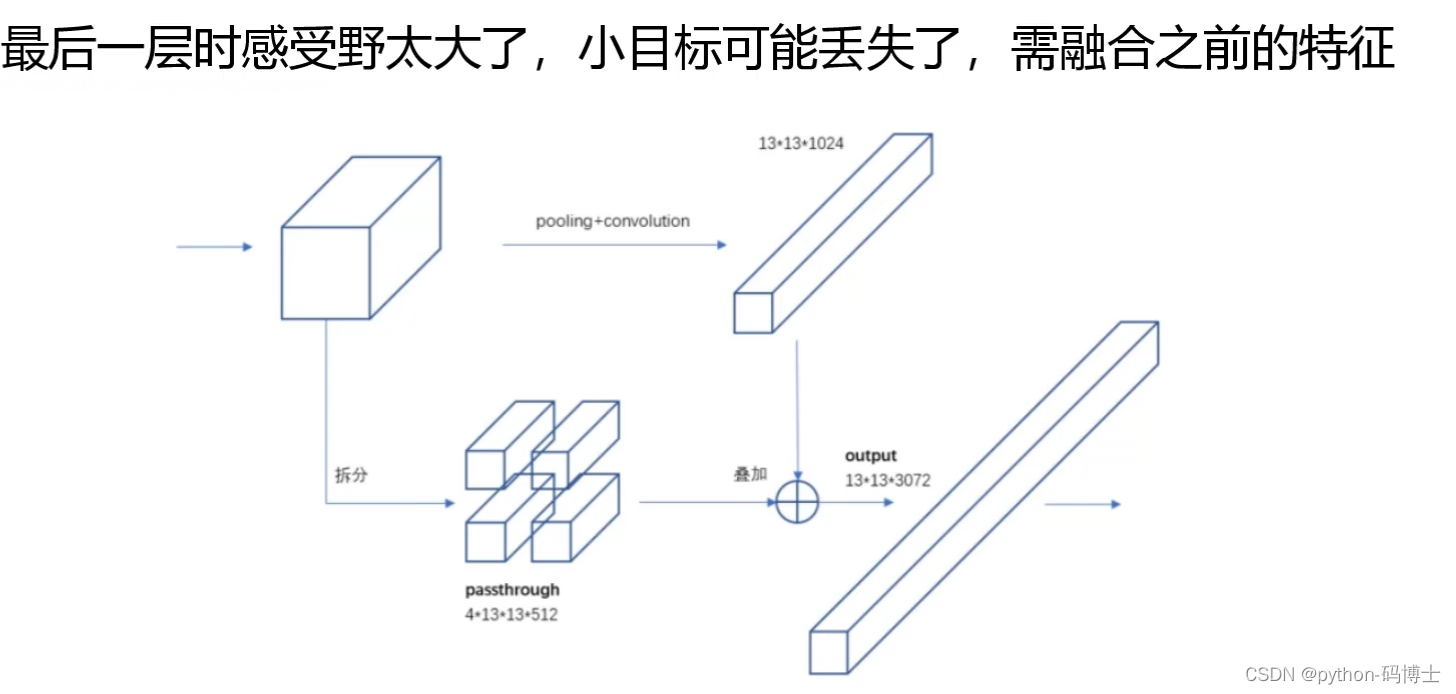
YOLO-V2算法使用经过扩展后的特征图,利用了之前层的特征,使得模型的性能获得了1%的提升。
多尺度训练(Multi-Scale)
原始的YOLO网络使用固定的448x448的图片作为输入,加入anchor boxes后输入变成了416x416,由于网络只用到了卷积层和池化层,就可以进行动态调整,检测任意大小的图片。为了让YOLO-V2对不同尺寸图片具有鲁棒性,在训练的时候也考虑到了这一点。
不同于固定网络输入图片尺寸的方法,每经过10批训练(10 batches)就会随机选择新的图片尺寸。网络使用的降采样参数为32,于是使用32的倍数{320,352,…,608},最小尺寸为320x320,最大尺寸为608x608。调整网络到相应维度然后继续训练。这样只需要调整最后一个卷积层的大小即可,如下图:
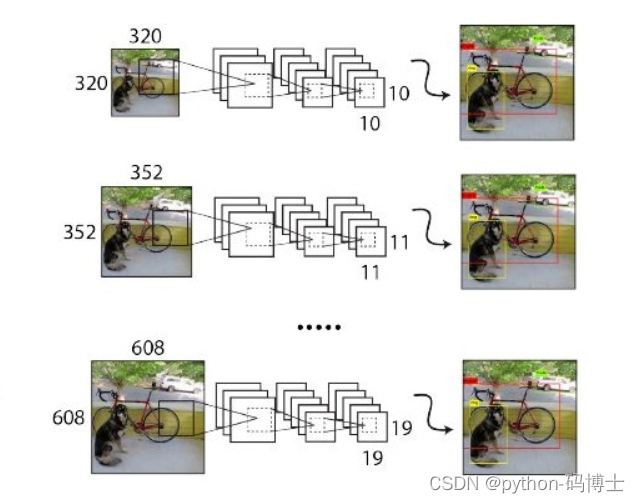
这种机制使得网络可以更好地预测不同尺寸的图片,同一个网格可以进行不同分辨率的检测任务,在小尺寸图片上YOLO-V2运行更快,在速度和精度上达到了平衡。



















 4784
4784





 到【灌水乐园】发言
到【灌水乐园】发言







