







- 这是我的概率论期中作业
一、理论基础
1.概述
方差分析又称“变异数分析”或“F检验”,用于多个样本平均数差异的显著性检验。一般来说,一个“结果”是受一个或多个“因素”影响的,在试验中也是如此,我们称试验中要考察的指标为“试验指标”,称因素所处的状态为该因素的“水平”。试验指标的差异的来源又可以分为两个方面:
- 组间差异:因处理的不同而造成的差异,是受控制的
- 组内差异:是一种随机误差,因环境因素或个体差异造成,不受控制
显然,不受控制的因素不是我们研究的目的,而根据受控制的因素的数目,试验又可以分为单因素试验、双因素实验、多因素试验。通俗的讲,方差分析研究的就是试验中可控变量的不同水平对试验指标的影响究竟有多大。
2.举例
- (单因素试验)研究不同生长素浓度对幼苗生长的影响…
- (单因素实验)研究不同肥料种类对水稻生长的影响…
- (双因素试验)研究不同催化剂种类和温度条件对化学反应速率的影响…
3.前提
- 试验中的样本是相互独立且随机的
- 试验中的样本来自各自的正态分布总体
- 上述正态分布总体的方差相等
4.数学模型–以单因素试验为例
我们假设一个因素有s个不同的水平,对于每一个水平又有n个样本,则每一个样本可以这样表示:
X
i
j
X_{ij}
Xij (i表同水平下不同样本,j表不同水平),那么由3中的提出的前提:
X
i
j
∼
N
(
μ
j
,
σ
2
)
X_{ij} \sim N(\mu_{j},\sigma^2)
Xij∼N(μj,σ2)
稍作变换:
X
i
j
−
μ
j
∼
N
(
0
,
σ
2
)
X_{ij}-\mu_{j} \sim N(0,\sigma^2)
Xij−μj∼N(0,σ2)
若记(
X
i
j
−
μ
j
X_{ij}-\mu_{j}
Xij−μj)为随机误差
ε
i
j
\varepsilon_{ij}
εij ,那么:
X
i
j
=
μ
j
+
ε
i
j
X_{ij} = \mu_{j} + \varepsilon_{ij}
Xij=μj+εij
ε
i
j
∼
N
(
0
,
σ
2
)
\varepsilon_{ij} \sim N(0,\sigma^2)
εij∼N(0,σ2)
(1)(2)以及 i、 j 的各自范围构成了单因素方差分析的数学模型。
5.方差分析的任务
对于上述数学模型,我们需要检验这样的假设:
H
0
:
μ
1
=
μ
2
=
μ
3
=
⋯
=
μ
s
H
1
:
μ
1
,
μ
2
,
μ
3
,
⋯
,
μ
s
不
全
相
等
H_0:\mu_1=\mu_2=\mu_3=\cdots=\mu_s\\ H_1:\mu_1,\mu_2,\mu_3,\cdots,\mu_s不全相等
H0:μ1=μ2=μ3=⋯=μsH1:μ1,μ2,μ3,⋯,μs不全相等
除此之外,方差分析还将对
μ
\mu
μ 以及
σ
2
\sigma^2
σ2 等参数作出估计 。
6.模型优化
进一步设:
总
平
均
:
μ
=
1
n
∑
j
=
1
s
n
j
μ
j
总平均:\mu =\frac{1}{n}\sum_{j=1}^{s}n_j\mu_j
总平均:μ=n1j=1∑snjμj
效 应 : δ j = μ j − μ 效应:\delta_j=\mu_j-\mu 效应:δj=μj−μ
模型优化为:
X
i
j
=
μ
+
ε
i
j
+
δ
i
j
∑
j
=
1
s
n
j
δ
j
=
0
ε
i
j
∼
N
(
0
,
σ
2
)
X_{ij} = \mu + \varepsilon_{ij} +\delta_{ij}\\ \sum_{j=1}^{s}n_j\delta_j = 0\\ \varepsilon_{ij} \sim N(0,\sigma^2)
Xij=μ+εij+δijj=1∑snjδj=0εij∼N(0,σ2)
这样做可以使假设变得更加明了:
H
0
:
δ
1
=
δ
2
=
⋯
=
δ
s
=
0
H
1
:
δ
1
,
δ
2
,
δ
3
,
⋯
,
δ
s
不
全
相
等
H_0:\delta_1=\delta_2=\cdots=\delta_s=0\\ H_1:\delta_1,\delta_2,\delta_3,\cdots,\delta_s不全相等
H0:δ1=δ2=⋯=δs=0H1:δ1,δ2,δ3,⋯,δs不全相等
二、问题研究
1.问题提出
为了将方差分析应用到实际之中,我需要找到一个有意义的项目。经过慎重的考虑,我决定应用方差分析去考察一个学校里不同的班级对成绩的影响。理由如下:
- 考试成绩数据相对容易获取,具有大量的样本
- 贴近生活,有一定的现实意义
- 前面提到过应用方差分析的前提–样本需要来自正态总体,恰巧,我们的考试成绩一般是符合正态分布的
2.试验目的
研究某高中的语文、数学、英语、理综成绩与班级(不同老师)差异之间的关系。
3.采集数据
以某高中的期中考试成绩为样本,数据来自互联网。避免侵犯隐私,隐去了姓名学号,只保留了班级、成绩等必要信息。采集到的样本共有417*4个,成绩分为4种:语文、数学、英语、理综,班级共有5个,即1~5班。部分数据展示:
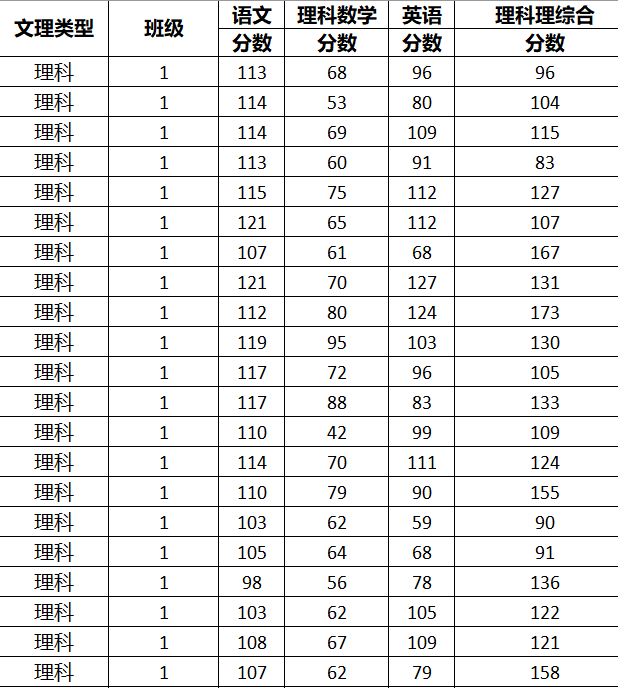
三、解决方法
使用matlab软件可以很方便的进行方差分析工作。
1.matlab方差分析函数
matlab提供了名为 anova 的一系列用于方差分析的函数。现在要用到的是其中的单因素方差分析函数,一般的调用格式是:
p
=
a
n
o
v
a
1
(
X
,
g
r
o
u
p
)
p=anova1(X,group)
p=anova1(X,group)
其中,输入 X 是样本值矩阵,group 代表不同的水平。在本项目中,X是由成绩构成的矩阵,group 是不同的班级构成的矩阵。输出p是检验的p值,这与前面提到的假设有关,一般认为,若p<0.05,则拒绝原假设
H
0
H_0
H0,接受
H
1
H_1
H1;否则接受
H
0
H_0
H0。
2.matlab生成图表中的统计量
在调用上述函数返回p值得同时,matlab还会自动生成标准的单因素方差分析表和箱线图。
表中含有的统计量有:
- 误差来源:前面概述中提到的两种误差,及其总和;
- 平方和(SS):两种来源的方差及其总和各自对应的平方和;
- 自由度(df):两种来源的方差中及其总和中取值不受限制的变量个数;
- 均方(MS):计算公式 M S = S S d f MS=\frac{SS}{df} MS=dfSS
- F值:计算公式 F = M S 1 M S 2 F=\frac{MS_1}{MS_2} F=MS2MS1,F值越大,说明差异越大,我们接受假设 H 0 H_0 H0的可能性越小;
- p值:即前面提到的p值。与F值不同,p值越小,越不可能接受 H 0 H_0 H0
箱线图可以直观展现数据的最大值、3/4数据点、中位数、1/4数据点、最小值,以及异常数据。
3.多重比较
为什么需要多重比较?因为我们做出的假设只能判断每一组的均值相等或不等,但没有办法知道两两之间均值的关系。matlab提供了multcompare函数用于多重比较,返回一个十分具体的、每两组之间的、以均值比较的值矩阵,以及一个用线段标出每一组样本均值置信区间的图形,进行比较的规则是若两条线段之间没有重叠部分,说明对应的两组之间均值差异显著。
4.代码展示
限于篇幅,这里只选取了比较有代表性的语文成绩和数学成绩进行了研究。
X=xlsread('score.xls'); %导入成绩表
Class=X(3:end,1); %导入班级
Ch=X(3:end,2); %导入语文成绩
Math=X(3:end,3); %导入数学成绩
Eg=X(3:end,4); %导入英语成绩
Sc=X(3:end,5); %导入理综成绩
[p1,table1,states1]=anova1(Ch,Class); %语文成绩方差分析
[p2,table2,states2]=anova1(Math,Class); %英语成绩方差分析
c=multcompare(states2); %多重比较
三、试验结果
1.语文成绩的方差分析表及箱线图:
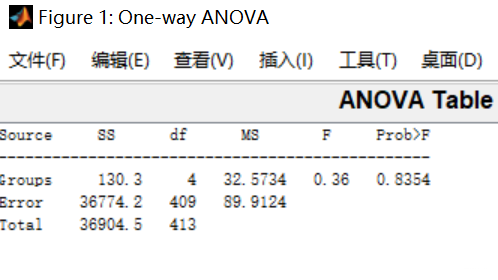
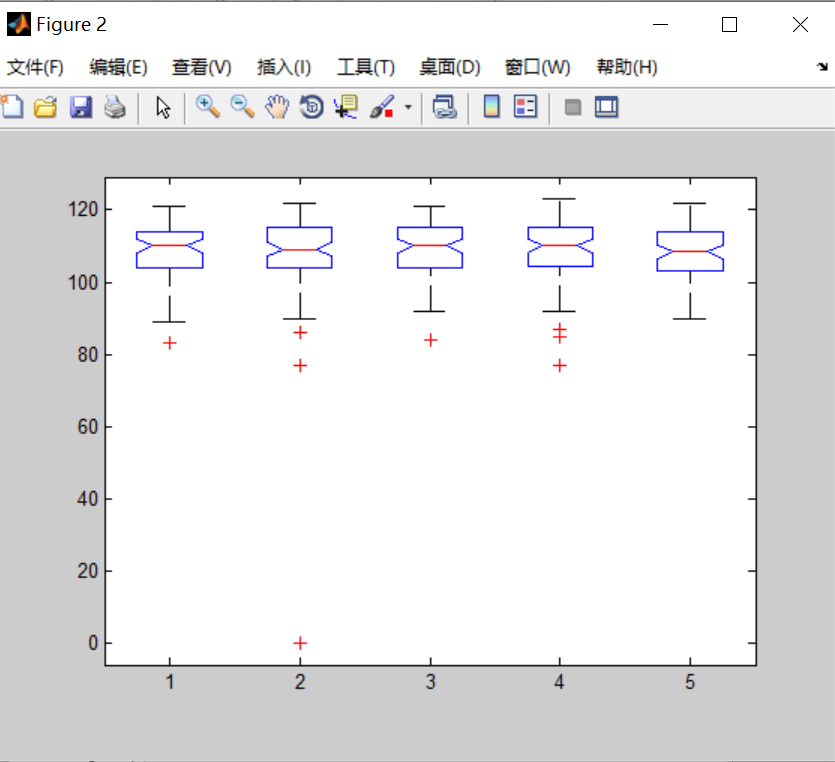
从图表中可以看出:
- 从箱线图来看,语文成绩集中分布在100~120之间,5个班皆是如此。各班均值十分接近;
- 从分析表来看,组内均方大于组间均方,F值略小,p值=0.8354,由此可以认为对于语文成绩而言更应该接受原假设 H 0 H_0 H0,即各班语文成绩均值相等。
2.数学成绩的方差分析表及箱线图:
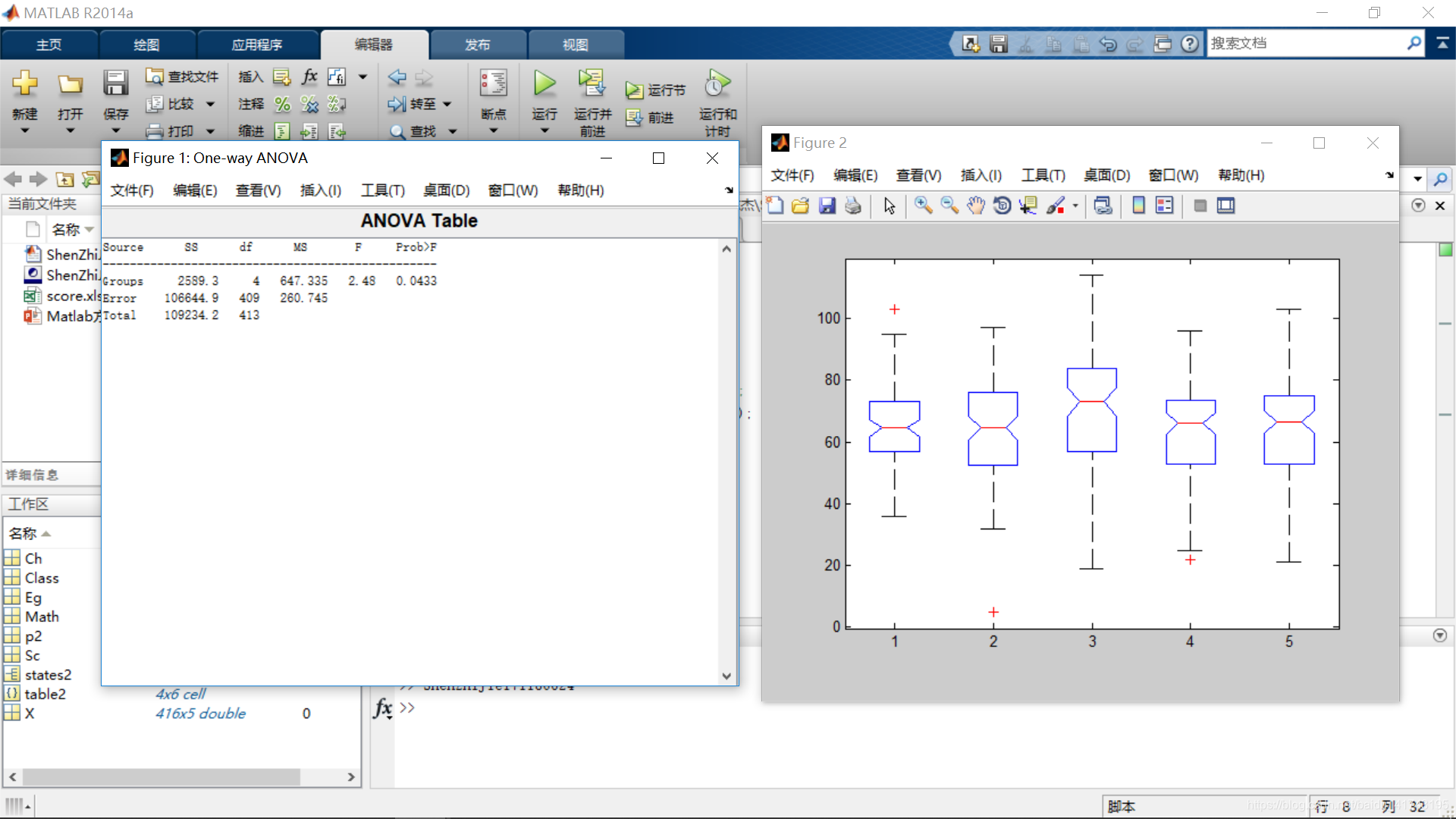
从图表中可以看出:
- 从箱线图来看,各班数学成绩的分布范围很广,最大值最小值差距很大。就班与班之间来看,3班的数学成绩均值明显要好于其他四个班;
- 从分析表来看,组间均方大于组内均方,F值略大,p值=0.0433 < 0.05,也就是说对于数学成绩而言,我们应该推翻假设 H 0 H_0 H0,接受假设 H 1 H_1 H1,即各班数学成绩的均值不全相等。
3.多重分析
显然,对于语文成绩而言,因为我们判定各班均值相等,所以进行多重分析没有什么意义。对于数学成绩,通过箱线图判断是3班的数学成绩均值要明显好于其他四个班,现在通过多重分析进行验证。结果如:
可以看出源于箱线图的猜想基本正确。更准确地说,3班的数学成绩的均值置信区间与4班、5班几乎没有重叠部分,同时也明显高于1班、2班。几乎可以断定造成在数学成绩上均值的不等(假设
H
1
H_1
H1)是由于3班的成绩均值明显高于其他四个班。
四、总结
方差分析大体上来看是对均值的比较,但绝不是仅仅求平均数而已。方差分析更著重的是对“方差”的比较,是对组内随机误差与组间控制变量之间关系的研究。除了成绩分析之外,方差分析还可以应用到生活的诸多方面,在科学研究方面同样应用广泛。

















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









