







 主动学习1、定义2、步骤3、分类3.1 Membership Query Synthesis3.2 Stream-Based Selective Sampling3.3 Pool-Based Sampling4、Query Strategy Frameworks4.1 Uncertainty Sampling4.1.1 least confident4.1.2 Margin Sampling4.1.3 Entropy4.2 Query-By-Committee4.2.1 Vote Entropy(投票熵)
主动学习1、定义2、步骤3、分类3.1 Membership Query Synthesis3.2 Stream-Based Selective Sampling3.3 Pool-Based Sampling4、Query Strategy Frameworks4.1 Uncertainty Sampling4.1.1 least confident4.1.2 Margin Sampling4.1.3 Entropy4.2 Query-By-Committee4.2.1 Vote Entropy(投票熵)
主动学习
1、定义
主动学习的主要目的是通过减少标注成本的情况下,得到模型的performance也不差。
在整个机器学习建模的过程中有人工参与的部分和环节,并且通过机器学习的方法筛选出合适的候选集给人工标注。其主要思路是:通过机器学习的方法获取那些比较‘难’分类的样本数据,交给人工进行标注,然后将人工标注的数据加入到训练集中重新训练机器学习的model,迭代进行下去,逐步提升模型的效果,将人工经验融入到机器学习的模型中。
在没有使用Active Learning的时候,通常来说系统会从样本中随机抽样一部分数据或者使用一些人工定义的规则来提供一些待标记的样本让人工进行标注。这样的做法或许会带来一定的效果提升,但其需要的标注数据量也会很大,标注的成本也是极高的。
2、步骤
在机器学习是建模过程中,通常包括样本选择,模型训练,模型预测,模型更新这几个步骤。在主动学习这个领域需要把标注候选集提取和人工标注这两个步骤加入整体的流程中。
1、机器学习模型:包括模型训练和预测两部分
2、待标注的数据候选集提取:依赖主动学习中的查询函数(Query Function)
3、人工标注:将标注候选集交给专家或者有业务经验的标注
4、获得标注后的数据:获得更有价值的样本数据
5、机器学习模型更新:将标注数据加入training data,更新模型,从而将人工标注的数据融入机器学习模型中,提升模型效果。
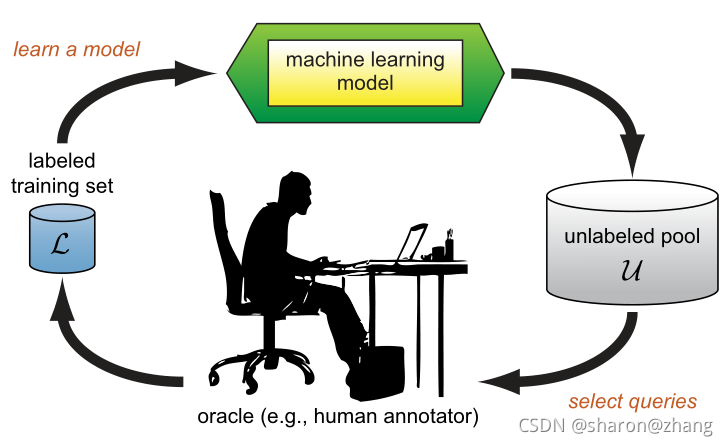
比较一下使用active learning的方式和random sample的方式所得到的模型
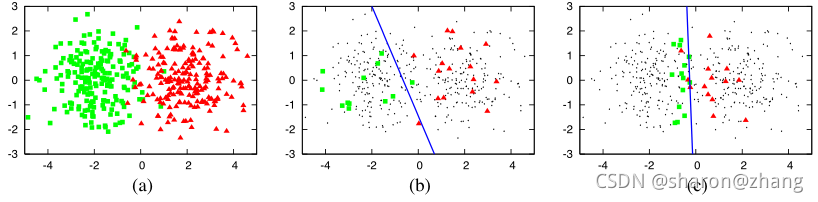
a是我们的两个类别的数据,b是随机选取30个样本数据做标注,并在训练逻辑回归模型,蓝色的线代表分类器的决策边界,其准确率为70%。c是利用active learning的方式选取的30个标注数据,然后再训练逻辑回归模型,其准确率达到90%。
所以可以看出,active learning具有的一定的优势,因为它在选取样本的时候,会优先选择分类器比较难分类的样本,将其作为标注数据的候选集,提高模型的性能。
3、分类
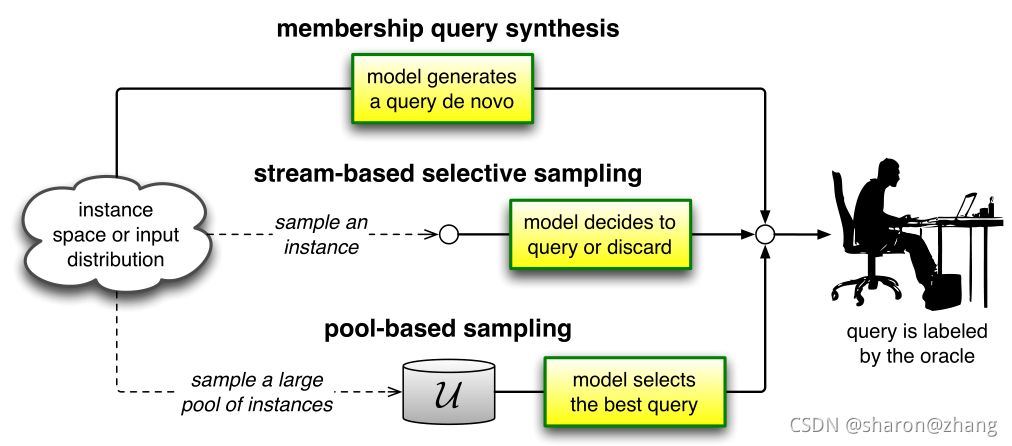
3.1 Membership Query Synthesis
学习者可以为输入空间中任何未标记实例请求标签,包括学习者从头生成的query,而不是从某些基本自然分布
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4062
4062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











