







 超级会员免费看
超级会员免费看
 本文介绍了差分熵的概念,作为连续型随机变量的熵,探讨了其与香农熵的区别,并通过实例展示了其可能为负的情况。此外,解释了差分熵在坐标变换下会变化的特性。接着,阐述了差分熵与香农熵的关系,证明了当离散化间距趋向于0时,两者的关系。最后,文章讲解了Kullback-Leibler(KL)散度,作为衡量两个概率分布差异的非对称度量,其在离散和连续情况下的应用,以及其主要性质。
本文介绍了差分熵的概念,作为连续型随机变量的熵,探讨了其与香农熵的区别,并通过实例展示了其可能为负的情况。此外,解释了差分熵在坐标变换下会变化的特性。接着,阐述了差分熵与香农熵的关系,证明了当离散化间距趋向于0时,两者的关系。最后,文章讲解了Kullback-Leibler(KL)散度,作为衡量两个概率分布差异的非对称度量,其在离散和连续情况下的应用,以及其主要性质。
一、差分熵(Differential Entropy)
我们已经在另外一篇文章(http://blog.csdn.net/baimafujinji/article/details/6469645)里介绍过香农熵的概念。一个非常重要的前提是,我们所讨论的香农熵是对离散型随机变量X而言的。现在我们要把这一概念推广到连续型随机变量的情况,此时便会得到一个非常重要的概念——差分熵。
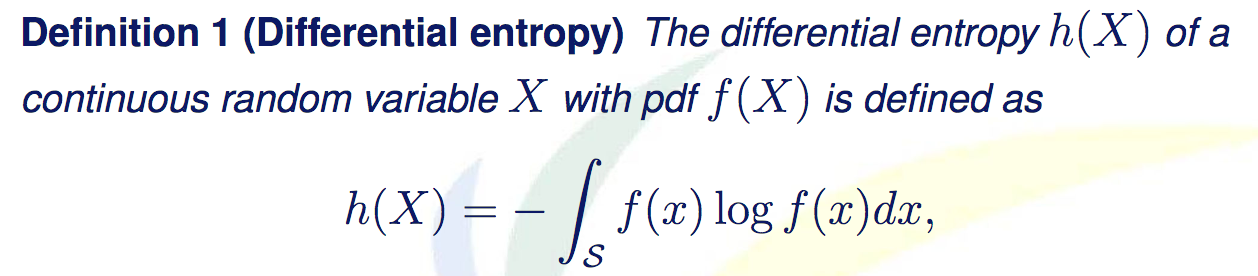
where S is the support set of the random variabl
一、差分熵(Differential Entropy)
我们已经在另外一篇文章(http://blog.csdn.net/baimafujinji/article/details/6469645)里介绍过香农熵的概念。一个非常重要的前提是,我们所讨论的香农熵是对离散型随机变量X而言的。现在我们要把这一概念推广到连续型随机变量的情况,此时便会得到一个非常重要的概念——差分熵。
 2300
2300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























