







LLM(5) | Encoder 和 Decoder 架构
文章目录
0. 目的
LLM 模型都是 transformer 结构的, 先前已经粗略翻阅了提出 transformer 模型的论文 “Attention Is All You Need”, 了解到了 transformer 结构是第一个完全基于 attention 的模型。
而在一些资料中, 看到有人对 LLM 进行分类, 分成 encoder-only, decoder-only, encode-decode 三类, 感觉很晕, 有必要了解下什么是 encoder 和 decoder。
本文主要是对 Understanding Encoder And Decoder LLMs 的翻译。
老规矩, 中文翻译后的括号里, 是个人粗浅的笔记和想法。
1. 概要
Several people asked me to dive a bit deeper into large language model (LLM) jargon and explain some of the more technical terms we nowadays take for granted. This includes references to “encoder-style” and “decoder-style” LLMs. What do these terms mean?
我被人问了好几次, 让我更深入的说说 LLM 术语, 并解释我们现在认为理所当然的一些更技术性的术语。 这包括对 encode-style 和 decoder-style 的 LLM。 这些术语是什么意思?
( LLM 火起来后, 经常发现一些缩写,术语, 让不了解它的人很晕。 有些老铁让作者讲讲。 作者 sebastianraschka 以前是 University of Wisconsin-Madison 的 Assistant Professor, 后来全职加入 lighting ai。)
To explain the difference between encoder- and decoder-style LLMs, I wanted to share an excerpt from my new book, Machine Learning Q and AI, that I completed last week.
为了解释 encoder-style 和 decoder-style LLM 的区别, 我想分享一段我上周完成的新书 “Machine Learning Q and AI” 的摘录。
(作者写了一本书, 看来在讲授 AI 方面有经验.)
This book is aimed at people who are already familiar with machine learning and deep learning (“AI”) and are interested in diving into more advanced topics. There are 30 chapters in total, covering various topics, including
这本书是针对那些已经熟悉机器学习和深度学习(AI), 并对深入更高级话题感兴趣的人, 总共有30章, 涵盖了各种主题,包括:
- 多GPU训练范式的解释 (Explanations of multi-GPU training paradigms)
- 微调 transformer (Finetuning transformers)
- encoder 和 decoder 风格的 LLM 之前的区别 (Differences between encoder- and decoder-style LLMs)
- 更多其他主题 (And many more!)
(看了下电子书需要购买,20+美元)
2. encoder 和 decoder 风格的 transformer (Encoder- And Decoder-Style Transformers)
Fundamentally, both encoder- and decoder-style architectures use the same self-attention layers to encode word tokens. However, the main difference is that encoders are designed to learn embeddings that can be used for various predictive modeling tasks such as classification. In contrast, decoders are designed to generate new texts, for example, answering user queries.
基本上, endoder- 和 decoder- 风格的架构, 都使用相同的 self-attention 层来编码单词标记 (word tokens). 然而, 主要区别在于 encoder 的设计,是为了学习可以用于各种预测建模任务的嵌入。 相反, decoder 的设计初衷是生成新的文本, 比如回答用户的查询。
(encoder 是为了学习一个 embedding, 这个 embedding 能用于预测性的任务比如分类; decoder 是为了生成新的文本, 比如回答问题.)
原始的 transformer (The original transformer)
The original transformer architecture (Attention Is All You Need, 2017), which was developed for English-to-French and English-to-German language translation, utilized both an encoder and a decoder, as illustrated in the figure below.
原始的 transformer 架构是在2017年的论文 “Attention Is All You Need” 里提出的, 左图是 encoder, 右图是 decoder:
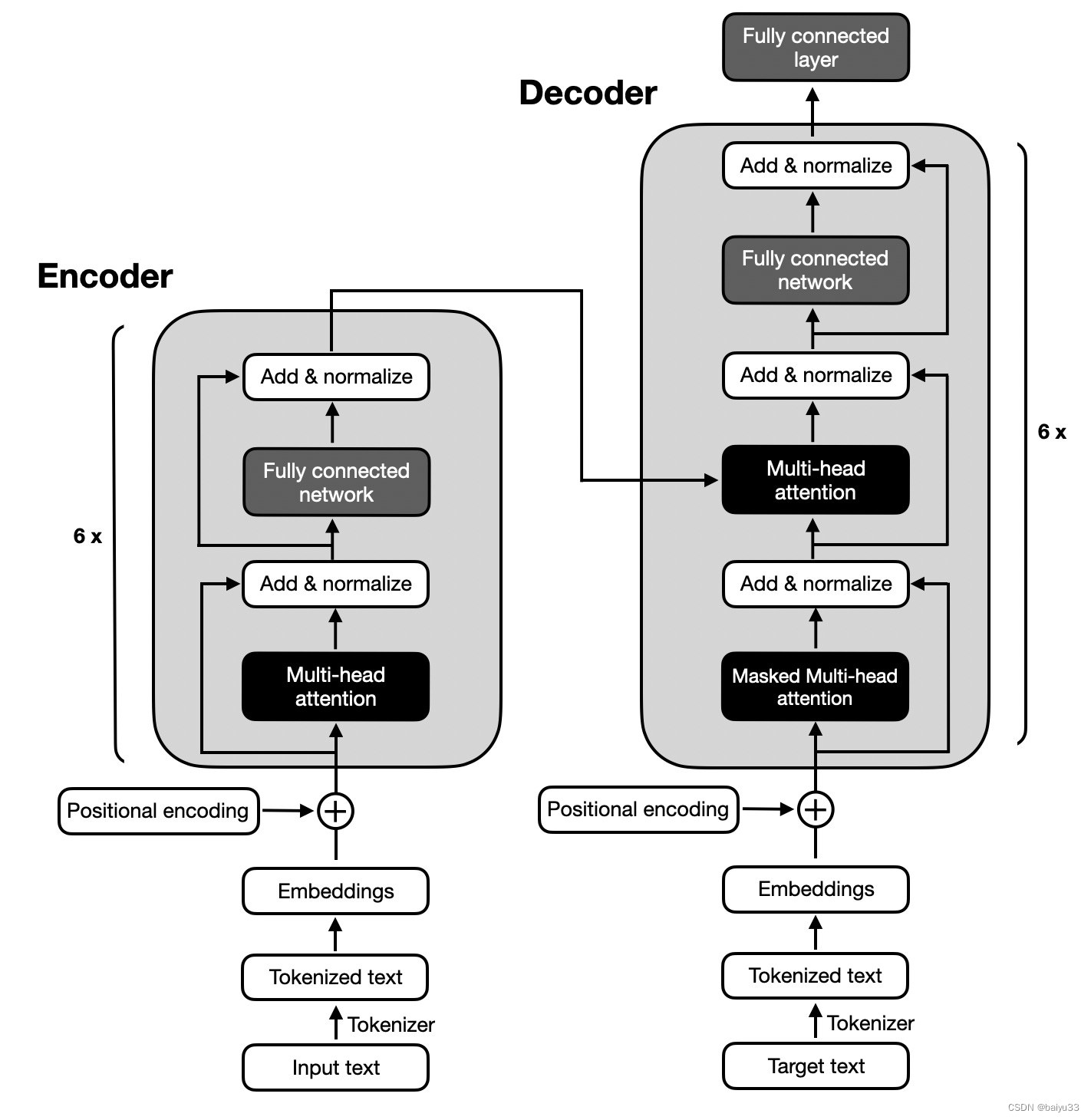
In the figure above, the input text (that is, the sentences of the text that is to be translated) is first tokenized into individual word tokens, which are then encoded via an embedding layer before it enters the encoder part.
在上图中, 输入文本(即要翻译的文本的句子)首先被分词成单个词元(token), 然后通过 embedding 层进行编码, 然后进入编码器部分。
Then, after adding a positional encoding vector to each embe
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









