






一、什么是逻辑回归
逻辑回归是一种统计学习方法,用于解决二分类问题。它基于线性回归的思想,通过对数据进行逻辑变换,将线性函数的输出值映射到[0, 1]范围内,从而得到一个概率值,表示样本属于某个类别的几率。
在逻辑回归中,被建模的是一个条件概率,即给定特征条件下目标变量属于某一类的概率。逻辑回归使用了名为sigmoid函数(也称为逻辑函数)的非线性函数,将线性回归的输出进行逻辑变换。
逻辑回归模型假设输入特征与目标变量之间存在着一个线性关系,然后通过最大似然估计等方法,估计模型的参数。具体来说,逻辑回归将线性函数的输出通过sigmoid函数转换为一个概率值,使用了Logistic函数的形式来建模条件概率。
逻辑回归有很多应用场景,如预测患者是否患有某种疾病、客户是否会购买某个产品、邮件是否为垃圾邮件等。它在实践中广泛应用,因为它简单而有效,计算开销小,容易解释模型的结果,并且能够处理高维特征空间的分类问题。
二、逻辑回归的原理
在“什么是逻辑回归”中,提到逻辑回归使用了名为sigmoid函数将线性回归的输出进行逻辑变换,Sigmoid函数(也称为逻辑函数)是一个S形的函数,它将任何实数值映射到0和1之间。它的数学表达式为:
三、逻辑回归实例
1.数据准备
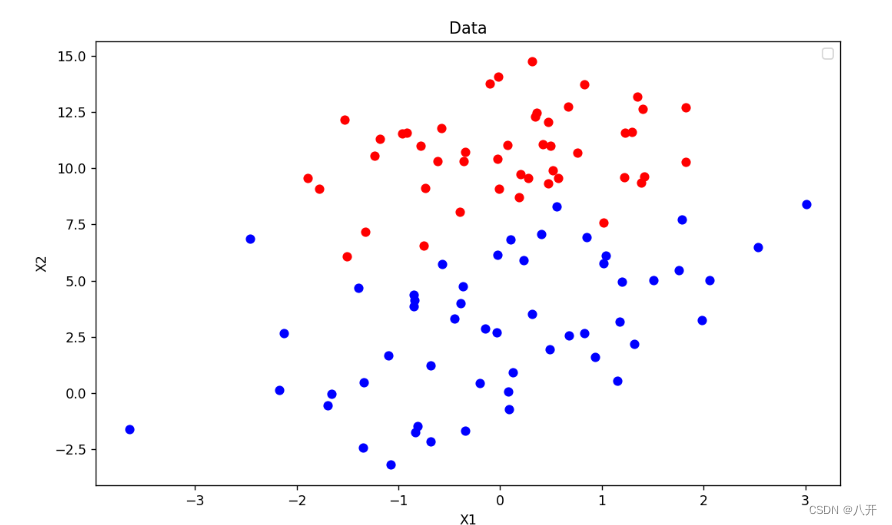
准备一份数据集,里面有一百份数据,每组数据包含两个特征值x1,x2,和一个类别,因为是二分法,所以类别取{0,1}。
x1,x2,Label
-3.346779,6.598435,0
-3.572691,10.751873,1
3.119014,9.896116,1
2.984582,8.020018,1
-0.311464,8.086096,1
2.882368,12.630635,1
-1.635797,13.661248,1
0.235125,13.906467,1
-0.383831,3.915327,0
1.350775,9.359368,1
0.217195,4.458460,0
-2.005690,9.439944,1
0.369123,11.048662,1
-3.454464,9.791264,1
-0.979069,1.703031,0
-1.042825,9.837216,1
-0.510284,10.951037,1
0.103680,11.077644,1
-3.615566,7.425991,0
3.590394,14.098319,1
-3.404072,7.738768,0
1.733468,4.048808,0
-3.863605,9.520848,1
-1.092603,11.738255,1
1.933252,8.377732,1
0.747766,8.403343,1
-2.003271,8.474311,1
-3.190953,0.479887,0
-2.671093,5.489693,0
-2.499644,10.600181,1
-1.359224,3.495547,0
-2.364849,9.153585,1
-2.671431,4.244890,0
1.052500,4.401043,0
1.973760,7.586393,1
1.263615,1.101084,0
-0.816525,12.887392,1
1.154387,8.674547,1
-2.046452,4.684154,0
1.434935,10.604420,1
-3.316157,4.771395,0
3.732391,13.878487,1
0.961582,13.647039,1
0.746453,5.061547,0
2.192805,11.049477,1
0.390464,14.095094,1
3.213523,2.523283,0
-1.006716,8.648946,1
-2.394018,2.628299,0
3.128700,3.316097,0
-1.598424,7.044168,0
0.882809,1.021032,0
0.200507,3.004039,0
1.743365,6.749293,1
-0.559414,12.700948,1
-2.690977,9.072812,1
1.670042,13.975356,1
3.642718,10.628240,1
-0.710466,2.427092,0
3.222439,9.380164,1
-2.679418,2.871734,0
2.900304,8.144637,1
2.985694,13.571508,1
-1.922006,7.246100,0
2.803586,11.104881,1
1.659858,14.593263,1
1.321891,10.106314,1
-1.775677,8.729331,1
3.700826,0.168873,0
0.594825,13.365155,1
-2.567871,7.053873,0
-2.409814,7.832318,0
0.151370,6.556311,1
0.404400,3.817120,0
......
2.导入数据集
def CreateData():
dataSet = []; labelSet = []
fr = open(r'文件路径')
for line in fr.readlines():
lineArr = line.strip().split(',')
dataSet.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelSet.append(int(lineArr[2]))
return dataSet, labelSet3.利用梯度上升法求回归系数
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def gradAscent(dataMatIn, classLabels):
dataMatrix = np.mat(dataMatIn)
labelMat = np.mat(classLabels).transpose()
m,n = np.shape(dataMatrix)
alpha = 0.001
maxCycles = 500
weights = np.ones((n,1))
for i in range(maxCycles):
h = sigmoid(dataMatrix*weights)
error = (labelMat - h)
weights = weights + alpha * dataMatrix.transpose() * error
return weights初始化后,设定学习率为步长,并设定最大迭代次数。通过多次迭代,利用梯度上升方法来更新权重,以优化回归系数。最终,将所得到的优化后的权重向量返回。
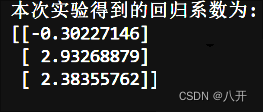
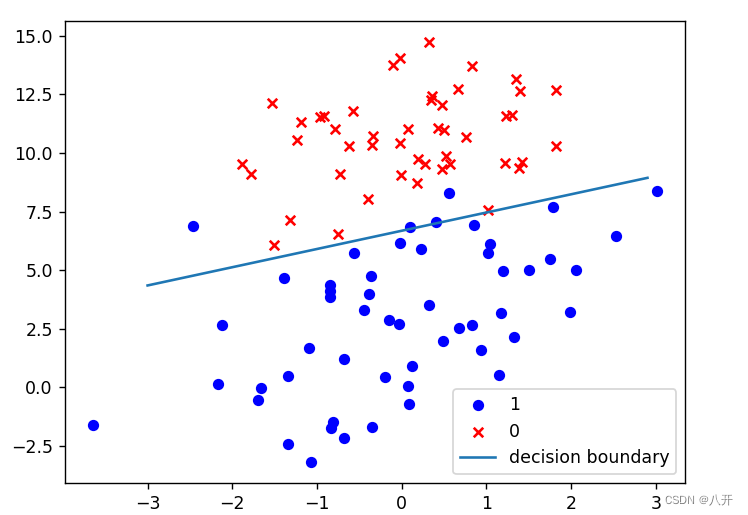
4.画出决策边界
上面已经解出了一组回归系数,通过Matplotlib画出决策边界。
def sigmoid(z):
# Sigmoid函数,计算1 / (1 + exp(-z))
return 1.0 / (1 + np.exp(-z))
def plotBestFit(wei):
weights = wei.getA()
dataMat, labelMat = CreateData()
dataArr = np.array(dataMat)
n = np.shape(dataArr)[0]
xcord1 = []
ycord1 = []
xcord2 = []
ycord2 = []
for i in range(n):
if int(labelMat[i]) == 1:
xcord1.append(dataArr[i, 1])
ycord1.append(dataArr[i, 2])
else:
xcord2.append(dataArr[i, 1])
ycord2.append(dataArr[i, 2])
# 绘制数据点
plt.scatter(xcord1, ycord1, s=30, c='red', marker='s')
plt.scatter(xcord2, ycord2, s=30, c='green')
x = np.arange(-3.0, 3.0, 0.1)
y = (-weights[0] - weights[1] * x) / weights[2]
# 绘制决策边界
plt.plot(x, y)
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()结果图















 2544
2544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









