







统计学习方法(3)逻辑回归
1、从线性回归到逻辑回归(模型)
1.1 线性模型:
给定数据集
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
n
,
y
n
)
}
\{(x_1, y_1), (x_2,y_2),...,(x_n,y_n)\}
{(x1,y1),(x2,y2),...,(xn,yn)},求参数
ω
\omega
ω满足如下回归模型:
y
^
=
ω
0
+
ω
1
x
1
+
ω
2
x
2
+
.
.
.
+
ω
n
x
n
\hat y = \omega_0+\omega_1x_1+\omega_2x_2+...+\omega_nx_n
y^=ω0+ω1x1+ω2x2+...+ωnxn
线性回归模型的向量形式:
y
^
=
ω
T
⋅
x
\hat y = \omega^T·\bf x
y^=ωT⋅x
其中:
θ
T
\theta^T
θT表示向量
θ
\theta
θ的转置(行向量变为了列向量);
x
\mathbf{x}
x为每个样本中特征值的向量形式,包括
x
1
x_{1}
x1,…,
x
n
x_{n}
xn,而且
x
0
x_0
x0 =1。
模型求解:
基于最小二乘思想(方差最小)求解模型参数
ω
\omega
ω:
ω
^
∗
=
a
r
g
m
i
n
1
m
∑
i
=
1
m
(
ω
^
T
x
(
i
)
−
y
(
i
)
)
2
\hat \omega^* = argmin{1\over m}\sum_{i=1}^m(\hat \omega^Tx^{(i)}-y{(i)})^2
ω^∗=argminm1i=1∑m(ω^Tx(i)−y(i))2
写成向量形式:
ω
^
∗
=
a
r
g
m
i
n
(
ω
^
T
x
−
y
)
T
(
ω
^
T
x
−
y
)
\hat \omega^* = argmin(\hat\omega^T\bf x-y)^T(\hat\omega^T\bf x-y)
ω^∗=argmin(ω^Tx−y)T(ω^Tx−y)
另
E
ω
^
=
(
ω
^
x
−
y
)
T
(
ω
^
x
−
y
)
E_{\hat\omega}=(\hat\omega\bf x-y)^T(\hat\omega\bf x-y)
Eω^=(ω^x−y)T(ω^x−y),对其求导:
∂
E
ω
^
∂
ω
^
=
2
X
(
X
T
ω
−
y
)
{\partial E_{\hat\omega} \over \partial{\hat\omega}}=2X(X^T\omega-y)
∂ω^∂Eω^=2X(XTω−y)
令导数为0,求正态方程得到:
ω
^
=
(
X
T
X
)
−
1
X
T
y
\hat \omega = (X^TX)^{-1}X^Ty
ω^=(XTX)−1XTy
注:当 X T X X^TX XTX列数大于行数(特征数大于样例数),为非满秩矩阵,需引入正则项。
若无法求解正态方程或数据量较大,可采用梯度下降法:
对任意一点
x
(
i
)
x^{(i)}
x(i)的梯度:
∂
E
ω
^
∂
ω
^
=
2
x
(
i
)
(
ω
T
x
(
i
)
−
y
)
{\partial E_{\hat\omega} \over \partial{\hat\omega}}=2x^{(i)}(\omega^T x^{(i)}-y)
∂ω^∂Eω^=2x(i)(ωTx(i)−y)
随机梯度下降:
ω
j
+
1
:
=
ω
j
−
α
∇
f
(
x
)
=
ω
j
+
α
(
y
(
i
)
−
ω
T
x
(
i
)
)
x
(
i
)
\omega_{j+1}:=\omega_j-\alpha\nabla f(x)=\omega_j+\alpha (y^{(i)}-\omega^T x^{(i)})x^{(i)}
ωj+1:=ωj−α∇f(x)=ωj+α(y(i)−ωTx(i))x(i)
   \;
1.2 逻辑回归:
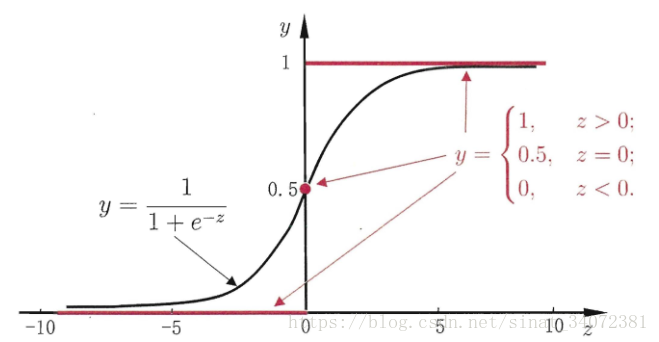
考虑二分类问题,由于线性回归输出值是
{
−
∞
,
+
∞
}
\{-\infty,+\infty\}
{−∞,+∞},应选取合适的映射函数
g
−
(
⋅
)
g^-(·)
g−(⋅),将模型输出映射为0/1值,这里想到单位阶跃函数可以做到,但是单位阶跃函数不连续,于是想到使用类似单位阶跃函数,又能单调可微的函数,所以可以使用对数几率函数,即sigmoid函数:
y
=
1
1
+
e
−
z
y={1\over 1+e^{-z}}
y=1+e−z1
sigmoid函数有一个非常好的性质,即当
z
z
z趋于正无穷时,
g
(
z
)
g(z)
g(z)趋于1,而当
z
z
z趋于负无穷时,
g
(
z
)
g(z)
g(z)趋于0,这非常适合于我们的分类概率模型。另外,它还有一个很好的导数性质:
g
′
(
z
)
=
g
(
z
)
(
1
−
g
(
z
)
)
g′(z)=g(z)(1−g(z))
g′(z)=g(z)(1−g(z))
这个通过函数对g(z)求导很容易得到,后面我们会用到这个式子。
线性模型带入sigmoid函数,得到:
h
ω
(
x
,
b
)
=
1
1
+
e
−
(
ω
T
x
+
b
)
h_{\omega}(x, b)={1\over 1+e^{-({\bf \omega}^T{\bf x}+b)}}
hω(x,b)=1+e−(ωTx+b)1
为了方便,将权重向量和输入向量加以扩充,于是得到逻辑回归模型:
h
ω
(
x
)
=
1
1
+
e
−
ω
T
x
h_{\omega}(\bf x)={1\over 1+e^{-{\bf \omega}^T{\bf x}}}
hω(x)=1+e−ωTx1
其中
x
x
x为样本输入,
h
ω
(
x
)
h_{\omega}(\bf x)
hω(x)为模型输出,可以理解为某一分类的概率大小。而
ω
\omega
ω为分类模型要求的模型参数。对于模型输出
h
ω
(
x
)
h_{\omega}(\bf x)
hω(x),我们让它和我们的二元样本输出
y
y
y(假设为0和1)有这样的对应关系:如果
h
ω
(
x
)
>
0.5
h_{\omega}(\bf x) > 0.5
hω(x)>0.5 ,即
ω
T
x
>
0
{\bf \omega}^T{\bf x} > 0
ωTx>0, 则
y
y
y为1;如果
h
ω
(
x
)
<
0.5
h_{\omega}(\bf x) < 0.5
hω(x)<0.5,即
ω
T
x
<
0
{\bf \omega}^T{\bf x} < 0
ωTx<0, 则
y
y
y为0;
h
ω
(
x
)
=
0.5
h_{\omega}(\bf x) = 0.5
hω(x)=0.5是临界情况,此时
ω
T
x
=
0
{\bf \omega}^T{\bf x} = 0
ωTx=0, 从逻辑回归模型本身无法确定分类。
h ω ( x ) h_{\omega}(\bf x) hω(x)的值越小,分类为0的的概率越高,反之,值越大的话分类为1的的概率越高。如果靠近临界点,则分类准确率会下降。
对于线性回归的损失函数,由于线性回归是连续的,所以可以使用模型误差的的平方和来定义损失函数。但是逻辑回归不是连续的,线性回归损失函数定义的经验就用不上了。不过我们可以用最大似然法来推导出我们的损失函数。
按照逻辑回归的定义,假设我们的样本输出是0或者1两类,属于伯努利分布(0-1分布),那么就有:
p
(
y
=
1
∣
x
)
=
h
ω
(
x
)
=
e
ω
T
x
1
+
e
ω
T
x
p(y=1|x) = h_{\omega}(\bf x) = {e^{{\bf \omega}^T{\bf x}}\over 1+e^{{\bf \omega}^T{\bf x}}}
p(y=1∣x)=hω(x)=1+eωTxeωTx
p
(
y
=
0
∣
x
)
=
1
−
h
ω
(
x
)
=
1
1
+
e
ω
T
x
p(y=0|x) = 1 - h_{\omega}(\bf x) = {1\over 1+e^{{\bf \omega}^T{\bf x}}}
p(y=0∣x)=1−hω(x)=1+eωTx1
其中,
ω
=
(
ω
(
1
)
,
ω
(
2
)
,
.
.
.
,
ω
(
n
)
,
b
)
T
,
x
=
(
x
(
1
)
,
x
(
2
)
,
.
.
.
,
x
(
n
)
,
1
)
T
\omega=(\omega^{(1)},\omega^{(2)},... ,\omega^{(n)},b)^T,x=(x^{(1)},x^{(2)},... ,x^{(n)},1)^T
ω=(ω(1),ω(2),...,ω(n),b)T,x=(x(1),x(2),...,x(n),1)T
2、策略
得到逻辑回归模型之后,考虑使用什么策略来学习模型。
2.1 极大似然估计
对于二分类,由于模型
y
i
∈
{
0
,
1
}
y_i\in \{0,1\}
yi∈{0,1}服从0-1分布,设:
P
(
Y
=
1
∣
x
)
=
ϕ
(
z
)
,
P
(
Y
=
0
∣
x
)
=
1
−
ϕ
(
z
)
P(Y=1|x) = \phi (z),P(Y=0|x) = 1-\phi (z)
P(Y=1∣x)=ϕ(z),P(Y=0∣x)=1−ϕ(z)则概率分布可写为:
p
(
y
i
∣
x
i
;
ω
^
)
=
ϕ
(
z
i
)
y
i
(
1
−
ϕ
(
z
i
)
)
1
−
y
i
p(y_i|x_i;\hat \omega) = \phi (z_i)^{y_i}(1-\phi (z_i))^{1-y_i}
p(yi∣xi;ω^)=ϕ(zi)yi(1−ϕ(zi))1−yi
由于概率分布已知,根据观测数据,可采用极大似然估计法来估计参数
ω
\omega
ω和
b
b
b。
通过概率分布写出联合概率密度:
L
(
ω
)
=
∏
i
=
1
n
p
(
y
(
i
)
∣
θ
,
ω
)
=
∏
i
=
1
n
ϕ
(
z
(
i
)
)
y
(
i
)
(
1
−
ϕ
(
z
(
i
)
)
)
(
1
−
y
(
i
)
)
L(\omega)=\prod_{i=1}^np(y^{(i)}|\theta, \omega) =\prod_{i=1}^n\phi(z^{(i)})^{y^{(i)}}(1-\phi(z^{(i)}))^{(1-y^{(i)})}
L(ω)=i=1∏np(y(i)∣θ,ω)=i=1∏nϕ(z(i))y(i)(1−ϕ(z(i)))(1−y(i))取对数可得:
l
(
ω
)
=
∑
i
=
1
n
l
n
p
(
y
(
i
)
∣
θ
,
ω
)
=
∑
i
=
1
n
y
(
i
)
l
n
[
ϕ
(
z
(
i
)
)
]
+
(
1
−
y
(
i
)
)
l
n
[
(
1
−
ϕ
(
z
(
i
)
)
)
]
l(\omega)=\sum_{i=1}^nlnp(y^{(i)}|\theta, \omega) =\sum_{i=1}^ny^{(i)}ln[\phi(z^{(i)})]+(1-y^{(i)})ln[(1-\phi(z^{(i)}))]
l(ω)=i=1∑nlnp(y(i)∣θ,ω)=i=1∑ny(i)ln[ϕ(z(i))]+(1−y(i))ln[(1−ϕ(z(i)))]
对
l
(
ω
)
l(\omega)
l(ω)求极大值,可求出最有可能的
ω
\omega
ω。
−
l
(
ω
)
=
∑
i
=
1
n
−
l
n
p
(
y
(
i
)
∣
θ
,
ω
)
=
−
∑
i
=
1
n
y
(
i
)
l
n
[
ϕ
(
z
(
i
)
)
]
+
(
1
−
y
(
i
)
)
l
n
[
(
1
−
ϕ
(
z
(
i
)
)
)
]
-l(\omega)=\sum_{i=1}^n-lnp(y^{(i)}|\theta, \omega) =-\sum_{i=1}^ny^{(i)}ln[\phi(z^{(i)})]+(1-y^{(i)})ln[(1-\phi(z^{(i)}))]
−l(ω)=i=1∑n−lnp(y(i)∣θ,ω)=−i=1∑ny(i)ln[ϕ(z(i))]+(1−y(i))ln[(1−ϕ(z(i)))]
最大化
l
(
ω
)
l(\omega)
l(ω)相当于最小化
−
l
(
ω
)
-l(\omega)
−l(ω),因此可以将
−
l
(
ω
)
-l(\omega)
−l(ω)作为损失函数
J
(
ω
)
=
−
l
(
ω
)
J(\omega) = -l(\omega)
J(ω)=−l(ω),求解参数。
2.2 损失函数
同其他统计学习方法一样,逻辑回归也可以使用损失函数来学习模型,逻辑回归使用的损失函数为对数损失函数:
L
(
Y
,
P
(
Y
∣
X
)
)
=
−
l
o
g
P
(
Y
∣
X
)
L(Y,P(Y|X))=-logP(Y|X)
L(Y,P(Y∣X))=−logP(Y∣X)
该模型的损失函数为:
P
(
ϕ
(
z
)
,
y
∣
x
;
ω
)
=
{
−
l
n
ϕ
(
z
)
,
if y=1
−
l
n
(
1
−
ϕ
(
z
)
)
,
if y=0
P(\phi(z), y|x; \omega)= \begin{cases} -ln\phi(z), & \text{if y=1} \\[2ex] -ln(1-\phi(z)), & \text{if y=0} \end{cases}
P(ϕ(z),y∣x;ω)=⎩⎨⎧−lnϕ(z),−ln(1−ϕ(z)),if y=1if y=0
由损失函数得到经验风险函数:
J
(
ω
^
)
=
−
1
n
∑
i
=
1
n
(
y
i
l
n
ϕ
(
z
(
i
)
)
+
(
1
−
y
i
)
l
n
(
1
−
ϕ
(
z
(
i
)
)
)
)
J(\hat \omega)=-{1\over n}\sum_{i=1}^n(y_iln\phi(z^{(i)})+(1-y_i)ln(1-\phi(z^{(i)})))
J(ω^)=−n1i=1∑n(yilnϕ(z(i))+(1−yi)ln(1−ϕ(z(i))))
同极大似然法得到的对数似然函数比较,
可以发现对数损失函数与极大似然估计的对数似然函数本质上是等价的,所以逻辑回归最小化对数损失函数求参数,实际上与采用极大化似然函数来求参数是一致的,实际逻辑回归的对数损失函数也就是用极大化似然估计得到的。
3、算法
由于对数似然函数是凸函数,故可采用数值优化算法如梯度下降法、拟牛顿法求其最优解。
以下采用梯度下降法:
令
J
(
θ
)
=
−
l
(
ω
)
=
−
∑
i
=
1
n
y
(
i
)
l
n
[
ϕ
(
z
(
i
)
)
]
+
(
1
−
y
(
i
)
)
l
n
[
(
1
−
ϕ
(
z
(
i
)
)
)
]
J(\theta) = -l(\omega)=-\sum_{i=1}^ny^{(i)}ln[\phi(z^{(i)})]+(1-y^{(i)})ln[(1-\phi(z^{(i)}))]
J(θ)=−l(ω)=−i=1∑ny(i)ln[ϕ(z(i))]+(1−y(i))ln[(1−ϕ(z(i)))]
∂
J
(
θ
)
∂
θ
j
=
−
∑
i
=
1
n
[
y
(
i
)
1
ϕ
(
z
(
i
)
)
−
(
1
−
y
(
i
)
)
1
(
1
−
ϕ
(
z
(
i
)
)
)
]
∂
ϕ
(
z
(
i
)
)
∂
θ
j
\frac{\partial J(\theta)}{\partial\theta_j} = -\sum_{i=1}^n[y^{(i)}{1\over \phi(z^{(i)})}-(1-y^{(i)}){1\over (1-\phi(z^{(i)}))}]\frac{\partial \phi(z^{(i)})}{\partial\theta_j}
∂θj∂J(θ)=−i=1∑n[y(i)ϕ(z(i))1−(1−y(i))(1−ϕ(z(i)))1]∂θj∂ϕ(z(i))
由于对于sigmoid函数:
ϕ
′
(
z
)
=
ϕ
(
z
)
(
1
−
ϕ
(
z
)
)
\phi'(z)=\phi(z)(1-\phi(z))
ϕ′(z)=ϕ(z)(1−ϕ(z))
∂
(
ω
T
x
+
b
)
∂
ω
=
x
\frac{\partial (\omega^Tx+b)}{\partial \omega} = x
∂ω∂(ωTx+b)=x
故:
=
−
∑
i
=
1
n
[
y
(
i
)
1
ϕ
(
z
(
i
)
)
−
(
1
−
y
(
i
)
)
1
(
1
−
ϕ
(
z
(
i
)
)
)
]
ϕ
(
z
(
i
)
)
(
1
−
ϕ
(
z
(
i
)
)
)
∂
z
(
i
)
∂
θ
j
=-\sum_{i=1}^n[y^{(i)}{1\over \phi(z^{(i)})}-(1-y^{(i)}){1\over (1-\phi(z^{(i)}))}]\phi(z^{(i)})(1-\phi(z^{(i)}))\frac{\partial z^{(i)}}{\partial\theta_j}
=−i=1∑n[y(i)ϕ(z(i))1−(1−y(i))(1−ϕ(z(i)))1]ϕ(z(i))(1−ϕ(z(i)))∂θj∂z(i)
=
−
∑
i
=
1
n
[
y
(
i
)
(
1
−
ϕ
(
z
(
i
)
)
)
−
(
1
−
y
(
i
)
)
ϕ
(
z
(
i
)
)
]
x
j
(
i
)
=-\sum_{i=1}^n[y^{(i)}(1-\phi(z^{(i)}))-(1-y^{(i)})\phi(z^{(i)})]x^{(i)}_j
=−i=1∑n[y(i)(1−ϕ(z(i)))−(1−y(i))ϕ(z(i))]xj(i)
=
−
∑
i
=
1
n
(
y
(
i
)
−
ϕ
(
z
(
i
)
)
)
x
j
(
i
)
=-\sum_{i=1}^n(y^{(i)}-\phi(z^{(i)}))x^{(i)}_j
=−i=1∑n(y(i)−ϕ(z(i)))xj(i)
=
−
∑
i
=
1
n
(
y
(
i
)
−
f
(
x
)
)
x
j
(
i
)
=-\sum_{i=1}^n(y^{(i)}-f(x))x^{(i)}_j
=−i=1∑n(y(i)−f(x))xj(i)
从而得到批量梯度下降:
θ
j
+
1
:
=
θ
j
+
η
∑
i
=
1
n
(
y
(
i
)
−
f
(
x
)
)
x
j
(
i
)
\theta_{j+1}:=\theta_j+\eta\sum_{i=1}^n(y^{(i)}-f(x))x^{(i)}_j
θj+1:=θj+ηi=1∑n(y(i)−f(x))xj(i)
随机梯度下降:
θ
j
+
1
:
=
θ
j
+
η
(
y
(
i
)
−
f
(
x
)
)
x
j
(
i
)
,
f
o
r
  
i
  
i
n
  
r
a
n
g
e
(
n
)
\theta_{j+1}:=\theta_j+\eta(y^{(i)}-f(x))x^{(i)}_j,for\;i\;in\;range(n)
θj+1:=θj+η(y(i)−f(x))xj(i),foriinrange(n)
4、实现
批量梯度下降:
def train(self, X, y):
"""
批量梯度下降:训练模型
:param X: 输入集,n*m(n行m列)
:param y: 标签集,1*m(1行m列)
:return: 训练好的模型
"""
n, m = np.shape(X)
# X = (X, 1), w=(w;b)
# w^T*x+b => w^T*X
X = np.mat(np.concatenate((X, np.ones((n, 1))), axis=1))
y = np.mat(y).T
w = np.ones((m + 1, 1))
alpha = self.alpha
tol = self.tol
records = []
for i in range(self.max_iter):
# 实际值与预测值之差
error = y - 1.0 / (1 + np.exp(-X * w))
# 误差变化记录
records.append((error.T * error)[0, 0])
if records[-1] <= tol:
break
# 负梯度方向更新参数
w += alpha * X.T * error
self.w = w[:-1]
self.b = w[-1]
随机梯度下降:
def train(self, X, y):
"""
随机梯度下降
:param X: 训练集
:param y: 标签
:return: w,b
"""
n, m = np.shape(X)
w = np.ones((m + 1, 1))
alpha = self.alpha
records = []
for i in range(self.max_iter):
row = random.randint(0, n - 1)
x_i = np.mat(np.concatenate((X[row], np.ones(1))))
y_i = y[row]
error = y_i - 1.0 / (1 + np.exp(-np.matmul(x_i, w))[0, 0])
records.append(error * error)
w += alpha * error * x_i.T
self.w = w[:-1]
self.b = w[-1]














 38万+
38万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









