







文章目录
CVAT(Computer Vision Annotation Tool,计算机视觉注释工具的主要功能)
1. 概述
1.1 图像注释工具
- 适用范围:用于注释数字图像和视频。CVAT 支持与对象检测、图像分类和图像分割相关的监督式机器学习任务。
- 标注类型:它使用户能够使用四种类型的形状对图像进行注释:框、多边形(通常和用于分割任务)、折线(可用于注释道路上的标记)和点(例如,用于注释面部特征或姿态估计)。
- 便捷工具:CVAT 还提供有助于执行典型注释任务的功能,例如许多自动化工具(包括使用 TensorFlow对象检测 API 复制和传播对象、插值和自动注释的功能)、视觉设置、快捷方式、过滤器等。
1.2 CVAT的优势:
- CVAT是基于Web的。图像和视频注释软件可以完全基于网络使用,而无需安装本地客户端。此类注释工具可以在本地计算机上运行,也可以作为基于 Web 的注释工具运行,允许团队成员之间进行协作。
- 团队开发:用户可以协作并创建公共任务,以在其他用户之间分配工作。可以团队一起完成一个项目project,一个项目可以分成多个任务task,一个任务有可以氛围多个job,可以同时分配给多人进行数据标注。
- CVAT中的自动注释允许用户在关键帧之间使用插值。可用于在多个关键帧之间插值边界框和属性。这用于自动注释一组图像,例如,不多次绘制相同的边界框。
- 可以调用模型自动标注。可以与 Roboflow 和 HuggingFace 集成,如可以在CVAT使用Roboflow Universe上的 50,000+ 模型之一在CVAT中自动标记数据。
- CVAT适合集成到计算机视觉平台中,例如Viso Suite。
1.3 CVAT的局限性:
- 测试检查必须手动完成,从而减慢了开发过程。 尽管 CVAT 支持一些自动标注,但所有检查都必须手动完成,这可能会减慢开发过程。CVAT的文档目前有些有限,这可能会阻碍参与该工具的开发。
- CVAT的浏览器支持需要使用 Google Chrome。
1.4 CVAT软件评价
- CVAT等内部数据注释工具可有效地注释图像并加快流程。该软件工具旨在快速分配新任务并管理工作流程。很容易平衡工作的价格和质量。
2. 标注类型
只适用于注释数字图像和视频,视觉任务的标注都能标。
适用范围:
- Image Classification 图像分类
- Object Detection 物体检测
- Semantic and Instance Segmentation 语义和实例分割
- Point Clouds / LIDAR 点云/激光雷达
- 3D Cuboids 3D长方体
- Video Annotation 视频注释
- Skeleton 姿态
选择需要标注的作业(作业状态是‘annotation’标注状态),进入标注。
[图片]
| Stage | 描述 |
|---|---|
| Annotation | 提供对批注工具的访问。被分派者将能够查看他们分配的工作并对其进行注释。默认情况下,具有“注释”阶段的工作负责人无法报告注释错误或问题。 |
| Validation | 授予对 QA 工具的访问权限。被分派者将看到他们分配的工作,并可以验证这些工作,同时报告问题。默认情况下,具有“验证”阶段的工作负责人无法更正错误或批注数据集。 |
| Acceptance | 不授予任何其他访问权限或更改注释器的界面。它只是将工作标记为已完成。 |
2.1 图像标注
CVAT提供以下形状来注释图像:
矩形或边界框多边形折线点长方体3d任务中的长方体



2.2 视频标注
追踪模式Track mode (视频标注使用)
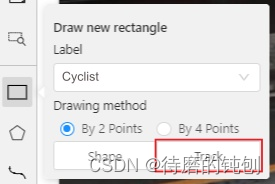
Shape:是用来标注图像的。
Track:是专门用来标注视频的。
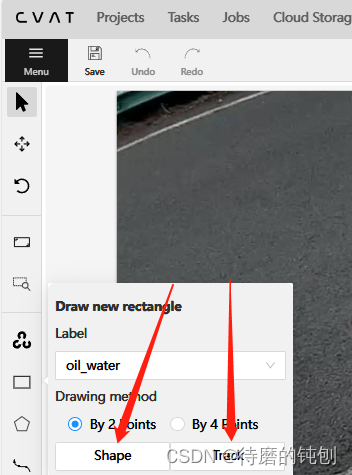
2. 为对象创建赛道(以所选汽车为例):
- 通过单击创建一个 Rectangle Track in Track mode 。
- 在矩形中 Track mode 将自动插入下一帧。
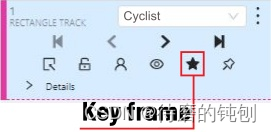
- 骑自行车的人开始在框架 #2270 上移动。让我们将帧标记为关键帧。您可以按 K 此按钮或单击 star 按钮(请参阅下面的屏幕截图)。
- 如果对象开始改变其位置,则需要修改它发生的位置的矩形。无需更改每个帧上的矩形,只需更新多个关键帧,它们之间的帧将自动插值。
- 让我们向前跳 30 帧并调整对象的边界。请参阅以下示例:

- 之后,对象的矩形将在帧 2270 到 2300 上自动更改:

3. 便捷工具
CVAT 还提供有助于执行典型注释任务的功能,例如许多自动化工具(包括使用 TensorFlow对象检测 API 复制和传播对象、插值和自动注释的功能)、视觉设置、快捷方式、过滤器等。
3.1 快捷键
| 功能 | 快捷键 |
|---|---|
| 标注(自动画框)再按1次结束标注 | N |
| 前、后移动1张 | D、F |
| 前、后移动10张 | C、V |
| 查看前,后一个标注的图片 | ←,→ |
| 调整标注的形状 | Q |
| 设置/取消视频标注的关键点 | K |
| 复制框/粘贴框 | Ctrl + C/Ctrl + V |
| 转换标签 | Ctrl+(0…9) |
4. 团队开发
4.1 CVAT分析监控
通过分析,可以查看每个用户在每项任务上花费了多少时间,以及他们在任何时间范围内做了多少工作。
4.2 线上检验标注作业是否合格
[图片]
将标注作业设置为检验状态时,打开该作业的时候,操作页面就换了左侧操作部分就没有标注的工具了,这时没法更正错误。
4.3 检验时自动注释的功能
进行浏览标注是否合格,若不合格右击进行不合格注释。
- 检验标注是否合格时自动注释:
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/111b54caf52eb8e5748dfe0a1ede775c.png)

如上图“1”是新创建一个注释,可以创建新的不符合你要求的内容。“2”是位置不合格“3”标注内容不对。
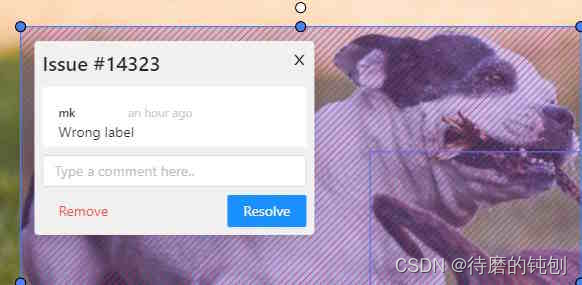
2. 如下图选择“2”位置不对,就会有如下注释。
3. 如下图选择“1”创建新的注释。且该这个创建的新注释也会加入到快捷注释中。
4.创建一个验证时的问题。
4.4 检验后重新标注,验收是否合格
-
如果反馈的问题如果得到解决,可以选择注释“已经解决”或者移除这个不合格的注释。
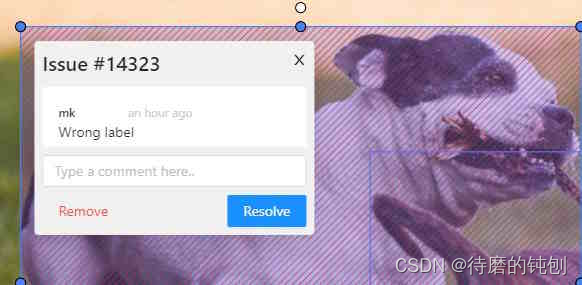
-
重新标注后进行验收时,检查这个标注作业的标注是否合格,若符合要求则更换这个标注作业的状态为完成。
5. 修改标注的格式
5.1 创建任务将图片导入cvat
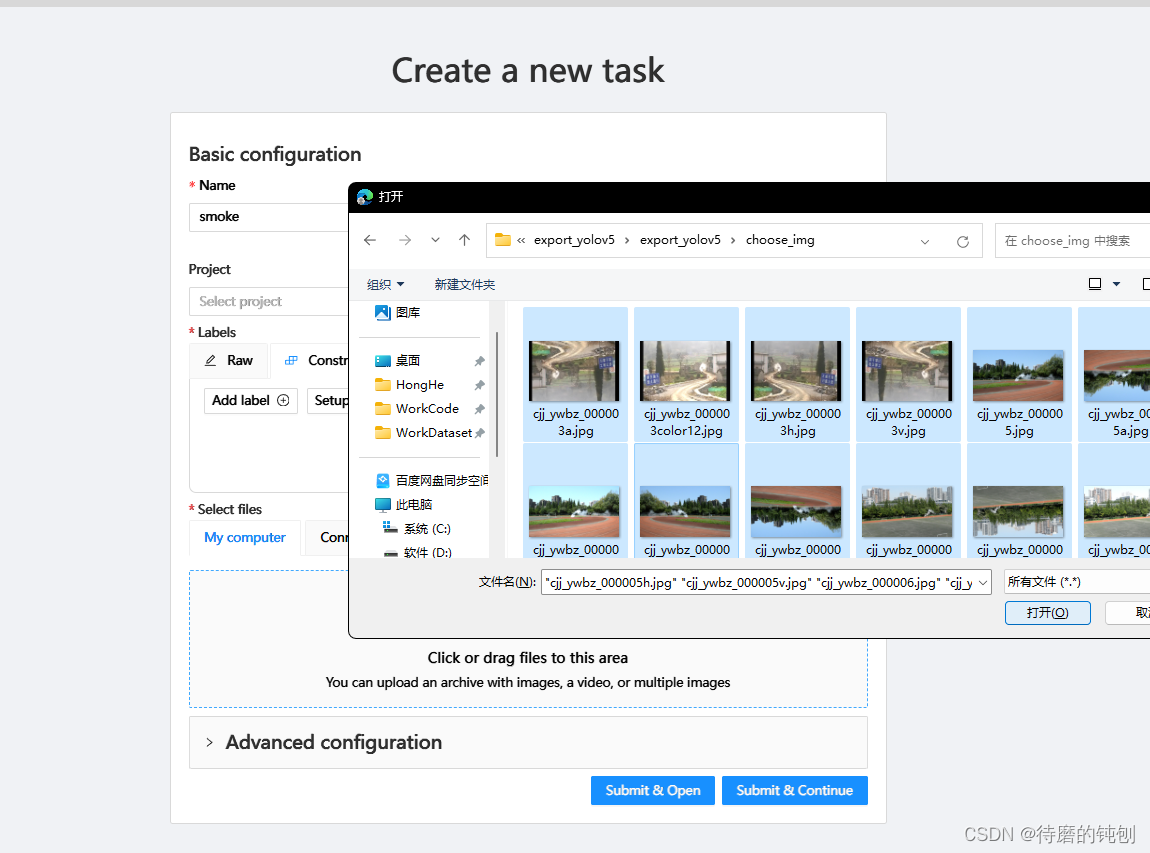
5.2 上传标注文件
-
Menus > Upload annotations
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/28e47e55116ac8a3b2f1856f4248c4dd.png)
-
从可用选项列表中选择对应的标签格式。
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/b3f533f07cac2d14ee6b6f8da3e88114.png)
-
标注文件的格式是打包压缩好的.zip 文件
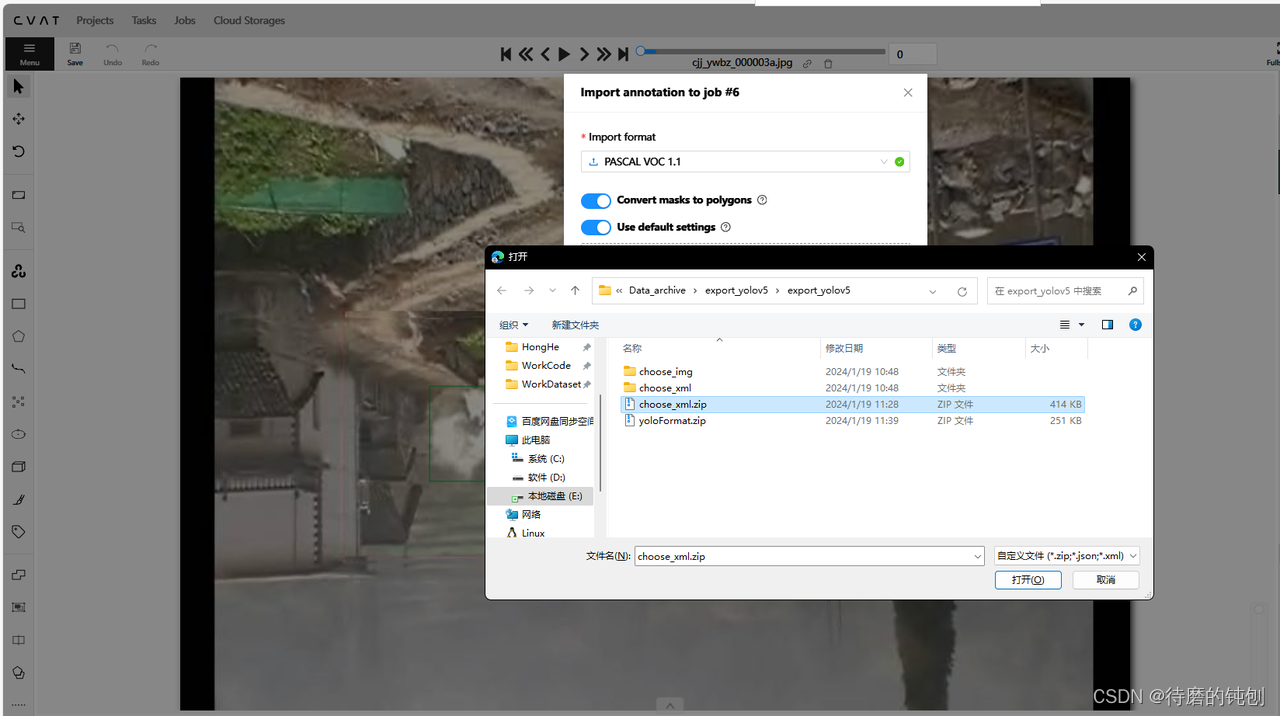
-
然后回到任务面板,打开就可以看到已经标注好的结果了
5.3 导出需要的标签格式
-
Menus > Export task dataset
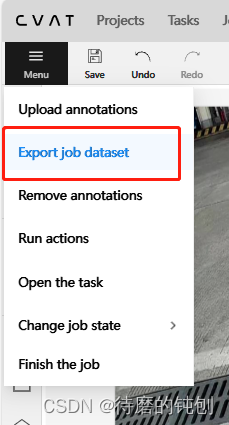
-
从选择需要输出的标签格式。
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/0f3598da5e403770cdb4be8471c2d17d.png)
-
导出标签文件
-
(可选)切换保存图像开关,如果您希望在导出中包含图像。
注意:“保存图像”选项是一项付费功能。 -
输入生成的 .zip 存档的名称。
-
单击“确定”启动导出。
(最全)CVAT标注工具详细操作步骤及CVAT介绍
CVAT标注工具概述
1.CVAT建项目步骤
1.1.CVAT初使用—Task界面介绍
1.2.CVAT标注界面介绍
2.CVAT—导入导出数据集并上传注释
3.CVAT—快捷键详述
4.1.CVAT——目标检测的标注详细步骤
4.2.CVAT——分类任务标注的详细步骤
4.3.CVAT——分割标注的详细步骤
4.4.CVAT——使用折线进行注释
4.5.CVAT——视频标注的详细步骤
4.6.CVAT——带点的注释详细操作
4.7.CVAT——椭圆标注(道路标志)
4.8.CVAT——用骨架skeletons注释
4.9.CVAT——用长方体进行注释
4.10.CVAT——3D对象标注
5.CVAT用户角色
6.CVAT——属性注释模式


















 3401
3401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









