






目录
CXL (Compute Express Link)是什么?
为什么需要CXL (Compute Express Link)?

CXL (Compute Express Link)是什么?
简单的可以理解为PCie的升级版替代协议。(基于PCIe物理层设计,向下兼容PCIe标准)
- CXL 是一种开放标准
- CPU 与各种设备(如 GPU、FPGA、内存缓冲器、智能网络接口、持久内存和固态硬盘等)之间的高速、低延迟的连接。
- CXL技术不仅提供了高速传输,还支持内存共享和虚拟化,使设备之间的协作更加紧密和高效。
推荐视频:What is...|CXL的延迟为什么会比PCIe低呢?_https://www.bilibili.com/video/BV1brAte8EzK
为什么需要CXL (Compute Express Link)?
解决CPU、内存、加速器和存储设备之间的数据传输瓶颈,特别是针对AI、大数据等领域的高性能需求。
提供低延迟、高带宽的通信能力,支持异构设备间的紧密协作。
协议分层:支持CXL.io(设备发现与I/O传输)、CXL.cache(缓存一致性)、CXL.memory(内存扩展)三种协议,分别优化不同场景的数据传输。
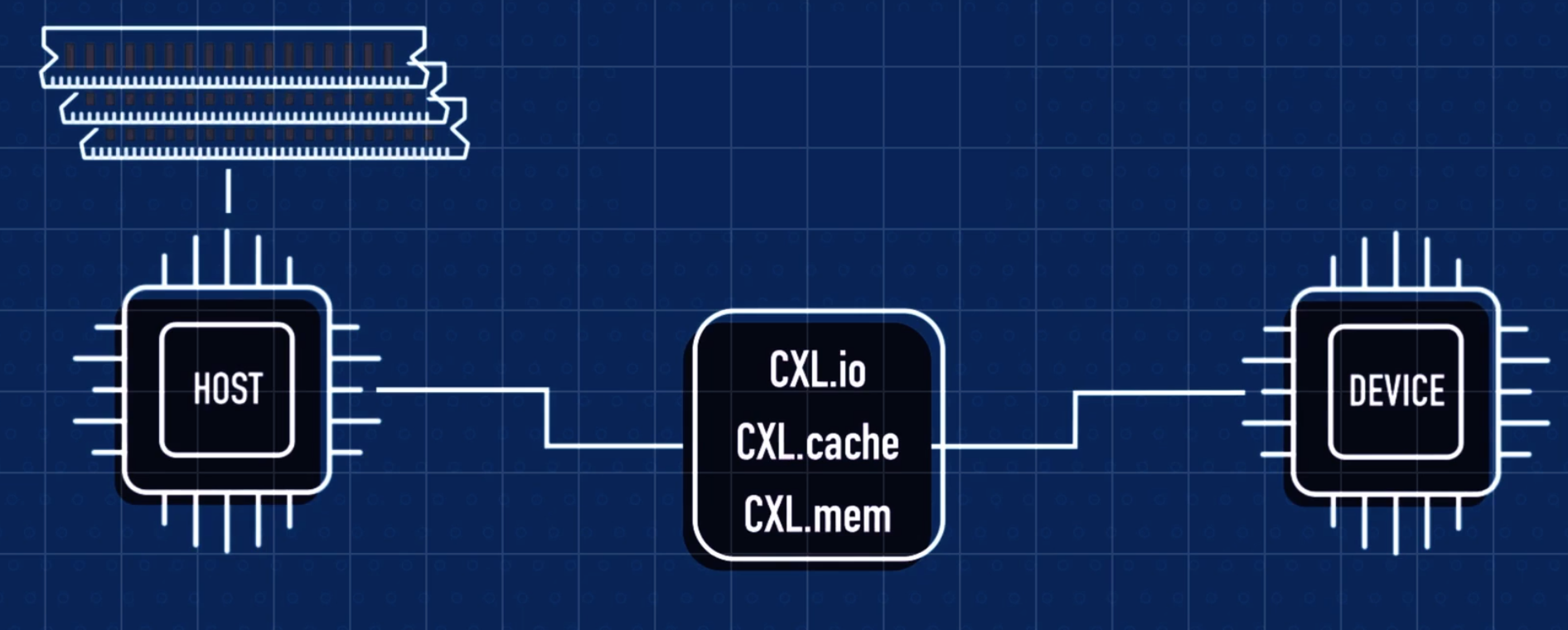
例子说明
下面以“CXL 与 DPU 的结合应用/协调处理“作为例子说明:
传统的基于 PCIe 的 CPU+DPU 协同处理模式存在性能瓶颈,因为需要在 CPU 和 DPU 各自的内存域之间进行多次数据移动(CPU 处理存储请求,而 DPU 负责执行具体的存储操作,如加密、压缩、解密、解压缩等)导致性能大幅下降。
简单例子
传统的基于 PCIe 的协同处理模式:
CPU 需要将存储请求发送到 DPU,DPU 处理完成后再将结果返回给 CPU。这个过程中,数据需要在 CPU 和 DPU 的内存域之间多次移动,导致性能下降。
而 CXL 技术的引入,可以有效解决这一问题。
基于 CXL 的协同处理模式:
使用 CXL 连接的设备内存(如 CXL.mem),创建单个共享内存域,作为 CPU+DPU 的共享内存,从而避免显式的数据移动。简化了存储数据访问和操作,提高了 IOPS(每秒输入输出操作)。
上面的例子,可以总结为:在传统的基于PCIe的CPU+DPU(或GPU)协同处理模式中,由于CPU和DPU(或GPU)都有自己的内存,数据需要在两者之间进行多次移动,这成为了性能提升的一个瓶颈。CXL的产生就是为了要解决这个问题。
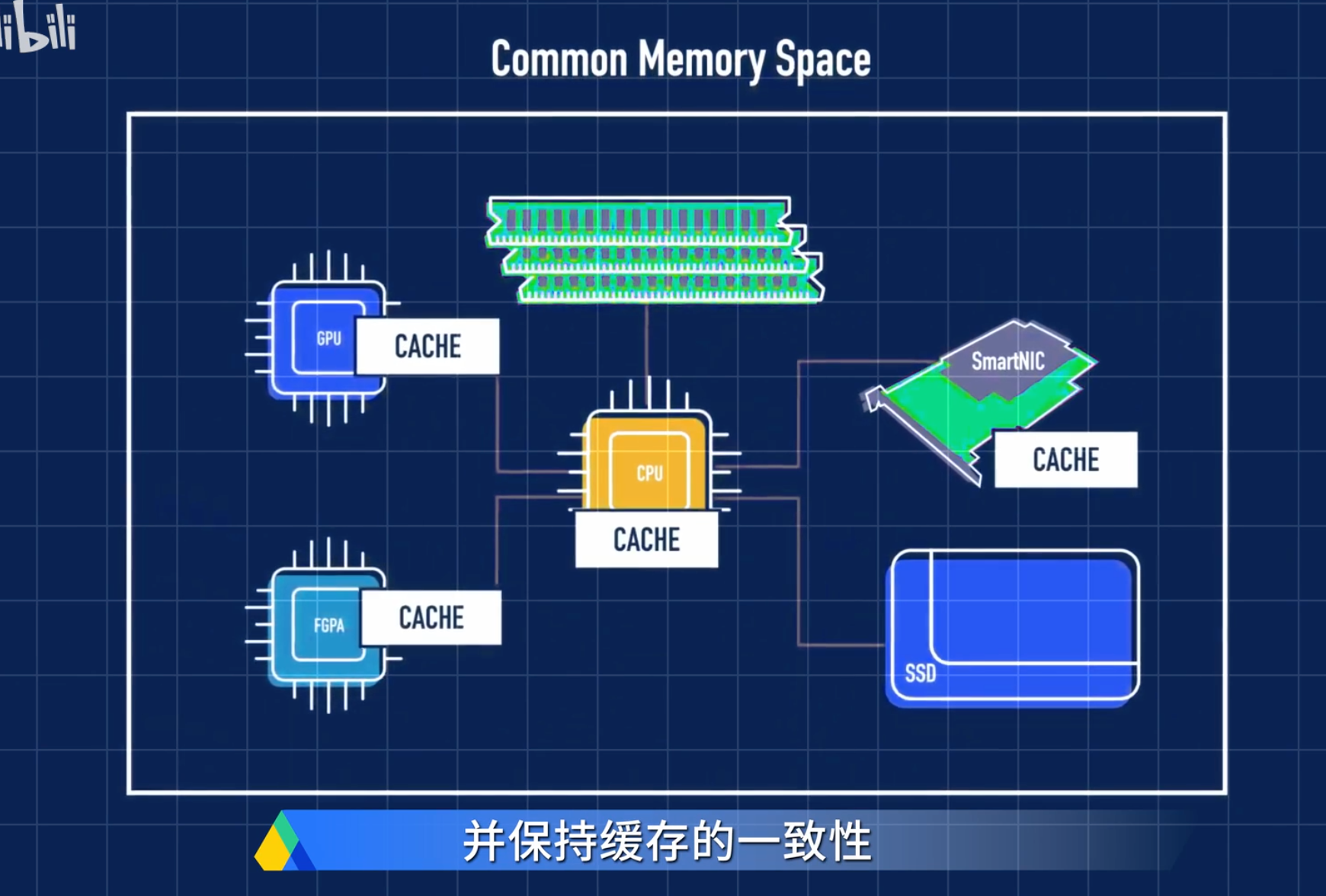
服务器用户有巨大的内存池和数量庞大的基于PCIe运算加速器,每个上面都有很大的内存。内存的分割已经造成巨大的浪费、不便和性能下降(数据在这些内存之间移动)。CXL就是为解决这个问题而诞生。
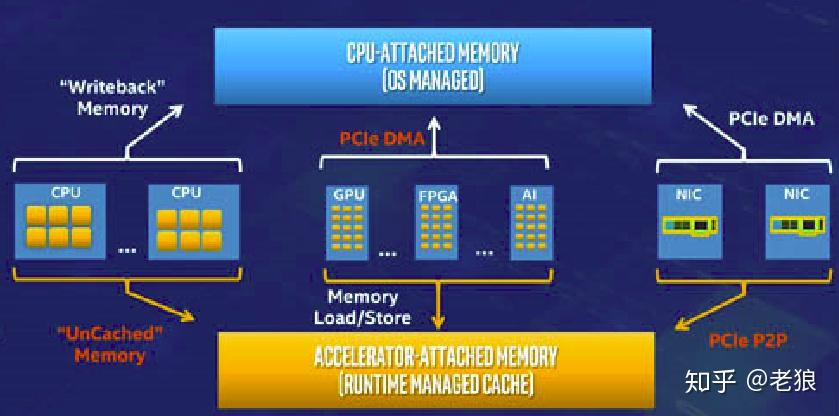
总结
CXL(Compute Express Link)是PCie的升级版替代协议,解决CPU、内存、加速器和存储设备之间的数据传输瓶颈的新型互连标准,其核心特点可归纳为以下六大方面,结合技术原理与实际应用场景进行阐述:
1. 异构设备协同优化
- 协议分层设计
通过CXL.io(设备发现与基础传输)、CXL.cache(缓存一致性协议)、CXL.memory(内存扩展协议)三层架构,分别解决设备通信、数据同步和内存共享问题。例如:- CXL.cache允许GPU直接访问CPU缓存,减少数据复制开销,在AI训练中可提升模型参数同步效率30%以上。
- CXL.memory支持将外部存储设备(如NVMe SSD)映射为主机内存,实现“内存级”存储访问,降低大数据处理延迟。
2. 带宽与延迟突破
- 物理层性能
基于PCIe 5.0/6.0规范,CXL 3.0理论带宽达64 GT/s(双向),延迟低于1微秒,相比传统PCIe方案:- 带宽提升:单通道带宽是PCIe 4.0的2倍,支持超大规模模型并行训练。
- 延迟优化:通过固定512位数据块(Flit)传输,减少协议开销,适合高频交易、实时推理等低延迟场景。
3. 内存革命性管理
- 池化与共享机制
支持多主机/设备共享内存池,资源利用率提升40%:- 动态扩展:按需分配内存,避免传统静态分区导致的碎片问题。
- 异构内存支持:可同时管理DRAM、持久内存(如Intel Optane)和非易失性内存(NVM),适配混合工作负载。
4. 拓扑灵活性
- 复杂网络支持
CXL 3.0引入结构功能(Fabric),支持4096节点全互联,突破传统树形拓扑限制:- 多主机架构:单个GPU可被多台服务器共享,降低硬件成本。
- 故障隔离:通过多级交换机实现链路冗余,提升系统可靠性。
5. 兼容性与生态扩展
- 无缝升级路径
- 物理兼容:CXL设备可插入PCIe插槽,不支持CXL协议的硬件自动回退至PCIe模式。
- 软件支持:Linux内核已集成CXL驱动框架,主流AI框架(如PyTorch)逐步适配CXL通信后端。
6.与NVLink区别
CXL用于CPU与加速器(如GPU、FPGA)、内存缓冲等设备之间的高效通信。
NVLink用于NVIDIA的GPU之间的快速数据交换。
| 特性 | CXL | PCIe | NVLink |
|---|---|---|---|
| 带宽 | 64 GT/s(CXL 3.0) | 32 GT/s(PCIe 5.0) | 900 GB/s(NVLink 4.0) |
| 延迟 | <1μs | ~2μs | <1μs(同节点GPU间) |
| 内存共享 | 支持跨设备内存池化 | 需主机显式拷贝数据 | 仅支持NVIDIA GPU间 |
| 拓扑扩展 | 支持Fabric多跳网络 | 树形拓扑为主 | 依赖专用交换机 |
| 适用场景 | 通用异构计算、AI、数据中心 | 通用外设连接 | NVIDIA GPU集群通信 |
典型应用场景
- AI训练加速
通过CXL连接多GPU/NPU,实现参数服务器与计算节点的内存共享,减少AllReduce操作开销。 - 超算资源池化
构建CPU+FPGA+存储的混合节点,动态分配计算与内存资源。 - 边缘智能设备
在自动驾驶场景中,连接传感器、AI加速器与存储,实现低延迟决策。
随着CXL 3.0标准的普及,预计未来三年内,80%的AI训练集群将采用CXL技术优化通信架构,推动算力效率进入新纪元。
参考:
https://zhuanlan.zhihu.com/p/65435956 基于PCIe 5.0的CXL是什么?
什么是CXL(Compute Express Link)技术?一文读懂CXL_https://blog.csdn.net/Long_xu/article/details/131317471


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









