






 CXL是一种旨在提升数据中心和高性能计算环境中处理器间通信效率的高速互连技术,基于PCIe物理层,强调缓存一致性、内存共享和设备互联。文章详细介绍了CXL的动机、协议、关键特性、应用案例和未来发展方向,包括内存扩展、GPU内存池和加密计算等领域。
CXL是一种旨在提升数据中心和高性能计算环境中处理器间通信效率的高速互连技术,基于PCIe物理层,强调缓存一致性、内存共享和设备互联。文章详细介绍了CXL的动机、协议、关键特性、应用案例和未来发展方向,包括内存扩展、GPU内存池和加密计算等领域。
Overview
-
Motivation of CXL
-
Introduction to CXL
- CXL’s Protocols
- CXL’s Major Benefits
- CXL’s Flow
-
Features of CXL
- CXL Stack
- Asymmetric Complexity
- Coherence Bias
-
CXL IP
- IP Vendors
-
CXL Use Cases
- Typical CPU Case
- Typical GPU Case
- Other Case
1. Motivation
Compute Express Link (CXL) 是一种高速互连技术,旨在提高数据中心和高性能计算环境中处理器、内存设备、加速器(如GPUs、FPGAs等)之间的通信效率。CXL基于PCI Express (PCIe) 物理层标准,但引入了新的协议层,专门设计来处理高带宽、低延迟的内存共享和设备互联需求。
CXL的主要目标是克服传统互连技术在处理高速、大容量数据传输时遇到的瓶颈,特别是在AI、机器学习、大数据分析等领域。它通过支持高效的缓存一致性模型和内存语义操作,实现了不同设备间的紧密协作和数据共享。它最初由英特尔、AMD和其他公司联合推出,并得到了包括谷歌、微软等公司在内的大量支持。

CXL的应用场景
- 人工智能和机器学习:在AI和ML应用中,CXL可以加速大规模数据集的处理,提高训练和推理的效率。
- 高性能计算 (HPC):CXL支持大规模HPC系统中的高速数据交换和处理,加速科学计算和工程模拟任务。
- 数据中心和云计算:在数据中心,CXL可以优化资源利用率,支持动态内存分配和加速器共享,提高云服务的性能和灵活性。
- 存储扩展和内存池:CXL允许创建大容量内存池,支持内存密集型应用,如大数据分析和实时数据处理。
不同应用场景下的互连需求
- 高效的资源共享
- 共享内存池,具备高效的访问机制
- 提高加速器和目标设备之间操作数和结果的传输效率
- 大幅减少延迟,以实现分布式内存
- 行业需要开放的标准,能够全面应对下一代互连挑战
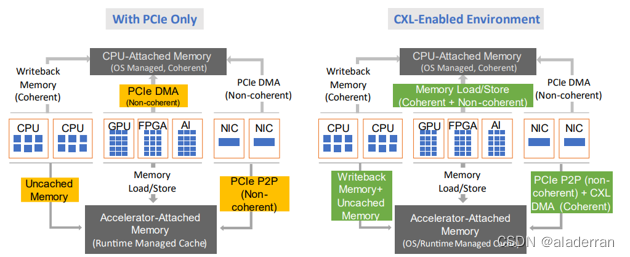
CXL的关键特性
- 高性能和低延迟:CXL利用PCIe的高带宽物理层,同时通过优化的协议栈减少通信延迟,支持高速数据传输和快速响应时间。
- 缓存一致性:CXL引入了先进的缓存一致性机制,允许不同处理器和加速器之间共享数据,同时保持数据的一致性和准确性。
- 内存协议扩展:CXL定义了一套内存协议扩展,支持对共享内存的高效访问和管理。这些扩展包括内存分配、迁移和共享等功能。
- 兼容性:CXL设计为向下兼容PCIe标准,这意味着它可以在现有的PCIe基础设施上部署,无需进行大规模的硬件升级。
- 多用途互连:CXL支持多种用途的互连,包括加速器互联、内存扩展和高速网络连接,为多样化的应用需求提供解决方案。
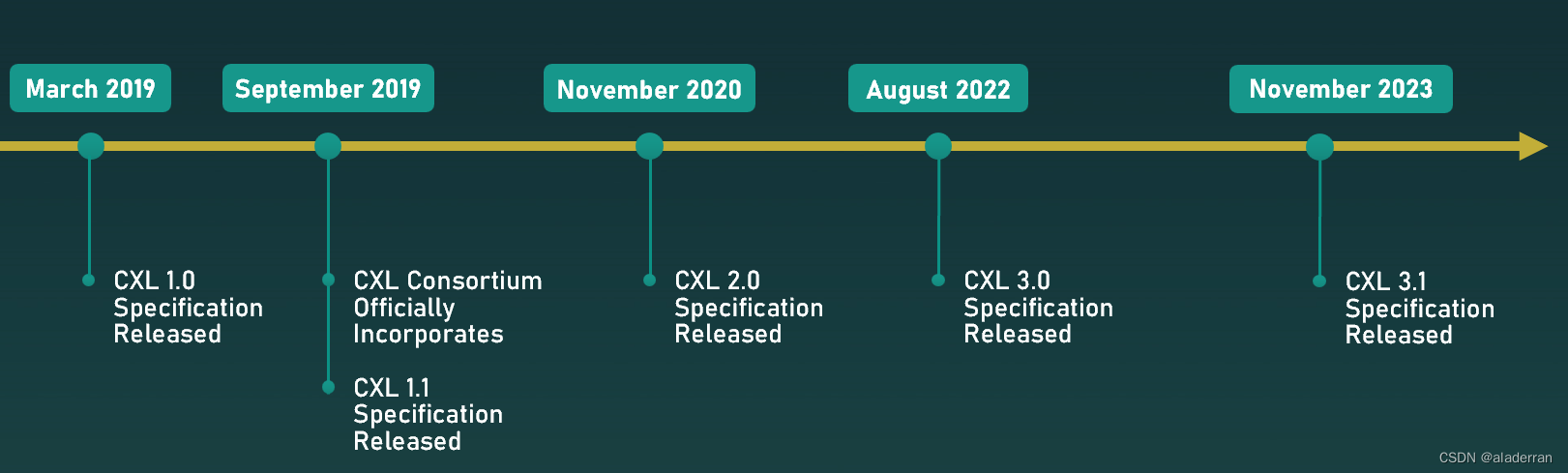
CXL时间线
CXL技术从2019年1.0版的首次发布,到2023年的3.1版规范,标志着CXL技术的不断进步和成熟。

CXL 1.0
- Processor Interconnect:在CXL 1.0中,重点是在单个处理器节点内部提供一致性内存互连(coherent interconnect)。它支持处理器和内存之间的高速数据传输,并保持一致性,这对于计算密集型任务来说至关重要。
- SoC Interconnect:CXL 1.0也支持片上系统(SoC)之间的互联,这对于集成了多种功能和处理单元的现代微处理器至关重要。
CXL 2.0
- Multiple Nodes inside a Rack/Chassis supporting pooling of resources:在CXL 2.0中,技术扩展到支持资源池化,允许多个节点共享资源,比如内存和加速器。
- Switch:推出了CXL 2.0交换机,它允许CXL设备之间的连接和通信,这是构建高效数据中心架构的关键。
CXL 3.0/3.1
- Expanding Scope of CXL:到了CXL 3.0和3.1,CXL的应用范围进一步扩大,支持更加复杂的数据中心架构,包括更广泛的资源解耦、池化和加速器支持。
- Composable Fabric growth for disaggregation/pooling/accelerator:CXL 3.x提供了组合式织物(Composable Fabric)的功能增强,这意味着资源(如内存和加速器)可以更加灵活地被分配和重组,以支持不同的工作负载和应用。
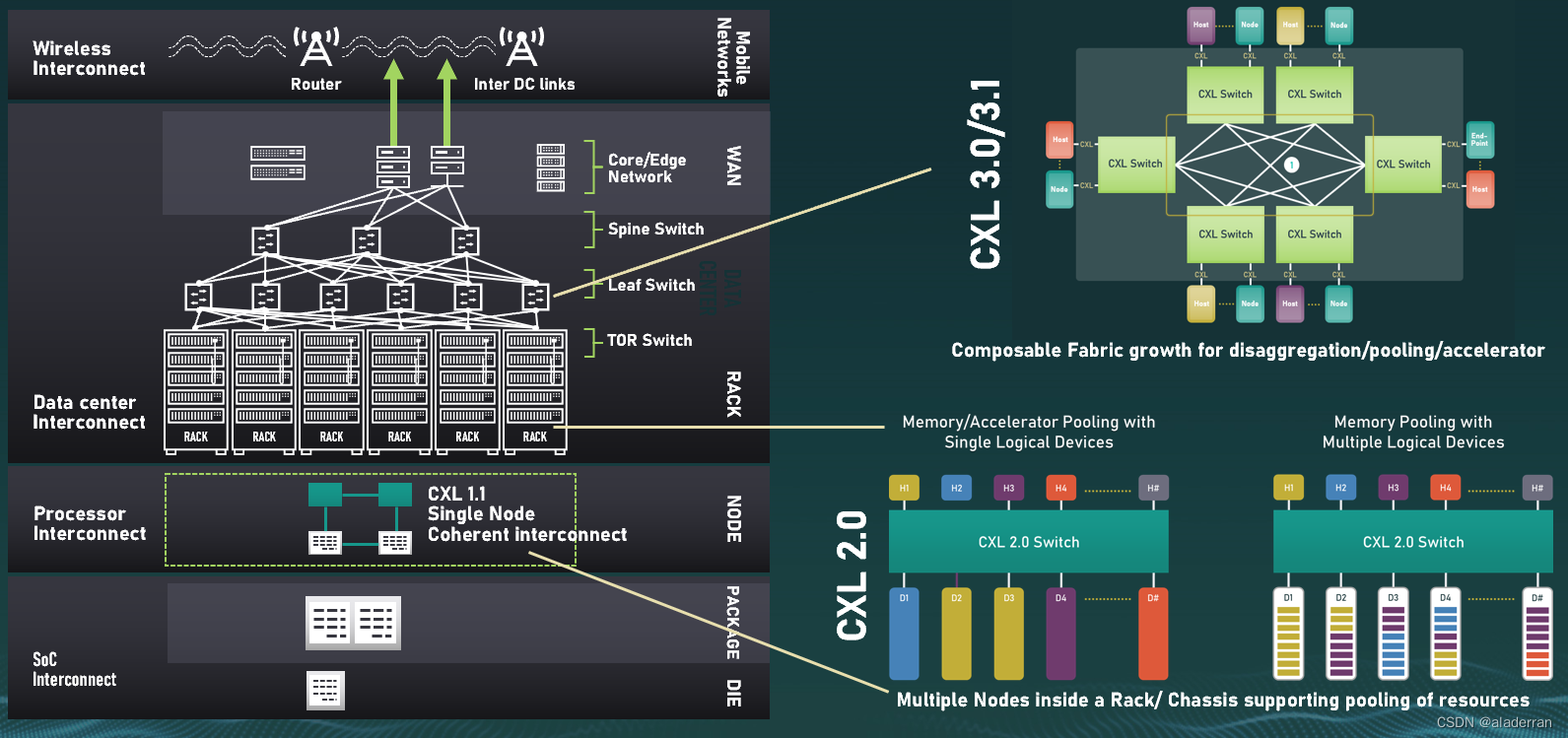
2. Introduction
CXL协议
CXL协议包含三个子协议:
- CXL.io:这种模式可以将内存扩展到外部设备,使得数据的传输速度更快。CXL.io通过PCIe总线连接CPU和外部设备,这样CPU就可以与外部设备共享内存,并且可以直接访问外部设备的I/O资源。
- CXL.cache:这种模式可以通过将内存缓存到外部设备中来提高性能。CXL.cache模式允许CPU在本地缓存中保留最常用的数据,而将不常用的数据保存在外部设备中。这样可以减少内存访问时间,提高整体系统性能。
- CXL.memory:这种模式可以将外部设备作为主内存使用,从而实现更大的内存容量。CXL.memory模式允许CPU将外部设备看作是扩展内存,从而可以存储更多的数据。这种方式可以提高系统的可靠性,因为即使发生了内存故障,CPU仍然可以通过外部设备继续运行。
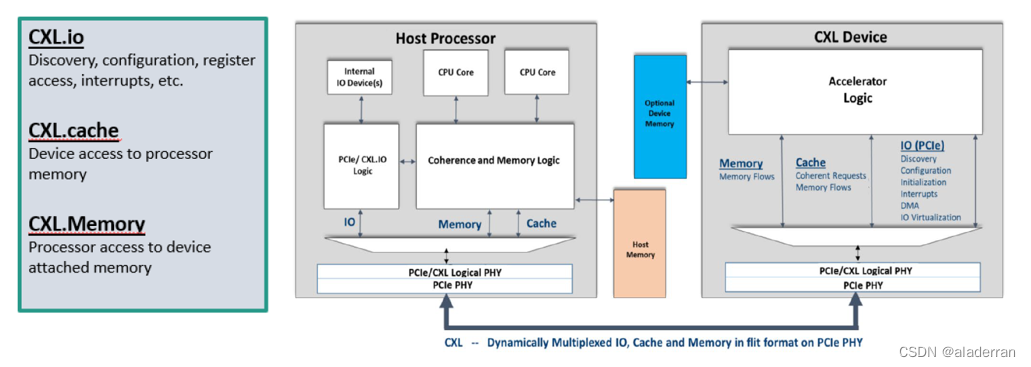
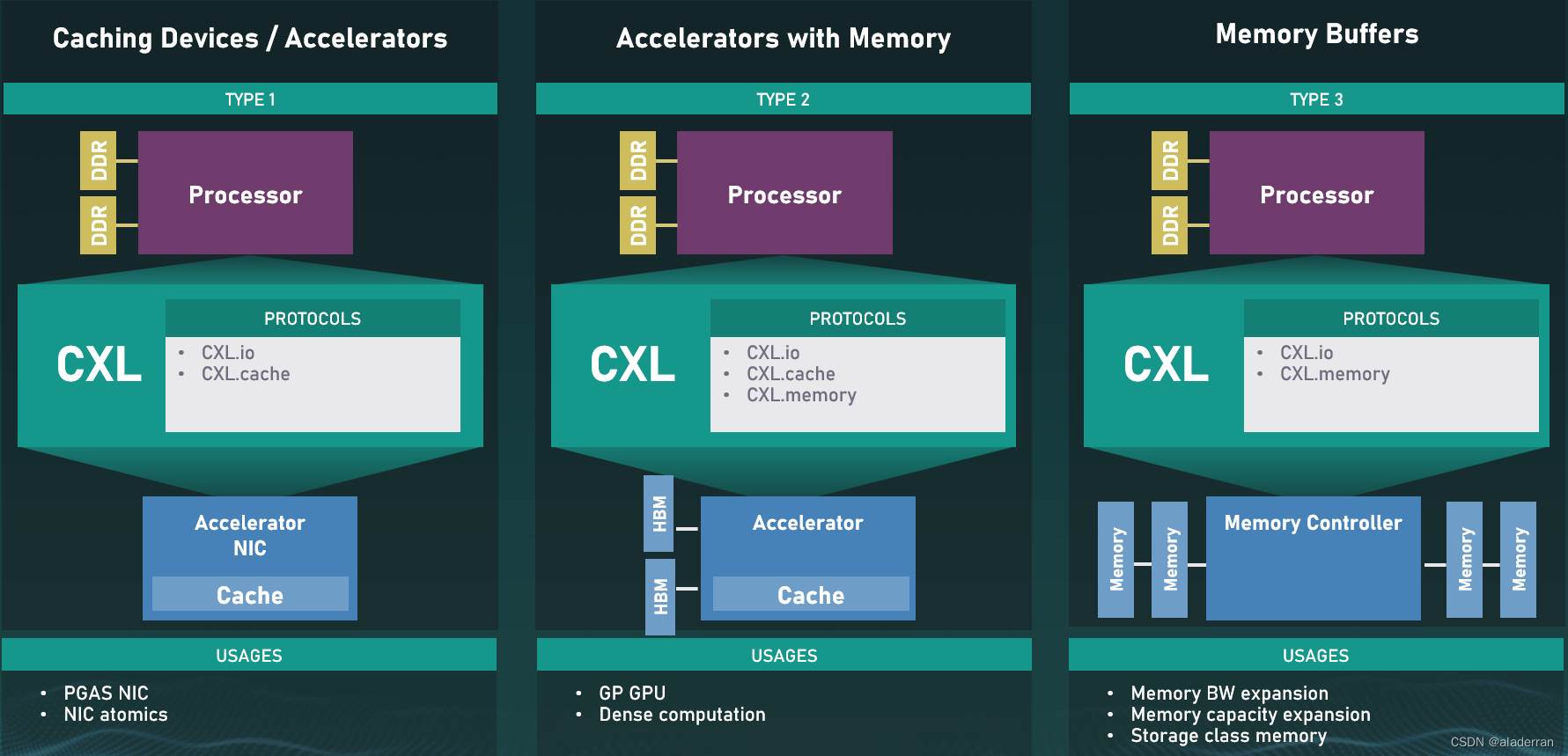
CXL协议的使用案例
- 通过 PCIe 插槽安装加速卡或附加卡。这些卡可以与现有系统集成,并通过 CXL 接口与 CPU 直接通信以提供更快的数据传输速度。用于网卡这类高速缓存设备。
- 具有所有CXL协议的功能,通常用于具有高密度计算的场景,比如 GPU 加速。
- 连接专用的存储设备,与主机处理器直接通信,并且可以使用 CXL 协议来实现低延迟、高吞吐量的数据传输。用作内存缓冲器,用于扩展内存带宽和内存容量。
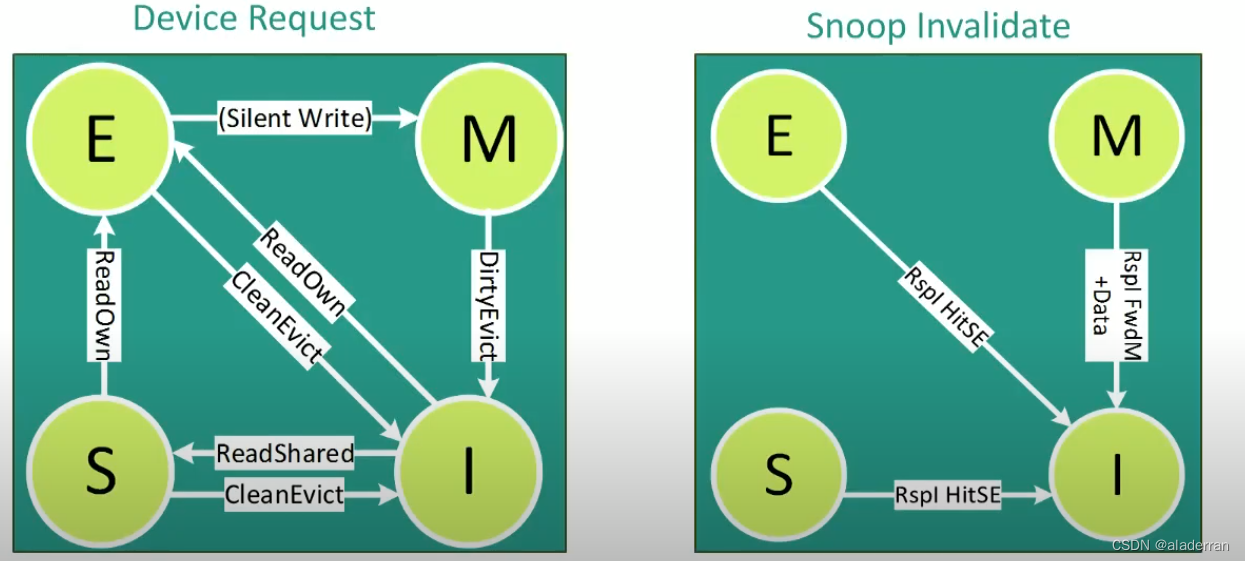
CXL缓存一致性
相较于PCIe,CXL的最重要的新特性是支持高速缓存一致性和内存语义操作,以及允许设备共享内存。这意味着CXL可以使多个处理器和加速器共享同一内存空间,同时保持数据一致性。
在现代的CPU缓存中,数据状态遵循M、E、S、I协议/状态模型:
- Modified(修改):数据仅存在于一个缓存中,可以被读取或写入,内存中的数据可能不是最新的。
- Exclusive(独占):数据仅存在于一个缓存中,可以被读取或写入,且内存中的数据是最新的。
- Shared(共享):数据可能存在于多个缓存中,仅可以被读取,且数据保证是最新的。
- Invalid(无效):数据不在任何缓存中。
CXL遵循现代CPU缓存/内存层次结构,其中几个关键概念为:
- 全局观测点(Global Observation):这是一个系统设计中的概念,指的是当数据被写入时,这些数据对系统中的其他部分是可见的,从而保证了数据的及时性和一致性。
- 追踪粒度:在CXL技术中,数据的追踪粒度被定义为“缓存线”(cacheline),通常是64字节,这是为了高效地追踪和管理缓存数据。
- 地址翻译:系统假定所有地址都是宿主物理地址(Host Physical Address,HPA),CXL缓存和内存协议通过现有的地址翻译服务(Address Translation Services,ATS)来进行转换,确保数据的准确定位和高效访问。
例如:在CPU Socket之间,通过CXL技术实现了一种连贯的CPU对CPU对称链接,允许不同处理器之间直接和高效地共享数据。如图所示,每个CPU Socket都有自己的L1、L2和L3缓存,以及直接连接的内存(DDR),并且通过CXL链接与其他设备交互。
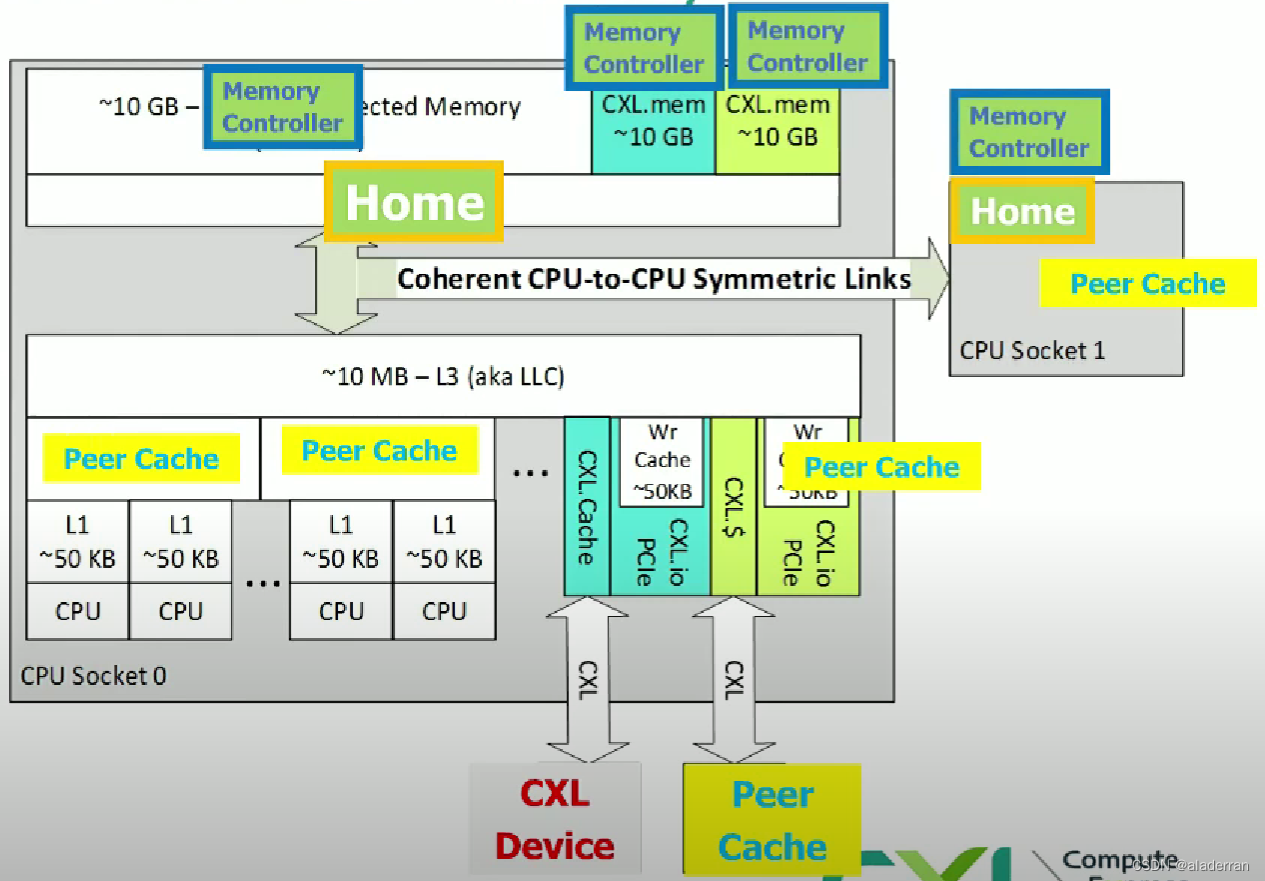
CXL还引入了新的对等缓存管理方法,其中所有的对等缓存都由“Home Agent”在缓存级别管理,对CXL设备隐藏。"Snoop"操作是Home Agent检查缓存状态并可能引起缓存状态变化的术语。

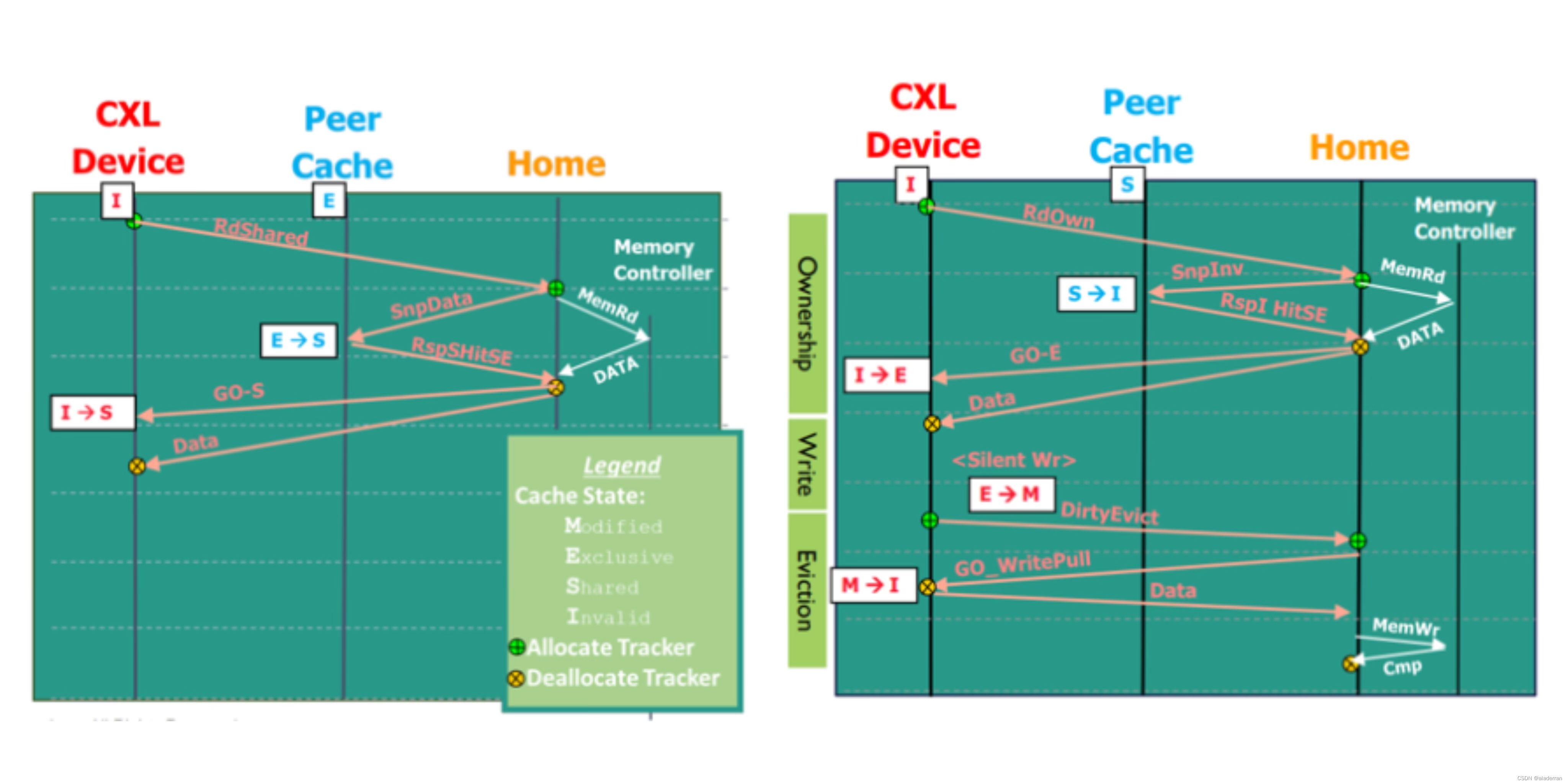
数据传输是通过明确定义的通道进行的,以确保高效和有序的通信。具体来说,包含以下几个方面:
- 通道设置:在CXL架构中,数据传输是通过三个通道在设备(D2H)和主机(H2D)之间双向进行的。这三个通道分别是请求通道、响应通道和数据通道。
- 通道预分配:为了保证传输的连续性和减少延迟,数据和响应通道是预先分配的。
- 设备请求(D2H):来自设备的请求是通过D2H(Device to Host)通道发送的,它负责将设备端的数据和命令传输到主机。
- 主机请求(H2D):主机对设备的请求通常是以Snoop(侦听)的形式出现的。这些Snoop请求通过H2D(Host to Device)通道发出,用于查询或修改设备侧的数据状态。
- 命令顺序:在CXL通信中,命令的顺序非常关键。H2D请求(Snoop)会推动H2D响应(RSP)的生成,这保证了数据的一致性和准确性。
CXL缓存读/写流程
CXL Fabric
CXL Fabrics是CXL 2.0规范中新增加的一项功能,它允许将CXL技术扩展到更大规模的设备网络中,比如在整个数据中心的范围内。CXL Fabrics旨在实现设备之间的高速、低延迟通信,并维持数据的一致性,同时还能提供资源池化和分区的能力。
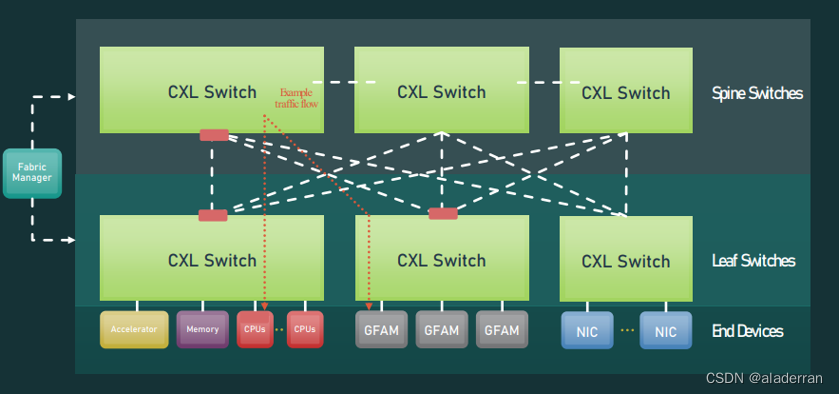
在CXL Fabric架构中,CXL交换机(Switches)扮演了中心的角色。它们负责在设备之间路由通信流量,可以看作是网络的中枢神经。这些交换机通常被组织为一个分层结构,包括脊柱交换机(Spine Switches)和叶子交换机(Leaf Switches)。脊柱交换机位于网络的顶层,负责连接多个叶子交换机,而叶子交换机则直接连接到端设备,如加速器、CPU、内存以及网络接口卡(NICs)等。
CXL Fabric的一个关键组件是Fabric Manager,它是一个软件或硬件实体,负责整个CXL Fabric的管理和配置。它监控交换机和端设备的状态,管理通信流程,并确保数据的正确路由和交付。在上图的例子中,可以看到示意性的流量(红色虚线)在不同交换机之间流动,展示了数据在CXL Fabric内是如何传递的。通过这种方式,CXL Fabric支持了高度可扩展的互连,允许多个计算节点和内存资源协同工作,以提高整体系统的性能和效率。
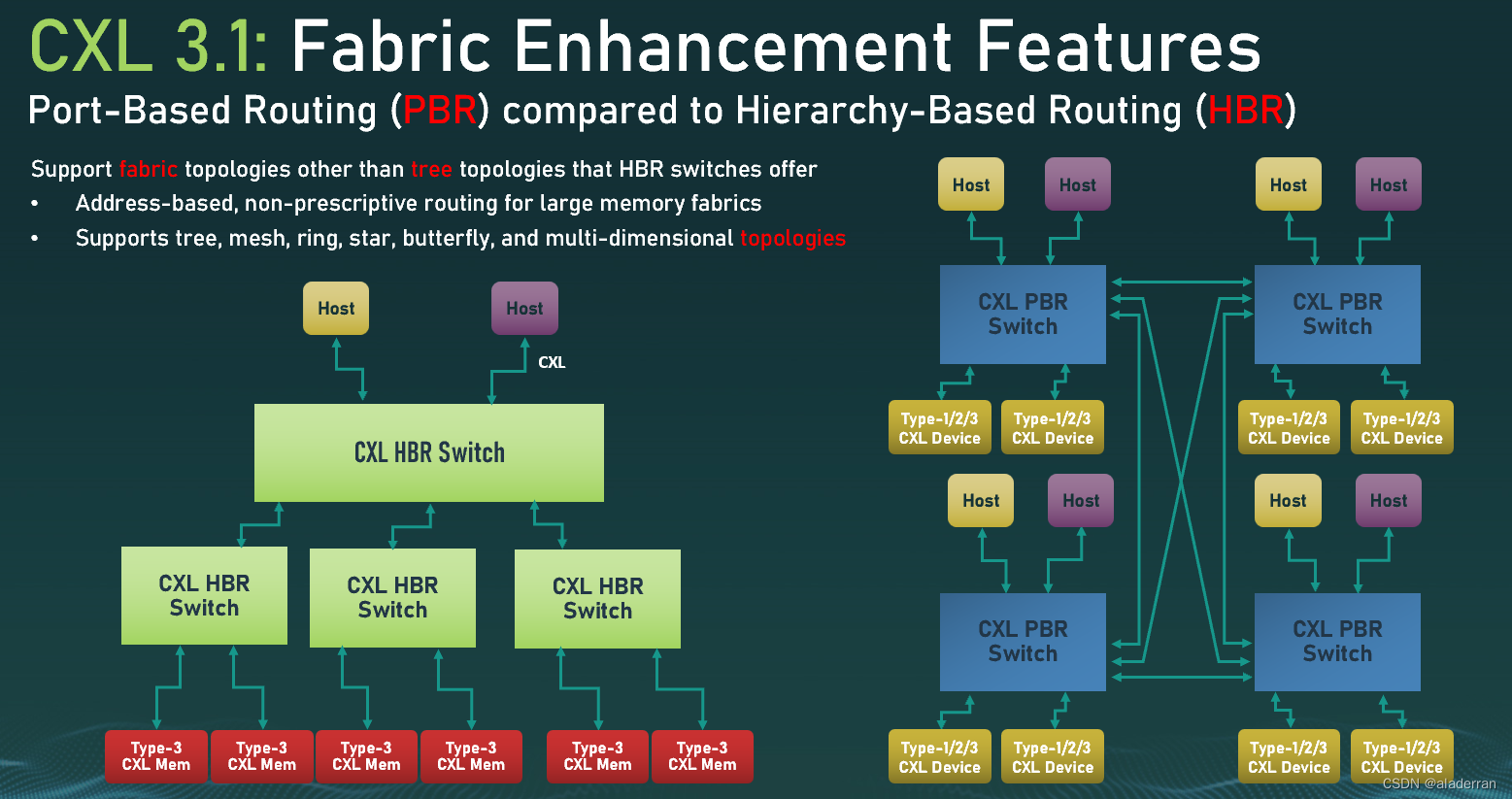
CXL 3.1的一个关键的拓展是它增强了CXL的路由能力,使其不仅仅局限于传统的树状拓扑结构。
在CXL 3.1中,PBR提供了更加灵活的路由机制,它支持各种网络拓扑结构,比如网状、环形、星形、蝴蝶形和多维拓扑。这种基于地址的、非规定性的路由方式适用于大型内存布局,使得内存和计算资源可以更加高效地在多个主机和设备之间共享和通信。
图中显示了多种类型的CXL设备(包括Type-1/2/3)都通过CXL PBR交换机连接在一起。这种连接方式不仅提高了内存的可访问性和灵活性,还为CXL网络的扩展提供了更多可能性。例如,不同类型的CXL设备可以通过不同的PBR交换机连接,从而构建一个高度定制和优化的CXL网络。
3. CXL Features
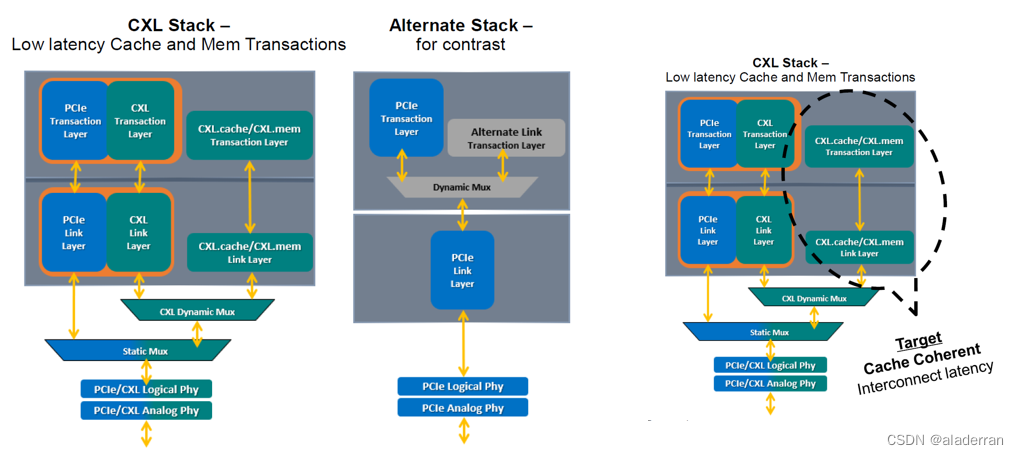
CXL Stack
CXL缓存和内存栈的特点包括:
- 将事务层和链接层从I/O(输入/输出操作)中分离出来,这有助于减少复杂性和提高效率。
- 固定的message framing结构,这确保了数据传输的稳定性和可靠性。
此外,CXL I/O流量通过的栈与标准PCIe栈在很大程度上是相同的:
- CXL采用动态框架结构,这使得栈可以更加灵活地处理不同类型的数据包。
- CXL事务层数据包(TLP)和数据链路层数据包(DLLP)被封装在CXL flits中,这是CXL通信的基本传输单元。
Asymmetric Complexity
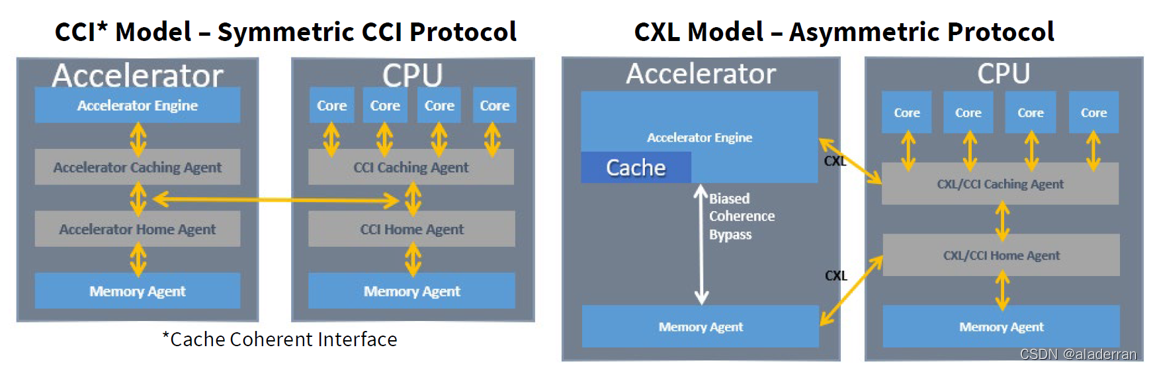
CCI模型(左侧)展示了一个对称的缓存一致性接口,其中加速器和CPU共享缓存一致性逻辑。在这个模型中,加速器具有自己的加速器引擎、缓存代理和主机代理。这种设计意味着加速器和CPU在缓存一致性方面具有等价的地位,所有的缓存一致性操作都需要在加速器和CPU之间进行协调。
CXL模型(右侧)呈现了一种非对称的协议,加速器可以直接与内存代理通信,从而减少了缓存一致性操作的复杂性。
其主要优势包括:
- 避免了协议互操作性的障碍,即不同技术间的兼容问题。
- 使设备能够拥有内存缓冲区而不承担一致性负担。
- 使得设备开发更简单,且处理器独立。
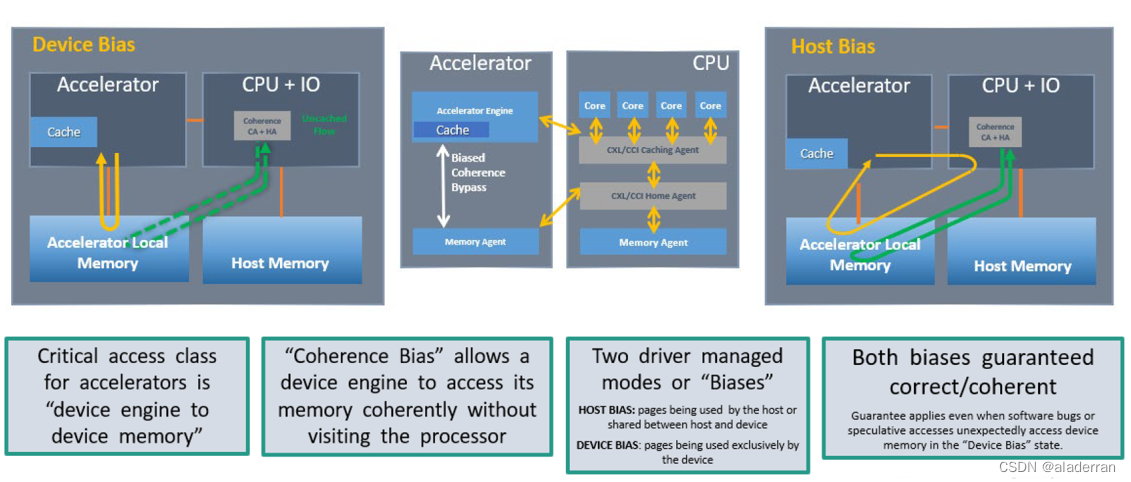
Coherence Bias
- 设备偏置(Device Bias):在这个模式中,加速器被设计为优先使用其本地内存,这样它就可以绕过主存(Host Memory)来访问数据,减少延迟和提高性能。
- 主机偏置(Host Bias):相反地,这种模式下,加速器被设计为与主存中的数据进行一致性交互,这通常适用于需要与CPU或其他I/O设备共享数据的场景。
两种管理模式或“偏置”确保了:
- 主机偏置下,页被主机和设备共享使用,保证了即使在软件出现错误或者设备在不预期的情况下访问内存时,也能保持数据的正确和一致。
- 设备偏置下,页被设备独占使用,这样即使出现预期之外的访问也能保持数据的正确和一致。
“一致性偏置”(Coherence Bias)允许设备引擎直接访问主机内存,而不需要协调处理器,从而保持高效访问而无需处理复杂的一致性协议。
4. CXL IP


5. CXL Use Cases
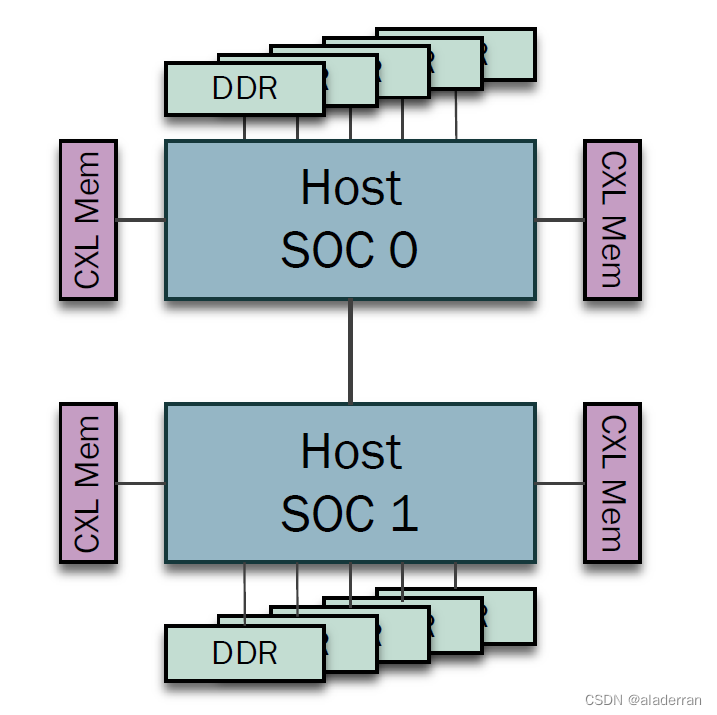
CPU Case (Memory Expansion)
CXL使得各个SOC可以共享外部CXL内存,提供在容量、延迟和持久性之间的权衡选择。包括:
- DRAM(动态随机存取内存)
- DRAM + 缓存
- 存储级内存
- DDR/SCM(静态列存储)+ NVMe(非易失性内存快速接口)
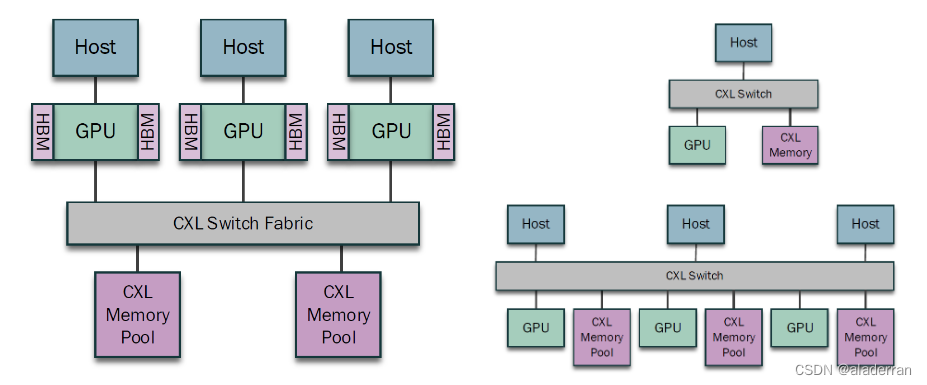
GPU Cases (Memory Pooling)
(左)CXL内存池化允许系统灵活地为每个GPU分配所需的内存,尤其适用于那些对内存容量要求高于带宽需求的工作负载。通过使用CXL技术,可以将大型数据集存储在统一的内存空间内,这些数据可以在不同的加速器之间共享,而不会对主机系统的接口造成额外负担。在这种配置中,多个主机通过CXL开关组织连接到CXL内存池,而每个主机又连接到配备有高带宽内存的GPU,从而实现了数据处理和计算资源的高效分配与使用。
(右)CXL可使主机和GPU之间的扩展内存共享,未来的技术发展可能会允许这些扩展内存同时在多个主机以及主机和加速器之间共享。这种共享提供了在不同需求下的配置灵活性,同时简化了编程模型。CXL开关可以是局部的物理开关,或者是通过其他物理传输层的虚拟开关,从而使远程分散内存成为可能。
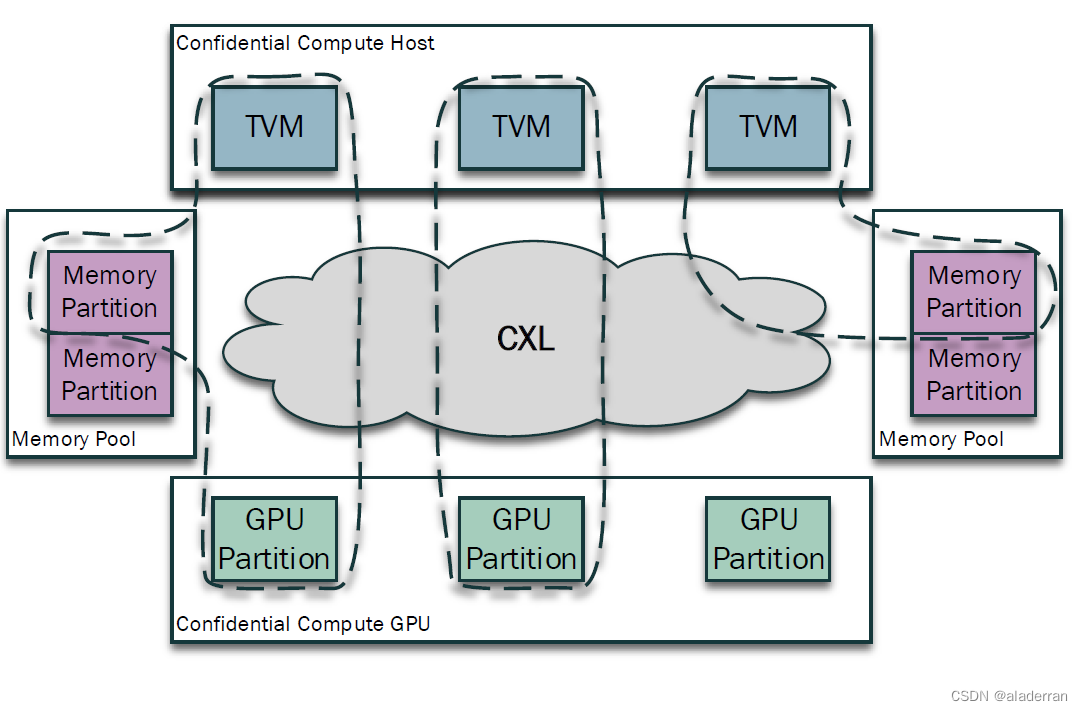
Other Case
CXL技术在加密计算领域的应用:
- 加密计算组件:这些组件可以分区并分配给可信执行环境虚拟机(TVM)。TVM可以创建它们自己的安全虚拟环境,包括主机资源、加速器分区和共享内存分区
- 数据传输安全性:数据传输过程中将被加密,并且数据的完整性得到保护
- 组件认证:所有组件都将通过安全方式进行认证
- 分区安全性:分区将对不信任的实体(包括其他虚拟机/TVM、固件和虚拟机管理器)安全,防止它们的访问
Reference:
Compute Express Link™ (CXL™): Exploring Coherent Memory and Innovative Use Cases
SDC2020: Understanding Compute Express Link: A Cache-coherent Interconnect
伺服器記憶體互連共享技術: CXL技術入門
是时候深入了解CXL了!

















 82
82

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









