









前言
以下参考及本文许多地方都有错误,指出立马修改
参考1
参考2
参考3
step01
安装pycuda库
缺少cuda,然后去必应上找的cuda 10.0
然后缺少一个编译用的cl.exe,去下载Microsoft Visual Studio/2017,一定不能是最新的
最后配置一下cl.exe的环境变量,跑起来一个基础的程序就可以了
from time import *
import numpy as np
from pycuda import gpuarray
import pycuda.autoinit
import os
import pycuda.driver as drv
from pycuda.compiler import SourceModule
# 刚开始这里不加会报错,就加上了
_path = r"C:/Program Files (x86)/Microsoft Visual Studio/2017/Enterprise/VC/Tools/MSVC/14.16.27023/bin/Hostx64/x64"
if os.system("cl.exe"):
os.environ['PATH'] += ';' + _path
if os.system("cl.exe"):
raise RuntimeError("cl.exe still not found, path probably incorrect")
def simple_speed_test():
host_data = np.float32(np.random.random(50000000))
t1 = time()
host_data_2x = host_data * np.float32(2)
t2 = time()
print(f'total time to compute on CPU: {t2 - t1}')
device_data = gpuarray.to_gpu(host_data)
t1 = time()
device_data_2x = device_data * np.float32(2)
t2 = time()
from_device = device_data_2x.get()
print(f'total time to compute on GPU: {t2 - t1}')
print(f'Is the host computation the same as the GPU computation? : {np.allclose(from_device, host_data_2x)}')
simple_speed_test()
step02
学习CUDA C编程,个人感觉比较重要的一点是索引选取和block以及thread的设计
自带的两个核:
还有一个用于自定义的SourceModel

# 编写核函数
mod = SourceModule("""
__global__ void CAL_RMS(float *a ,float *b)
{
int idx = threadIdx.x + blockIdx.x*blockDim.x;
a[idx] = (a[idx]-b[idx])*(a[idx]-b[idx])*96.04;
}
""")
# 创建数据
acc_data = np.array(acc_data, dtype=np.float32)
acc_mean = np.empty_like(acc_data)
acc_mean[:] = np.float32(acc_data.mean())
# 分配内存
a_gpu = cuda.mem_alloc(acc_data.nbytes)
b_gpu = cuda.mem_alloc(acc_mean.nbytes)
# 赋值
cuda.memcpy_htod(a_gpu, acc_data)
cuda.memcpy_htod(b_gpu, acc_mean)
# 调用
func = mod.get_function("CAL_RMS")
func(a_gpu, b_gpu, grid=(int(acc_data.shape[0]/250),), block=(250, 1, 1))
# 取结果值
a_doubled = np.empty_like(acc_data)
cuda.memcpy_dtoh(a_doubled, a_gpu)
这里就涉及到一个很重要的概念,就是
int idx = threadIdx.x + blockIdx.x*blockDim.x;
pycuda里线程号的选取方式,这个其实是和
func(a_gpu, b_gpu, grid=(int(acc_data.shape[0]/250),), block=(250, 1, 1))
密切相关的,前提是了解GPU线程,线程块概念
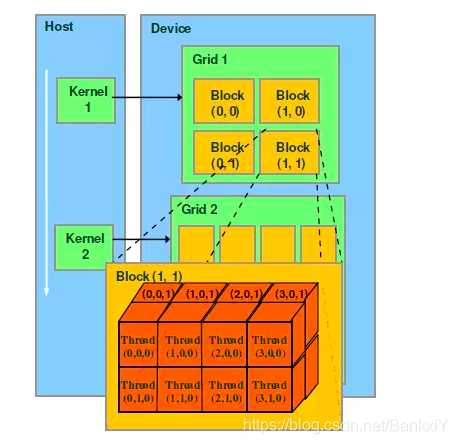
线程号的计算方式(不一定都对,至少情况4是没问题的):
# 1.使用N个线程块,每一个线程块只有一个线程
dim3 dimGrid(N);
dim3 dimBlock(1);
threadId = blockIdx.x;
# 2.使用M×N个线程块,每个线程块1个线程
dim3 dimGrid(M,N);
dim3 dimBlock(1);
blockIdx.x #取值0到M-1
blcokIdx.y #取值0到N-1
pos = blockIdx.y * gridDim.x + blockIdx.x; #其中gridDim.x等于M
# 3.使用一个线程块,该线程具有N个线程
dim3 dimGrid(1);
dim3 dimBlock(N);
threadId = threadIdx.x;
# 4.使用M个线程块,每个线程块内含有N个线程
dim3 dimGrid(M);
dim3 dimBlock(N);
threadId = threadIdx.x + blcokIdx.x*blockDim.x;
# 5.使用M×N的二维线程块,每一个线程块具有P×Q个线程
dim3 dimGrid(M, N);
dim3 dimBlock(P, Q);
threadId.x = blockIdx.x*blockDim.x+threadIdx.x;
threadId.y = blockIdx.y*blockDim.y+threadIdx.y;
step03
最后就是多理解多敲吧,找到合适可以修改的地方进行修改,GPU并行这块就靠pycuda了,另外在CPU的并行计算上有三个适用于pandas的库
# 1.用parallel_apply代替apply,仅限linux和Mac系统
from pandarallel import pandarallel
pandarallel.initialize()
# 2.针对apply
import swifter
data.swifter.apply(lambda)
# 3.直接替代pandas,适代码而用
import modin.pandas as pd
另外就是用多线程多进程来处理了
import threadpool
thread_data=list(np.array(km_stake))[1:]
# print(thread_data)
pool = threadpool.ThreadPool(8)
requests = threadpool.makeRequests(apply_work, thread_data)
[pool.putRequest(req) for req in requests]
pool.wait()















 5203
5203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









